
Maison >Périphériques technologiques >IA >Les cartes en ligne peuvent-elles encore être ainsi ? MapTracker : Utilisez le tracking pour réaliser le nouveau SOTA des cartes en ligne !
Les cartes en ligne peuvent-elles encore être ainsi ? MapTracker : Utilisez le tracking pour réaliser le nouveau SOTA des cartes en ligne !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-25 17:01:171321parcourir
Écrit ci-dessus et compréhension personnelle de l'auteur
Cet algorithme permet la construction de cartes en ligne de haute précision. Notre méthode, MapTracker, accumule les flux de capteurs dans les mémoires tampons de deux affichages : 1) les latents raster dans l'espace Bird's Eye View (BEV) et 2) les latents vectoriels sur les éléments routiers (c'est-à-dire les passages pour piétons, les lignes de voies et les limites des routes). La méthode s'appuie sur le paradigme de propagation des requêtes dans le suivi d'objets, qui associe explicitement les éléments de route suivis de la trame précédente à la trame actuelle, tout en fusionnant un sous-ensemble de mémoire latente avec des foulées de distance pour atteindre
Lien open source : https ://map-tracker.github.io/
En résumé, les principales contributions de cet article sont les suivantes :
- Un nouvel algorithme de cartographie HD vectorielle qui formule la cartographie HD comme une tâche de suivi, et Exploitation de l'historique de la mémoire latentes dans les deux représentations pour obtenir une cohérence temporelle ;
- Un benchmark de cartographie HD vectorielle amélioré avec des performances GT cohérentes dans le temps et mAP sensibles à la cohérence ; Améliorations significatives par rapport aux meilleures méthodes actuelles sur les métriques traditionnelles et nouvelles.
Cet article utilise deux façons de réfléchir et de résoudre le problème de cartographie HD vectorielle cohérente. Nous passons d’abord en revue les dernières tendances en matière de suivi visuel d’objets à l’aide de transformateurs et de conceptions de mémoire dans la conduite autonome basée sur la vision. Enfin, nous discutons des méthodes concurrentes de cartographie vectorielle HD.
Utilisez des transformateurs pour le suivi visuel des objets. Le suivi visuel des objets a une longue histoire, parmi laquelle les méthodes de transformation de bout en bout sont devenues une tendance récente en raison de leur simplicité. TrackFormer, TransTrack et MOTR exploitent les mécanismes d'attention et les requêtes de suivi pour corréler explicitement les instances entre les trames. MeMOT et MeMOTR étendent encore le transformateur de suivi avec un mécanisme de mémoire pour une meilleure cohérence à long terme. Cet article formule le mappage HD vectoriel comme une tâche de suivi en combinant des requêtes de suivi avec un mécanisme de mémoire plus robuste.
Conception de mémoire dans la conduite autonome. Les systèmes de conduite autonome à châssis unique ont des difficultés à gérer les occlusions, les pannes de capteurs ou les environnements complexes. La modélisation temporelle avec Memory constitue un ajout prometteur. Il existe de nombreuses conceptions de mémoire pour les fonctions BEV en réseau qui constituent la base de la plupart des tâches de conduite autonome. BEVDet4D et BEVFormerv2 superposent les caractéristiques de plusieurs images passées dans la mémoire, mais le calcul se développe linéairement avec la longueur de l'historique, ce qui rend difficile la capture d'informations à long terme. VideoBEV propage les requêtes raster BEV à travers les images pour accumuler des informations en boucle. Dans le domaine vectoriel, Sparse4Dv2 utilise une mémoire de style RNN similaire pour les requêtes cibles, tandis que Sparse4Dv3 utilise en outre le débruitage temporel pour un apprentissage temporel robuste. Ces idées ont été partiellement intégrées aux méthodes de cartographie vectorielle HD. Cet article propose une nouvelle conception de mémoire pour la latence du réseau BEV et la latence vectorielle des éléments routiers.
Cartographie vectorielle HD. Traditionnellement, les cartes de haute précision sont reconstruites hors ligne à l'aide de méthodes basées sur SLAM, puis gérées manuellement, ce qui nécessite des coûts de maintenance élevés. Avec l'amélioration de la précision et de l'efficacité, les algorithmes de cartes vectorielles en ligne de haute précision ont attiré plus d'attention que les algorithmes de cartes hors ligne, ce qui simplifiera le processus de production et gérera les modifications des cartes. HDMapNet convertit la segmentation d'images raster en instances d'images vectorielles via un post-traitement et a établi la première référence de cartographie vectorielle HD. VectorMapNet et MapTR utilisent des transformateurs basés sur DETR pour une prédiction de bout en bout. Le premier prédit de manière autorégressive les sommets de chaque courbe détectée, tandis que le second utilise une requête hiérarchique et une perte de correspondance pour prédire tous les sommets simultanément. MapTRv2 complète en outre MapTR avec des tâches auxiliaires et des modifications du réseau. La représentation des courbes, la conception des réseaux et les paradigmes de formation sont au centre d'autres travaux. StreamMapNet fait un pas en avant vers une cartographie cohérente en s'appuyant sur l'idée de flux dans la perception BEV. L'idée est d'accumuler des informations passées dans la mémoire latente et de les transmettre sous forme de conditions (c'est-à-dire un cadre de détection de conditions). SQD MapNet imite DN-DETR et propose un débruitage de courbe temporelle pour favoriser l'apprentissage temporel.
MapTracker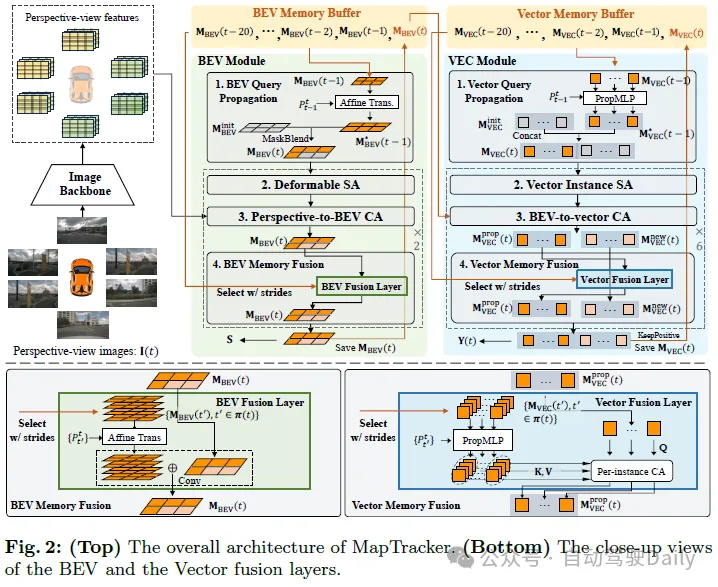 Le mécanisme de mémoire robuste est au cœur de MapTracker, qui accumule les flux de capteurs dans des mémoires latentes représentées par deux représentations : 1) Une vue plongeante de haut en bas de la zone autour du véhicule dans le une mémoire du système de coordonnées BEV (BEV) en tant qu'image latente ; et 2) une mémoire vectorielle (VEC) d'éléments routiers (c'est-à-dire des intersections pour piétons, des lignes de voies et des limites de route) en tant qu'ensemble de quantités latentes.
Le mécanisme de mémoire robuste est au cœur de MapTracker, qui accumule les flux de capteurs dans des mémoires latentes représentées par deux représentations : 1) Une vue plongeante de haut en bas de la zone autour du véhicule dans le une mémoire du système de coordonnées BEV (BEV) en tant qu'image latente ; et 2) une mémoire vectorielle (VEC) d'éléments routiers (c'est-à-dire des intersections pour piétons, des lignes de voies et des limites de route) en tant qu'ensemble de quantités latentes.
Deux idées simples et le mécanisme de mémoire permettent d'obtenir une cartographie cohérente. La première idée est d'utiliser une mémoire tampon historique au lieu d'une seule mémoire pour la trame actuelle. Une seule mémoire devrait contenir des informations sur l'ensemble de l'historique, mais il est facile de perdre de la mémoire, en particulier dans des environnements encombrés où un grand nombre de véhicules bloquent les structures routières. Plus précisément, pour des raisons d'efficacité et de couverture, nous sélectionnons un sous-ensemble de mémoires latentes passées à fusionner à chaque image en fonction du mouvement du véhicule. La deuxième idée est de formuler des cartes HD en ligne comme tâches de suivi. Le mécanisme de mémoire VEC maintient la séquence de mémoire latente pour chaque élément routier et simplifie cette formulation en empruntant le paradigme de propagation des requêtes à la littérature de suivi. Le reste de cette section explique notre architecture neuronale (voir les figures 2 et 3), y compris les tampons de mémoire BEV et VEC et leurs modules réseau correspondants, puis présente les détails de la formation.
Memory Buffers
La mémoire BEV est une 2D latente dans le système de coordonnées BEV, centrée sur le véhicule et orientée au niveau du cadre. La dimension spatiale (soit 50×100) couvre une zone rectangulaire, 15 m gauche/droite et 30 m avant/arrière. Chaque latence mémoire accumule l'intégralité des informations passées et le tampon maintient ces latentes mémoire dans les 20 dernières images, rendant le mécanisme de mémoire redondant mais robuste.
VECmemory est un ensemble de latences vectorielles, chaque latence vectorielle accumule des informations sur les éléments routiers actifs jusqu'à l'image t. Le nombre d'éléments actifs change d'une image à l'autre. Le tampon contient les vecteurs latents des 20 dernières trames et leur correspondance entre les trames (c'est-à-dire la séquence latente de vecteurs correspondant au même élément routier).
Module BEV

Les entrées sont 1) les caractéristiques CNN de l'image surround aéroportée et ses paramètres de caméra traités par la structure de l'image 2) la mémoire tampon BEV et 3) le mouvement du véhicule. Ce qui suit explique les quatre composants de l'architecture du module BEV et leurs sorties.
- Propagation des requêtes BEV : la mémoire BEV est une image latente 2D dans le système de coordonnées du véhicule. La transformation affine et l'interpolation bilinéaire initialisent la mémoire BEV actuelle à la mémoire BEV précédente. Pour les pixels situés en dehors de l'image latente après transformation, le vecteur d'intégration apprenable de chaque pixel est initialisé et son fonctionnement est représenté par « MaskBlend » sur la figure 3.
- Auto-attention déformable : la couche d'auto-attention déformable enrichit la mémoire BEV.
- Attention croisée perspective-BEV : similaire à StreamMapNet, la couche d'attention croisée spatialement déformable de BEVFormer injecte des informations de perspective dans MBEV(t).
- BEV Memory Fusion : La mémoire latente dans le tampon est fusionnée pour enrichir MBEV(t). L’utilisation de toutes les mémoires est coûteuse en calcul et redondante.
Le résultat est 1) la mémoire finale MBEV(t) enregistrée dans le tampon et transmise au module VEC ; et 2) la géométrie rastérisée de l'élément routier S(t) déduite par la tête de segmentation et utilisée pour les calculs de perte. La tête de segmentation est un module de projection linéaire qui projette chaque pixel de la mémoire latente sur un masque de segmentation 2×2, ce qui donne un masque 100×200.
Module VEC
L'entrée est la mémoire BEV MBEV(t) et le tampon de mémoire vectorielle et le mouvement du véhicule ;
- Propagation des requêtes vectorielles : la mémoire vectorielle est un ensemble de vecteurs potentiels d'éléments routiers actifs.
- Vector Instance Self Attention : couche d'auto-attention standard ;
- BEV-to-Vector Cross Attention : attention multipoint ;
- Vector Memory Fusion : pour chaque vecteur potentiel de la mémoire actuelle MVEC (t), vecteurs latents associés. avec les mêmes éléments routiers dans le tampon sont fusionnés pour enrichir leur représentation. La même sélection de trame de foulée sélectionne quatre vecteurs potentiels, où pour certains éléments de route ayant un historique de suivi court, les trames sélectionnées π(t) seront différentes et inférieures. Par exemple, un élément suivi pendant deux images n'a que deux latentes dans le tampon.
Le résultat est 1) la mémoire finale des éléments routiers « positifs » testés par classification à partir d'une seule couche entièrement connectée de MVEC(t) et 2) régressée par un MLP à 3 couches de la géométrie routière vectorielle MVEC(t) ; avec des éléments routiers positifs.
Entraînement
Perte BEV :
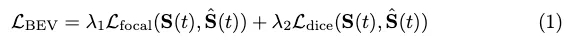
Perte VEC. Inspirés par MOTR, un transformateur de bout en bout pour le suivi multi-objets, nous étendons la perte basée sur la correspondance pour prendre explicitement en compte le suivi GT. L'attribution optimale d'étiquettes au niveau de l'instance pour les nouveaux éléments est définie comme :
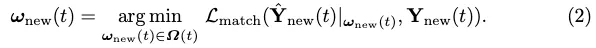
Ensuite, l'attribution d'étiquettes ω(t) entre toutes les sorties et GT est définie de manière inductive :
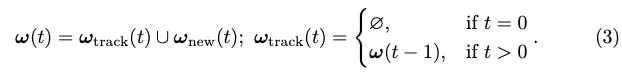
La perte de style de suivi pour la sortie vectorielle est :
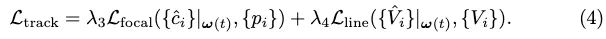
Perte de conversion. Nous empruntons la perte de transformation Ltrans à StreamMapNet pour entraîner PropMLP, qui force les transformations de requêtes dans l'espace latent pour préserver la géométrie vectorielle et les types de classe. La perte finale de formation est la suivante :
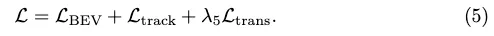
Benchmarks de cartographie HD vectorielle cohérents
Vérité terrain cohérente
MapTR a créé des références de cartographie HD vectorielles à partir des ensembles de données nuScenes et Agroverse2, qui ont été adoptés par de nombreuses études ultérieures. Cependant, les passages pour piétons sont naïvement fusionnés et incohérents d’une image à l’autre. La ligne de démarcation est également incompatible avec l’échec de son processus de suivi graphique (pour Argoverse2).
StreamMapNet hérite du code de VectorMapNet et crée un benchmark avec un meilleur réalisme qui a été utilisé dans le défi de l'atelier. Toutefois, certains problèmes demeurent. Pour Argoverse2, les diviseurs sont parfois divisés en segments plus courts. Pour nuScenes, de grands passages pour piétons segmentent parfois de petites boucles, dont les incohérences apparaissent de manière aléatoire dans chaque image, ce qui entraîne des représentations temporairement incohérentes. Nous fournissons des visualisations des problèmes de référence existants en annexe.
Nous avons amélioré le code de traitement de la ligne de base existante pour (1) améliorer la géométrie GT de chaque cadre puis (2) calculer leur correspondance entre les cadres pour former une « trajectoire » GT.
(1) Améliorez chaque géométrie du cadre. Nous avons hérité et amélioré la base de code MapTR populaire dans la communauté tout en apportant deux modifications : remplacer le traitement des zones de marche par le traitement dans StreamMapNet et améliorer la qualité avec plus de contraintes géométriques et améliorer l'algorithme de suivi des graphiques pour gérer le bruit des annotations d'origine afin d'améliorer la cohérence temporelle dans ; traitement des diviseurs (Argoverse2 uniquement).
(2) Former des pistes. Compte tenu de la géométrie des éléments routiers dans chaque cadre, nous résolvons le problème de correspondance bipartie optimale entre chaque paire de cadres adjacents pour établir la correspondance entre les éléments routiers. Des couples de correspondances s'enchaînent pour former des trajectoires d'éléments routiers. Le score de correspondance entre une paire d’éléments routiers est défini comme suit. La géométrie des éléments routiers est une courbe ou une boucle polygonale. Nous convertissons la géométrie des éléments de l'ancien cadre vers le nouveau cadre en fonction du mouvement du véhicule, puis pixellisons deux courbes/boucles d'une certaine épaisseur en masques d'instance. Leur intersection sur l’union constitue le score correspondant.
Métrique mAP sensible à la cohérence
La métrique mAP ne pénalise pas les reconstructions temporairement incohérentes. Nous faisons correspondre les éléments routiers reconstruits et la vérité terrain dans chaque image indépendamment avec les distances de chanfrein, comme dans la procédure mAP standard, puis éliminons temporairement les correspondances incohérentes via les vérifications suivantes. Premièrement, pour la méthode de base qui ne prédit pas les informations de suivi, nous utilisons le même algorithme que celui utilisé pour obtenir la correspondance temporelle GT afin de former des trajectoires d'éléments routiers reconstruits (nous étendons également l'algorithme pour réidentifier les éléments manquants en échangeant la vitesse ; voir pour détails en annexe). Supposons ensuite que les « ancêtres » soient les éléments routiers qui appartiennent à la même trajectoire dans le cadre précédent. Dès le début de la séquence, nous supprimons chaque correspondance de trame (élément reconstruit et élément de vérité terrain) comme temporairement incohérentes si l'un de leurs ancêtres ne correspond pas. Les correspondances temporellement cohérentes restantes sont ensuite utilisées pour calculer le mAP standard.
Expériences
Nous avons construit notre système basé sur la base de code StreamMapNet tout en entraînant notre modèle sur nuScenes pendant 72 époques et Argoverse2 pendant 35 époques en utilisant 8 GPU NVIDIA RTX A5000. Les tailles de lots pour les trois étapes de formation sont respectivement de 16, 48 et 16. La formation prend environ trois jours et la vitesse d'inférence est d'environ 10 FPS. Après avoir expliqué l'ensemble de données, les métriques et les méthodes de base, cette section fournit des résultats expérimentaux.
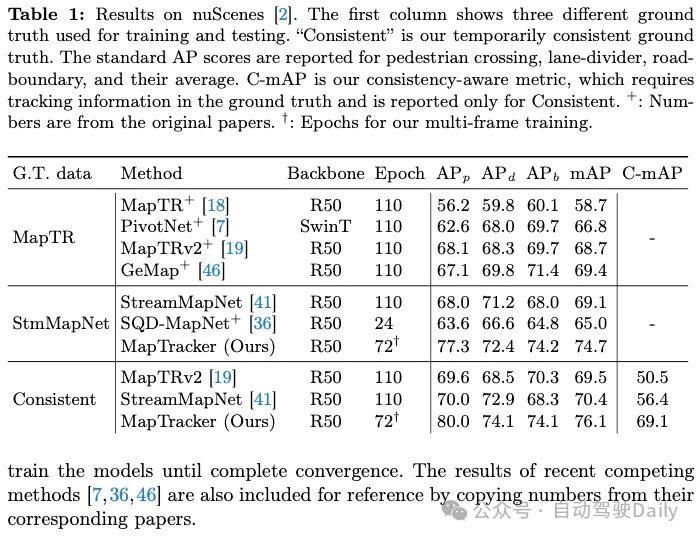
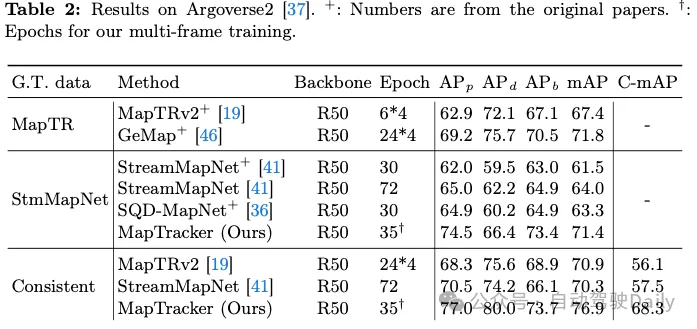
L'une de nos contributions est d'obtenir une vérité terrain (GT) temporellement cohérente sur deux homologues existants, à savoir MapTR et StreamMapNet. Les tableaux 1 et 2 montrent les résultats de la formation et des tests du système sur l'un des trois GT (indiqués dans la première colonne). Puisque notre base de code est basée sur StreamMapNet, nous évaluons notre système sur StreamMapNet GT et notre GT cohérent ad hoc.
résultats nuScenes. Le tableau 1 montre que MapTRv2 et StreamMapNet obtiennent un meilleur mAP en utilisant notre GT, ce à quoi nous nous attendions en corrigeant l'incohérence dans leur GT d'origine. L'amélioration de StreamMapNet est légèrement supérieure car il dispose d'une modélisation temporelle (contrairement à MapTR) et exploite la cohérence temporelle des données. MapTracker surpasse considérablement les méthodes concurrentes, d'autant plus que notre GT cohérent s'améliore respectivement de plus de 8 % et 22 % en termes de scores mAP bruts et sensibles à la cohérence. Notez que MapTracker est le seul système qui produit des informations de suivi explicites (c'est-à-dire la reconstruction de la correspondance des éléments entre les images), nécessaires à la région de cohérence mAP. Un algorithme de correspondance simple crée des trajectoires pour la méthode de base.
Résultats Argoverse2. Le tableau 2 montre que MapTRv2 et StreamMapNet obtiennent de meilleurs scores mAP avec notre GT cohérent, qui en plus d'être cohérent dans le temps, a également un GT de meilleure qualité (pour les passages pour piétons et les diviseurs), bénéficiant à toutes les méthodes. MapTracker surpasse toutes les autres références dans tous les contextes avec une marge significative (c'est-à-dire 11 % ou 8 %, respectivement). Le Consistency Awareness Score (C-mAP) démontre en outre notre cohérence supérieure, s'améliorant de plus de 18 % par rapport à StreamMapNet.
Résultats avec des données géographiquement non chevauchantes
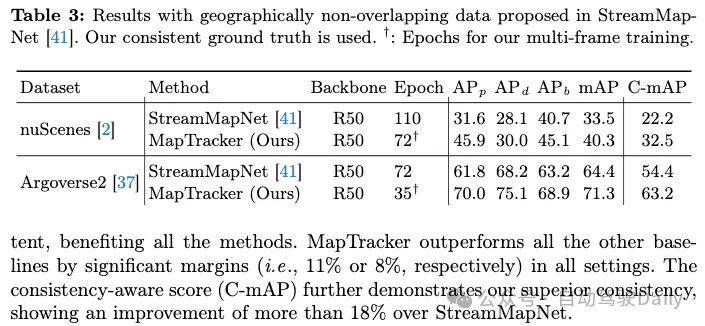
La répartition officielle train/test des ensembles de données nuScenes et Agroverse2 a un chevauchement géographique (c'est-à-dire que les mêmes routes apparaissent dans train/test), ce qui permet un surajustement. Le tableau 3 compare les meilleures méthodes de base proposées par StreamMapNet et MapTracker basées sur une segmentation géographiquement sans chevauchement. MapTracker fonctionne systématiquement bien, avec une marge significative, démontrant de solides capacités de généralisation entre scénarios. Notez que pour les deux méthodes, les performances sur l'ensemble de données nuScenes seront réduites. Après une inspection minutieuse, la détection des éléments routiers est réussie, mais les erreurs de coordonnées de la régression sont importantes, ce qui entraîne de mauvaises performances. L’annexe fournit une analyse supplémentaire.
Études d'ablation
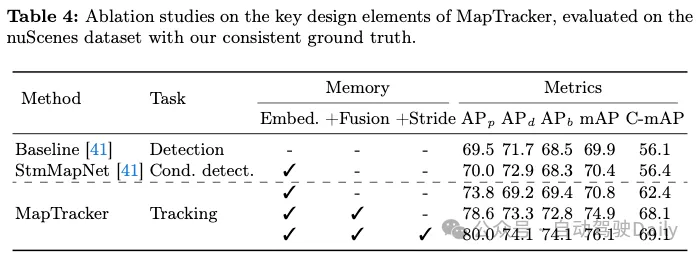
Les études d'ablation du tableau 4 démontrent la contribution des éléments de conception clés dans MapTracker. La première entrée « de base » est StreamMapNet, qui n'a aucune capacité d'inférence temporelle (c'est-à-dire pas de mémoire et de modules BEV et de flux vectoriel). La deuxième entrée est StreamMapNet. Les deux méthodes ont été entraînées pendant 110 époques jusqu'à convergence complète. Les trois dernières entrées sont des variantes de MapTracker, avec ou sans éléments de conception clés. La première variante supprime le composant de fusion de mémoire dans le module BEV/VEC. Cette variante utilise des formules de suivi mais s'appuie sur une seule mémoire BEV/VEC pour conserver les informations passées. La deuxième variante ajoute un tampon mémoire et un composant de fusion de mémoire, mais sans foulée, c'est-à-dire en utilisant les 4 dernières images pour la fusion. Cette variante améliore les performances et démontre l'efficacité de notre mécanisme de mémoire. La dernière variante ajoute des progrès en mémoire, permettant une utilisation plus efficace du mécanisme de mémoire et améliorant les performances.
Évaluations qualitatives

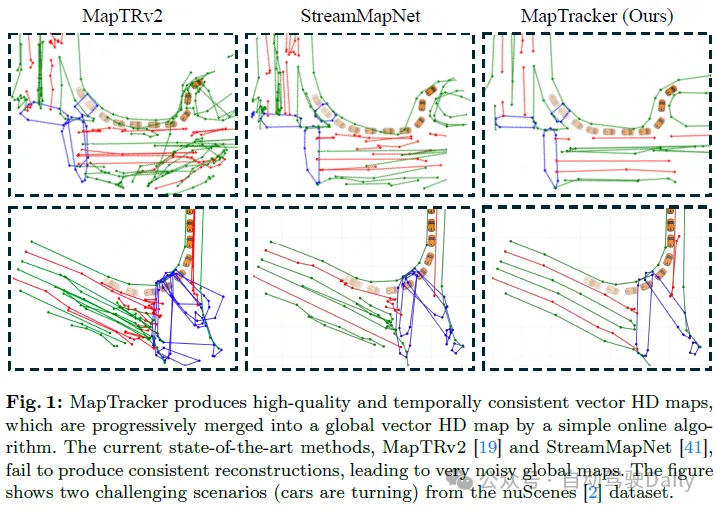
La figure 4 montre la comparaison qualitative de MapTracker et des méthodes de base sur les ensembles de données nuScenes et Argoverse2. Pour une meilleure visualisation, nous utilisons un algorithme simple pour fusionner chaque carte HD vectorielle image dans une carte HD vectorielle globale. Voir l'annexe pour plus de détails sur l'algorithme de fusion et la visualisation de chaque reconstruction de trame. MapTracker a produit des résultats plus précis et plus propres, montrant une qualité globale et une cohérence temporelle supérieures. Pour les scénarios dans lesquels le véhicule tourne ou n'avance pas légèrement (y compris les deux exemples de la figure 1), StreamMapNet et MapTRv2 peuvent produire des résultats instables, entraînant des résultats fusionnés brisés et bruyants. Cela est principalement dû au fait que les formulations basées sur la détection ont du mal à maintenir une reconstruction temporellement cohérente sous des mouvements complexes de véhicules.
Conclusion
Cet article présente MapTracker, qui formule la cartographie HD en ligne comme une tâche de suivi et exploite l'historique des latents raster et vectoriels pour maintenir la cohérence temporelle. Nous utilisons un mécanisme de propagation de requêtes pour associer les éléments de route suivis à travers les images et fusionnons un sous-ensemble sélectionné d'entrées de mémoire avec des foulées de distance pour améliorer la cohérence. Nous améliorons également les références existantes en générant des GT cohérents à l'aide d'étiquettes de suivi et en améliorant la métrique brute mAP avec des contrôles de cohérence temporelle. MapTracker surpasse considérablement les méthodes existantes sur les ensembles de données nuScenes et Agroverse2 lorsqu'il est évalué à l'aide de métriques traditionnelles, et démontre une cohérence temporelle supérieure lorsqu'il est évalué à l'aide de nos métriques soucieuses de la cohérence.
Limitations : Nous avons identifié deux limitations de MapTracker. Premièrement, la formulation de suivi actuelle ne gère pas la fusion et la division des éléments de route (par exemple, une limite en forme de U est divisée en deux lignes droites dans les futurs cadres, et vice versa). Les faits de base ne les représentent pas non plus de manière appropriée. Deuxièmement, notre système est toujours à 10 FPS et les performances en temps réel font un peu défaut, notamment lors de crashs critiques. L’optimisation de l’efficacité et la gestion de structures routières réelles plus complexes sont nos travaux futurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment vérifier quel est le mot de passe git
- Comment supprimer une branche dans git
- Comment annuler un commit git
- Comment installer git sur mac ? Explication détaillée de deux méthodes
- Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !