
Maison >Périphériques technologiques >IA >Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !

- WBOYavant
- 2024-03-14 23:50:021057parcourir
Écrit ci-dessus et compréhension personnelle de l'auteur
Dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés pendant la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome.
Actuellement, les méthodes de perception visuelle purement basées sur l'image ont des coûts matériels et de déploiement inférieurs à ceux des algorithmes de perception basés sur le lidar et ont donc reçu une large attention de la part de l'industrie et du monde universitaire. De nombreux excellents algorithmes de perception visuelle ont émergé pour réaliser des tâches de perception d'objets 3D et des tâches de segmentation sémantique dans les scènes BEV. Bien que les algorithmes de perception de cibles 3D existants aient fait des progrès significatifs en termes de performances de détection, certains problèmes sont encore progressivement révélés dans les applications pratiques :
- L'algorithme de perception de cibles 3D original ne peut pas bien résoudre les problèmes existants dans l'ensemble de données. Problèmes de longue traîne , ainsi que des objets qui existent dans le monde réel mais peuvent ne pas être étiquetés dans l'ensemble de données d'entraînement actuel (tels que de gros rochers sur la route, des véhicules renversés, etc.)
- Les algorithmes originaux de perception d'objets 3D génèrent généralement directement une 3D approximative Le cadre de délimitation stéréoscopique ne peut pas décrire avec précision un objet cible de forme arbitraire, et l'expression de la forme et de la structure géométrique de l'objet n'est pas suffisamment fine. Bien que cette boîte de résultats de sortie puisse satisfaire la plupart des scènes d'objets, par exemple des bus connectés ou des véhicules de construction avec de longs crochets, l'algorithme de perception 3D actuel ne peut pas donner une description précise et claire
Sur la base de ce qui précède Concernant les problèmes connexes mentionnés, la grille Un algorithme de détection du réseau d'occupation (Occupancy Network) a été proposé. Essentiellement, l’algorithme de perception d’Occupancy Network est une tâche de segmentation sémantique basée sur des scènes spatiales 3D. L'algorithme de perception du réseau d'occupation basé sur la vision pure divisera l'espace 3D actuel en grilles de voxels 3D et enverra les images environnantes collectées au modèle de réseau via le capteur de caméra environnant équipé sur le véhicule autonome. Après le traitement et la prédiction du modèle d'algorithme, sortie. l'état d'occupation de chaque grille de voxels 3D dans l'espace actuel et les catégories sémantiques cibles possibles, obtenant ainsi une perception complète de la scène spatiale 3D actuelle.
Ces dernières années, l'algorithme de perception basé sur Occupancy Network a reçu une grande attention de la part des chercheurs en raison de ses meilleurs avantages en matière de perception. À l'heure actuelle, de nombreux excellents travaux ont vu le jour pour améliorer les performances de détection de ce type d'algorithme. L'orientation de l'idée est de proposer une méthode d'extraction de caractéristiques plus robuste, une méthode de transformation de coordonnées d'entités 2D en entités 3D, une conception de structure de réseau plus complexe et comment générer plus précisément des annotations de vérité terrain d'occupation pour faciliter l'apprentissage du modèle, etc. Cependant, de nombreuses méthodes de perception du réseau d'occupation existantes nécessitent une surcharge de calcul importante dans le processus de prédiction et d'inférence du modèle, ce qui rend difficile pour ces algorithmes de répondre aux exigences de perception en temps réel pour la conduite autonome et difficile à déployer dans les véhicules.
Nous proposons une méthode innovante de prédiction du réseau d'occupation. Comparé aux principaux algorithmes de perception actuels, notre algorithme FastOcc a une vitesse d'inférence en temps réel et d'excellentes performances de détection. La figure suivante peut comparer visuellement la différence de performances et de vitesse d'inférence entre notre algorithme proposé et d'autres algorithmes.
 Comparaison de la précision et de la vitesse d'inférence entre l'algorithme FastOcc et d'autres algorithmes SOTA
Comparaison de la précision et de la vitesse d'inférence entre l'algorithme FastOcc et d'autres algorithmes SOTA
Lien papier : https://arxiv.org/pdf/2403.02710.pdf
Architecture globale et détails du modèle de réseau
Dans l'ordre pour améliorer l'occupation Pour la vitesse d'inférence de l'algorithme de perception du réseau, nous avons mené des expériences sur quatre parties : la résolution de l'image d'entrée, le réseau fédérateur d'extraction de caractéristiques, la méthode de conversion de perspective et la structure de la tête de prédiction de la grille à travers le. Résultats expérimentaux, nous avons constaté que la structure tridimensionnelle de la tête de prédiction de grille, convolution ou déconvolution, nécessite beaucoup de temps d'optimisation. Sur cette base, nous avons conçu la structure de réseau de l'algorithme FastOcc, comme le montre la figure ci-dessous.
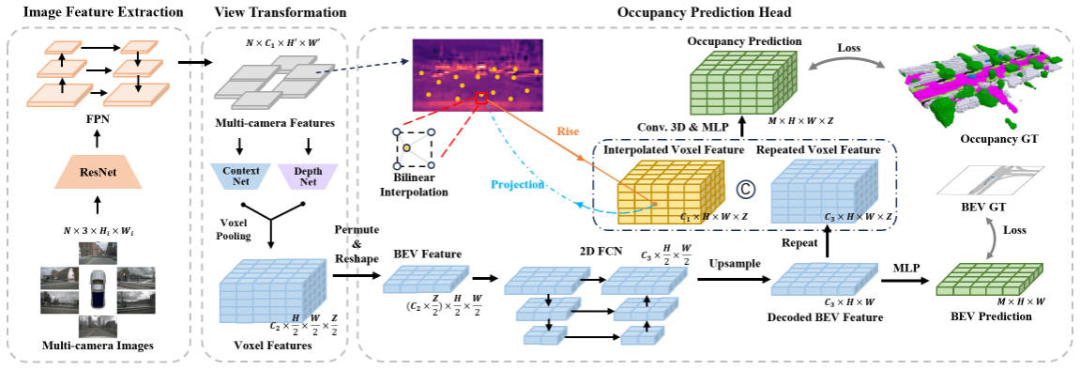 Diagramme de structure du réseau de l'algorithme FastOcc
Diagramme de structure du réseau de l'algorithme FastOcc
Dans l'ensemble, l'algorithme FastOcc proposé comprend trois sous-modules, à savoir Extraction de caractéristiques d'image pour l'extraction de caractéristiques à plusieurs échelles, Transformation de vue pour la conversion de perspective, Tête de prédiction d'occupation Utilisée pour Pour obtenir un résultat perceptuel, nous présenterons les détails de ces trois parties séparément.
Extraction de caractéristiques d'image
Pour l'algorithme FastOcc proposé, l'entrée réseau est toujours l'image surround collectée. Ici, nous utilisons la structure de réseau ResNet pour terminer le processus d'extraction de caractéristiques de l'image surround. Dans le même temps, nous utilisons également la structure pyramidale des fonctionnalités FPN pour regrouper les fonctionnalités d'image multi-échelle produites par le réseau fédérateur. Pour faciliter l'expression ultérieure, nous représentons ici l'image d'entrée par , et les caractéristiques après extraction des caractéristiques par .
View Transformation
La fonction principale du module de transformation de vue est de terminer le processus de conversion des caractéristiques de l'image 2D en caractéristiques de l'espace 3D en même temps, afin de réduire le coût du modèle d'algorithme, généralement les fonctionnalités. converti en espace 3D sera une expression approximative, ici pour faciliter l'expression, nous marquons les caractéristiques converties en espace 3D comme, où représente la dimension du vecteur de caractéristiques intégré et représente la longueur, la largeur et la hauteur de l'espace perceptuel. Parmi les algorithmes de perception actuels, le processus de conversion de perspective traditionnel comprend deux catégories :
- L'une est la méthode de transformation de coordonnées arrière représentée par BEVFormer. Ce type de méthode génère généralement d'abord une requête de voxel dans l'espace 3D, puis utilise Cross-view Attention pour interagir avec la requête de voxel dans l'espace 3D et les fonctionnalités d'image 2D afin de terminer la construction de la fonctionnalité de voxel 3D finale.
- Un type est la méthode de transformation de coordonnées avant représentée par LSS. Ce type de méthode utilisera le réseau d'estimation de profondeur du réseau pour estimer simultanément les informations sur les caractéristiques sémantiques et la probabilité de profondeur discrète de chaque position de pixel de caractéristique, construira la caractéristique de tronc sémantique via l'opération de produit externe et enfin utilisera la couche VoxelPooling pour atteindre l'objectif. caractéristique finale du voxel 3D de la construction.
Considérant que l'algorithme LSS a une meilleure vitesse et efficacité de raisonnement, dans cet article, nous adoptons l'algorithme LSS comme module de conversion de perspective. Dans le même temps, étant donné que la profondeur discrète de chaque position de pixel est estimée, son incertitude limitera dans une certaine mesure les performances perceptuelles finales du modèle. Par conséquent, dans notre implémentation spécifique, nous utilisons les informations du nuage de points pour la supervision dans le sens de la profondeur afin d'obtenir de meilleurs résultats de perception.
Tête de prédiction raster (tête de prédiction d'occupation)
Dans le diagramme de structure de réseau présenté ci-dessus, la tête de prédiction raster contient également trois sous-parties, à savoir Extraction de caractéristiques BEV, Échantillonnage d'interpolation de caractéristiques d'image, Intégration de caractéristiques . Ensuite, nous présenterons les détails de la méthode en trois parties un par un.
Extraction de caractéristiques BEV
Actuellement, la plupart des algorithmes du réseau d'occupation traitent les caractéristiques de voxel 3D obtenues par le module de conversion de perspective. La forme de traitement est généralement un réseau tridimensionnel entièrement convolutif. Plus précisément, pour n'importe quelle couche du réseau tridimensionnel entièrement convolutif, la quantité de calcul requise pour convoluer les caractéristiques de voxel tridimensionnel d'entrée est la suivante :
où, et représentent respectivement le nombre de canaux de l'entité d'entrée et de l'entité de sortie. et représentent la taille de l'espace de la carte des fonctionnalités. Par rapport au traitement des fonctionnalités de voxel directement dans l'espace 3D, nous utilisons un module de convolution de fonctionnalités 2D BEV léger. Plus précisément, pour les caractéristiques de voxel de sortie du module de conversion de perspective, nous fusionnons d'abord les informations de hauteur et les caractéristiques sémantiques pour obtenir les caractéristiques BEV 2D, puis utilisons un réseau 2D entièrement convolutif pour effectuer l'extraction de caractéristiques afin d'obtenir l'extraction de caractéristiques de ce 2D. processus La quantité de calcul du processus peut être exprimée sous la forme suivante
En comparant la quantité de calcul des processus de traitement 3D et 2D, on peut voir qu'en utilisant le module léger de convolution de caractéristiques 2D BEV pour remplacer l'extraction de caractéristiques de voxel 3D d'origine , cela peut être considérablement réduit Le montant du calcul du modèle. Dans le même temps, l'organigramme visuel des deux types de traitement est présenté dans la figure ci-dessous :
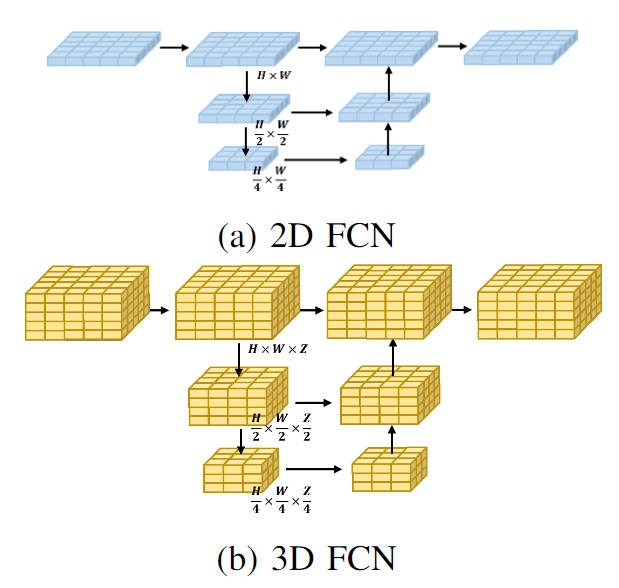
Visualisation des structures de réseau FCN 2D et 3D
Échantillonnage d'interpolation de caractéristiques d'image
Afin de réduire la quantité de calcul du module de tête de prédiction raster, nous compressons la hauteur des caractéristiques du voxel 3D produites par le module de conversion de perspective et utilisons le module de convolution 2D BEV pour l'extraction des caractéristiques. Cependant, afin d'augmenter les informations manquantes sur les caractéristiques de hauteur de l'axe Z et de respecter l'idée de réduire la quantité de calculs de modèle, nous avons proposé une méthode d'échantillonnage par interpolation des caractéristiques d'image.
Plus précisément, nous définissons d'abord l'espace voxel tridimensionnel correspondant en fonction de la plage qui doit être détectée, et l'attribuons au système de coordonnées de l'ego, noté . Deuxièmement, les matrices de transformation de coordonnées extrinsèques et intrinsèques de la caméra sont utilisées pour projeter les points de coordonnées du système de coordonnées de l'ego vers le système de coordonnées de l'image, qui est utilisé pour extraire les caractéristiques de l'image aux positions correspondantes.
Parmi eux, représentent respectivement les matrices de transformation de coordonnées intrinsèques et extrinsèques de la caméra, représentant la position du point spatial dans le système de coordonnées de l'ego projeté sur le système de coordonnées de l'image. Après avoir obtenu les coordonnées de l'image correspondantes, nous filtrons les points de coordonnées qui dépassent la plage de l'image ou ont une profondeur négative. Ensuite, nous utilisons une opération d'interpolation bilinéaire pour obtenir les caractéristiques sémantiques de l'image correspondantes en fonction de la position des coordonnées projetées, et faisons la moyenne des caractéristiques collectées à partir de toutes les images de caméra pour obtenir le résultat final d'échantillonnage par interpolation.
Intégration de fonctionnalités
Afin d'intégrer les caractéristiques planaires BEV obtenues avec les caractéristiques de voxel 3D obtenues par échantillonnage par interpolation, nous utilisons d'abord une opération de suréchantillonnage pour aligner les dimensions spatiales des caractéristiques BEV et les dimensions spatiales des caractéristiques de voxel 3D. , et L'opération de répétition est effectuée le long de la direction de l'axe Z et les caractéristiques obtenues après l'opération sont enregistrées sous la forme . Ensuite, nous concaténons les caractéristiques obtenues par échantillonnage par interpolation des caractéristiques de l'image et les intégrons via une couche convolutive pour obtenir la caractéristique de voxel finale.
Le processus global d'échantillonnage par interpolation de caractéristiques d'image et d'intégration de caractéristiques mentionné ci-dessus peut être représenté par la figure suivante :
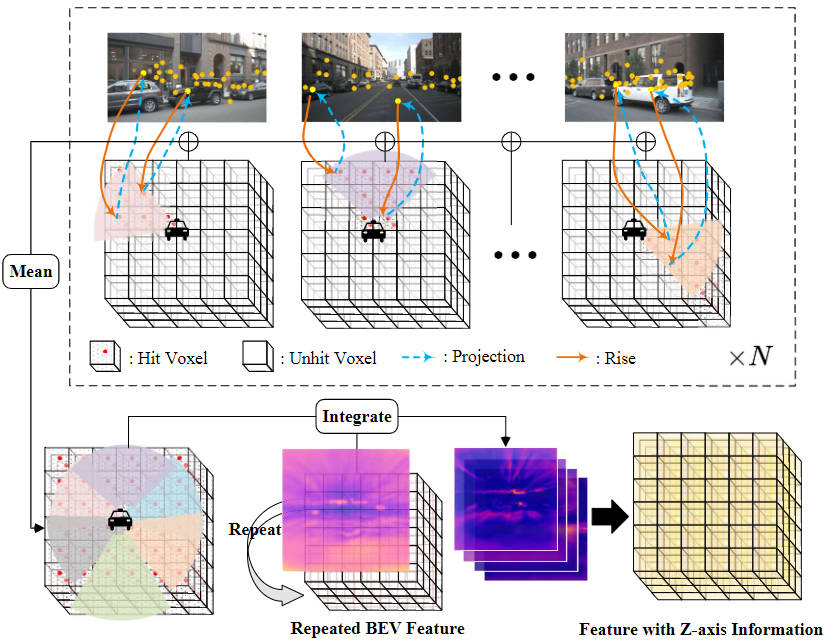
Processus d'échantillonnage par interpolation de caractéristiques d'image et d'intégration de caractéristiques
De plus, afin de garantir davantage que la fonctionnalité BEV module d'extraction Les caractéristiques BEV de sortie contiennent suffisamment d'informations sur les caractéristiques pour terminer le processus de perception ultérieur. Nous adoptons une méthode de supervision supplémentaire, c'est-à-dire utiliser une tête de segmentation sémantique pour effectuer d'abord la tâche de segmentation sémantique et utiliser la vraie valeur de l'occupation pour construire la tâche. la segmentation sémantique. L’étiquette de vérité complète l’ensemble du processus de supervision.
Résultats expérimentaux et indicateurs d'évaluation
Partie analyse quantitative
Tout d'abord, nous montrerons la comparaison entre notre algorithme FastOcc proposé et d'autres algorithmes SOTA sur l'ensemble de données Occ3D-nuScenes. Les indicateurs spécifiques de chaque algorithme sont présentés. dans le tableau ci-dessous montre
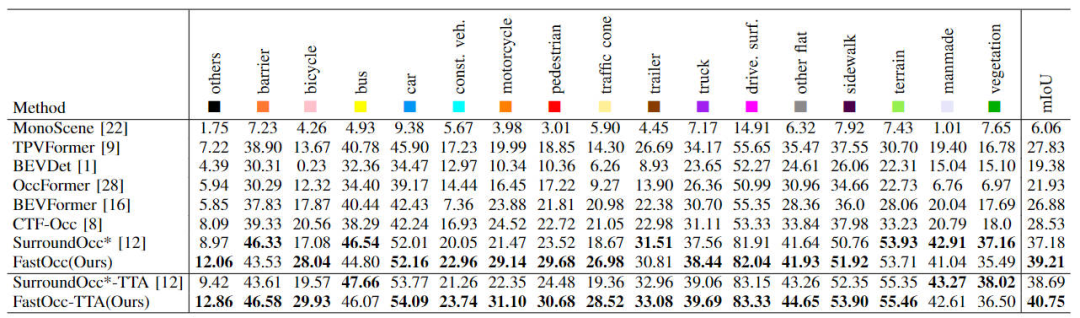
La comparaison de chaque index d'algorithme sur l'ensemble de données Occ3D-nuScenes
Il ressort des résultats du tableau que par rapport à d'autres algorithmes, l'algorithme FastOcc que nous avons proposé a de meilleures performances dans La plupart des catégories ont plus d'avantages que les autres algorithmes, et l'indicateur global mIoU produit également l'effet SOTA.
De plus, nous avons également comparé l'impact de différentes méthodes de conversion de perspective et du module de fonction de décodage utilisé dans la tête de prédiction raster sur les performances de perception et le temps d'inférence (les données expérimentales sont basées sur la résolution de l'image d'entrée de 640 × 1600, l'épine dorsale utilise le réseau ResNet-101), les résultats expérimentaux pertinents sont comparés comme indiqué dans le tableau ci-dessous

Comparaison de la précision et de la consommation de temps d'inférence de différentes conversions de perspective et têtes de prédiction raster
L'algorithme SurroundOcc utilise plusieurs L'échelle Cross -view La méthode de conversion de perspective Attention et la convolution 3D sont utilisées pour extraire les caractéristiques du voxel 3D, qui ont le temps de raisonnement le plus élevé. Après avoir remplacé la méthode de conversion de perspective Cross-view Attention d'origine par la méthode de conversion LSS, la précision mIoU a été améliorée et la consommation de temps a également été réduite. Sur cette base, en remplaçant la convolution 3D d'origine par une structure FCN 3D, la précision peut être encore augmentée, mais le temps de raisonnement est également considérablement augmenté. Enfin, nous avons choisi la méthode de conversion de coordonnées d'échantillonnage LSS et la structure 2D FCN pour atteindre un équilibre entre les performances de détection et la consommation de temps d'inférence.
De plus, nous avons également vérifié l'efficacité de notre tâche de supervision de segmentation sémantique proposée basée sur les caractéristiques BEV et l'échantillonnage par interpolation des caractéristiques d'image. Les résultats expérimentaux d'ablation spécifiques sont présentés dans le tableau ci-dessous :
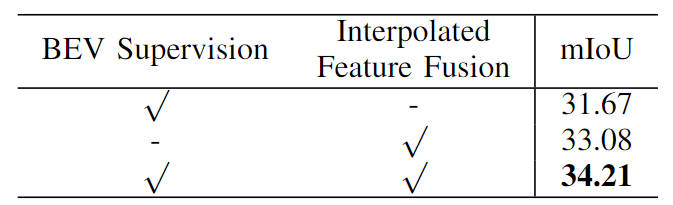
Comparaison des expériences d'ablation de différentes. modules Situation
De plus, nous avons également mené des expériences à grande échelle sur le modèle et construit un ensemble de modèles d'algorithmes de perception du réseau d'occupation (FastOcc, FastOcc-Small, FastOcc-Tiny) en contrôlant la taille du réseau fédérateur et la résolution du image d'entrée. La configuration spécifique est présentée dans le tableau ci-dessous :
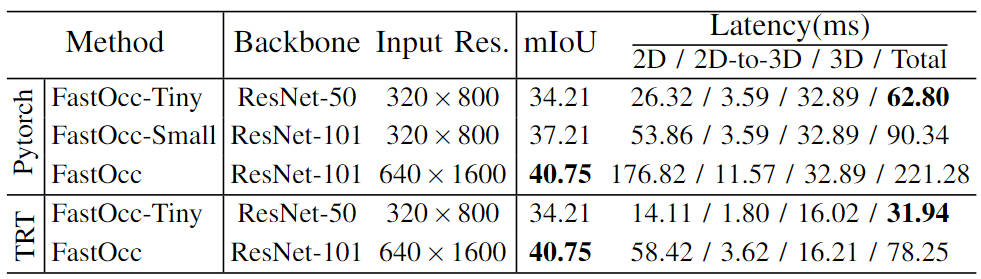
Comparaison des capacités du modèle sous différentes configurations de réseau fédérateur et de résolution
Partie analyse qualitative
La figure suivante montre la comparaison des résultats visuels de notre Modèle d'algorithme FastOcc proposé et modèle d'algorithme SurroundOcc À partir de cette situation, il peut être clairement vu que le modèle d'algorithme FastOcc proposé remplit les éléments environnementaux environnants de manière plus raisonnable et permet d'obtenir une perception plus précise de la conduite des véhicules et des arbres.

Comparaison des résultats visuels de l'algorithme FastOcc et de l'algorithme SurroundOcc
Conclusion
Dans cet article, nous avons proposé le modèle d'algorithme FastOcc pour résoudre le problème selon lequel le modèle d'algorithme de réseau d'occupation existant prend beaucoup de temps à détecter et est difficile à déployer sur le véhicule. En remplaçant le module de convolution 3D d'origine qui traite les voxels 3D par une convolution 2D, le temps de raisonnement est considérablement réduit et, par rapport à d'autres algorithmes, des résultats de perception SOTA sont obtenus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!