Snowflake rejoint la mêlée LLM.
Snowflake lance le modèle Arctic de haute « intelligence d'entreprise », axé sur les applications internes de l'entreprise. Tout à l'heure, le fournisseur de gestion de données et d'entrepôts Snowflake a annoncé avoir rejoint la mêlée LLM et publié un modèle de langage étendu (LLM) de haut niveau axé sur les applications de niveau entreprise - Snowflake Arctic. En tant que LLM lancé par une société de cloud computing, Arctic présente principalement les deux avantages suivants :
- Intelligence efficace : Arctic fonctionne bien dans les tâches d'entreprise, telles que la génération SQL, la programmation et le suivi d'instructions. , même comparable aux modèles open source entraînés avec des coûts de calcul plus élevés. Arctic établit une nouvelle référence en matière de formation rentable, permettant aux clients de Snowflake de créer des modèles personnalisés de haute qualité à faible coût pour les besoins de leur entreprise.
- Open source : Arctic adopte la licence Apache 2.0, offrant un accès ouvert aux poids et au code, et Snowflake ouvrira également toutes les solutions de données et les résultats de recherche en open source.
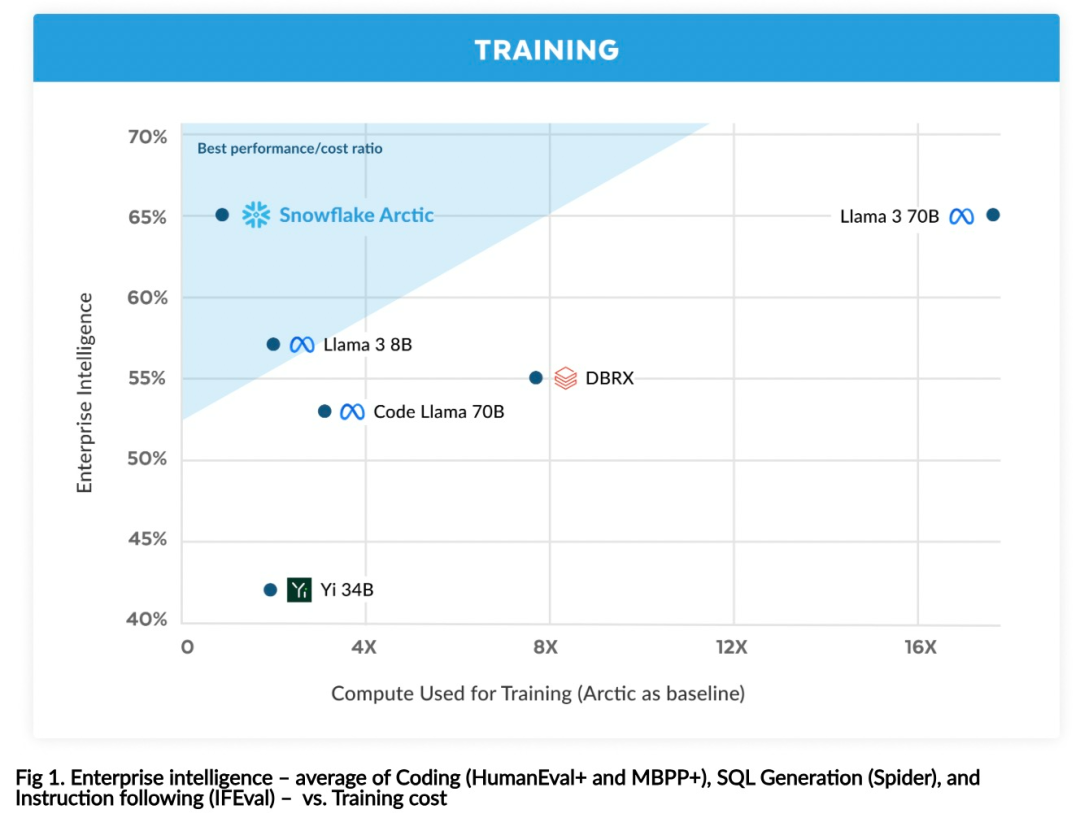
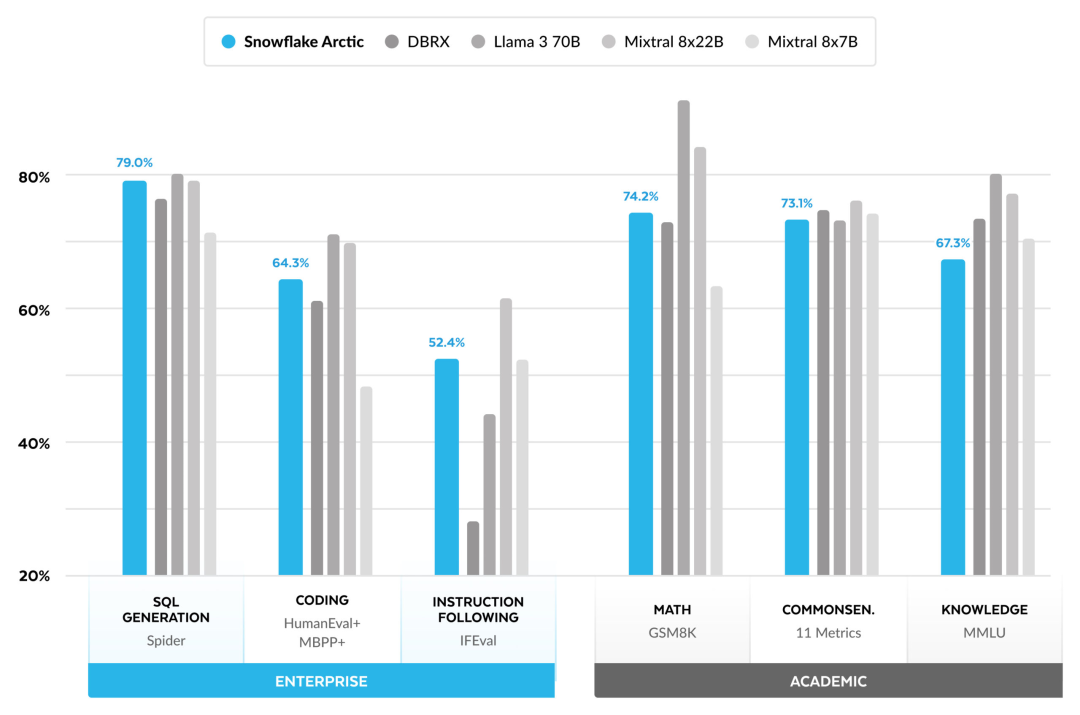
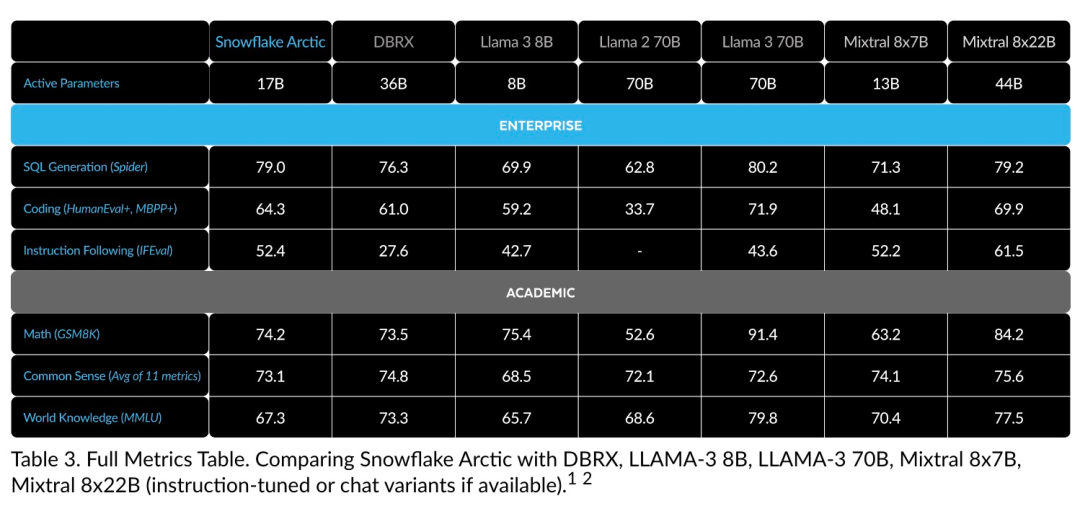
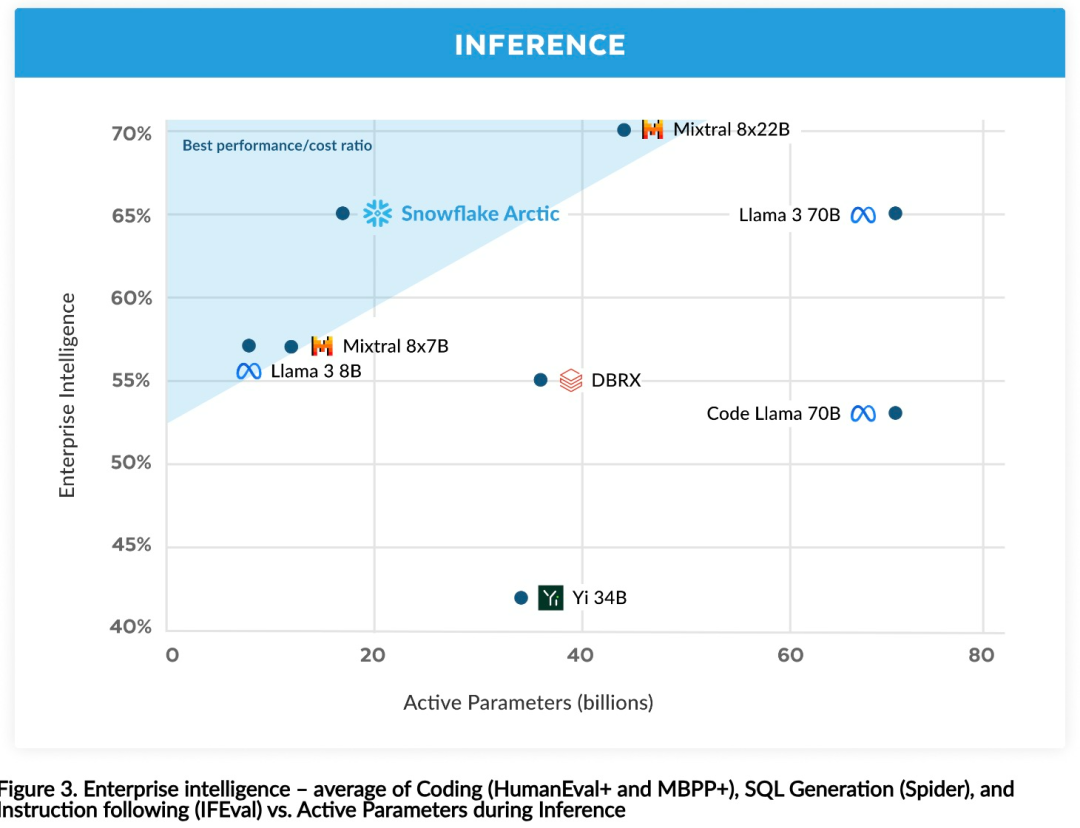
Vous pouvez désormais accéder au modèle Arctique sur Hugging Face. Snowflake a déclaré : Les utilisateurs pourront bientôt l'obtenir via un certain nombre de bibliothèques de modèles, notamment Snowflake Cortex, AWS, Microsoft Azure, NVIDIA API, Lamini, Perplexity, Replicate et Together, etc. Hugging Face : https://huggingface.co/Snowflake/snowflake-arctic-instructLa fenêtre contextuelle d'Arctic est réglée sur 4K et l'équipe de recherche développe une fenêtre coulissante basée sur le récepteur d'attention. la mise en œuvre prendra en charge la génération illimitée de séquences dans les semaines à venir et sera étendue à 32 000 fenêtres d'attention dans un avenir proche. Hautes performances, faible coûtL'équipe de recherche de Snowflake a constaté un modèle cohérent parmi les besoins en IA et les cas d'utilisation des entreprises clientes : les entreprises souhaitent utiliser LLM pour créer un copilote de données SQL conversationnel, du code chatbots copilote et RAG. Cela signifie que le LLM doit exceller en SQL, en code, en suivant des instructions complexes et en générant des réponses concrètes. Snowflake combine ces fonctionnalités en une seule métrique appelée « Enterprise Intelligence » en faisant la moyenne des niveaux de performances d'encodage (HumanEval+ et MBPP+), de génération SQL (Spider) et de suivi d'instructions (IFEval). Arctic atteint le plus haut niveau de « l'intelligence d'entreprise » dans le LLM open source, et le fait pour environ moins de 2 millions de dollars en coût de calcul de formation (moins de 3 000 semaines de GPU). Cela signifie qu'Arctic est plus performant que d'autres modèles open source entraînés avec des coûts de calcul similaires. Plus important encore, Arctic excelle en matière d'intelligence d'entreprise, même par rapport aux modèles entraînés avec des coûts de calcul beaucoup plus élevés. L’efficacité élevée de la formation d’Arctic signifie que les clients de Snowflake et la communauté IA dans son ensemble peuvent former des modèles personnalisés de manière plus rentable. Comme le montre la figure 1, Arctic est à égalité avec LAMA 3 8B et LAMA 2 70B en termes de mesures d'intelligence d'entreprise tout en utilisant moins de la moitié du coût de calcul de la formation. Et, bien qu'il utilise seulement 1/17 fois le coût de calcul, Arctic est comparable à Llama3 70B dans des indicateurs tels que l'encodage (HumanEval+ et MBPP+), SQL (Spider) et le suivi des instructions (IFEval), c'est-à-dire qu'Arctic maintient sa compétitivité globale en termes de performances. j'ai fait ça en même temps. De plus, Snowflake a également évalué Arctic sur la base de critères académiques, impliquant la connaissance du monde, le raisonnement de bon sens et les capacités mathématiques. Les résultats complets de l'évaluation sont présentés dans la figure ci-dessous : .
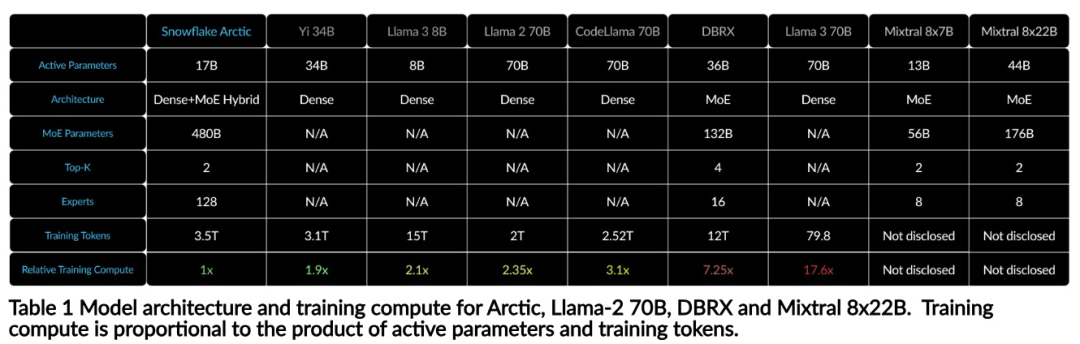
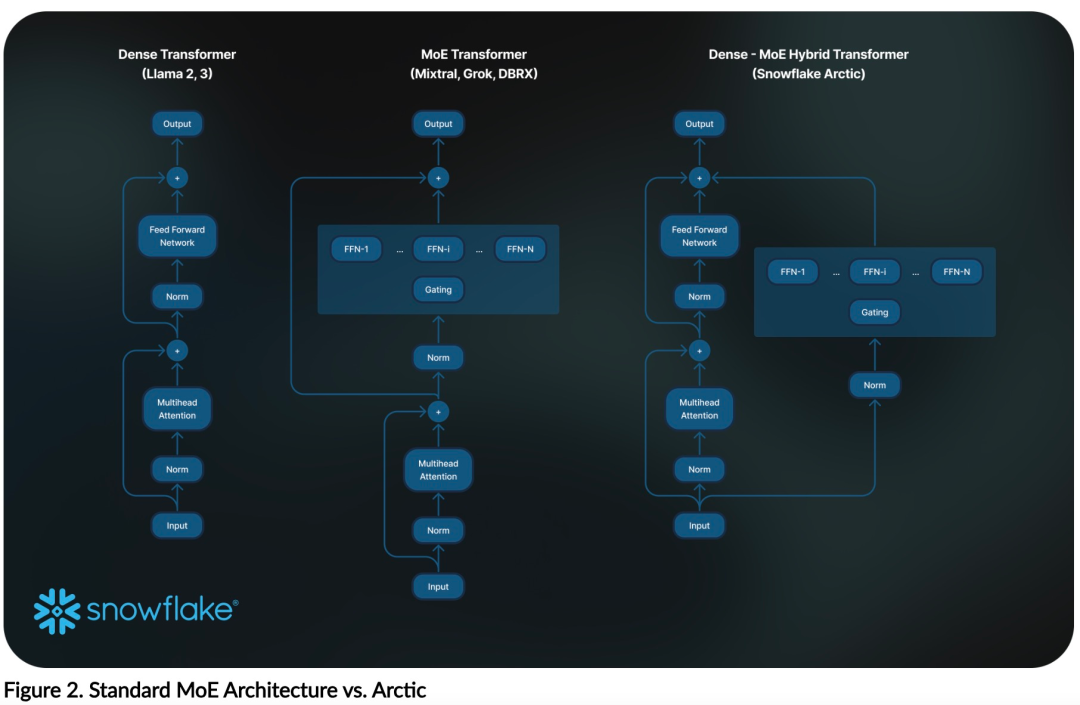
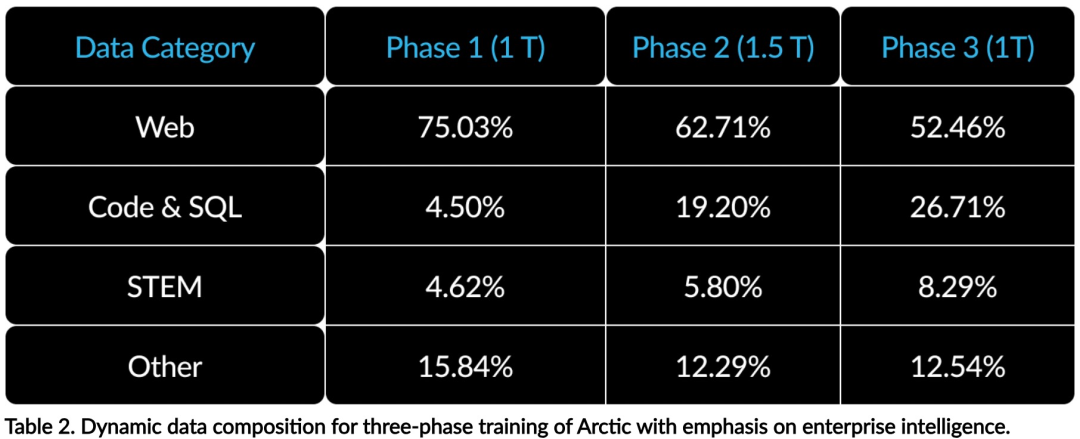
Efficacité de la formationAfin d'atteindre l'efficacité de la formation ci-dessus, Arctic utilise une architecture de transformateur hybride Dense-MoE unique. Il combine un modèle de transformateur dense 10B avec un MLP MoE résiduel de 128 × 3,66B, avec un total de 480B paramètres et 17B paramètres actifs, en utilisant les 2 premiers déclenchements pour la sélection.Lors de la conception et de la formation d'Arctic, l'équipe de recherche a utilisé les trois idées et innovations clés suivantes : Experts du MoE et technologie de compression Fin 2021, l'équipe DeepSpeed Il Il est démontré que MoE peut être appliqué au LLM autorégressif, améliorant ainsi considérablement la qualité du modèle sans augmenter le coût de calcul. Lors de la conception d'Arctic, l'équipe de recherche a remarqué que, sur la base de cette idée, l'amélioration de la qualité du modèle dépend principalement du nombre d'experts et du nombre total de paramètres du modèle MoE, ainsi que du nombre de combinaisons de ces experts. Sur cette base, Arctic est conçu pour distribuer 480B de paramètres entre 128 experts à grain fin et utiliser le top 2 du gate pour sélectionner 17B de paramètres actifs. Co-conception d'architecture et de systèmeLa formation d'une architecture MoE de base avec un grand nombre d'experts sur du matériel de formation en IA puissant est très inefficace en raison des frais généraux élevés liés à une communication entièrement connectée entre experts. Snowflake a découvert que cette surcharge pourrait être éliminée si la communication pouvait chevaucher le calcul. Par conséquent, Arctic combine un transformateur dense avec un composant MoE résiduel (Figure 2) pour calculer le chevauchement via la communication, permettant au système de formation d'atteindre une bonne efficacité de formation, masquant la majeure partie des frais généraux de communication. Curriculum Learning axé sur les données d'entrepriseExcellentes performances dans les métriques au niveau de l'entreprise telles que la génération de code et SQL nécessitent un apprentissage du curriculum de données (Curriculum Learning) qui est complètement différent des métriques générales. Grâce à des centaines d'expériences d'ablation à petite échelle, l'équipe a appris que des compétences générales, telles que le raisonnement de bon sens, peuvent être acquises dès les premières étapes ; tandis que des mesures plus complexes, telles que le codage, les mathématiques et SQL, peuvent être apprises efficacement plus tard. dans la formation. Cela peut être comparé à l'éducation à la vie humaine, acquérant progressivement des capacités du simple au difficile. Par conséquent, Arctic utilise un programme en trois étapes, chaque étape ayant une composition de données différente, la première étape étant axée sur les compétences générales (jeton 1T) et les deux dernières étapes sur les compétences d'entreprise (jeton 1,5T et 1T). Efficacité de l'inférenceL'efficacité de l'inférence est également un aspect important de l'efficacité du modèle, qui détermine si le modèle peut être réellement déployé à faible coût. Arctic représente un bond en avant dans la taille des modèles MoE, utilisant plus d'experts et de paramètres totaux que tout autre modèle MoE de régression open source. Par conséquent, Snowflake a besoin de plusieurs idées innovantes pour garantir qu'Arctic puisse déduire efficacement : a) Dans l'inférence interactive avec une petite taille de lot, comme une taille de lot de 1, la latence d'inférence du modèle MoE est limitée par la lecture de tous paramètres actifs Le temps d'inférence est limité par la bande passante mémoire. À cette taille de lot, le volume de lecture de la mémoire d'Arctic (17 B de paramètres actifs) ne représente que 1/4 de Code-Llama 70B et 2/5 de Mixtral 8x22B (44 B de paramètres actifs), ce qui entraîne des taux d'inférence plus rapides. b) Lorsque la taille du lot augmente de manière significative, par exemple des milliers de jetons par passage direct, Arctic passe d'une bande passante mémoire limitée à une limite informatique, avec une inférence limitée par les paramètres actifs de chaque jeton. À cet égard, Arctic représente 1/4 de l’effort de calcul de CodeLlama 70B et Llama 3 70B. Pour obtenir une inférence liée au calcul et un débit élevé correspondant au petit nombre de paramètres actifs dans l'Arctique, une taille de lot plus grande est requise. Pour y parvenir, il faut suffisamment de cache KV pour le prendre en charge, ainsi que suffisamment de mémoire pour stocker les près de 500 B de paramètres du modèle. Bien que difficile, Snowflake y parvient en utilisant deux nœuds pour l'inférence et en combinant des optimisations de système telles que les poids FP8, le fusible divisé et le traitement par lots continu, le parallélisme tenseur intra-nœud et le parallélisme de pipeline inter-nœuds. L'équipe de recherche a travaillé en étroite collaboration avec NVIDIA pour optimiser l'inférence pour les microservices NVIDIA NIM pilotés par TensorRT-LLM. Dans le même temps, l'équipe de recherche travaille également avec la communauté vLLM, et les équipes de développement internes mettront également en œuvre l'inférence efficace d'Arctic pour les cas d'utilisation en entreprise dans les semaines à venir. Lien de référence : https://www.snowflake.com/blog/arctic-open-efficient-foundation-lingual-models-snowflake/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!