
Maison >Périphériques technologiques >IA >Plusieurs SOTA ! OV-Uni3DETR : Améliorer la généralisabilité de la détection 3D à travers les catégories, scènes et modalités (Tsinghua & HKU)
Plusieurs SOTA ! OV-Uni3DETR : Améliorer la généralisabilité de la détection 3D à travers les catégories, scènes et modalités (Tsinghua & HKU)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-11 19:46:18675parcourir
Cet article traite du domaine de la détection d'objets 3D, en particulier de la détection d'objets 3D pour Open-Vocabulary. Dans les tâches traditionnelles de détection d'objets 3D, les systèmes doivent prédire l'emplacement des objets dans des scènes réelles, des cadres de délimitation 3D et des étiquettes de catégories sémantiques, qui s'appuient généralement sur des nuages de points ou des images RVB. Bien que la technologie de détection d’objets 2D soit performante en raison de son omniprésence et de sa rapidité, des recherches pertinentes montrent que le développement de la détection universelle 3D est à la traîne en comparaison. Actuellement, la plupart des méthodes de détection d'objets 3D reposent encore sur un apprentissage entièrement supervisé et sont limitées par des données entièrement annotées dans des modes de saisie spécifiques, et ne peuvent reconnaître que les catégories qui émergent au cours de l'entraînement, que ce soit dans des scènes intérieures ou extérieures.
Cet article souligne que les défis auxquels est confrontée la détection universelle d'objets 3D incluent principalement : les détecteurs 3D existants ne peuvent fonctionner qu'avec une agrégation de vocabulaire fermée, et ne peuvent donc détecter que des catégories déjà vues. La détection d'objets 3D d'Open-Vocabulary est nécessaire de toute urgence pour identifier et localiser de nouvelles instances d'objets de classe non acquises pendant la formation. Les ensembles de données de détection 3D existants sont limités en taille et en catégorie par rapport aux ensembles de données 2D, ce qui limite la capacité de généralisation dans la localisation de nouveaux objets. De plus, le manque de modèles image-texte pré-entraînés dans le domaine 3D exacerbe encore les défis de la détection 3D à vocabulaire ouvert. Dans le même temps, il manque une architecture unifiée pour la détection 3D multimodale, et les détecteurs 3D existants sont pour la plupart conçus pour des modalités d'entrée spécifiques (nuages de points, images RVB ou les deux), ce qui entrave l'utilisation efficace des données de différentes modalités et scènes (intérieures ou extérieures), limitant ainsi la capacité de généralisation à de nouvelles cibles.
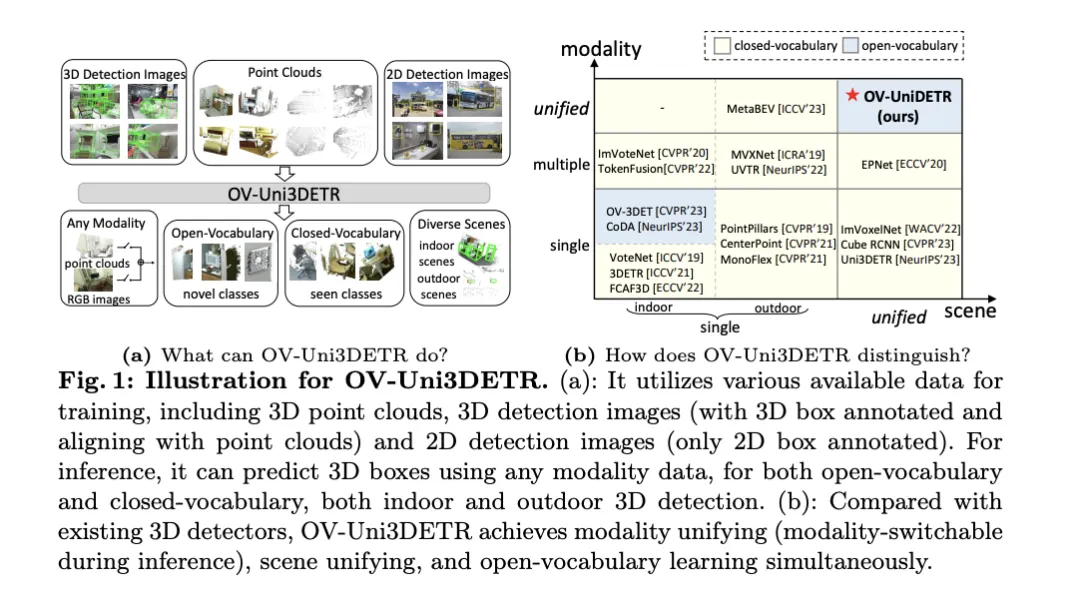
Afin de résoudre les problèmes ci-dessus, l'article propose un détecteur 3D multimodal unifié appelé OV-Uni3DETR. Le détecteur est capable d'utiliser des données multimodales et multisources pendant l'entraînement, notamment des nuages de points, des nuages de points avec des annotations de boîtes 3D précises et des images de détection 3D alignées sur des nuages de points, ainsi que des images de détection 2D contenant uniquement des annotations de boîtes 2D. Grâce à cette méthode d'apprentissage multimodale, OV-Uni3DETR est capable de traiter des données de n'importe quelle modalité pendant l'inférence, de réaliser une commutation modale pendant les tests et de bien détecter les catégories de base et les nouvelles catégories. La structure unifiée permet en outre à OV-Uni3DETR de détecter dans des scènes intérieures et extérieures, avec des capacités de vocabulaire ouvert, améliorant ainsi considérablement l'universalité du détecteur 3D à travers les catégories, scènes et modalités.
De plus, visant à résoudre le problème de savoir comment généraliser le détecteur pour identifier de nouvelles catégories et comment apprendre à partir d'un grand nombre d'images de détection 2D sans annotations de boîte 3D, l'article propose une méthode appelée propagation en mode périodique—— Grâce à cela Dans cette approche, les connaissances se propagent entre les modalités 2D et 3D pour relever les deux défis. De cette manière, les riches connaissances sémantiques du détecteur 2D peuvent être propagées au domaine 3D pour aider à découvrir de nouvelles boîtes, et les connaissances géométriques du détecteur 3D peuvent être utilisées pour localiser des objets dans l'image de détection 2D et faire correspondre les étiquettes de classification. grâce à la correspondance.
Les principales contributions de l'article incluent la proposition d'un détecteur 3D à vocabulaire ouvert unifié OV-Uni3DETR qui peut détecter n'importe quelle catégorie de cibles dans différentes modalités et diverses scènes ; la proposition d'un détecteur multimodal unifié pour l'architecture des scènes intérieures et extérieures ; un concept de boucle de propagation des connaissances entre les modalités 2D et 3D est proposé. Grâce à ces innovations, OV-Uni3DETR atteint des performances de pointe sur plusieurs tâches de détection 3D et surpasse considérablement les méthodes précédentes dans le cadre du vocabulaire ouvert. Ces résultats montrent qu'OV-Uni3DETR a franchi une étape importante pour le développement futur des modèles de base 3D.
Explication détaillée de la méthode OV-Uni3DETR
Apprentissage multimodal
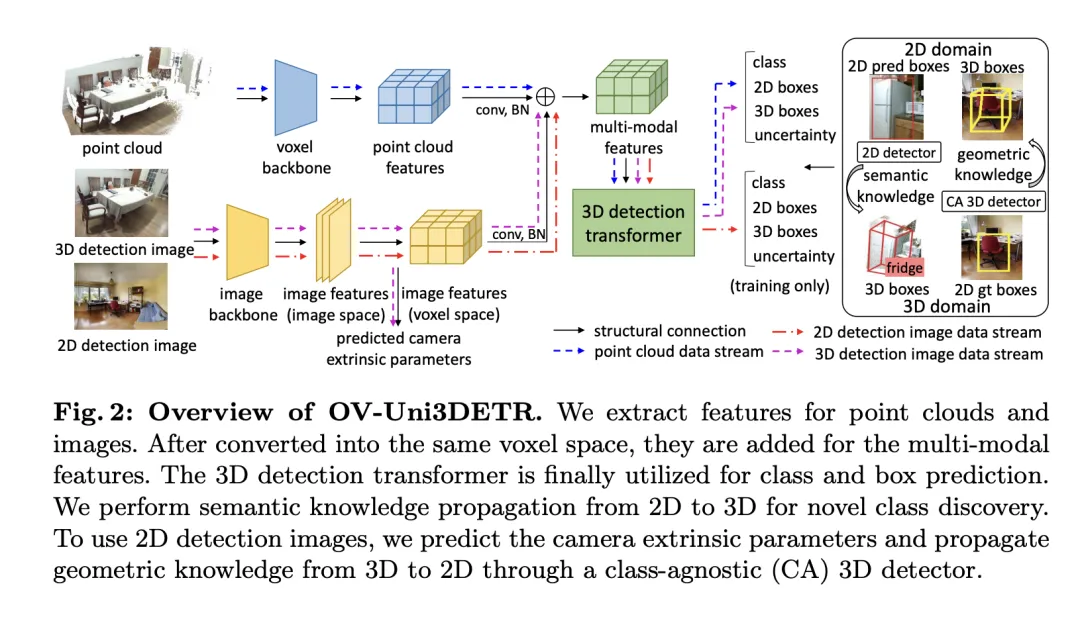
Cet article présente un cadre d'apprentissage multimodal spécifiquement pour les tâches de détection de cibles 3D en intégrant des données cloud et des données d'image. Améliorez les performances de détection. Ce cadre peut gérer certaines modalités de capteur qui peuvent manquer lors de l'inférence, c'est-à-dire qu'il a également la possibilité de changer de mode pendant les tests. Les caractéristiques de deux modalités différentes, y compris les caractéristiques de nuage de points 3D et les caractéristiques d'image 2D, sont extraites et intégrées via une structure de réseau spécifique. Après le traitement élémentaire et le mappage des paramètres de la caméra, ces caractéristiques sont fusionnées pour les tâches de détection de cible ultérieures.
Les points techniques clés incluent l'utilisation de la convolution 3D et de la normalisation par lots pour normaliser et intégrer les fonctionnalités de différents modes afin d'éviter qu'une incohérence au niveau des fonctionnalités entraîne l'ignorance d'un certain mode. De plus, la stratégie de formation consistant à changer de mode de manière aléatoire garantit que le modèle peut traiter de manière flexible les données d'un seul mode, améliorant ainsi la robustesse et l'adaptabilité du modèle.
En fin de compte, l'architecture utilise une fonction de perte composite qui combine les pertes dues à la prédiction de classe, à la régression du cadre de délimitation 2D et 3D et à une prédiction d'incertitude pour une perte de régression pondérée afin d'optimiser l'ensemble du processus de détection. Cette méthode d'apprentissage multimodale améliore non seulement les performances de détection des catégories existantes, mais améliore également la capacité de généralisation à de nouvelles catégories en fusionnant différents types de données. L'architecture multimodale prédit finalement les étiquettes de classe, les boîtes 4D 2D et les boîtes 7D 3D pour la détection d'objets 2D et 3D. Pour la régression en boîte 3D, la perte L1 et la perte IoU découplée sont utilisées ; pour la régression en boîte 2D, la perte L1 et la perte GIoU sont utilisées. Dans le cadre de vocabulaire ouvert, il existe de nouveaux échantillons de catégories, ce qui augmente la difficulté de formation des échantillons. Par conséquent, la prédiction de l’incertitude 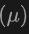 est introduite et utilisée pour pondérer la perte de régression L1. La perte d'apprentissage de la détection d'objets est la suivante :
est introduite et utilisée pour pondérer la perte de régression L1. La perte d'apprentissage de la détection d'objets est la suivante :
Pour certaines scènes 3D, il peut y avoir des images multi-vues au lieu d'une seule image monoculaire. Pour chacun d’eux, les caractéristiques de l’image sont extraites et projetées dans l’espace voxel à l’aide de la matrice de projection respective. Plusieurs caractéristiques d'image dans l'espace voxel sont additionnées pour obtenir des caractéristiques multimodales. Cette approche améliore la capacité de généralisation du modèle à de nouvelles catégories et améliore l'adaptabilité dans diverses conditions d'entrée en combinant des informations provenant de différentes modalités.
Propagation des connaissances : 2D — 3D
Basée sur l'apprentissage multimodal introduit, une méthode appelée « Propagation des connaissances :  » est implémentée pour la détection 3D du vocabulaire ouvert. Le problème central de l’apprentissage du vocabulaire ouvert est d’identifier de nouvelles catégories qui n’ont pas été annotées manuellement au cours du processus de formation. En raison de la difficulté d'obtenir des données sur les nuages de points, des modèles de langage visuel pré-entraînés n'ont pas encore été développés dans le domaine des nuages de points. Les différences modales entre les données de nuages de points et les images RVB limitent les performances de ces modèles en détection 3D.
» est implémentée pour la détection 3D du vocabulaire ouvert. Le problème central de l’apprentissage du vocabulaire ouvert est d’identifier de nouvelles catégories qui n’ont pas été annotées manuellement au cours du processus de formation. En raison de la difficulté d'obtenir des données sur les nuages de points, des modèles de langage visuel pré-entraînés n'ont pas encore été développés dans le domaine des nuages de points. Les différences modales entre les données de nuages de points et les images RVB limitent les performances de ces modèles en détection 3D.

Pour résoudre ce problème, il est proposé d'utiliser les connaissances sémantiques d'un détecteur de vocabulaire ouvert 2D pré-entraîné et de générer des cadres de délimitation 3D correspondants pour de nouvelles catégories. Ces boîtes 3D générées compléteront les étiquettes de vérité terrain 3D limitées disponibles pendant la formation.
Plus précisément, les cadres de délimitation 2D ou les masques d'instance sont d'abord générés à l'aide du détecteur 2DOpen-Vocabulary. Étant donné que les données et annotations disponibles dans le domaine 2D sont plus riches, ces boîtes 2D générées peuvent atteindre une plus grande précision de positionnement et couvrir un plus large éventail de catégories. Ensuite, ces boîtes 2D sont projetées dans l'espace 3D via 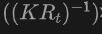 pour obtenir les boîtes 3D correspondantes. L'opération spécifique consiste à utiliser
pour obtenir les boîtes 3D correspondantes. L'opération spécifique consiste à utiliser 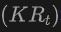
pour projeter des points 3D dans l'espace 2D, trouver les points dans la boîte 2D, puis regrouper ces points dans la boîte 2D pour éliminer les valeurs aberrantes afin d'obtenir la boîte 3D correspondante. Grâce à la présence de détecteurs 2D pré-entraînés, de nouveaux objets non étiquetés peuvent être découverts dans le coffret 3D généré. De cette manière, la détection de 3DOpen-Vocabulary est grandement facilitée par la riche connaissance sémantique propagée du domaine 2D vers les boîtes 3D générées. Pour les images multi-vues, les boîtes 3D sont générées séparément et intégrées ensemble pour une utilisation finale.
Lors de l'inférence, lorsque les nuages de points et les images sont disponibles, les boîtes 3D peuvent être extraites de la même manière. Ces boîtes 3D générées peuvent également être considérées comme une forme de résultats de détection 3DOpen-Vocabulary. Ces boîtes 3D sont ajoutées aux prédictions du transformateur 3D multimodal pour compléter les éventuels objets manquants et filtrer les boîtes englobantes qui se chevauchent via la suppression 3D non maximale (NMS). Le score de confiance attribué par le détecteur 2D pré-entraîné est systématiquement divisé par une constante prédéterminée puis réinterprété comme le score de confiance de la case 3D correspondante.
Expérience
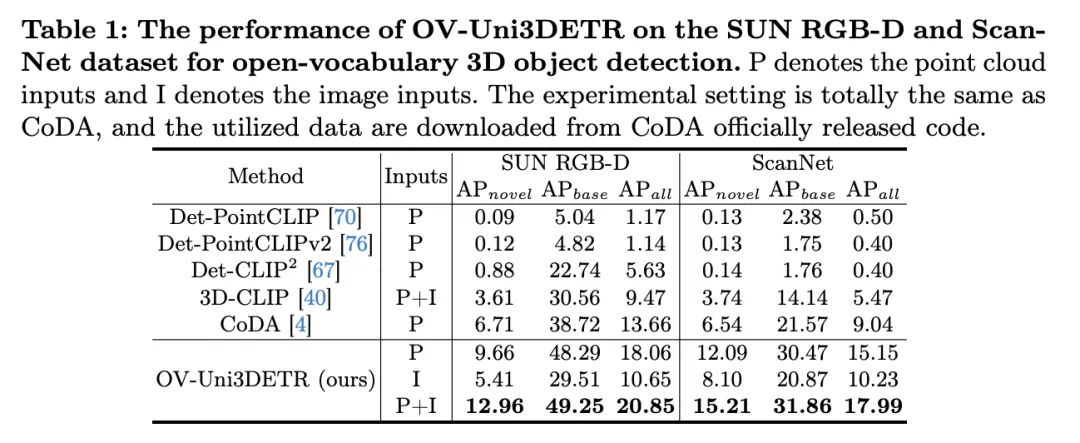
Die Tabelle zeigt die Leistung von OV-Uni3DETR für die Open-Vocabulary3D-Objekterkennung in SUN RGB-D- und ScanNet-Datensätzen. Die experimentellen Einstellungen sind genau die gleichen wie bei CoDA, und die verwendeten Daten stammen aus dem offiziell veröffentlichten Code von CoDA. Zu den Leistungsmetriken gehören die durchschnittliche Genauigkeit der neuen Klasse 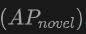 , die durchschnittliche Genauigkeit der Basisklasse
, die durchschnittliche Genauigkeit der Basisklasse 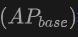 und die durchschnittliche Genauigkeit aller Klassen
und die durchschnittliche Genauigkeit aller Klassen 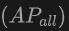 . Zu den Eingabetypen gehören Punktwolken (P), Bilder (I) und deren Kombinationen (P+I).
. Zu den Eingabetypen gehören Punktwolken (P), Bilder (I) und deren Kombinationen (P+I).
Bei der Analyse dieser Ergebnisse können wir folgende Punkte beobachten:
-
Vorteile der multimodalen Eingabe: Bei Verwendung einer Kombination aus Punktwolken und Bildern als Eingabe schneidet OV-Uni3DETR bei allen Bewertungsmetriken der beiden Datensätze gut ab Es erzielte in allen Aspekten die höchste Punktzahl, insbesondere die Verbesserung der durchschnittlichen Genauigkeit neuer Kategorien
 ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann.
ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann. - Vergleich mit anderen Methoden: Im Vergleich zu anderen punktwolkenbasierten Methoden (wie Det-PointCLIP, Det-PointCLIPv2, Det-CLIP, 3D-CLIP und CoDA) weist OV-Uni3DETR bei allen Auswertungen eine überlegene Leistung auf Kennzahlen Hervorragende Leistung. Dies zeigt die Wirksamkeit von OV-Uni3DETR bei der Bewältigung von Open-Vocabulary3D-Objekterkennungsaufgaben, insbesondere bei der Nutzung multimodaler Lern- und Wissensverbreitungsstrategien.
- Vergleich von Bild- und Punktwolkeneingabe: Obwohl die Leistung von OV-Uni3DETR, bei der nur Bild (I) als Eingabe verwendet wird, geringer ist als die bei Verwendung von Punktwolke (P) als Eingabe, zeigt es dennoch gute Erkennungsfähigkeiten. Dies beweist die Flexibilität und Anpassungsfähigkeit der OV-Uni3DETR-Architektur an einzelne Modaldaten und unterstreicht auch die Bedeutung der Fusion mehrerer Modaldaten zur Verbesserung der Erkennungsleistung.
-
Leistung bei neuen Kategorien: Besonders hervorzuheben ist die Leistung von OV-Uni3DETR bei der durchschnittlichen Genauigkeit neuer Kategorien, was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe.
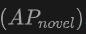 ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann.
ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann. 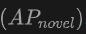 , was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte
, was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte 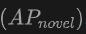 bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe.
bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe. Im Allgemeinen zeigt OV-Uni3DETR durch seine einheitliche multimodale Lernarchitektur eine hervorragende Leistung bei Open-Vocabulary3D-Objekterkennungsaufgaben, insbesondere bei der Kombination von Punktwolken- und Bilddaten, und kann die Erkennungsgenauigkeit neuer Objekte effektiv verbessern Kategorien beweisen die Wirksamkeit und Bedeutung multimodaler Input- und Wissensverbreitungsstrategien.
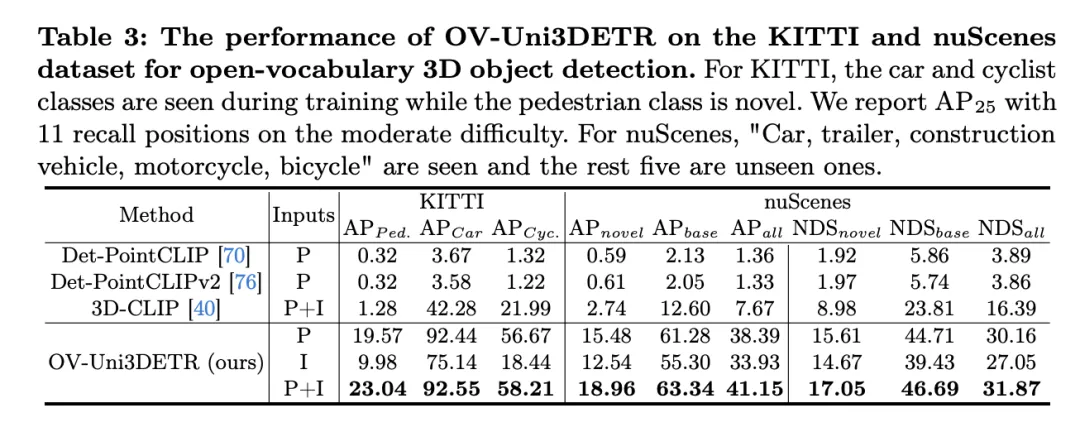
Diese Tabelle zeigt die Leistung von OV-Uni3DETR für die Open-Vocabulary3D-Objekterkennung in KITTI- und nuScenes-Datensätzen und deckt Kategorien ab, die während des Trainingsprozesses gesehen (Basis) und unsichtbar (Roman) wurden. Für den KITTI-Datensatz wurden die Kategorien „Auto“ und „Radfahrer“ während des Trainings gesehen, während die Kategorie „Fußgänger“ neu ist. Die Leistung wird anhand der 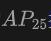
-Metrik bei mittlerem Schwierigkeitsgrad und unter Verwendung von 11 Rückrufpositionen gemessen. Für den nuScenes-Datensatz ist „Auto, Anhänger, Baufahrzeug, Motorrad, Fahrrad“ eine sichtbare Kategorie und die restlichen fünf sind unsichtbare Kategorien. Zusätzlich zu den AP-Indikatoren wird auch NDS (NuScenes Detection Score) zur umfassenden Bewertung der Erkennungsleistung berichtet.
Die Analyse dieser Ergebnisse führt zu folgenden Schlussfolgerungen:
- Wesentliche Vorteile der multimodalen Eingabe: Verglichen mit dem Fall, dass nur Punktwolke (P) oder Bild (I) als Eingabe verwendet werden, wenn sowohl Punktwolke als auch Bild (P+I) als Eingabe verwendet werden, OV – Uni3DETR erhielt bei allen Bewertungskriterien die höchste Punktzahl. Dieses Ergebnis unterstreicht die erheblichen Vorteile des multimodalen Lernens bei der Verbesserung der Erkennungsfähigkeiten für unsichtbare Kategorien und der gesamten Erkennungsleistung.
- Effektivität der Erkennung offener Vokabeln: OV-Uni3DETR zeigt eine hervorragende Leistung bei der Handhabung unsichtbarer Kategorien, insbesondere in der Kategorie „Fußgänger“ des KITTI-Datensatzes und der Kategorie „Roman“ des nuScenes-Datensatzes. Dies zeigt, dass das Modell über eine starke Verallgemeinerungsfähigkeit für neuartige Kategorien verfügt und eine effektive Lösung zur Erkennung von offenem Vokabular darstellt.
- Vergleich mit anderen Methoden: Im Vergleich zu anderen punktwolkenbasierten Methoden (wie Det-PointCLIP, Det-PointCLIPv2 und 3D-CLIP) zeigt OV-Uni3DETR deutliche Leistungsverbesserungen, sowohl bei der Erkennung von Gesehenem als auch Unsichtbarem Kategorien. Dies zeigt seinen Fortschritt bei der Handhabung von Open-Vocabulary3D-Objekterkennungsaufgaben.
- Vergleich von Bildeingabe und Punktwolkeneingabe: Obwohl die Leistung der Bildeingabe etwas geringer ist als die der Punktwolkeneingabe, kann die Bildeingabe immer noch eine relativ hohe Erkennungsgenauigkeit bieten, was die Anpassungsfähigkeit des OV zeigt -Uni3DETR-Architektur und Flexibilität.
- Umfassender Bewertungsindex: Aus den Ergebnissen des NDS-Bewertungsindex geht hervor, dass OV-Uni3DETR nicht nur bei der Erkennungsgenauigkeit gut abschneidet, sondern auch bei der Gesamterkennungsqualität hohe Werte erzielt, insbesondere in Kombination mit Punktwolken und Bildern Daten.
OV-Uni3DETR zeigt eine hervorragende Leistung bei der Open-Vocabulary3D-Objekterkennung, insbesondere bei der Verarbeitung unsichtbarer Kategorien und multimodaler Daten. Diese Ergebnisse bestätigen die Wirksamkeit der multimodalen Eingabe- und Wissensverbreitungsstrategie sowie das Potenzial von OV-Uni3DETR zur Verbesserung der Generalisierungsfähigkeit von 3D-Objekterkennungsaufgaben.
Diskussion

Dieses Papier bringt erhebliche Fortschritte auf dem Gebiet der 3D-Objekterkennung mit offenem Vokabular, indem es OV-Uni3DETR vorschlägt, einen einheitlichen multimodalen 3D-Detektor. Diese Methode nutzt multimodale Daten (Punktwolken und Bilder), um die Erkennungsleistung zu verbessern, und erweitert effektiv die Erkennungsfähigkeiten des Modells für unsichtbare Kategorien durch eine 2D-zu-3D-Wissensverbreitungsstrategie. Experimentelle Ergebnisse an mehreren öffentlichen Datensätzen zeigen die hervorragende Leistung von OV-Uni3DETR bei neuen Klassen und Basisklassen, insbesondere bei der Kombination von Punktwolken- und Bildeingaben, wodurch die Erkennungsfähigkeiten neuer Klassen erheblich verbessert werden können, während gleichzeitig auch die Gesamterkennungsleistung einen neuen Stand erreicht hat Höhe.
In Bezug auf die Vorteile demonstriert OV-Uni3DETR zunächst das Potenzial des multimodalen Lernens zur Verbesserung der 3D-Zielerkennungsleistung. Durch die Integration von Punktwolken- und Bilddaten ist das Modell in der Lage, ergänzende Merkmale jeder Modalität zu erlernen und so eine genauere Erkennung komplexer Szenen und verschiedener Zielkategorien zu ermöglichen. Zweitens ist OV-Uni3DETR durch die Einführung eines 2D-zu-3D-Wissenstransfermechanismus in der Lage, umfangreiche 2D-Bilddaten und vorab trainierte 2D-Erkennungsmodelle zu nutzen, um neue Kategorien zu identifizieren und zu lokalisieren, die während des Trainingsprozesses nicht gesehen wurden, was den Prozess erheblich verbessert Verallgemeinerungsfähigkeit des Modells. Darüber hinaus zeigt diese Methode leistungsstarke Fähigkeiten bei der Verarbeitung der Open-Vocabulary-Erkennung und eröffnet neue Forschungsrichtungen und potenzielle Anwendungen im Bereich der 3D-Erkennung.
Obwohl OV-Uni3DETR seine Vorteile in vielen Aspekten unter Beweis gestellt hat, gibt es auch einige potenzielle Einschränkungen. Erstens kann multimodales Lernen zwar die Leistung verbessern, es erhöht jedoch auch die Komplexität der Datenerfassung und -verarbeitung. Insbesondere in praktischen Anwendungen kann die Synchronisierung und Registrierung verschiedener modaler Daten Herausforderungen darstellen. Zweitens kann die Wissensverbreitungsstrategie zwar effektiv 2D-Daten zur Unterstützung der 3D-Erkennung nutzen, diese Methode basiert jedoch möglicherweise auf hochwertigen 2D-Erkennungsmodellen und einer genauen 3D-2D-Ausrichtungstechnologie, was in einigen komplexen Umgebungen möglicherweise schwierig zu gewährleisten ist. Darüber hinaus kann bei einigen äußerst seltenen Kategorien sogar die Erkennung offener Vokabeln mit Herausforderungen bei der Erkennungsgenauigkeit konfrontiert sein, deren Lösung weitere Forschung erfordert.
OV-Uni3DETR hat durch seine innovative multimodale Lern- und Wissensverbreitungsstrategie erhebliche Fortschritte bei der Open-Vocabulary3D-Objekterkennung gemacht. Obwohl es einige potenzielle Einschränkungen gibt, zeigen seine Vorteile das große Potenzial dieser Methode bei der Förderung der Entwicklung und Anwendungserweiterung der 3D-Inspektionstechnologie. Zukünftige Forschungen können weiter untersuchen, wie diese Einschränkungen überwunden werden können und wie diese Strategien auf ein breiteres Spektrum von 3D-Wahrnehmungsaufgaben angewendet werden können.
Fazit
In diesem Artikel haben wir hauptsächlich OV-Uni3DETR vorgeschlagen, einen einheitlichen multimodalen 3D-Detektor mit offenem Vokabular. Mit Hilfe des multimodalen Lernens und der zyklischen modalen Wissensverbreitung kann unser OV-Uni3DETR neue Klassen gut identifizieren und lokalisieren und so eine modale Vereinheitlichung und Szenenvereinheitlichung erreichen. Experimente demonstrieren seine starken Fähigkeiten sowohl in Umgebungen mit offenem als auch geschlossenem Vokabular, sowohl in Innen- als auch in Außenszenen und bei jeder modalen Dateneingabe. Wir sind davon überzeugt, dass unsere Studie, die auf eine einheitliche 3D-Erkennung mit offenem Vokabular in multimodalen Umgebungen abzielt, die nachfolgende Forschung in die vielversprechende, aber herausfordernde Richtung der allgemeinen 3D-Computervision vorantreiben wird.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment implémenter un mur de photos 3D avec javascript (avec code)
- Unity3d peut-il être écrit en python ?
- Que dois-je faire si une erreur se produit lorsque le rendu 3dmax m'est demandé ?
- La dernière architecture profonde pour la détection de cibles a la moitié des paramètres et est 3 fois plus rapide +
- Tout diffuser ? 3DifFusionDet : le modèle de diffusion entre dans la détection de cibles 3D LV fusion !