
Maison >Périphériques technologiques >IA >Qui a dit que les éléphants ne pouvaient pas danser ! Reprogrammation de grands modèles de langage pour réaliser une prédiction temporelle des interactions intermodales ICLR 2024 !
Qui a dit que les éléphants ne pouvaient pas danser ! Reprogrammation de grands modèles de langage pour réaliser une prédiction temporelle des interactions intermodales ICLR 2024 !

- 王林avant
- 2024-04-15 15:20:02857parcourir
Récemment, des chercheurs de l'Université Monash en Australie, d'Ant Group, d'IBM Research et d'autres institutions ont exploré l'application de la reprogrammation de modèles sur de grands modèles de langage (LLM) et ont proposé une nouvelle perspective : une reprogrammation efficace de grands modèles de langage pour la prévision générale de séries chronologiques. systèmes, le cadre Time-LLM. Ce cadre peut réaliser des prédictions de haute précision et efficaces sans modifier le modèle de langage. Il peut surpasser les modèles de séries chronologiques traditionnels dans plusieurs ensembles de données et tâches de prédiction, permettant aux LLM de démontrer d'excellentes performances lors du traitement des données de séries chronologiques intermodales. .

Récemment, le développement de grands modèles de langage dans le domaine de l'intelligence générale, la nouvelle direction des « grands modèles + séries chronologiques/données temporelles » a montré de nombreux progrès connexes. Les LLM actuels ont le potentiel de révolutionner les méthodes d'exploration de séries chronologiques et de données temporelles, favorisant ainsi une prise de décision efficace dans des systèmes complexes classiques tels que les villes, l'énergie, les transports, la santé, etc., et évoluant vers des formes intelligentes d'analyse temps/espace plus universelles. .
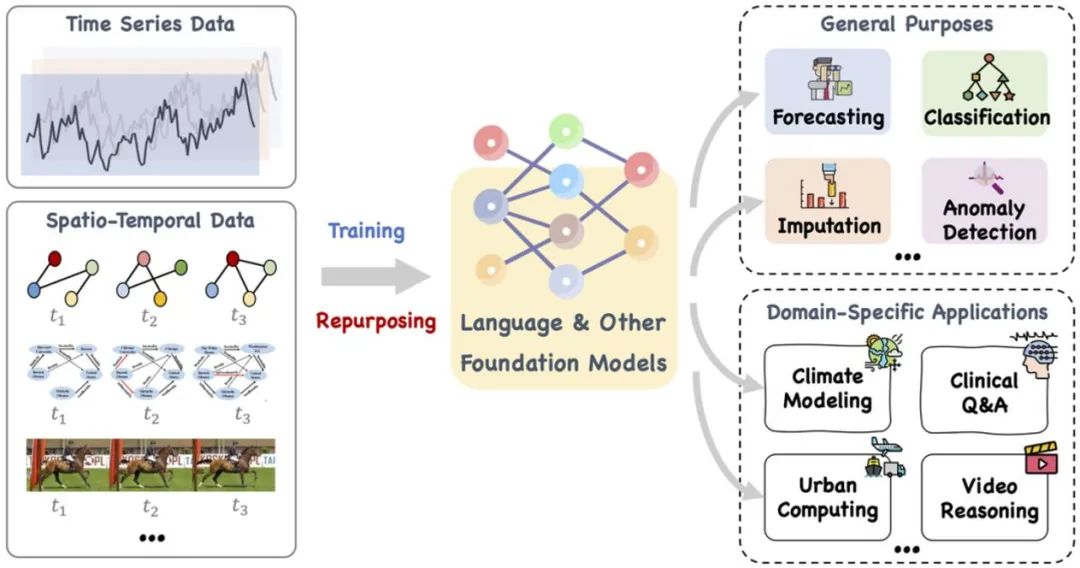
Cet article propose un modèle de base étendu, tel que le langage et d'autres modèles associés, qui peut être entraîné et intelligemment réutilisé pour gérer une gamme de tâches générales et d'applications de domaine spécifiques au temps. Données spatiales séquentielles et temporelles . Référence : https://arxiv.org/pdf/2310.10196.pdf.
Des recherches récentes ont étendu les modèles de langage à grande échelle, du traitement du langage naturel aux séries chronologiques et aux tâches spatio-temporelles. Cette nouvelle direction de recherche, à savoir « grand modèle + séries chronologiques/données spatio-temporelles », a produit de nombreux développements connexes, tels que LLMTime, qui utilise directement les LLM pour l'inférence prédictive de séries chronologiques sans tir. Bien que les LLM disposent de puissantes capacités d'apprentissage et d'expression et puissent capturer efficacement des modèles complexes et des dépendances à long terme dans les données de séquences de texte, en tant que « boîte noire » axée sur le traitement du langage naturel, l'application des LLM dans les séries temporelles et les tâches spatio-temporelles reste confrontée à des difficultés. défi. Par rapport aux modèles de séries chronologiques traditionnels tels que TimesNet, TimeMixer, etc., les LLM sont comparables aux « éléphants » en raison de leurs paramètres et de leur échelle énormes.
Ce que vous demandez, c'est comment « apprivoiser » de tels grands modèles de langage (LLM) formés dans le domaine du langage naturel afin qu'ils puissent traiter des données de séquence numérique à travers des modèles de texte et exercer un raisonnement puissant dans des séries chronologiques et des capacités prédictives. sont devenus un axe majeur de la recherche actuelle. À cette fin, une analyse théorique plus approfondie est nécessaire pour explorer les similitudes potentielles entre les données linguistiques et temporelles et les appliquer efficacement à des séries temporelles et à des tâches spatio-temporelles spécifiques.
LLM Reprogramming est une technologie générale de prédiction de séries chronologiques. Il propose deux technologies clés, à savoir (1) la reprogrammation des entrées temporelles et (2) la préprogrammation rapide, pour convertir la tâche de prédiction temporelle en une tâche de « langage » qui peut être efficacement résolue par les LLM, en activant avec succès de grands modèles de langage pour atteindre des niveaux élevés. performance. Capacité à effectuer un raisonnement temporel précis.

Adresse papier : https://openreview.net/pdf?id=Unb5CVPtae
Code papier : https://github.com/KimMeen/Time-LLM
1 Contexte du problème
Timing. Les données sont largement stockées dans la réalité, où la prévision temporelle revêt une grande importance dans de nombreux systèmes dynamiques du monde réel et a été largement étudiée. Contrairement au traitement du langage naturel (NLP) et à la vision par ordinateur (CV), où un seul grand modèle peut gérer plusieurs tâches, les modèles de prédiction de séries chronologiques doivent souvent être spécialement conçus pour répondre aux besoins de différentes tâches et scénarios d'application. Des recherches récentes ont montré que les grands modèles de langage (LLM) sont également fiables lors du traitement de séquences temporelles complexes. Il reste encore difficile d'utiliser les capacités de raisonnement des grands modèles de langage eux-mêmes pour gérer des tâches d'analyse temporelle.
2. Présentation de l'article
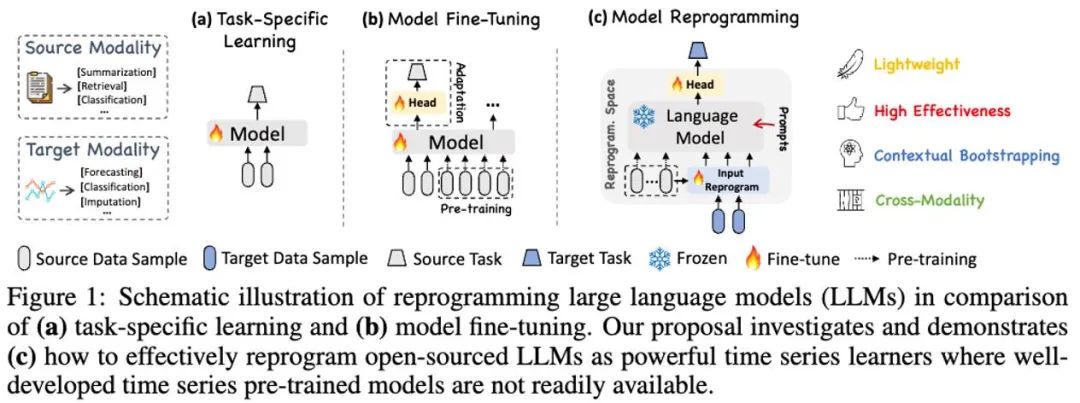
Dans ce travail, l'auteur propose Time-LLM, qui est un cadre général de reprogrammation de modèles de langage (LLM Reprogramming) qui utilise facilement LLM pour les prédictions générales de séries chronologiques sans aucune formation. sur le grand modèle de langage lui-même. Time-LLM utilise d'abord des prototypes de texte (Text Prototypes) pour reprogrammer les données de séries chronologiques d'entrée, et utilise une représentation en langage naturel pour représenter les informations sémantiques des données de séries chronologiques, alignant ainsi deux modalités de données différentes, de sorte que le grand modèle de langage ne nécessiter toute modification. Vous pouvez comprendre les informations derrière une autre modalité de données.
Afin d'améliorer davantage la compréhension de LLM des données de séries chronologiques d'entrée et des tâches correspondantes, l'auteur a proposé le paradigme d'invite en tant que préfixe (PaP), qui active pleinement le paradigme d'invite en tant que préfixe (PaP) en ajoutant des invites contextuelles supplémentaires et instructions de tâche avant la représentation des données de séries chronologiques. Dans ce travail, l'auteur a mené suffisamment d'expériences sur les ensembles de données de référence des séries chronologiques traditionnelles, et les résultats ont montré que Time-LLM peut surpasser le modèle de série chronologique traditionnel dans la plupart des cas et obtenir de meilleures performances dans les échantillons à quelques tirs et à zéro tir. la tâche d'apprentissage de l'échantillon (zero-shot) a été grandement améliorée.
Les principales contributions de ce travail peuvent être résumées comme suit :
1. Ce travail propose un nouveau concept de reprogrammation de grands modèles de langage pour l'analyse temporelle sans aucune modification du modèle de langage principal. Les auteurs montrent que la prédiction de séries chronologiques peut être considérée comme une autre tâche « linguistique » qui peut être efficacement résolue par des LLM disponibles dans le commerce.
2. Ce travail propose un cadre général de reprogrammation de modèle de langage, à savoir Time-LLM, qui consiste à reprogrammer les données temporelles d'entrée dans une représentation prototype de texte plus naturelle, et à l'intégrer à des indices déclaratifs tels que les connaissances d'experts du domaine et la description des tâches) pour améliorer le contexte d'entrée pour guider le LLM pour un raisonnement inter-domaines efficace. Cette technologie fournit une base solide pour le développement de modèles de base de synchronisation multimodale.
3. Time-LLM surpasse systématiquement les meilleures performances des modèles existants dans les tâches de prédiction traditionnelles, en particulier dans les scénarios à quelques échantillons et à zéro échantillon. De plus, Time-LLM est capable d'atteindre des performances plus élevées tout en conservant une excellente efficacité de reprogrammation du modèle. Libérez considérablement le potentiel inexploité du LLM pour les séries chronologiques et autres données séquentielles.
3. Cadre du modèle
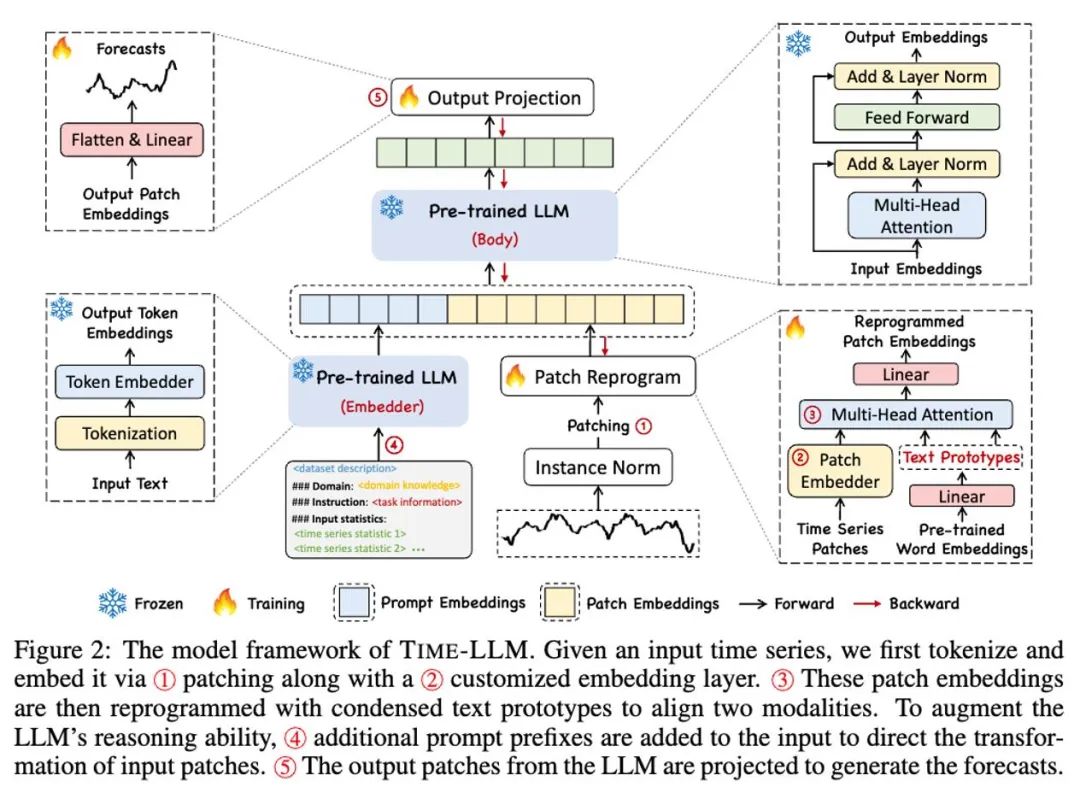
Comme le montrent les points ① et ② dans le diagramme du cadre du modèle ci-dessus, les données de série chronologique d'entrée sont d'abord normalisées par RevIN, puis divisées en différents correctifs et mappées à l'espace latent.
Il existe des différences significatives dans les méthodes d'expression entre les données de séries chronologiques et les données textuelles, et elles appartiennent à des modalités différentes. Les séries chronologiques ne peuvent ni être directement éditées ni décrites sans perte en langage naturel, ce qui pose un défi important pour inciter directement LLM à comprendre les séries chronologiques. Par conséquent, nous devons aligner les fonctionnalités d’entrée temporelles sur le domaine textuel en langage naturel.
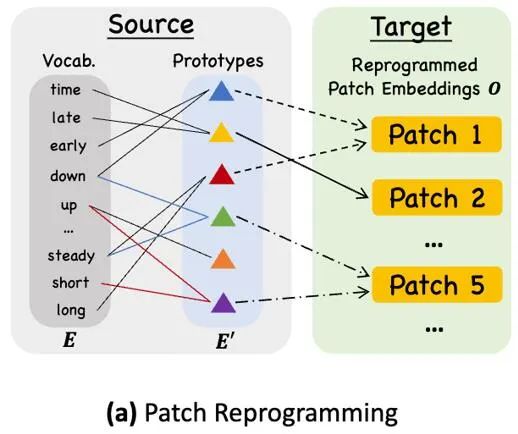
Une méthode courante pour aligner différentes modalités est l'attention croisée. Comme le montre le point ③ du diagramme du cadre du modèle, il vous suffit de faire une attention croisée pour les fonctionnalités d'intégration et de synchronisation de tous les mots (où le timing). la fonctionnalité d'entrée est Query, l'intégration de tous les mots est Key et Value). Cependant, le vocabulaire inhérent du LLM est très vaste, il ne peut donc pas aligner directement et efficacement les caractéristiques temporelles sur tous les mots, et tous les mots n'ont pas aligné les relations sémantiques avec les séries temporelles. Afin de résoudre ce problème, ce travail effectue une combinaison linéaire de vocabulaire pour obtenir des prototypes de texte. Le nombre de prototypes de texte est beaucoup plus petit que le vocabulaire original. La combinaison peut être utilisée pour représenter les caractéristiques changeantes des données de séries chronologiques, telles que. "une brève hausse ou un lent déclin.", Comme le montre la FIG.
Afin d'activer pleinement la capacité du LLM sur des tâches de synchronisation spécifiées, ce travail propose le paradigme du préfixe rapide, qui est une méthode simple et efficace, comme le montre le point ④ du diagramme-cadre du modèle. Des progrès récents ont montré que d'autres modèles de données, tels que les images, peuvent être intégrés de manière transparente dans le préfixe des signaux, permettant ainsi une inférence efficace basée sur ces entrées. Inspirés par ces résultats, les auteurs, afin de rendre leur méthode directement applicable aux séries temporelles du monde réel, posent une question alternative : les indices peuvent-ils servir d'informations de préfixe pour enrichir le contexte d'entrée et guider la transformation des correctifs de séries chronologiques reprogrammés ? Ce concept est appelé Prompt-as-Prefix (PaP), et de plus, les auteurs ont observé qu'il améliore considérablement l'adaptabilité du LLM aux tâches en aval tout en complétant la reprogrammation des correctifs. En termes simples, cela signifie fournir des informations préalables sur l'ensemble de données de séries chronologiques sous la forme d'un langage naturel comme invite de préfixe, et les associer aux caractéristiques de séries chronologiques alignées dans LLM. Cela peut-il améliorer l'effet de prédiction ?
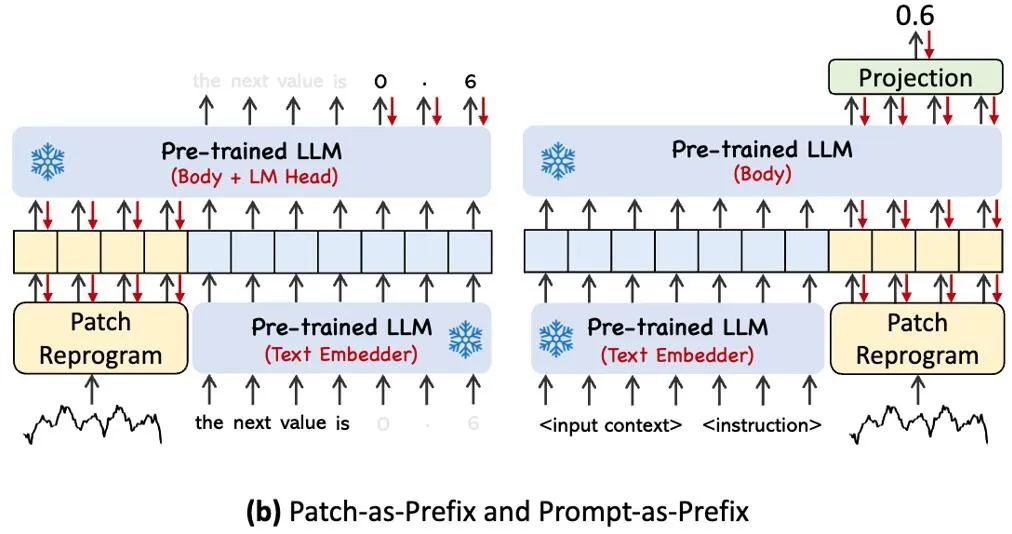
L'image ci-dessus montre deux méthodes d'invite. Dans Patch-as-Prefix, un modèle de langage est invité à prédire les valeurs suivantes dans une série chronologique, exprimées en langage naturel. Cette approche rencontre certaines contraintes : (1) les modèles de langage présentent souvent une faible sensibilité lors du traitement de nombres de haute précision sans l'aide d'outils externes, ce qui pose des défis importants pour le traitement précis des tâches de prédiction à long terme ; (2) un post-traitement personnalisé complexe ; est requis pour différents modèles de langage car ils sont pré-entraînés sur différents corpus et peuvent utiliser différents types de segmentation de mots lors de la génération de nombres de haute précision. Cela se traduit par la représentation des prédictions dans différents formats de langage naturel, tels que ['0', '.', '6', '1'] et ['0', '.', '61'], qui représente 0,61.
En pratique, l'auteur a identifié trois éléments clés pour créer des invites efficaces : (1) le contexte de l'ensemble de données ; (2) les instructions de tâche pour adapter le LLM aux différentes tâches en aval, telles que les tendances, le délai et l'attente ; permettre à LLM de mieux comprendre les caractéristiques des données de séries chronologiques. L'image ci-dessous donne un exemple d'invite.

4. Résultats expérimentaux
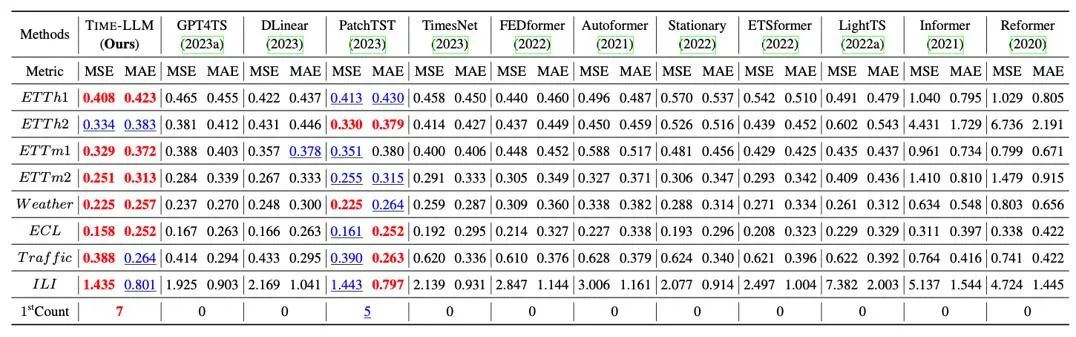
Nous avons effectué des tests complets sur 8 ensembles de données publiques classiques pour la prédiction à long terme, comme le montre le tableau ci-dessous, Time-LLM a largement dépassé le meilleur précédent dans le domaine dans le benchmark. De plus, par rapport à GPT4TS qui utilise directement GPT-2, Time-LLM qui utilise des idées de reprogrammation et l'invite en tant que préfixe (Prompt-as-Prefix) a également été considérablement amélioré, indiquant l'efficacité de cette méthode.
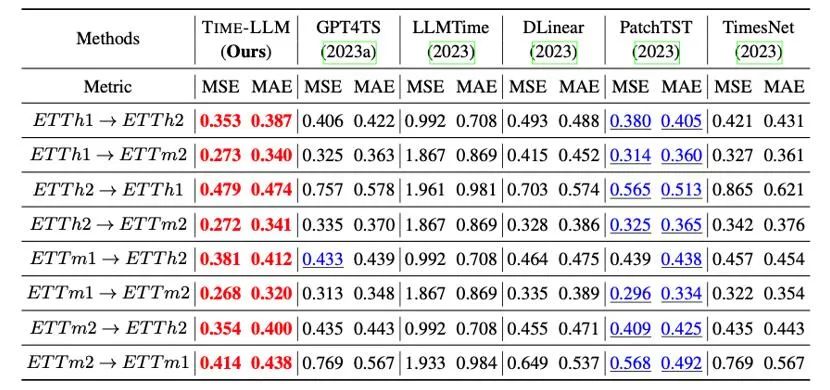
De plus, nous évaluons la capacité d'apprentissage zéro tir du LLM reprogrammé dans le cadre de l'adaptation inter-domaines. Grâce à la capacité de reprogrammation, nous activons pleinement la capacité de prédiction du LLM en inter-domaines. Comme le montre le tableau ci-dessous, Time-LLM affiche également des résultats de prédiction extraordinaires dans des scénarios sans tir.
5. Résumé
Le développement rapide des grands modèles de langage (LLM) a grandement favorisé les progrès de l'intelligence artificielle dans les scénarios multimodaux et favorisé leur application généralisée dans de multiples domaines. Cependant, la grande échelle de paramètres des LLM et leur conception principalement pour des scénarios de traitement du langage naturel (NLP) posent de nombreux défis à leurs applications multimodales et inter-domaines. Compte tenu de cela, nous proposons une nouvelle idée de reprogrammation de grands modèles, visant à réaliser une interaction intermodale entre les données de texte et de séquence, et appliquons largement cette méthode au traitement de séries temporelles et de données spatio-temporelles à grande échelle. De cette manière, nous espérons créer des LLM comme des éléphants dansants avec flexibilité, capables de démontrer leurs puissantes capacités dans un plus large éventail de scénarios d’application.
Les amis intéressés sont invités à lire l'article (https://arxiv.org/abs/2310.01728) ou à visiter la page du projet (https://github.com/KimMeen/Time-LLM) pour en savoir plus.
Ce projet a reçu le soutien total de NextEvo, le département R&D d'innovation en IA de la division Intelligent Engine d'Ant Group, notamment grâce à l'étroite collaboration entre l'équipe langage et intelligence machine et l'équipe intelligence d'optimisation. Sous la direction et la direction de Zhou Jun, vice-président de la division des moteurs intelligents, et de Lu Xingyu, chef de l'équipe d'intelligence d'optimisation, nous avons travaillé ensemble pour mener à bien cette importante réalisation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!