
Maison >Périphériques technologiques >IA >ICLR 2024 Spotlight | Le poids du modèle de langage large, l'activation et la micronisation complète à faible débit ont été intégrés dans l'application commerciale
ICLR 2024 Spotlight | Le poids du modèle de langage large, l'activation et la micronisation complète à faible débit ont été intégrés dans l'application commerciale

- PHPzavant
- 2024-03-07 16:16:16888parcourir
La quantification du modèle est une technologie clé dans la compression et l'accélération des modèles. Elle quantifie les poids du modèle et les valeurs d'activation en bits faibles, permettant au modèle d'occuper moins de mémoire et d'accélérer l'inférence. Pour les grands modèles de langage avec des paramètres massifs, la quantification du modèle est encore plus importante. Par exemple, les paramètres 175B du modèle GPT-3 consomment 350 Go de mémoire lorsqu'ils sont chargés au format FP16, nécessitant au moins cinq GPU A100 de 80 Go.
Mais si les poids du modèle GPT-3 peuvent être compressés à 3 bits, alors un seul A100-80GB peut être utilisé pour charger tous les poids du modèle.
À l'heure actuelle, l'algorithme de quantification post-formation du modèle de langage à grande échelle existant présente un défi évident, à savoir qu'il repose sur le réglage manuel des paramètres de quantification et qu'il lui manque un processus d'optimisation correspondant. Il en résulte que les méthodes existantes subissent souvent une dégradation des performances lors de l'exécution d'une quantification à bits faibles. Bien que la formation prenant en compte la quantification soit efficace pour déterminer la configuration de quantification optimale, elle nécessite des coûts de formation et une prise en charge des données supplémentaires. En particulier dans les modèles de langage à grande échelle, la quantité de calcul elle-même est déjà importante, ce qui rend plus difficile l'application d'une formation prenant en compte la quantification dans la quantification de modèles de langage à grande échelle.
Cela soulève la question : pouvons-nous atteindre les performances d'un entraînement prenant en compte la quantification tout en conservant l'efficacité du temps et des données de la quantification post-entraînement ?
Afin de traiter le problème de l'optimisation des paramètres de quantification lors de la post-formation de grands modèles de langage, un groupe de chercheurs du Laboratoire d'Intelligence Artificielle de Shanghai, de l'Université de Hong Kong et de l'Université chinoise de Hong Kong a proposé « OmniQuant : Omnidirectionnellement Quantification calibrée pour les grands modèles de langage". Cet algorithme prend non seulement en charge la quantification des poids et des activations dans de grands modèles de langage, mais peut également s'adapter à différents paramètres de bits de quantification.

Adresse de l'article arXiv : https://arxiv.org/abs/2308.13137
Adresse de l'article OpenReview : https://openreview.net/forum?id=8Wuvhh0LYW
Adresse du code : https://github. com/OpenGVLab/OmniQuant
Framework Method

Comme le montre la figure ci-dessus, OmniQuant est une technologie de quantification différenciable pour les grands modèles de langage (LLM), prenant en charge à la fois la quantification par poids uniquement et la quantification simultanée de la valeur d'activation du poids. De plus, il permet d'obtenir un modèle de quantification hautes performances tout en conservant l'efficacité du temps de formation et l'efficacité des données de la quantification post-formation. Par exemple, OmniQuant peut mettre à jour les paramètres de quantification des modèles LLaMA-7B ~ LLaMA70B en 1 à 16 heures sur une seule carte A100-40GB.
Pour atteindre cet objectif, OmniQuant adopte un cadre de minimisation des erreurs de quantification par blocs. Dans le même temps, OmniQuant a conçu deux nouvelles stratégies pour augmenter les paramètres de quantification apprenables, notamment l'écrêtage de poids apprenable (LWC) pour réduire la difficulté de quantification des poids, et une transformation équivalente apprenable (Learnable Equivalent Transformation, LET), qui déplace encore davantage le défi de la quantification. des valeurs d'activation aux poids.
De plus, tous les paramètres apprenables introduits par OmniQuant peuvent être fusionnés et éliminés une fois la quantification terminée, et le modèle de quantification peut être déployé sur plusieurs plates-formes basées sur des outils existants, notamment GPU, Android, IOS, etc.
Minimisation des erreurs de quantification par blocs
OmniQuant propose un nouveau processus d'optimisation qui utilise la minimisation des erreurs de quantification par blocs et optimise les paramètres de quantification supplémentaires de manière différenciable. Parmi eux, l'objectif d'optimisation est formulé comme suit :
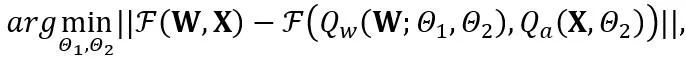
où F représente la fonction de cartographie d'un bloc de transformateur en LLM, W et sont respectivement les paramètres de quantification en écrêtage de poids apprenable (LWC) et transformation équivalente apprenable (LET). . OmniQuant installe une quantification par bloc pour quantifier séquentiellement les paramètres d'un bloc Transformer avant de passer au suivant. 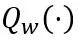
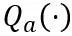
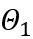 Coupe de poids apprenable (LWC)
Coupe de poids apprenable (LWC)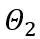
La transformation équivalente effectue un transfert de grandeur entre les poids du modèle et les valeurs d'activation. La transformation équivalente apprenable adoptée par OmniQuant entraîne une modification continue de la distribution des poids du modèle avec la formation pendant le processus d'optimisation des paramètres. Les méthodes précédentes d’apprentissage direct des seuils d’écrêtage de poids [1,2] ne conviennent que lorsque la répartition du poids ne change pas radicalement, sinon il sera difficile de converger. Basé sur ce problème, contrairement aux méthodes précédentes qui apprennent directement le seuil d'écrêtage du poids, LWC optimise l'intensité d'écrêtage de la manière suivante :
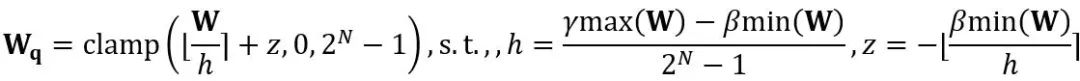
où ⌊⋅⌉ représente l'opération d'arrondi. N est le nombre cible de chiffres. 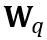 et W représentent respectivement les poids quantifiés et de pleine précision. h est le facteur de normalisation des poids et z est la valeur du point zéro. L'opération de serrage limite la valeur quantifiée à la plage d'entiers de N bits, c'est-à-dire
et W représentent respectivement les poids quantifiés et de pleine précision. h est le facteur de normalisation des poids et z est la valeur du point zéro. L'opération de serrage limite la valeur quantifiée à la plage d'entiers de N bits, c'est-à-dire 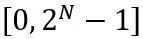 . Dans la formule ci-dessus,
. Dans la formule ci-dessus, 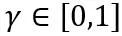 et
et 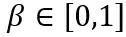 sont respectivement les forces d'écrêtage apprenables des limites supérieure et inférieure du poids. Par conséquent, dans la fonction objectif d’optimisation
sont respectivement les forces d'écrêtage apprenables des limites supérieure et inférieure du poids. Par conséquent, dans la fonction objectif d’optimisation 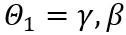 .
.
Transformation équivalente apprenable (LET)
En plus d'optimiser le seuil d'écrêtage pour atteindre LWC avec des poids plus adaptés à la quantification, OmniQuant réduit encore la difficulté de quantifier les valeurs d'activation via LET. Considérant que des valeurs aberrantes dans les valeurs d'activation LLM existent dans des canaux spécifiques, les méthodes précédentes telles que SmoothQuant [3], Outlier Supression+[4] transfèrent la difficulté de quantification des valeurs d'activation aux poids via des transformations mathématiquement équivalentes.
Cependant, des paramètres de transformation équivalents obtenus par sélection manuelle ou recherche gourmande limiteront les performances du modèle quantifié. Grâce à l'introduction de la minimisation des erreurs de quantification par blocs, le LET d'OmniQuant peut déterminer les paramètres de transformation équivalents optimaux de manière différentiable. Inspiré par Outlier Suppression+~citep {outlier-plus}, la mise à l'échelle et le décalage au niveau du canal sont utilisés pour manipuler la distribution d'activation, offrant ainsi une solution efficace au problème des valeurs aberrantes dans les valeurs d'activation. Plus précisément, OmniQuant explore les transformations équivalentes dans les couches linéaires et les opérations d'attention.
Transformation équivalente dans une couche linéaire : Une couche linéaire accepte une séquence d'entrée de jetons 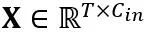 , où T est la longueur du jeton et est le produit de la matrice de poids
, où T est la longueur du jeton et est le produit de la matrice de poids 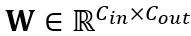 et du vecteur de biais
et du vecteur de biais 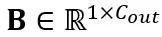 . L'expression de couche linéaire mathématiquement équivalente est :
. L'expression de couche linéaire mathématiquement équivalente est :
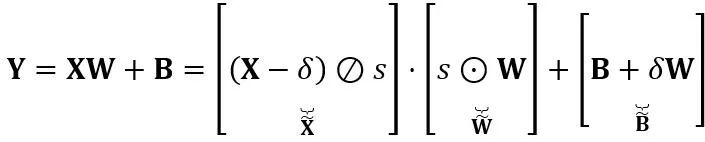
où Y représente la sortie, 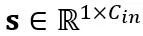 et
et 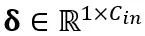 sont respectivement des paramètres de mise à l'échelle et de décalage au niveau du canal,
sont respectivement des paramètres de mise à l'échelle et de décalage au niveau du canal, 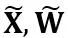 et
et 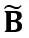 sont respectivement des activations, des poids et des biais équivalents, ⊘ et ⊙ représentent la division et la multiplication au niveau des éléments. Grâce à la conversion équivalente de la formule ci-dessus, la valeur d'activation est convertie en une forme plus facile à quantifier, au prix d'une difficulté accrue de quantification du poids. En ce sens, LWC peut améliorer les performances de quantification du modèle obtenues par LET car il facilite la quantification des poids. Enfin, OmniQuant quantifie les activations et les poids transformés comme suit
sont respectivement des activations, des poids et des biais équivalents, ⊘ et ⊙ représentent la division et la multiplication au niveau des éléments. Grâce à la conversion équivalente de la formule ci-dessus, la valeur d'activation est convertie en une forme plus facile à quantifier, au prix d'une difficulté accrue de quantification du poids. En ce sens, LWC peut améliorer les performances de quantification du modèle obtenues par LET car il facilite la quantification des poids. Enfin, OmniQuant quantifie les activations et les poids transformés comme suit

où Q_a est le quantificateur MinMax ordinaire et Q_w est le quantificateur MinMax avec découpage de poids apprenable (c'est-à-dire le LWC proposé).
Transformation équivalente dans les opérations d'attention : En plus des couches linéaires, les opérations d'attention occupent également la plupart des calculs de LLM. De plus, le mode d'inférence autorégressive de LLM nécessite de stocker un cache clé-valeur (KV) pour chaque jeton, ce qui entraîne d'énormes besoins en mémoire pour les longues séquences. Par conséquent, OmniQuant envisage également de quantifier la matrice Q/K/V dans les calculs de force autonomes en bits faibles. Plus précisément, la transformation équivalente apprenable dans la matrice d'auto-attention peut s'écrire comme :

où 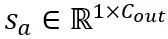 facteur d'échelle. Le calcul quantitatif dans le calcul d’auto-attention est exprimé par
facteur d'échelle. Le calcul quantitatif dans le calcul d’auto-attention est exprimé par 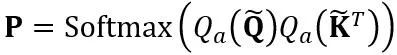 . Ici, OmniQuant utilise également le schéma de quantification MinMax comme
. Ici, OmniQuant utilise également le schéma de quantification MinMax comme 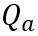 pour quantifier la matrice
pour quantifier la matrice 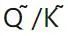 . Par conséquent,
. Par conséquent, 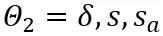 dans la fonction objectif est finalement optimisé.
dans la fonction objectif est finalement optimisé.
Pseudo code

Le pseudo-algorithme d'OmniQuant est présenté dans la figure ci-dessus. Notez que les paramètres supplémentaires introduits par LWC et LET peuvent être éliminés une fois le modèle quantifié, c'est-à-dire qu'OmniQuant n'introduit aucune surcharge supplémentaire dans le modèle quantifié, il peut donc être directement adapté aux outils de déploiement de quantification existants.
Performance expérimentale
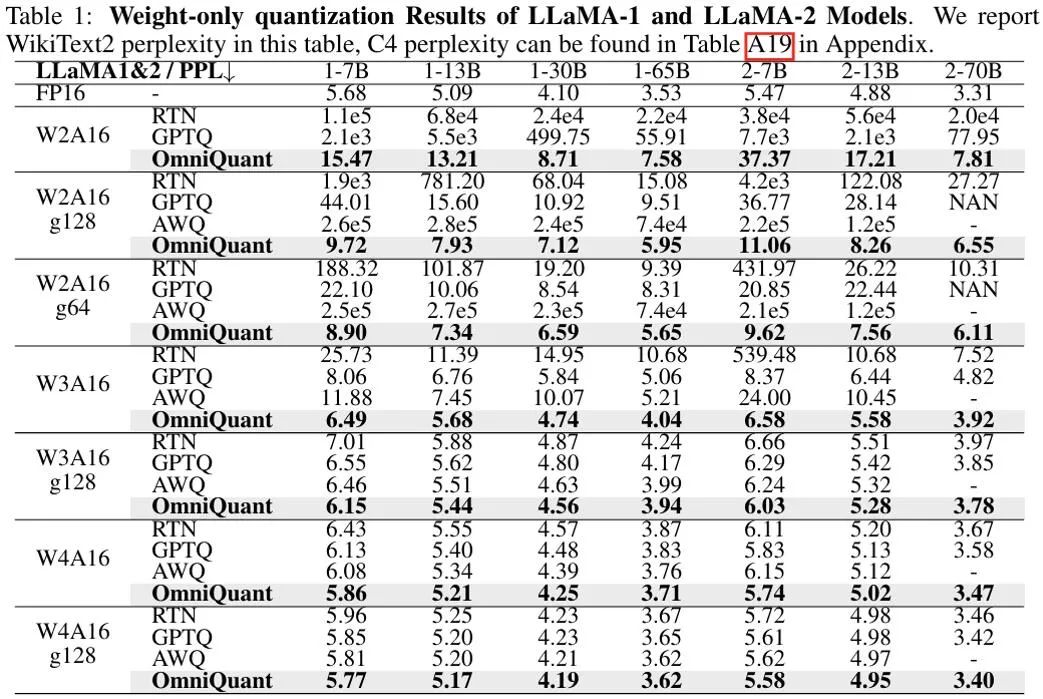
La figure ci-dessus montre les résultats expérimentaux des résultats de quantification du poids uniquement d'OmniQuant sur le modèle LLaMA. Pour plus de résultats du modèle OPT, voir le texte original. Comme on peut le constater, OmniQuant surpasse systématiquement les modèles précédents dans divers modèles LLM (OPT, LLaMA-1, LLaMA-2) et diverses configurations de quantification (notamment W2A16, W2A16g128, W2A16g64, W3A16, W3A16g128, W4A16 et W4A16g128). LLM est une quantification de poids. méthode uniquement. Dans le même temps, ces expériences démontrent la polyvalence d’OmniQuant et sa capacité à s’adapter à diverses configurations de quantification. Par exemple, alors qu'AWQ [5] est particulièrement efficace pour la quantification de groupe, OmniQuant présente des performances supérieures dans la quantification au niveau du canal et du groupe. De plus, à mesure que le nombre de bits de quantification diminue, les avantages en termes de performances d’OmniQuant deviennent encore plus évidents.
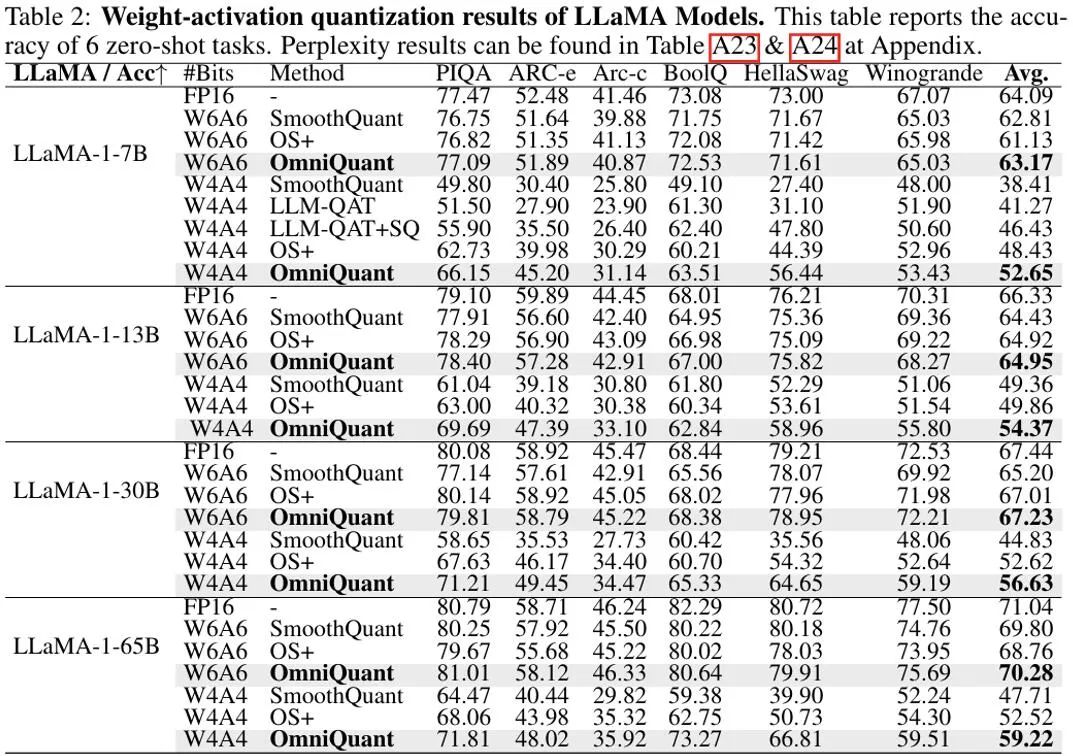
Dans un contexte où les poids et les activations sont quantifiés, l'objectif principal de l'expérience est la quantification W6A6 et W4A4. La quantification W8A8 a été exclue de la configuration expérimentale car le précédent SmoothQuant permettait une quantification du modèle W8A8 presque sans perte par rapport aux modèles de pleine précision. La figure ci-dessus montre les résultats expérimentaux de la quantification par OmniQuant des valeurs d'activation du poids sur le modèle LLaMA. OmniQuant améliore considérablement la précision moyenne des différents modèles de quantification W4A4, avec des augmentations allant de +4,99 % à +11,80 %. Surtout dans le modèle LLaMA-7B, OmniQuant surpasse même la récente méthode de formation prenant en compte la quantification LLM-QAT [6] d'un écart significatif de +6,22 %. Cette amélioration démontre l'efficacité de l'introduction de paramètres apprenables supplémentaires, ce qui est plus bénéfique que les ajustements de poids globaux utilisés dans la formation prenant en compte la quantification.

Dans le même temps, les modèles quantifiés à l'aide d'OmniQuant peuvent être déployés de manière transparente sur MLC-LLM [7]. La figure ci-dessus montre les besoins en mémoire et la vitesse d'inférence du modèle de quantification de la série LLaMA sur NVIDIA A100-80G.
Weights Memory (WM) représente le stockage de poids quantifié, tandis que Running Memory (RM) représente la mémoire lors de l'inférence, cette dernière étant plus élevée car certaines valeurs d'activation sont conservées. La vitesse d'inférence est mesurée en générant 512 jetons. Il est évident que le modèle quantifié réduit considérablement l’utilisation de la mémoire par rapport au modèle 16 bits pleine précision. De plus, la quantification W4A16g128 et W2A16g128 double presque la vitesse d'inférence.
Il convient de noter que MLC-LLM [7] prend également en charge le déploiement du modèle de quantification OmniQuant sur d'autres plates-formes, notamment les téléphones Android et IOS. Comme le montre la figure ci-dessus, la récente application Private LLM utilise l'algorithme OmniQuant pour compléter le déploiement économe en mémoire de LLM sur plusieurs plates-formes telles que iPhone, iPad, macOS, etc.
Résumé
OmniQuant est un algorithme avancé de quantification de grands modèles de langage qui fait progresser la quantification vers un format à bits faibles. Le principe de base d'OmniQuant est de conserver les poids d'origine de pleine précision tout en ajoutant des paramètres de quantification apprenables. Il utilise des connexions de poids apprenables et des transformations équivalentes pour optimiser la compatibilité de quantification des poids et des valeurs d'activation. Tout en intégrant des mises à jour de gradient, OmniQuant maintient une efficacité du temps de formation et une efficacité des données comparables aux méthodes PTQ existantes. De plus, OmniQuant garantit la compatibilité matérielle car ses paramètres pouvant être entraînés supplémentaires peuvent être incorporés dans le modèle d'origine sans aucune surcharge supplémentaire.
Référence
[1] Pact : Activation d'écrêtage paramétrée pour les réseaux de neurones quantifiés.
[2] LSQ : Quantification de la taille des pas appris.
[3] Smoothquant : Post précis et efficace -quantification d'entraînement pour les grands modèles de langage.
[4] Suppression des valeurs aberrantes+ : quantification précise des grands modèles de langage par décalage et mise à l'échelle équivalents et optimaux.
[5] Awq : quantification de poids sensible à l'activation pour la compression LLM et accélération.
[6] Llm-qat : formation prenant en compte la quantification sans données pour les grands modèles de langage.
[7] MLC-LLM : https://github.com/mlc-ai/mlc-llm.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un ingénieur web front-end ? Que fait un ingénieur web front-end ?
- Comment les ingénieurs PHP sont-ils traités ?
- Feuille de route d'apprentissage des ingénieurs de développement PHP full-stack (illustration de la relation et de la séquence d'apprentissage de chaque langage de programmation)
- Quelle est la puissance de charge de l'iphone13pro
- 10 façons de coupler un iPhone avec un Macbook