
Maison >Périphériques technologiques >IA >ReFT (Representation Fine-tuning) : une nouvelle technologie de réglage fin de grands modèles de langage meilleure que PeFT
ReFT (Representation Fine-tuning) : une nouvelle technologie de réglage fin de grands modèles de langage meilleure que PeFT

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-15 15:30:021426parcourir
ReFT (Representation Finetuning) est une méthode révolutionnaire qui promet de redéfinir la façon dont nous affinons les grands modèles de langage.
Des chercheurs de l'Université de Stanford ont récemment publié (avril) un article sur arxiv, ReFT est très différent des méthodes traditionnelles de réglage fin basées sur le poids, et il fournit une méthode plus efficace pour s'adapter à ces modèles à grande échelle pour adaptez-vous à de nouvelles tâches et domaines!

Avant de présenter cet article, jetons un coup d'œil à PeFT.
Parameter Efficient Fine-Tuning PeFT
Parameter Efficient Fine-Tuning (PEFT) est une méthode de réglage fin efficace pour affiner un petit nombre ou des paramètres de modèle supplémentaires. Par rapport aux méthodes traditionnelles de réglage fin des réseaux de prédiction, le réglage fin à l’aide de PEFT peut réduire considérablement les coûts de calcul et de stockage tout en garantissant des performances comparables à un réglage fin complet. Cette technologie a un large éventail d’applications et peut atteindre des performances comparables à celles d’un parage complet.
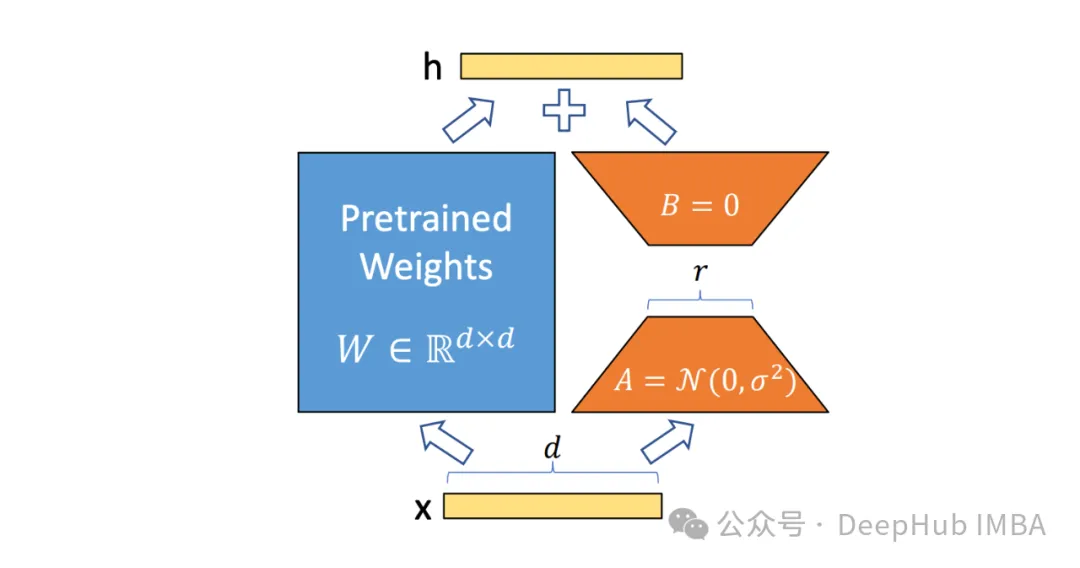
Basé sur l'idée de PeFT, la LoRA que nous connaissons très bien a été produite, et il existe différentes variantes de LoRA En plus de la célèbre LoRA, les méthodes PeFT couramment utilisées incluent :
. Prefix Tuning : via un jeton virtuel, construit une invite implicite continue, qui est une méthode publiée par Stanford en 2021.
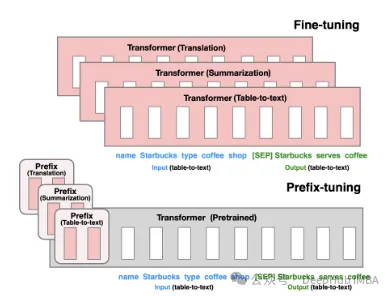
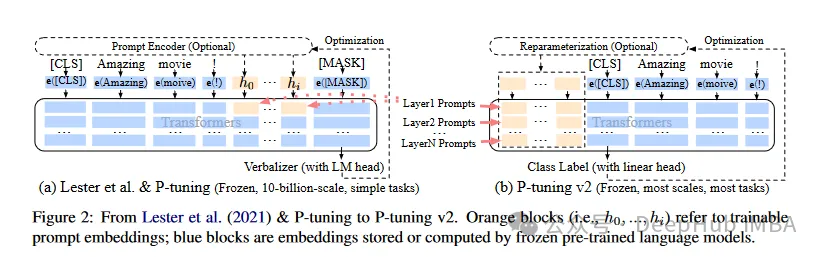
P-Tuning V1/V2 est une technologie proposée par l'Université Tsinghua en 2021, visant à convertir des modèles discrets de langage naturel en invites implicites pouvant être entraînées (problèmes d'optimisation continue des paramètres). La version V2 améliore encore les performances de la version V1 en ajoutant des paramètres ajustables à chaque couche avant la saisie. Cette méthode étend efficacement la portée d’application et la flexibilité du modèle.
Ensuite, il y a LoRA, que nous connaissons et qui est le plus utilisé. Je ne le présenterai pas en détail ici. Nous pouvons comprendre au sens étroit que LoRA est la meilleure méthode PeFT à l'heure actuelle. ce qui peut être meilleur pour le contraste ReFT que nous présentons ci-dessous.
Representation Finetuning ReFT
ReFT (Representation Finetuning) est un groupe de méthodes qui se concentrent sur l'intervention dans l'apprentissage de la représentation cachée du modèle de langage pendant le processus d'inférence, plutôt que sur la modification directe de ses poids.
Contrairement aux méthodes traditionnelles de réglage fin qui mettent à jour l'ensemble des paramètres d'un modèle, ReFT fonctionne en manipulant stratégiquement de petites parties de la représentation d'un modèle, guidant son comportement pour résoudre plus efficacement les tâches en aval.
L'idée centrale de ReFT s'inspire de recherches récentes sur l'interprétabilité des modèles de langage : de riches informations sémantiques sont codées dans les représentations apprises par ces modèles. En intervenant dans ces représentations, ReFT vise à débloquer et à exploiter ces connaissances codées, permettant une adaptation plus efficace et efficiente du modèle.
Un avantage clé de ReFT est l'efficacité de ses paramètres : les méthodes traditionnelles de réglage fin nécessitent la mise à jour d'une grande partie des paramètres du modèle, ce qui peut être coûteux en termes de calcul et gourmand en ressources, en particulier pour les grands modèles de langage comportant des milliards de paramètres. Les méthodes ReFT nécessitent généralement des ordres de grandeur de formation en moins de paramètres, ce qui se traduit par des temps de formation plus rapides et moins de besoins en mémoire.
En quoi ReFT diffère de PeFT
ReFT diffère des méthodes PEFT traditionnelles sur plusieurs aspects clés :
1 Cibles d'intervention
Méthodes PEFT, par exemple LoRA, DoRA et préfixe -tuning, qui se concentre sur la modification des poids du modèle ou l’introduction de matrices de poids supplémentaires. Les méthodes ReFT ne modifient pas directement les poids du modèle ; elles interfèrent avec la représentation cachée calculée par le modèle lors du passage direct.
2. Mécanisme d'adaptation
Les méthodes PEFT comme LoRA et DoRA apprennent les mises à jour de poids ou les approximations de bas rang de la matrice de poids du modèle. Ces mises à jour de poids sont ensuite incorporées aux poids du modèle de base lors de l'inférence, ce qui n'entraîne aucune surcharge de calcul supplémentaire. Les méthodes ReFT apprennent à intervenir, en manipulant la représentation du modèle à des couches et à des emplacements spécifiques lors de l'inférence. Ce processus d'intervention entraîne une certaine surcharge de calcul mais permet une adaptation plus efficace.
3. Motivation
La principale motivation de la méthode PEFT est la nécessité d'une adaptation efficace des paramètres, ce qui réduit le coût de calcul et les besoins en mémoire liés au réglage de grands modèles de langage. Les méthodes ReFT, quant à elles, s'inspirent de recherches récentes sur l'interprétabilité des modèles de langage, qui montrent que de riches informations sémantiques sont codées dans les représentations apprises par ces modèles. L'objectif de ReFT est d'exploiter et d'exploiter ces connaissances codées pour s'adapter plus efficacement au modèle.
4. Efficacité des paramètres
Les méthodes PEFT et ReFT sont toutes deux conçues pour l'efficacité des paramètres, mais la méthode ReFT s'est avérée être une efficacité des paramètres plus élevée dans la pratique. Par exemple, les méthodes LoReFT (ReFT de sous-espace linéaire de bas rang) nécessitent généralement 10 à 50 fois moins de paramètres à entraîner que la méthode PEFT de pointe (LoRA), tout en obtenant des performances compétitives ou meilleures sur divers benchmarks NLP.
5. Interprétabilité
Alors que la méthode PEFT se concentre principalement sur une adaptation efficace, la méthode ReFT apporte des avantages supplémentaires en termes d'interprétabilité. En intervenant dans des représentations connues pour coder des informations sémantiques spécifiques, les méthodes ReFT peuvent fournir un aperçu de la manière dont les modèles de langage traitent et comprennent le langage, conduisant potentiellement à des systèmes d'intelligence artificielle plus transparents et plus fiables.
Architecture ReFT
L'architecture du modèle ReFT définit le concept général d'intervention, ce qui signifie essentiellement la modification de la représentation cachée lors du passage en avant du modèle. Nous considérons d'abord un modèle de langage basé sur un transformateur qui génère des représentations contextualisées de séquences de jetons.
Étant donné une séquence de n jetons d'entrée x = (x₁,…,xn), le modèle l'intègre d'abord dans une liste de représentations, en termes de h₁,…,hn. Ensuite, la couche m calcule en continu la jième représentation cachée. Chaque représentation cachée est un vecteur h∈λ, où d est la dimension de la représentation.
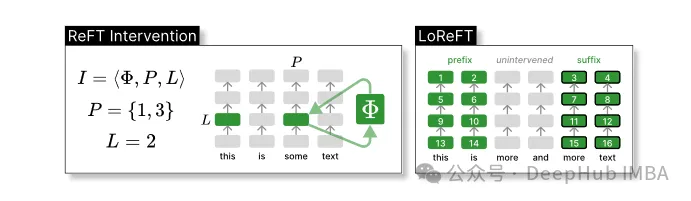
ReFT définit la notion d'intervention qui modifie la représentation cachée lors du passage vers l'avant du modèle.
Intervention I est un tuple ⟨Φ, P, L , qui encapsule l'action d'intervention d'un seul temps d'inférence représenté par le calcul LM basé sur le transformateur. Cette fonction contient trois paramètres :
Fonction d'intervention Φ : représentée. par le paramètre appris Φ (Φ).
L'ensemble des positions d'entrée P≤{1,…,n} auxquelles l'intervention est appliquée.
Intervenir sur la couche L∈{1,…,m}.
Ensuite, l'action d'intervention est la suivante :
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}Cette intervention est effectuée immédiatement après la fin du calcul de propagation vers l'avant, elle affectera donc la représentation calculée dans les couches suivantes.
Afin d'améliorer l'efficacité du calcul, les poids d'intervention peuvent également être décomposés en bas rang, ce qui consiste à obtenir un sous-espace linéaire de bas rang ReFT (LoReFT).
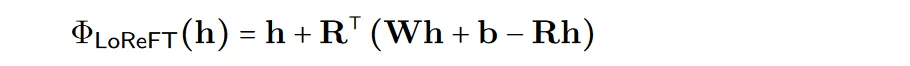
Utilisez la source de projection apprise Rs = Wh +b dans la formule ci-dessus. LoReFT édite la représentation dans le sous-espace R-dimensionnel des R colonnes pour prendre les valeurs obtenues à partir de notre projection linéaire Wh + b.
Pour les tâches de génération, l'article ReFT utilise l'objectif de formation de la modélisation du langage, en se concentrant sur la minimisation de la perte d'entropie croisée sur toutes les positions de sortie.
exemple de code de bibliothèque pyreft
Parallèlement à leur article, des chercheurs de l'Université de Stanford ont également publié la bibliothèque pyreft, une bibliothèque construite sur pyvene pour exécuter et entraîner des interventions d'activation sur des modèles PyTorch arbitraires.
pyreft est compatible avec n'importe quel modèle de langage pré-entraîné disponible sur HuggingFace et peut être affiné à l'aide de la méthode ReFT. Voici un exemple de code montrant comment effectuer une seule intervention sur la sortie de la 19ème couche du modèle lama-27b :
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()Le code restant n'est pas différent du modèle d'entraînement HuggingFace :
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
Une fois la formation terminée, vous pouvez vérifier les informations du modèle :
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))Test de performances de LoReFT
Enfin, jetons un coup d'œil à ses excellentes performances dans divers benchmarks PNL. Voici les données présentées par des chercheurs de l'Université de Stanford.
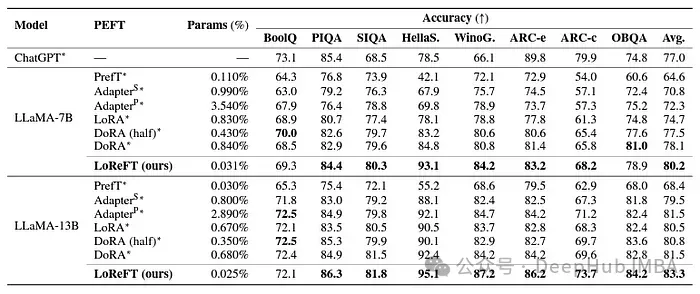
LoReFT atteint des performances de pointe sur 8 ensembles de données difficiles, dont BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c et OBQA. Bien qu'elle utilise beaucoup moins de paramètres que les méthodes PEFT existantes (10 à 50 fois moins), LoReFT surpasse considérablement toutes les autres méthodes, démontrant son efficacité à capturer et à exploiter les connaissances de bon sens codées dans de grands modèles de langage.
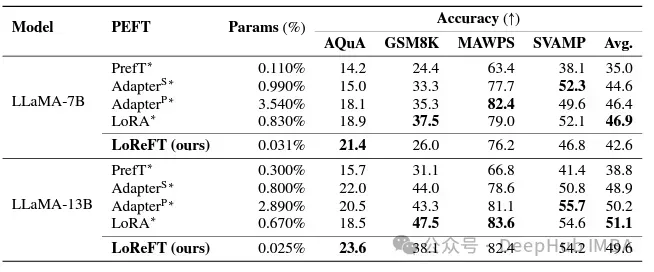
Bien que LoReFT ne surpasse pas les méthodes PEFT existantes sur les tâches de raisonnement mathématique, il démontre des performances compétitives sur des ensembles de données tels que AQuA, GSM8K, MAWPS et SVAMP. Les chercheurs ont noté que les performances de LoReFT s'améliorent avec la taille du modèle, ce qui suggère que ses capacités s'étendent à mesure que les modèles de langage continuent de croître.
Dans le domaine du respect des instructions, LoReFT a obtenu des résultats remarquables, surpassant toutes les méthodes de réglage fin du benchmark Alpaca-Eval v1.0, y compris le réglage fin complet (notez ceci). Lorsqu'il est formé sur le modèle lama-27b, LoReFT est 1 % meilleur que le modèle GPT-3.5 Turbo, tout en utilisant beaucoup moins de paramètres que les autres méthodes PEFT.
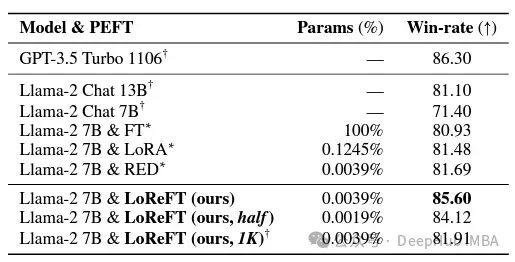
LoReFT démontre également ses capacités dans les tâches de compréhension du langage naturel, atteignant des performances comparables aux méthodes PEFT existantes sur le benchmark GLUE lorsqu'elles sont appliquées aux modèles RoBERTa-base et RoBERTa-large.
En faisant correspondre la méthode PEFT précédente la plus efficace en termes de nombre de paramètres, LoReFT a obtenu des scores similaires dans une variété de tâches, y compris l'analyse des sentiments et le raisonnement en langage naturel.
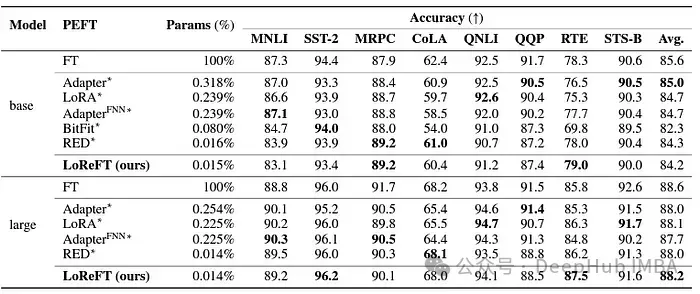
Résumé
Le succès de ReFT, en particulier de LoReFT, est d'une grande importance pour l'avenir du traitement du langage naturel et l'application pratique de grands modèles de langage. L'efficacité des paramètres de ReFT en fait une solution efficace pour adapter de grands modèles de langage à des tâches ou des domaines spécifiques tout en minimisant les ressources de calcul et le temps de formation.
Et ReFT offre également une perspective unique pour améliorer l'interprétabilité des grands modèles de langage. La réussite dans des tâches telles que le raisonnement de bon sens, le raisonnement arithmétique et le suivi d'instructions démontre l'efficacité de cette approche. À l'heure actuelle, ReFT devrait ouvrir de nouvelles possibilités et surmonter les limites des méthodes de réglage traditionnelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Intelligence artificielle générale, perception de l'intelligence artificielle et grands modèles de langage
- AMD présente le GPU Instinct MI300X : conçu pour les grands modèles de langage et l'informatique IA
- Kunlun Wanwei lance Tiangong AI Search : le premier outil de recherche d'IA national intégrant des modèles linguistiques à grande échelle
- Microsoft lance le modèle Phi-2 de 2,7 milliards de paramètres, qui surpasse de nombreux grands modèles de langage
- La différence entre les grands modèles de langage et les modèles d'intégration de mots