
Maison >Périphériques technologiques >IA >Surpassant largement ViT, Meituan, l'Université du Zhejiang, etc., VisionLLAMA a proposé, une architecture unifiée pour les tâches visuelles
Surpassant largement ViT, Meituan, l'Université du Zhejiang, etc., VisionLLAMA a proposé, une architecture unifiée pour les tâches visuelles

- PHPzavant
- 2024-03-07 15:37:02940parcourir
Depuis plus de six mois, l'architecture open source LLaMA de Meta a résisté aux tests en LLM et a obtenu un grand succès (formation stable et mise à l'échelle facile).
En suivant les idées de recherche de ViT, pouvons-nous véritablement parvenir à l’unification architecturale du langage et des images à l’aide de l’architecture innovante LLaMA ?
Sur cette proposition, une récente étude VisionLLaMA a fait des progrès. VisionLLaMA s'est considérablement amélioré par rapport à la méthode de classe ViT originale dans de nombreuses tâches courantes telles que la génération d'images (y compris le DIT sous-jacent sur lequel s'appuie Sora) et la compréhension (classification, segmentation, détection, auto-supervision).

- Titre de l'article : VisionLLaMA : Une interface LLaMA unifiée pour les tâches de vision
- Adresse de l'article : https://arxiv.org/abs/2403.00522
- Code adresse : https://github.com/Meituan-AutoML/VisionLLaMA
Cette recherche tente d'unifier l'architecture de l'image et du langage et peut profiter des résultats de formation de la communauté LLM sur LLaMA, notamment stables et efficaces expansion et déploiement.
Contexte de recherche
Le grand modèle de langage est un sujet brûlant dans la recherche universitaire actuelle. Parmi eux, LLaMA est l'un des travaux les plus influents et les plus représentatifs. La plupart des travaux de recherche les plus récents sont basés sur cette architecture. des solutions appliquées sont construites sur les modèles open source de cette série. Dans l'avancement des modèles multimodaux, bon nombre de ces méthodes s'appuient sur LLaMA pour le traitement de texte et sur des transformateurs visuels comme CLIP pour la perception visuelle. Dans le même temps, de nombreux efforts sont consacrés à accélérer la vitesse d’inférence de LLaMA et à réduire le coût de stockage de LLaMA. Dans l’ensemble, LLaMA est désormais de facto l’architecture de grand modèle de langage la plus polyvalente et la plus importante.

Le succès de l'architecture LLaMA a conduit l'auteur de cet article à proposer une idée simple et intéressante : cette architecture peut-elle être également réussie dans les modalités visuelles ? Si la réponse est oui, alors les modèles visuels et linguistiques peuvent utiliser la même architecture unifiée et bénéficier des différentes techniques de déploiement dynamique conçues pour LLaMA. Il s’agit cependant d’une question complexe car il existe des différences évidentes entre les deux modalités.
Il existe des différences significatives dans la façon dont les données sont traitées entre les séquences de texte et les tâches visuelles. D’une part, les séquences de texte sont des données unidimensionnelles, tandis que les tâches de vision nécessitent le traitement de données bidimensionnelles ou multidimensionnelles plus complexes. En revanche, pour les tâches visuelles, il est généralement nécessaire d'utiliser un réseau fédérateur à structure pyramidale pour améliorer les performances, alors que l'encodeur LLaMA a une structure relativement simple. De plus, traiter efficacement les entrées d’images et de vidéos de différentes résolutions constitue un défi. Ces différences doivent être pleinement prises en compte dans des recherches croisées entre les domaines textuels et visuels afin de trouver des solutions plus efficaces.
Le but de cet article est de relever ces défis et de réduire l'écart architectural entre les différentes modalités, en proposant l'architecture LLaMA adaptée aux tâches de vision. Grâce à cette architecture, les problèmes liés aux différences modales peuvent être résolus et les données visuelles et linguistiques peuvent être traitées uniformément, conduisant à de meilleurs résultats.
Les principales contributions de cet article sont les suivantes :
1 Cet article propose VisionLLaMA, une architecture de transformateur visuel similaire à LLaMA, pour réduire la différence architecturale entre langage et vision.
2. Cet article étudie les moyens d'adapter VisionLLaMA aux tâches de vision courantes, y compris la compréhension et la création d'images (Figure 1). Cet article étudie deux schémas d'architecture de vision bien connus (structure régulière et structure pyramidale) et évalue leurs performances dans des scénarios d'apprentissage supervisé et auto-supervisé. De plus, cet article propose AS2DRoPE (c'est-à-dire Autoscaling 2D RoPE), qui étend le codage de position de rotation de 1D à 2D et utilise la mise à l'échelle par interpolation pour s'adapter à des résolutions arbitraires.
3. Sous une évaluation précise, VisionLLaMA surpasse considérablement les transformateurs de vision actuels et affinés avec précision dans de nombreuses tâches représentatives telles que la génération d'images, la classification, la segmentation sémantique et la détection d'objets. Des expériences approfondies montrent que VisionLLaMA a une vitesse de convergence plus rapide et de meilleures performances que les transformateurs de vision existants.
Conception globale de l'architecture de VisionLLaMA
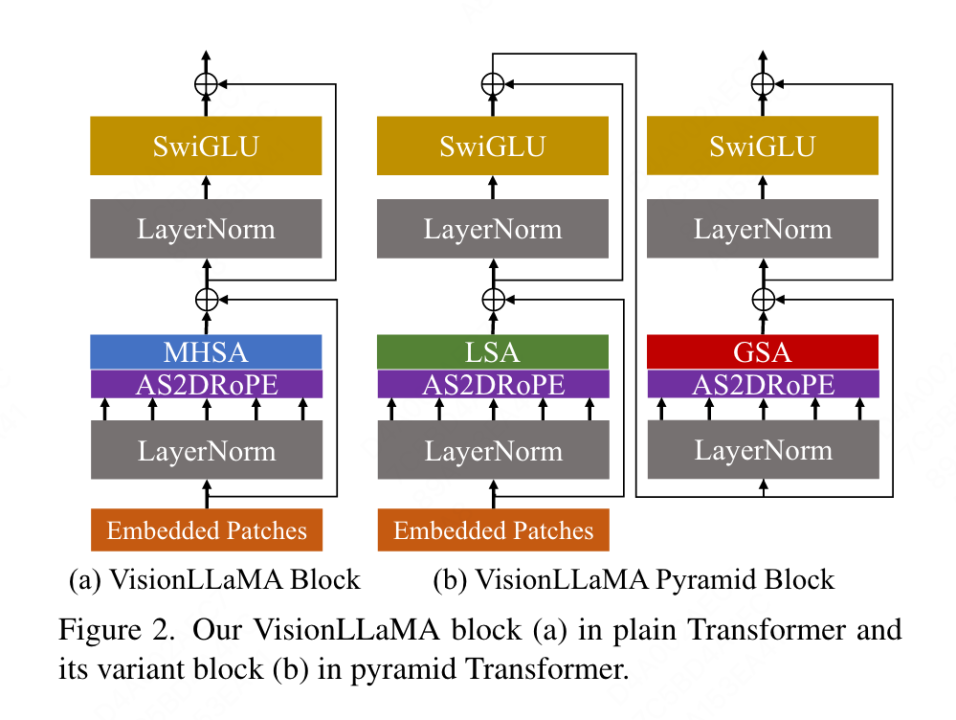
Transformateur conventionnel
Le VisionLLaMA conventionnel proposé dans cet article suit le processus de ViT et conserve autant que possible la conception architecturale de LLaMA. Pour une image, elle est d'abord transformée et aplatie en une séquence, puis un jeton de catégorie est ajouté au début de la séquence, et la séquence entière est traitée via des blocs L VisionLLaMA. Contrairement à ViT, VisionLLaMA n'ajoute pas de codage de position à la séquence d'entrée car les blocs de VisionLLaMA contiennent un codage de position. Plus précisément, ce bloc diffère du bloc ViT standard de deux manières : l'auto-attention avec codage positionnel (RoPE) et l'activation de SwiGLU. Cet article utilise toujours LayerNorm au lieu de RMSNorm car il a constaté expérimentalement que le premier fonctionne mieux (voir Tableau 11g). La structure du bloc est illustrée à la figure 2 (a). Cet article révèle que l'application directe de RoPE 1D dans les tâches de vision ne se généralise pas bien à différentes résolutions, elle est donc étendue à une forme 2D :

Pyramid Structure Transformer
VisionLLaMA est très simple pour s'appliquer aux transformateurs basés sur des fenêtres comme Swin, cet article choisit donc d'explorer comment construire un puissant transformateur à structure pyramidale sur les Twins de base plus forts. L'architecture originale de Twins exploite le codage positionnel conditionnel et l'échange d'informations locales-globales entrelacées sous la forme d'une attention locale-globale. Ces composants sont communs à tous les transformateurs, ce qui signifie qu'il n'est pas difficile d'appliquer VisionLLaMA à diverses variantes de transformateur.
Le but de cet article n'est pas d'inventer un nouveau transformateur de vision à structure pyramidale, mais de savoir comment ajuster la conception de base de VisionLLaMA en fonction de la conception existante. Par conséquent, cet article suit le principe de modifications minimales de l'architecture et. hyperparamètres. Suivant la méthode de dénomination de ViT, deux blocs consécutifs peuvent être écrits comme suit :

où LSA est l'opération d'auto-attention locale au sein du groupe, et GSA est effectuée en interagissant avec les valeurs clés représentatives de chaque sous-fenêtre Sous-échantillonnage global de l'attention. Cet article supprime le codage de position conditionnel dans la structure pyramidale VisionLLaMA car les informations de position sont déjà incluses dans AS2DRoPE. De plus, le jeton de catégorie est supprimé et GAP (global Average Pooling) est utilisé avant le chef de classification. La structure de bloc sous ce paramètre est illustrée à la figure 2 (b).
Formation ou inférence au-delà des limitations de longueur de séquence
Extension de RoPE unidimensionnel en deux dimensions : le traitement de différentes résolutions d'entrée est une exigence courante dans les tâches de vision. Les réseaux de neurones convolutifs utilisent un mécanisme de fenêtre coulissante pour gérer des longueurs variables. En revanche, la plupart des transformateurs visuels appliquent des opérations de fenêtre locales ou une interpolation, par exemple DeiT utilise une interpolation bicubique lorsqu'il est formé sur différentes résolutions ; CPVT utilise un codage de position basé sur la convolution. Cet article évalue les performances du RoPE 1D et constate qu'il a la précision la plus élevée à une résolution de 224 × 224. Cependant, lorsque la résolution augmente à 448 × 448, la précision chute fortement et atteint même 0. Par conséquent, cet article étend le RoPE unidimensionnel à deux dimensions. Pour le mécanisme d’auto-attention multi-têtes, le RoPE 2D est partagé entre différentes têtes.
L'interpolation positionnelle aide le RoPE 2D à mieux se généraliser : Inspiré par certains travaux utilisant l'interpolation pour étendre la fenêtre contextuelle de LLaMA, VisionLLaMA adopte une manière similaire pour étendre la fenêtre contextuelle 2D avec la participation de résolutions plus élevées. Contrairement aux tâches linguistiques avec des longueurs de contexte fixes élargies, les tâches visuelles telles que la détection d'objets gèrent souvent différentes résolutions d'échantillonnage dans différentes itérations. Cet article utilise une résolution d'entrée de 224 × 224 pour entraîner un petit modèle et évalue les performances d'une résolution plus grande sans recyclage, guidant cet article pour mieux appliquer la stratégie d'interpolation ou hétérodyne. Après expérimentations, cet article a choisi d'appliquer une interpolation de mise à l'échelle automatique (AS2DRoPE) basée sur la « résolution d'ancrage ». La méthode de calcul pour traiter une image carrée de H × H et une résolution de point d'ancrage de B × B est la suivante :
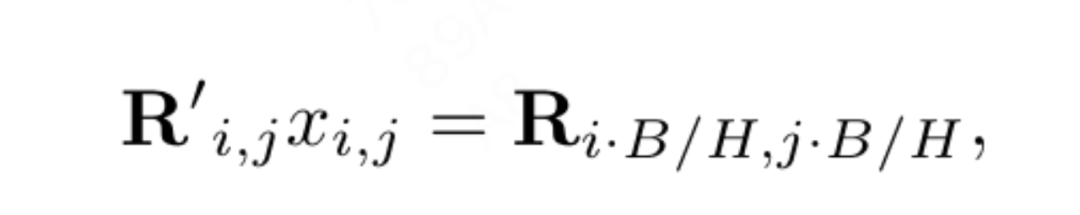
Cette méthode de calcul est efficace et n'introduit pas de coûts supplémentaires. Si la résolution d’entraînement reste inchangée, AS2DRoPE dégénère en RoPE 2D.

En raison de la nécessité d'ajouter des informations de localisation aux valeurs clés résumées, cet article effectue un traitement spécial pour GSA dans le cadre du paramètre de structure pyramidale. Ces clés sous-échantillonnées sont générées par abstraction sur la carte des fonctionnalités. Cet article utilise la convolution avec une taille de noyau k×k et une foulée k. Comme le montre la figure 3, les coordonnées des valeurs clés générées peuvent être exprimées comme la moyenne des caractéristiques échantillonnées.
Résultats expérimentaux
Cet article évalue de manière exhaustive l'efficacité de VisionLLaMA sur des tâches telles que la génération, la classification, la segmentation et la détection d'images. Par défaut, tous les modèles de cet article sont formés sur 8 GPU NVIDIA Tesla A100.
Génération d'images
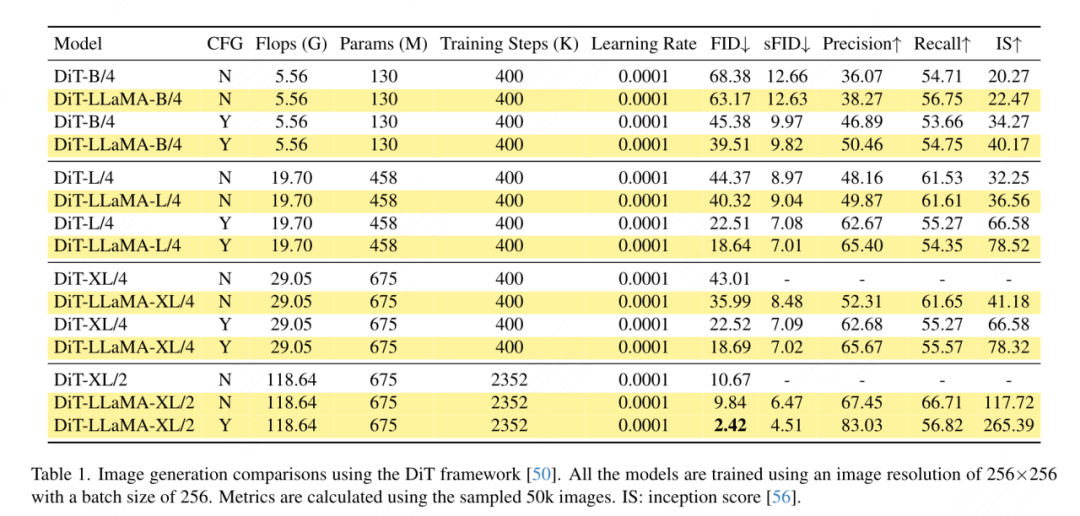
Génération d'images basée sur le framework DiT : Cet article choisit d'appliquer VisionLLaMA sous le framework DiT car DiT est un travail représentatif sur la génération d'images utilisant Visual Transformer et DDPM. Cet article remplace le transformateur de vision d'origine de DiT par VisionLLaMA, tout en conservant les autres composants et hyperparamètres inchangés. Cette expérience démontre la polyvalence de VisionLLaMA sur les tâches de génération d'images. Comme pour DiT, cet article définit les exemples de pas de DDPM à 250 et les résultats expérimentaux sont présentés dans le tableau 1. Conformément à la plupart des méthodologies, le FID est considéré comme la mesure principale et est évalué sur d'autres mesures secondaires telles que le sFID, la précision/le rappel et le score initial. Les résultats montrent que VisionLLaMA surpasse considérablement DiT dans différentes tailles de modèles. Cet article étend également le nombre d'étapes de formation du modèle XL à 2 352 000 pour évaluer si notre modèle présente l'avantage d'une convergence plus rapide ou s'il fonctionne toujours mieux avec des paramètres de période de formation plus longues. Le FID de DiT-LLaMA-XL/2 est inférieur de 0,83 à celui de DiT-XL/2, ce qui indique que VisionLLaMA a non seulement une meilleure efficacité de calcul, mais également des performances supérieures à celles de DiT. Quelques exemples générés à l'aide de modèles XL sont présentés dans la figure 1.
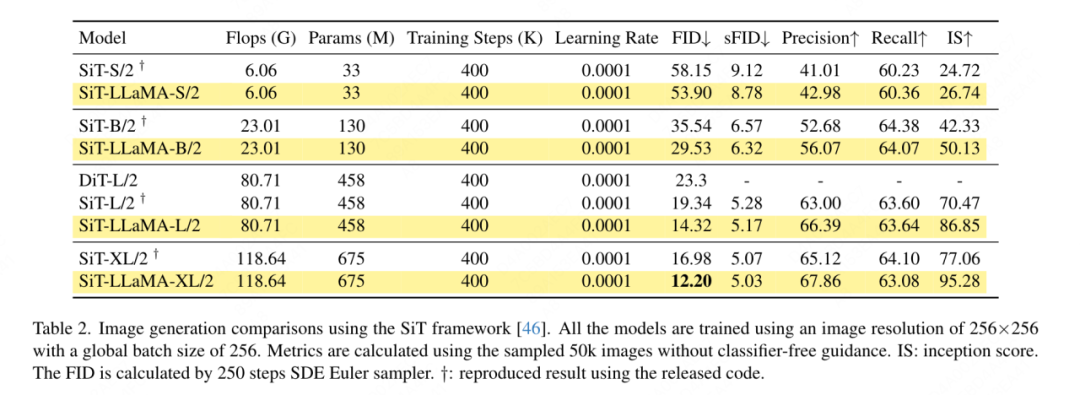
Génération d'images basée sur le framework SiT : le framework SiT améliore considérablement les performances de génération d'images à l'aide de transformateurs visuels. Cet article remplace le transformateur de vision dans SiT par VisionLLaMA pour évaluer les avantages d'une meilleure architecture de modèle, que cet article appelle SiT-LLaMA. Les expériences ont conservé tous les paramètres et hyperparamètres restants dans SiT, tous les modèles ont été formés en utilisant le même nombre d'étapes et des modèles d'interpolation et de vitesse linéaires ont été utilisés dans toutes les expériences. Pour une comparaison équitable, nous avons également réexécuté le code publié et échantillonné 50 000 images 256 × 256 à l'aide d'un échantillonneur SDE (Euler) avec 250 étapes, et les résultats sont présentés dans le tableau 2. SiT-LLaMA surpasse SiT dans les modèles à différents niveaux de capacité. Par rapport à SiT-L/2, SiT-LLaMA-L/2 diminue de 5,0 FID, ce qui est supérieur à l'amélioration apportée par le nouveau framework (4,0 FID). Cet article montre également un échantillonneur ODE plus efficace (dopri5) dans le tableau 13, et l'écart de performances avec notre méthode existe toujours. Des conclusions similaires peuvent être tirées comme dans l’article de SiT : les SDE ont de meilleures performances que leurs homologues ODE.
Classification d'images sur ImageNet
- Entraînement entièrement supervisé
Cette section se concentre sur l'entraînement entièrement supervisé du modèle sur l'ensemble de données ImageNet-1K, à l'exclusion des autres s Ou En raison de l'influence des compétences en distillation, tous les modèles ont été formés à l'aide de l'ensemble de formation ImageNet-1K et les résultats de précision sur l'ensemble de validation sont présentés dans le tableau 3.
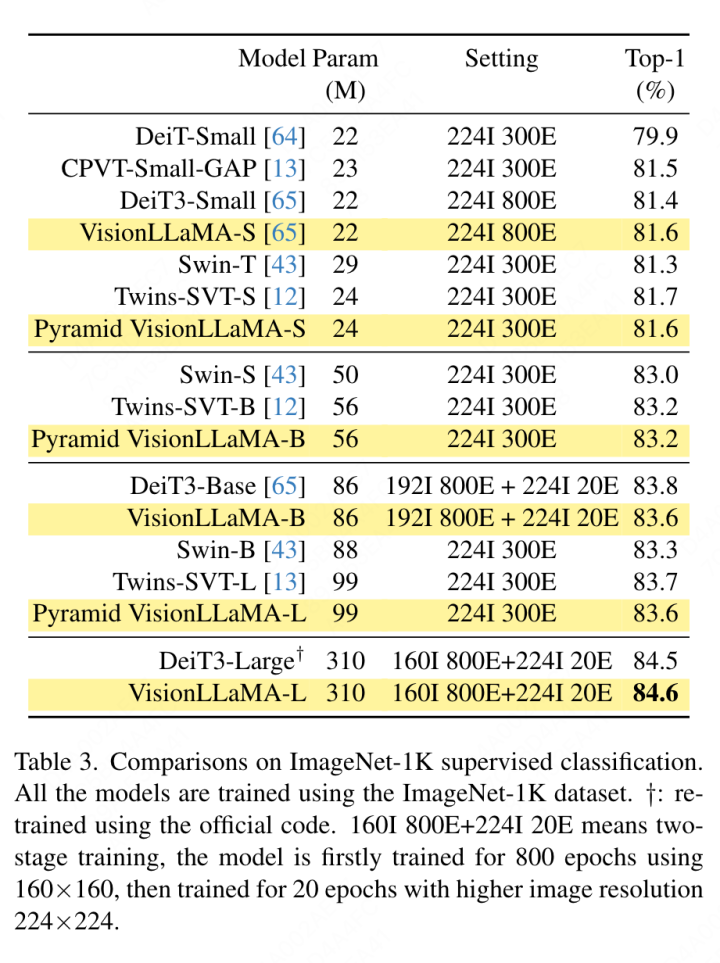
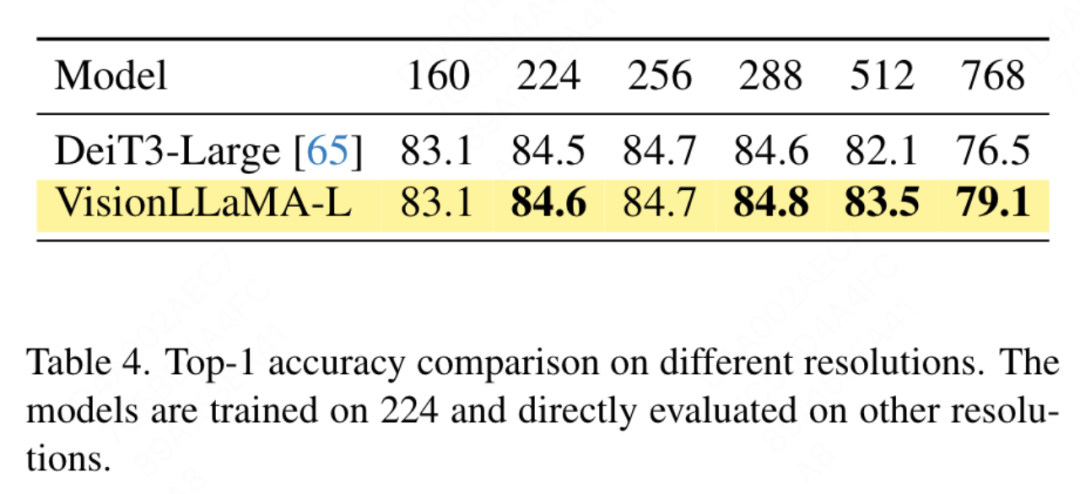
Comparaison des transformateurs de vision conventionnels : DeiT3 est le transformateur de vision conventionnel de pointe actuel qui propose une augmentation spéciale des données et effectue une recherche approfondie d'hyperparamètres pour améliorer les performances. DeiT3 est sensible aux hyperparamètres et sujet au surajustement. Le remplacement des jetons de catégorie par GAP (pooling moyen global) entraînera une baisse de la précision du modèle DeiT3-Large de 0,7 % après 800 époques d'entraînement. Par conséquent, cet article utilise des jetons de catégorie au lieu de GAP dans les transformateurs classiques. Les résultats sont présentés dans le tableau 3, où VisionLLaMA atteint une précision de premier ordre comparable à DeiT3. La précision à une seule résolution ne fournit pas une comparaison complète. Cet article évalue également les performances à différentes résolutions d'image, et les résultats sont présentés dans le tableau 4. Pour DeiT3, nous utilisons l'interpolation bicubique pour un codage positionnel apprenable. Bien que les deux modèles aient des performances comparables à une résolution de 224 × 224, l'écart se creuse lorsque la résolution augmente, ce qui signifie que notre méthode a une meilleure capacité de généralisation à différentes résolutions, ce qui est bon pour la détection de cibles et de nombreuses autres tâches en aval.
Comparaison du transformateur visuel de la structure pyramidale : cet article utilise la même architecture que Twins-SVT, et la configuration détaillée est répertoriée dans le tableau 17. Cet article supprime le codage de position conditionnel car VisionLLaMA contient déjà un codage de position de rotation. Par conséquent, VisionLLaMA est une architecture sans convolution. Cet article suit tous les paramètres, y compris les hyperparamètres dans Twins-SVT, qui sont cohérents avec Twins-SVT. Cet article n'utilise pas de jetons de catégorie, mais applique GAP. Les résultats sont présentés dans le tableau 3. Notre méthode atteint des performances comparables à Twins à tous les niveaux de modèle et est toujours meilleure que Swin.
- Formation auto-supervisée
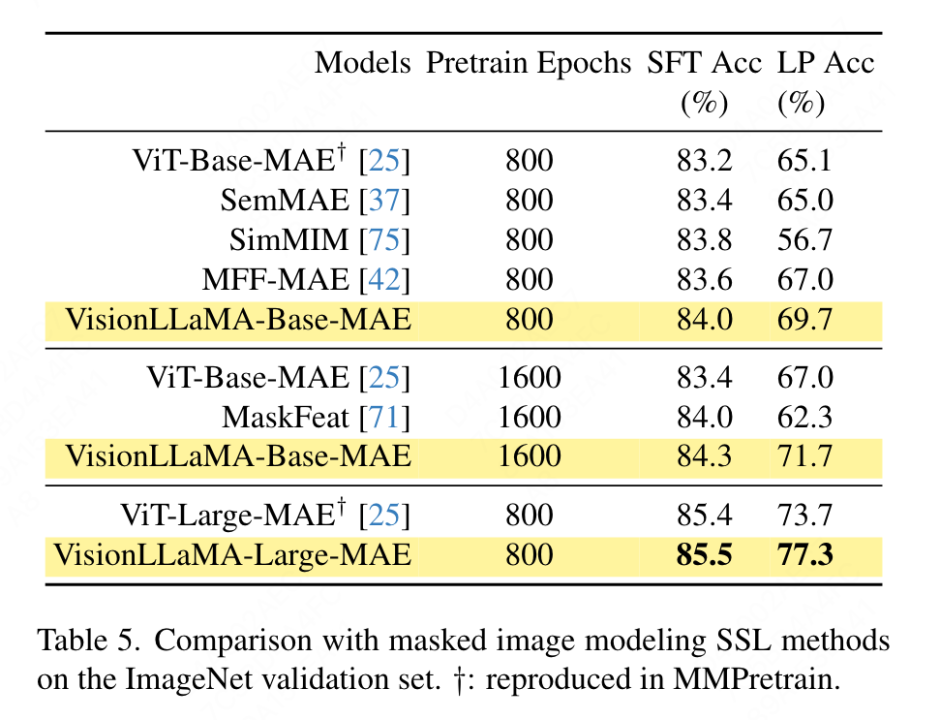
Cet article utilise l'ensemble de données ImageNet pour évaluer deux méthodes courantes de transformateurs visuels auto-supervisés, tout en limitant les données de formation à ImageNet-1K, en supprimant toute utilisation de CLIP, DALLE ou distillation, etc. Composants pouvant améliorer les performances, la mise en œuvre de cet article est basée sur le framework MMPretrain, utilise le framework MAE et utilise VisionLLaMA pour remplacer l'encodeur, tout en gardant les autres composants inchangés. Cette expérience de contrôle permet d'évaluer l'efficacité de cette méthode. De plus, nous utilisons les mêmes paramètres d'hyperparamètres que les méthodes comparées, grâce auxquels nous obtenons toujours des améliorations de performances significatives par rapport aux lignes de base puissantes.
Configuration de réglage fin complète : dans la configuration actuelle, le modèle est d'abord initialisé avec des poids pré-entraînés, puis entraîné en plus avec des paramètres entièrement entraînables. VisionLLaMA-Base a été formé sur ImageNet pendant 800 époques et a atteint une précision top-1 de 84,0 %, soit 0,8 % de plus que ViT-Base. La méthode décrite dans cet article s'entraîne environ 3 fois plus vite que SimMIM. Ce document augmente également la période de formation à 1 600 pour vérifier si VisionLLaMA peut maintenir son avantage avec des ressources de formation suffisantes. VisionLLaMA-Base obtient de nouveaux résultats SOTA parmi les variantes MAE, avec une précision top 1 de 84,3 %, soit une amélioration de 0,9 % par rapport à ViT-Base. Étant donné qu’un réglage fin complet comporte un risque de saturation des performances, l’amélioration de cette méthode est très significative.
Sondage linéaire : un travail récent considère la métrique du sondage linéaire comme une évaluation plus fiable de l'apprentissage représentationnel. Dans la configuration actuelle, le modèle est initialisé avec des poids pré-entraînés de l'étape SSL. Ensuite, pendant la formation, l’ensemble du réseau fédérateur est gelé à l’exception de la tête du classificateur. Les résultats sont présentés dans le tableau 5 : avec un coût de formation de 800 époques, VisionLLaMA-Base surpasse ViTBase-MAE de 4,6 %. Il surpasse également ViT-Base-MAE formé pendant 1 600 époques. Lorsque VisionLLaMA est entraîné pendant 1 600 époques, VisionLLaMA-Base atteint une précision top1 de 71,7 %. Cette méthode est également étendue à VisionLLaMA-Large, qui s'améliore de 3,6% par rapport à ViT-Large.
Segmentation sémantique sur le jeu de données ADE20K
- Formation entièrement supervisée
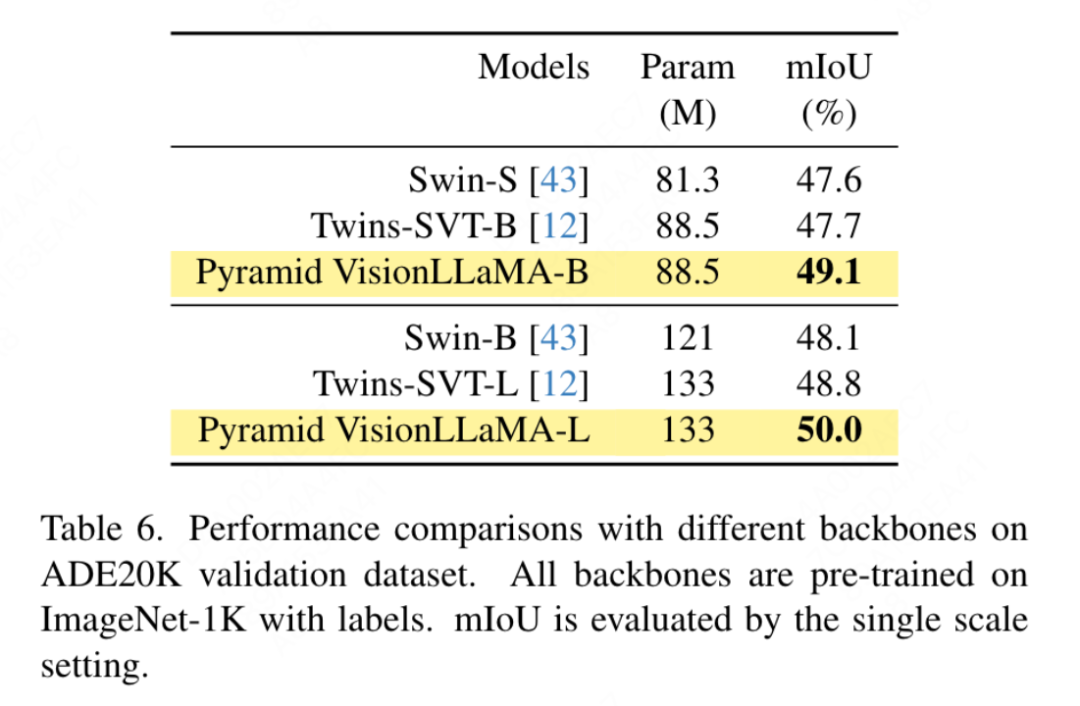
Selon les paramètres de Swin, cet article utilise la segmentation sémantique sur le Ensemble de données ADE20K pour évaluer cette méthode d'efficacité. Pour une comparaison équitable, cet article limite le modèle de base à l'utilisation d'ImageNet-1K uniquement pour la pré-formation. Cet article utilise le framework UpperNet et remplace le réseau fédérateur par la structure pyramidale VisionLLaMA. La mise en œuvre de cet article est basée sur le framework MMSegmentation. Le nombre d'étapes de formation du modèle est fixé à 160 000 et la taille globale du lot est de 16. Les résultats sont présentés dans le tableau 6. À des FLOP similaires, notre méthode surpasse Swin et Twins de plus de 1,2 % mIoU.
- Formation auto-supervisée
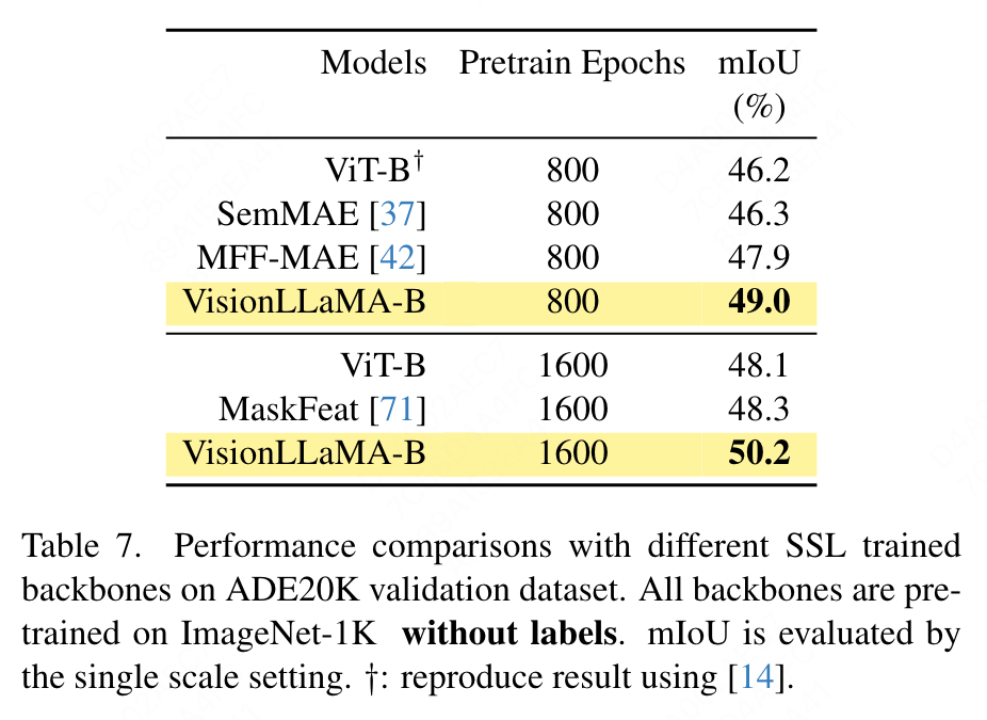
Cet article utilise le framework UpperNet pour la segmentation sémantique sur l'ensemble de données ADE20K, remplaçant le squelette ViT par VisionLLaMA tout en gardant les autres composants et hyperparamètres inchangés. La mise en œuvre de cet article est basée sur MMSegmentation et les résultats sont présentés dans le tableau 7. Pour l'ensemble de pré-formation de 800 époques, VisionLLaMA-B a considérablement amélioré ViT-Base de 2,8 % mIoU. Notre méthode est également nettement meilleure que d'autres améliorations, telles que l'introduction d'objectifs ou de fonctionnalités de formation supplémentaires, ce qui entraînerait une surcharge supplémentaire au processus de formation et réduirait la vitesse de formation. En revanche, VisionLLaMA implique uniquement le remplacement du modèle de base et a une vitesse d'entraînement rapide. Cet article évalue en outre les performances de 1 600 époques de pré-entraînement plus longues, et VisionLLaMA-B atteint 50,2 % mIoU sur l'ensemble de validation ADE20K, ce qui améliore les performances de ViT-B de 2,1 % mIoU.
Détection d'objets sur l'ensemble de données COCO
- Formation entièrement supervisée
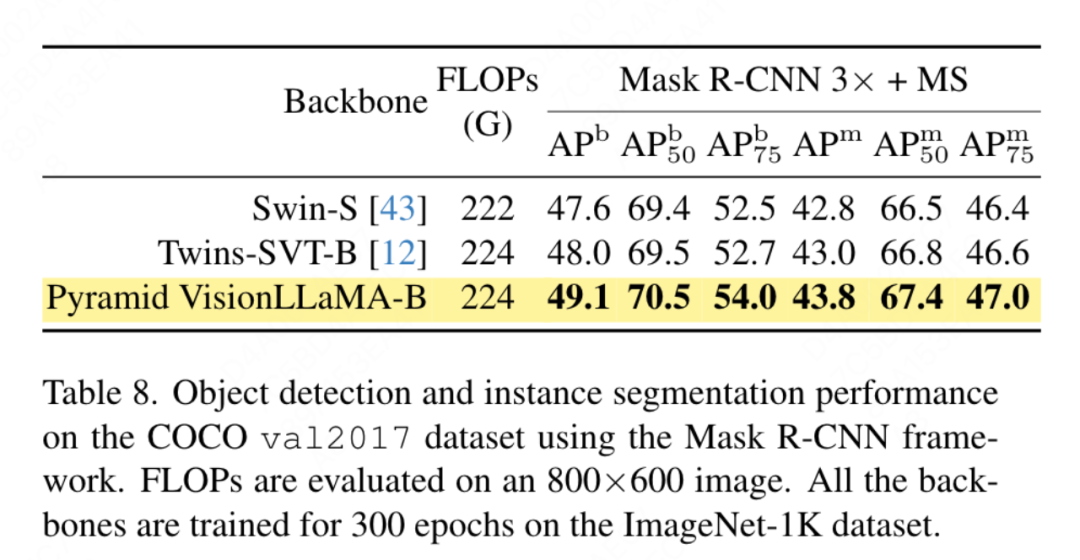
Cet article évalue les performances du VisionLLaMA structuré en pyramide sur la tâche de détection d'objets sur le COCO Ensemble de données CO . Cet article utilise le framework Mask RCNN et remplace le réseau fédérateur par un VisionLLaMA à structure pyramidale pré-entraîné sur l'ensemble de données ImageNet-1K pendant 300 époques, similaire à la configuration de Swin. Par conséquent, notre modèle a le même nombre de paramètres et de FLOP que Twins. Cette expérience peut être utilisée pour vérifier l'efficacité de cette méthode sur des tâches de détection de cibles. La mise en œuvre de cet article est basée sur le framework MMDetection. Le tableau 8 montre les résultats du cycle de formation standard de 36 époques (3×). Plus précisément, VisionLLaMA-B surpasse Swin-S de 1,5 % en boîte mAP et de 1,0 % en masque mAP. Par rapport à la base de référence plus forte Twins-B, notre méthode présente l’avantage d’un mAP de boîte 1,1 % plus élevé et d’un mAP de masque 0,8 % plus élevé.
- Formation auto-supervisée
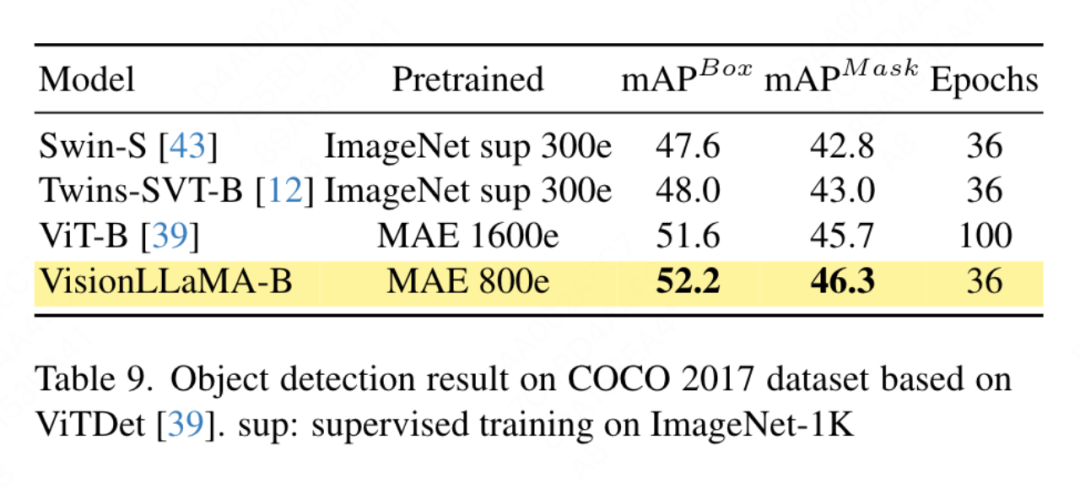
Cet article applique VisionLLaMA basé sur le cadre ViTDet, qui utilise des transformateurs de vision conventionnels pour obtenir des performances comparables au transformateur de vision à structure pyramidale correspondant. Cet article utilise le détecteur Mask RCNN et remplace le réseau fédérateur vit-Base par le modèle VisionLLaMA-Base, qui est pré-entraîné avec MAE pendant 800 époques. Le ViTDet original converge lentement et nécessite des stratégies de formation spécialisées telles que des périodes de formation plus longues pour atteindre des performances optimales. Au cours du processus de formation, cet article a révélé que VisionLLaMA atteignait des performances similaires après 30 époques. Par conséquent, cet article appliquait directement la stratégie de formation standard 3x. Le coût de formation de notre méthode ne représente que 36 % du coût de base. Contrairement aux méthodes comparées, notre méthode n’effectue pas de recherche d’hyperparamètres optimale. Les résultats sont présentés dans le tableau 9. VisionLLaMA surpasse ViT-B de 0,6 % sur la boîte mAP et de 0,8 % sur la masque mAP.
Expérience et discussion sur l'ablation
Expérience sur l'ablation
Cet article mène par défaut des expériences d'ablation sur le modèle ViT-Large, car cet article observe que ce modèle produit des résultats dans plusieurs courses La variance est faible.
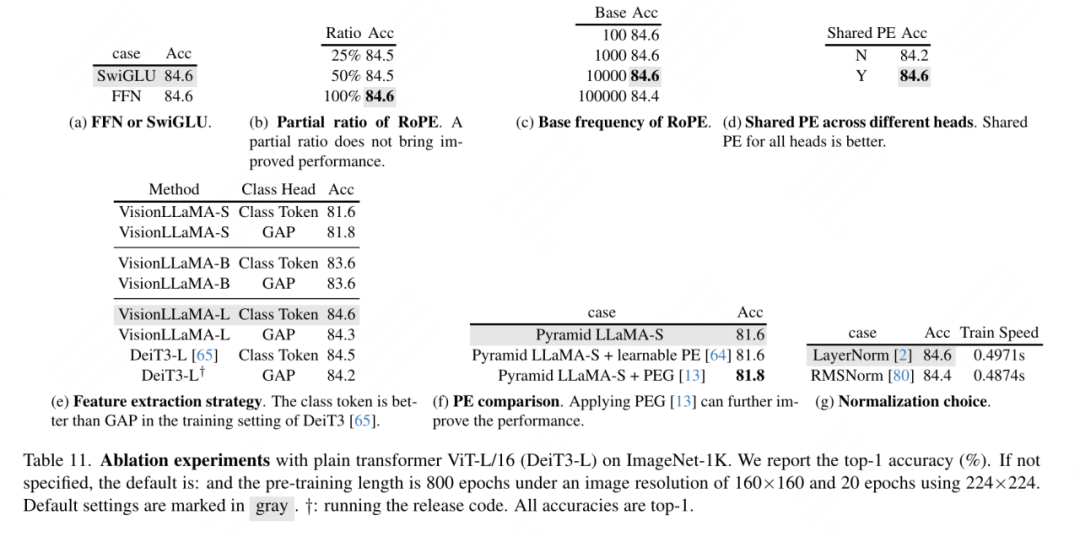
Ablation de FFN et SwiGLU : cet article remplace FFN par SwiGLU, et les résultats sont présentés dans le tableau 11a. En raison de l'écart de performances évident, cet article a choisi d'utiliser SwiGLU pour éviter d'introduire des modifications supplémentaires à l'architecture LLaMA.
Ablation de la stratégie de normalisation : cet article compare deux méthodes de normalisation largement utilisées dans les transformateurs, RMSNorm et LayerNorm, et les résultats sont présentés dans le tableau 11g. Ce dernier a de meilleures performances finales, ce qui suggère que le recentrage invariant est également important dans les tâches de vision. Cet article calcule également le temps moyen passé par itération pour mesurer la vitesse d'entraînement, où LayerNorm n'est que 2 % plus lent que RMSNorm. Par conséquent, cet article choisit LayerNorm au lieu de RMSNorm pour des performances plus équilibrées.
Codage de position partielle : cet article utilise RoPE pour ajuster le rapport de tous les canaux. Les résultats sont présentés dans le tableau 11b. Les résultats montrent que le réglage du rapport à un petit seuil peut obtenir de bonnes performances, et aucune différence significative n'est observée entre les différents. paramètres. Par conséquent, cet article conserve les paramètres par défaut dans LLaMA.
Fréquence de base : cet article modifie et compare la fréquence de base, et les résultats sont présentés dans le tableau 11c. Les résultats montrent que les performances sont robustes sur une large gamme de fréquences. Par conséquent, cet article conserve les valeurs par défaut dans LLaMA pour éviter des manipulations spéciales supplémentaires au moment du déploiement.
Encodage positionnel partagé entre chaque tête d'attention : cet article révèle que le partage du même PE entre différentes têtes (la fréquence dans chaque tête varie de 1 à 10 000) est meilleur que le PE indépendant (la fréquence dans tous les canaux varie de 1 à 10 000 changements). ), les résultats sont présentés dans le tableau 11d.
Stratégie d'abstraction de fonctionnalités : cet article compare deux stratégies d'extraction de fonctionnalités courantes sur un modèle à grande échelle de paramètres (-L) : le jeton de catégorie et GAP. Les résultats sont présentés dans le tableau 11e, qui est meilleur que GAP. est différente de la conclusion obtenue dans PEG [13]. Cependant, les paramètres de formation pour les deux méthodes sont très différents. Cet article a également mené des expériences supplémentaires en utilisant DeiT3-L et est parvenu à des conclusions similaires. Cet article évalue en outre les performances des modèles « petit » (-S) et « de base » (-B). Il est intéressant de noter que la conclusion opposée a été observée dans les petits modèles, et il y a des raisons de soupçonner que le taux de chute plus élevé utilisé dans DeiT3 rend difficile l’obtention de l’effet souhaité par les méthodes d’abstraction sans paramètres telles que GAP.
Stratégie d'encodage positionnel : cet article évalue également d'autres stratégies d'encodage positionnel absolu, telles que l'encodage positionnel apprenable et le PEG, sur la structure pyramidale VisionLLaMA-S. En raison de l'existence d'une base de référence solide, cet article utilise le « petit » modèle et les résultats sont présentés dans le tableau 11f : l'EP apprenable n'améliore pas les performances, le PEG améliore légèrement la base de référence de 81,6 % à 81,8 %. Cet article n’inclut pas le PEG comme composant essentiel pour trois raisons. Tout d'abord, cet article tente d'apporter des modifications minimes à LLaMA. Deuxièmement, le but de cet article est de proposer une approche générale pour diverses tâches telles que ViT. Pour les frameworks d'images masquées comme MAE, PEG augmente les coûts de formation et peut nuire aux performances des tâches en aval. En principe, le PEG clairsemé peut être appliqué dans le cadre MAE, mais des opérateurs peu conviviaux pour le déploiement seront introduits. La question de savoir si les convolutions clairsemées contiennent autant d’informations de position que leurs versions denses reste ouverte. Troisièmement, la conception sans modalité ouvre la voie à de nouvelles recherches portant sur d’autres modalités au-delà du texte et des visuels.
Sensibilité à la taille d'entrée : sans formation, cet article compare plus en détail les performances d'une résolution accrue et d'une résolution commune, et les résultats sont présentés dans le tableau 12. Le transformateur de structure pyramidale est utilisé ici car il est plus populaire pour les tâches en aval que la version non hiérarchique correspondante. Il n’est pas surprenant que les performances du 1D-RoPE soient gravement affectées par les changements de résolution. L'interpolation NTK-Aware avec α = 2 permet d'obtenir des performances similaires à 2D-RoPE, qui est en fait NTKAware (α = 1). AS2DRoPE démontre les meilleures performances à des résolutions plus élevées.
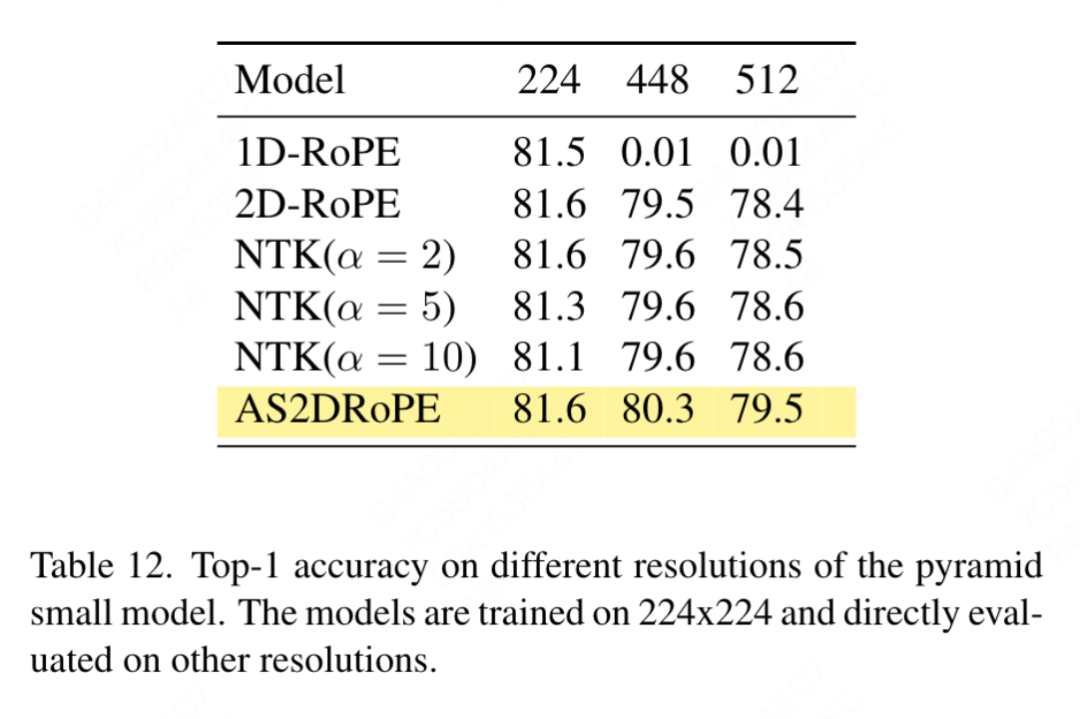
Discussion
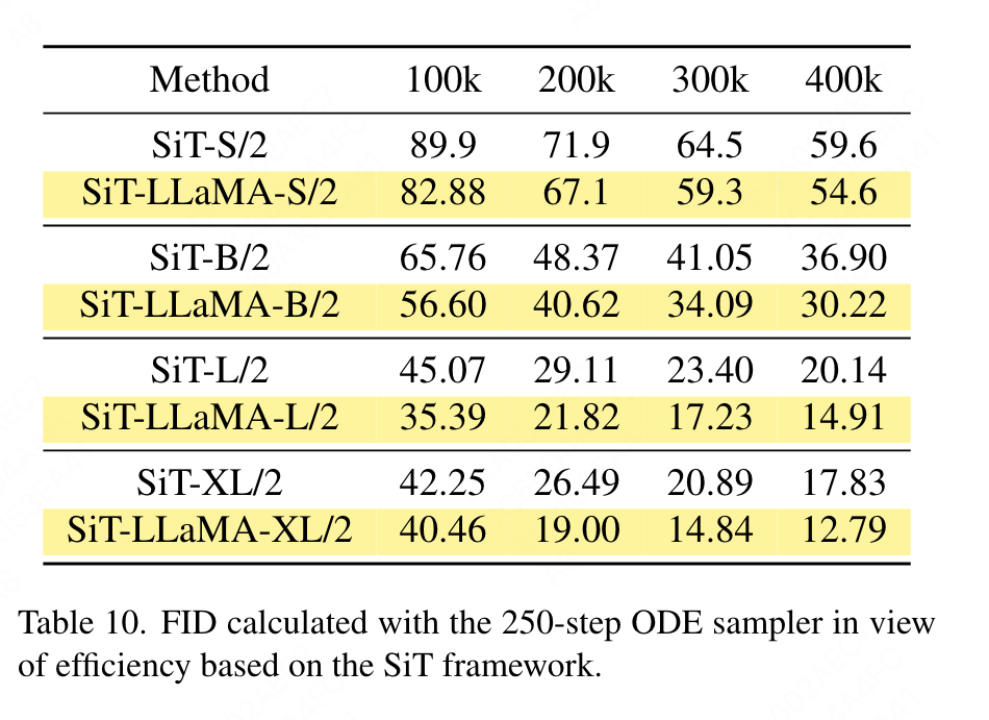
Vitesse de convergence : pour la génération d'images, cet article étudie les performances sous différentes étapes d'entraînement, en stockant des poids pour calculer l'indice de fidélité à 100k, 200k, 300k et 400k itérations. Étant donné que SDE est nettement plus lent qu’ODE, nous avons choisi d’utiliser l’échantillonneur ODE dans cet article. Les résultats du tableau 10 montrent que VisionLLaMA converge beaucoup plus rapidement que ViT sur tous les modèles. SiT-LLaMA avec 300 000 itérations de formation surpasse même le modèle de base avec 400 000 itérations de formation.
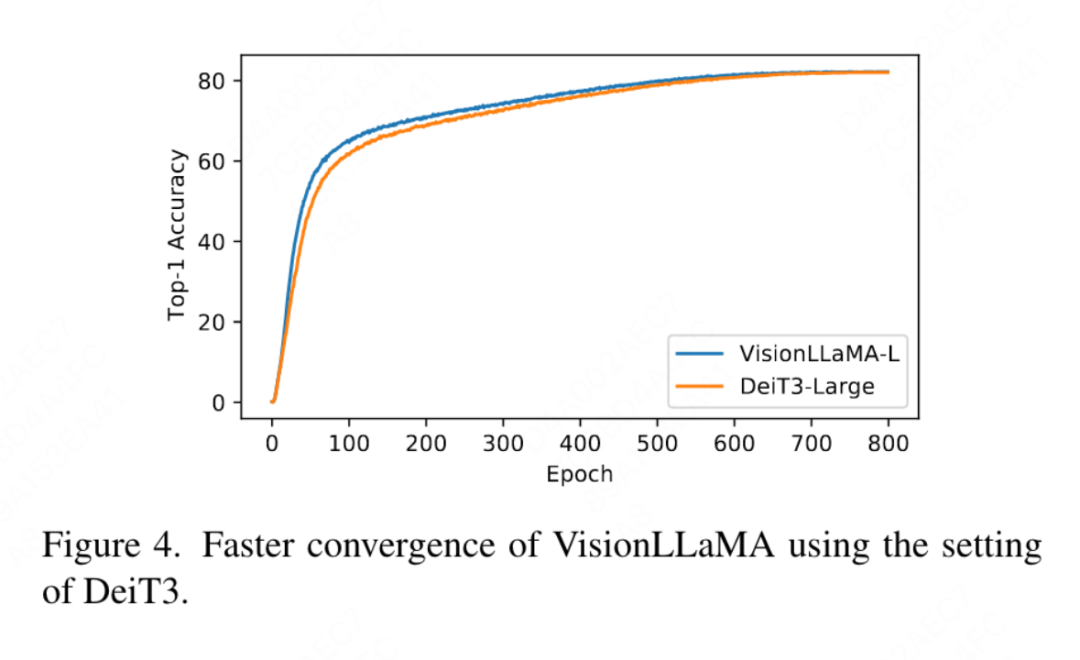
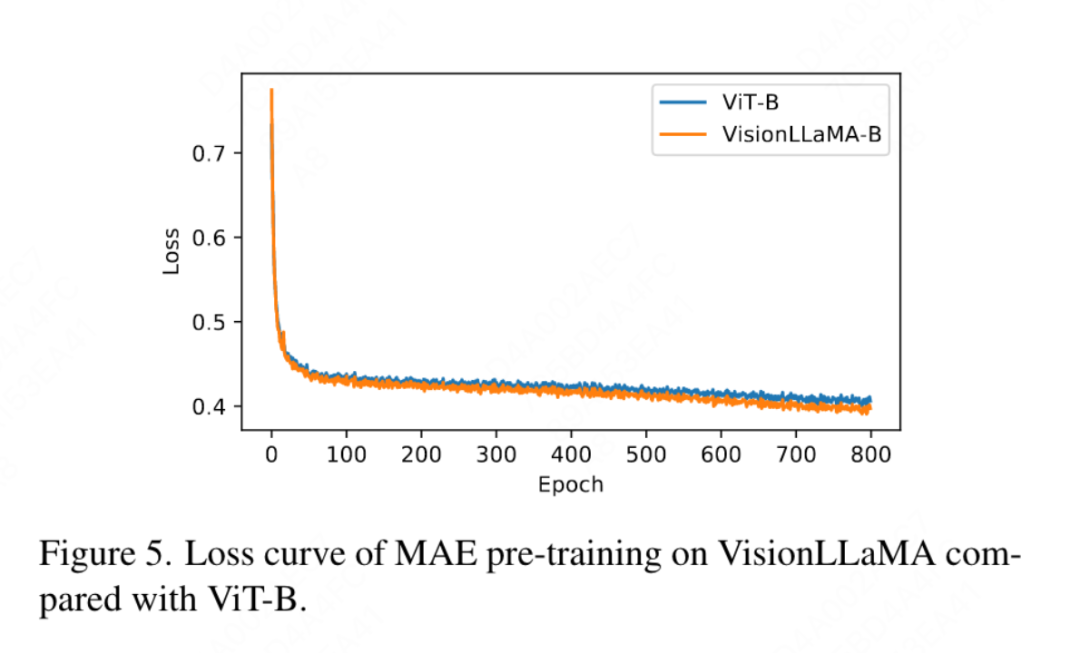
Cet article se compare également à la précision top 1 de 800 époques de formation entièrement supervisée sur ImageNet utilisant DeiT3-Large dans la figure 4, montrant que VisionLLaMA converge plus rapidement que DeiT3-L. Cet article compare en outre la perte de formation de 800 époques du modèle ViT-Base dans le cadre MAE et est illustré à la figure 5. VisionLLaMA a une perte d'entraînement plus faible au début et maintient cette tendance jusqu'à la fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tutoriel vidéo de formation pratique sur la conception fonctionnelle du système logiciel Java
- À quoi fait référence le modèle Python IPO ?
- À quelle couche du modèle osi la fonction de sélection de chemin est-elle terminée ?
- Former BERT et ResNet sur un smartphone pour la première fois, réduisant ainsi la consommation d'énergie de 35 %
- Les programmeurs sont en danger ! On dit qu'OpenAI recrute des troupes d'externalisation dans le monde entier et forme étape par étape les agriculteurs de code ChatGPT.