
Maison >Périphériques technologiques >IA >100 000 $ US pour former le grand modèle Llama-2 ! Tous les Chinois construisent un nouveau ministère de l'Éducation, observe Jia Yangqing, ancien PDG de SD.
100 000 $ US pour former le grand modèle Llama-2 ! Tous les Chinois construisent un nouveau ministère de l'Éducation, observe Jia Yangqing, ancien PDG de SD.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-07 09:04:01644parcourir
Si vous souhaitez en savoir plus sur l'AIGC,
veuillez visiter : 51CTO AI , entraînez de grands modèles au niveau Llama-2.
Le modèle
MoEest plus petit mais a les mêmes performances :
Il s'appelle JetMoE et provient d'instituts de recherche tels que le MIT et Princeton. Les performances dépassent de loin celles du Llama-2 de même taille.
△Jia Yangqing a transmis
Il faut savoir que ce dernier a un coût d'investissement demilliards de dollars
niveau.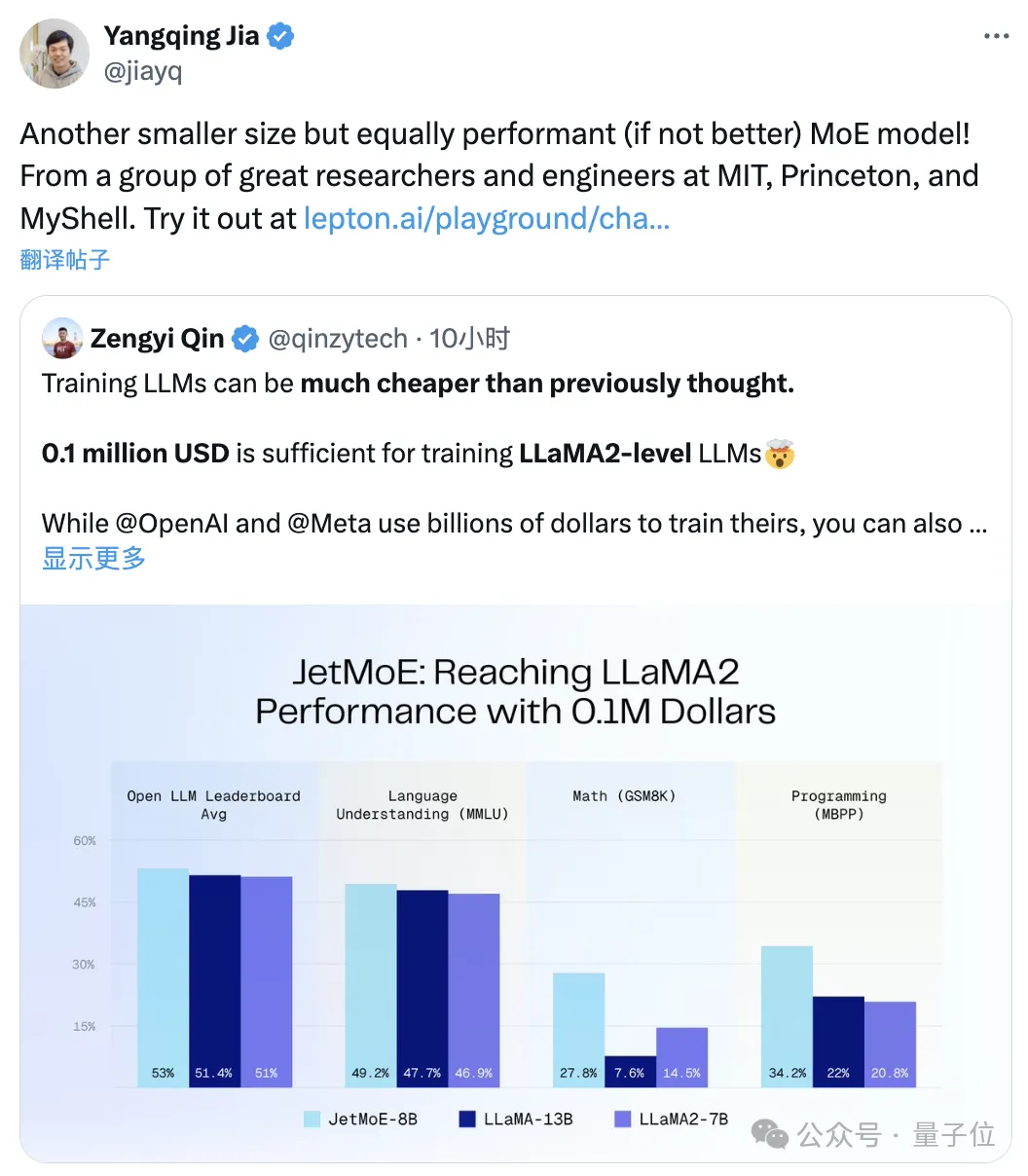
open source et convivial sur le plan académique : en utilisant uniquement des ensembles de données publiques et du code open source, il peut être affiné avec un GPU grand public
. Il faut dire que le coût de construction de grands modèles est vraiment bien moins cher qu’on ne le pense.
Il faut dire que le coût de construction de grands modèles est vraiment bien moins cher qu’on ne le pense.
Ps. Emad, l'ancien patron de Stable Diffusion, a également aimé :
100 000 $ pour atteindre les performances de Llama-2JetMoE s'inspire de l'architecture d'activation clairsemée de ModuleFormer.
(ModuleFormer, une architecture modulaire basée sur Sparse Mixture of Experts (SMoE) pour améliorer l'efficacité et la flexibilité des grands modèles, proposée en juin de l'année dernière) 
MoE est toujours utilisé dans sa couche d'attention :
JetMoE avec 8 milliards Les paramètres ont un total de 24 blocs, chaque bloc contient 2 couches MoE, à savoir attention head mixage
(MoA)et MLP expert mixage (MoE) .
Chaque couche MoA et MoE compte 8 experts, 2 sont activés à chaque fois qu'un jeton est saisi.
JetMoE-8B utilise
1,25T token dans l'ensemble de données publiques pour la formation, avec un taux d'apprentissage de 5,0 x 10-4 et une taille de lot globale de 4 millions de jetons.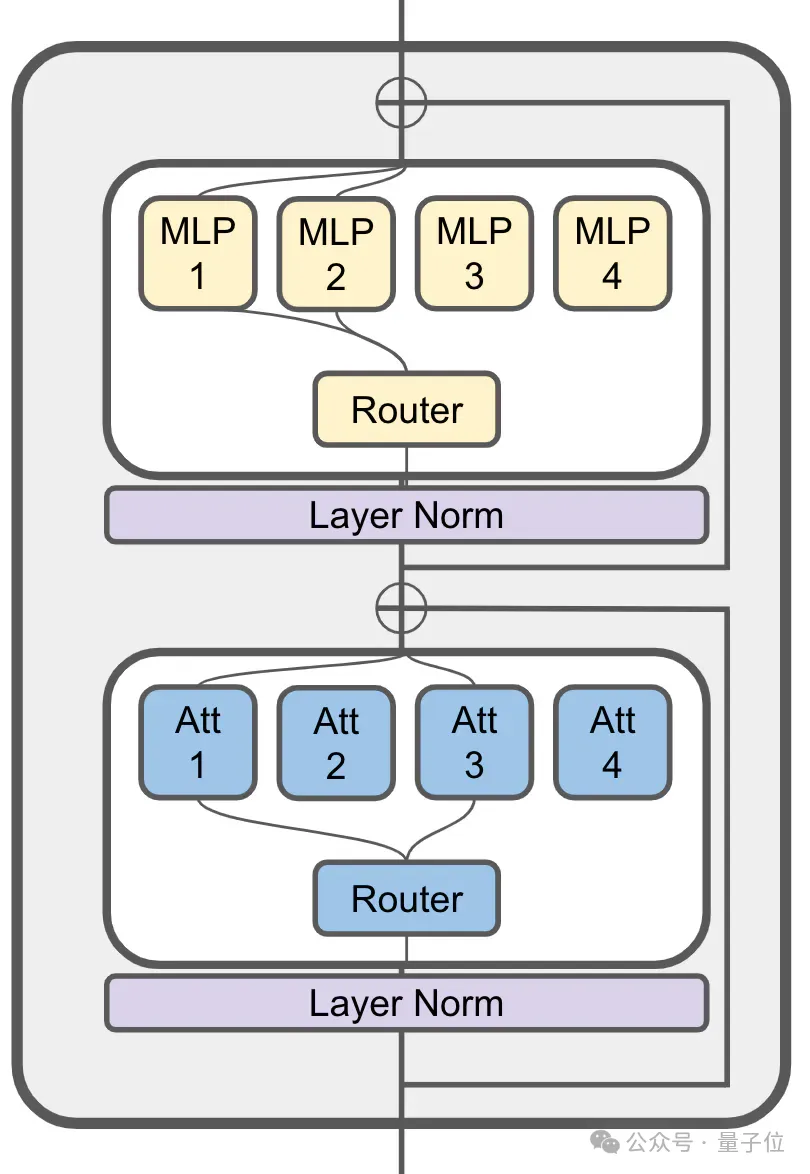
Le plan d'entraînement spécifique suit l'idée du MiniCPM (à partir de l'intelligence face au mur, le modèle 2B peut rattraper Mistral-7B), et comprend
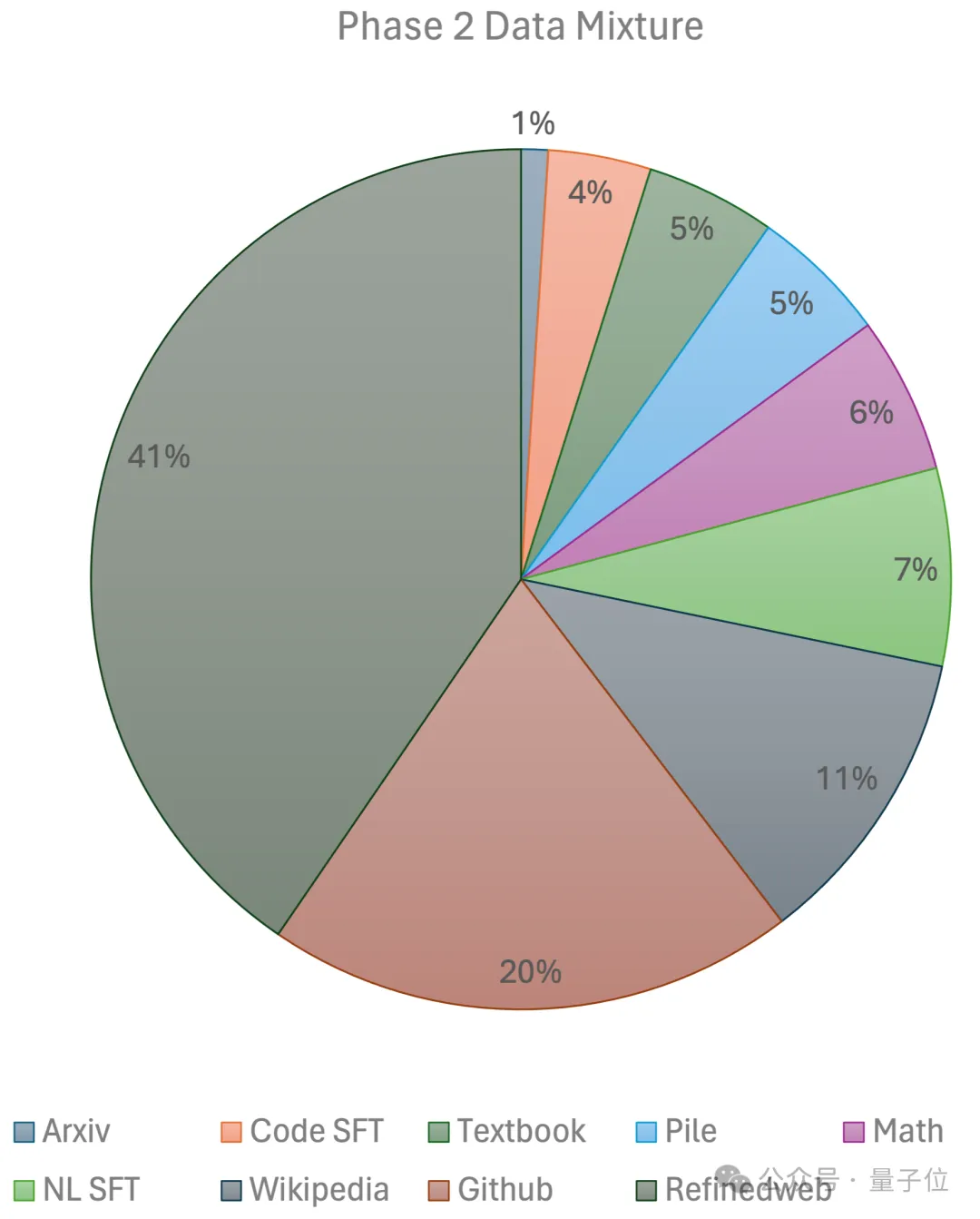
deux étapes : La première l'étape utilise un préchauffage linéaire Taux d'apprentissage constant, formé avec 1 000 milliards de jetons à partir d'ensembles de données de pré-formation open source à grande échelle, notamment RefinedWeb, Pile, données Github, etc. La deuxième étape utilise une décroissance exponentielle du taux d'apprentissage et utilise 250 milliards de jetons pour former des jetons à partir de l'ensemble de données de la première étape et des ensembles de données open source de très haute qualité.
En fin de compte, l'équipe a utilisé 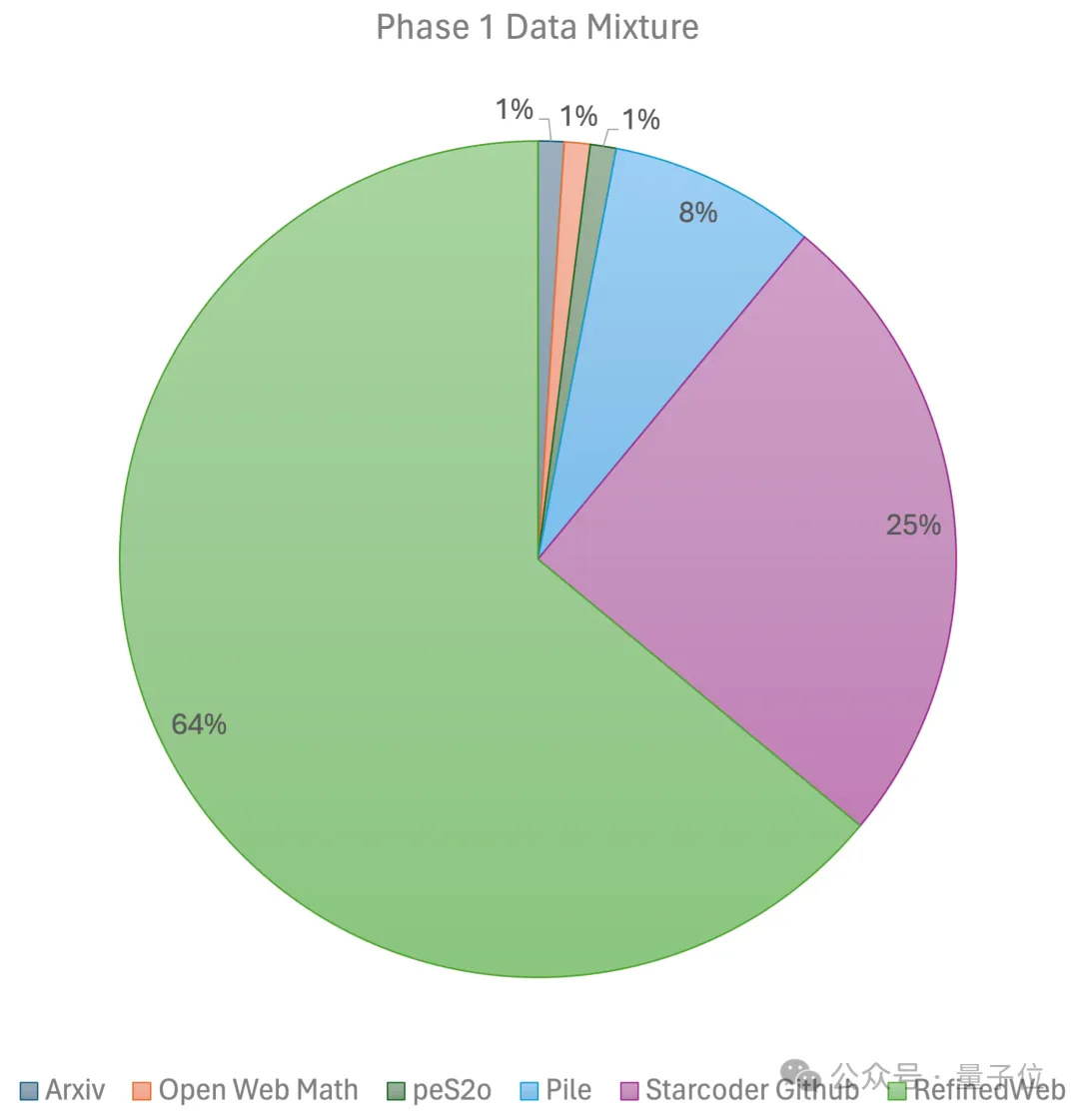
 a passé 2 semaines et environ 80 000 dollars américains
a passé 2 semaines et environ 80 000 dollars américains
pour terminer JetMoE-8B. Plus de détails techniques seront révélés dans le rapport technique publié prochainement. Pendant le processus d'inférence, puisque JetMoE-8B ne dispose que de 2,2 milliards de paramètres d'activation, le coût de calcul est considérablement réduit -
En même temps, il a également atteint de bonnes performances.
Comme le montre la figure ci-dessous : JetMoE-8B a obtenu 5 sota sur 8 critères d'évaluation (y compris le classement Open LLM de la grande arène de modèles) , surpassant LLaMA-13B, LLaMA2-7B et DeepseekMoE-16B.
Score de 6,681 sur le benchmark MT-Bench, surpassant également des modèles tels que LLaMA2 et Vicuna avec 13 milliards de paramètres.
Présentation de l'auteur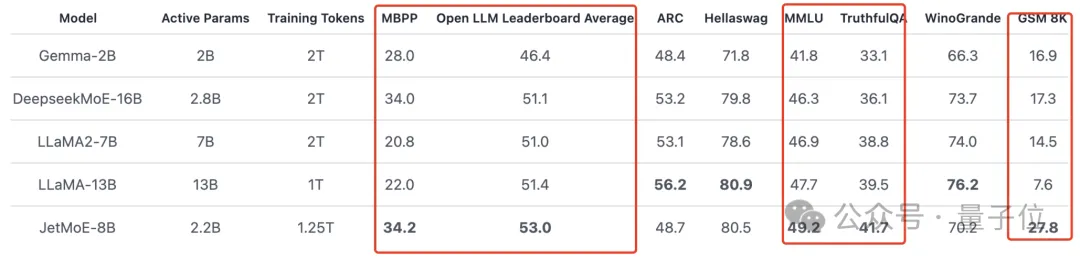
- Yikang Shen
Chercheur au MIT-IBM Watson Lab, direction de recherche PNL.
Diplômé de l'Université de Beihang avec une licence et une maîtrise, ainsi qu'une expérience de doctorat au Mila Research Institute fondé par Yoshua Bengio.
- Guozhen (Gavin Guo)
est doctorant au MIT. Son domaine de recherche est l'apprentissage automatique efficace des données pour l'imagerie 3D.
Diplômé d'un baccalauréat de l'UC Berkeley l'été dernier, il a rejoint le MIT-IBM Watson Lab en tant qu'étudiant chercheur. Son mentor était Yikang Shen et d'autres.
- Cai Tianle
Candidat au doctorat à Princeton, titulaire d'un baccalauréat en mathématiques appliquées et en informatique de l'Université de Pékin, il est actuellement également chercheur à temps partiel à Together.ai, travaillant avec Tri Dao. .
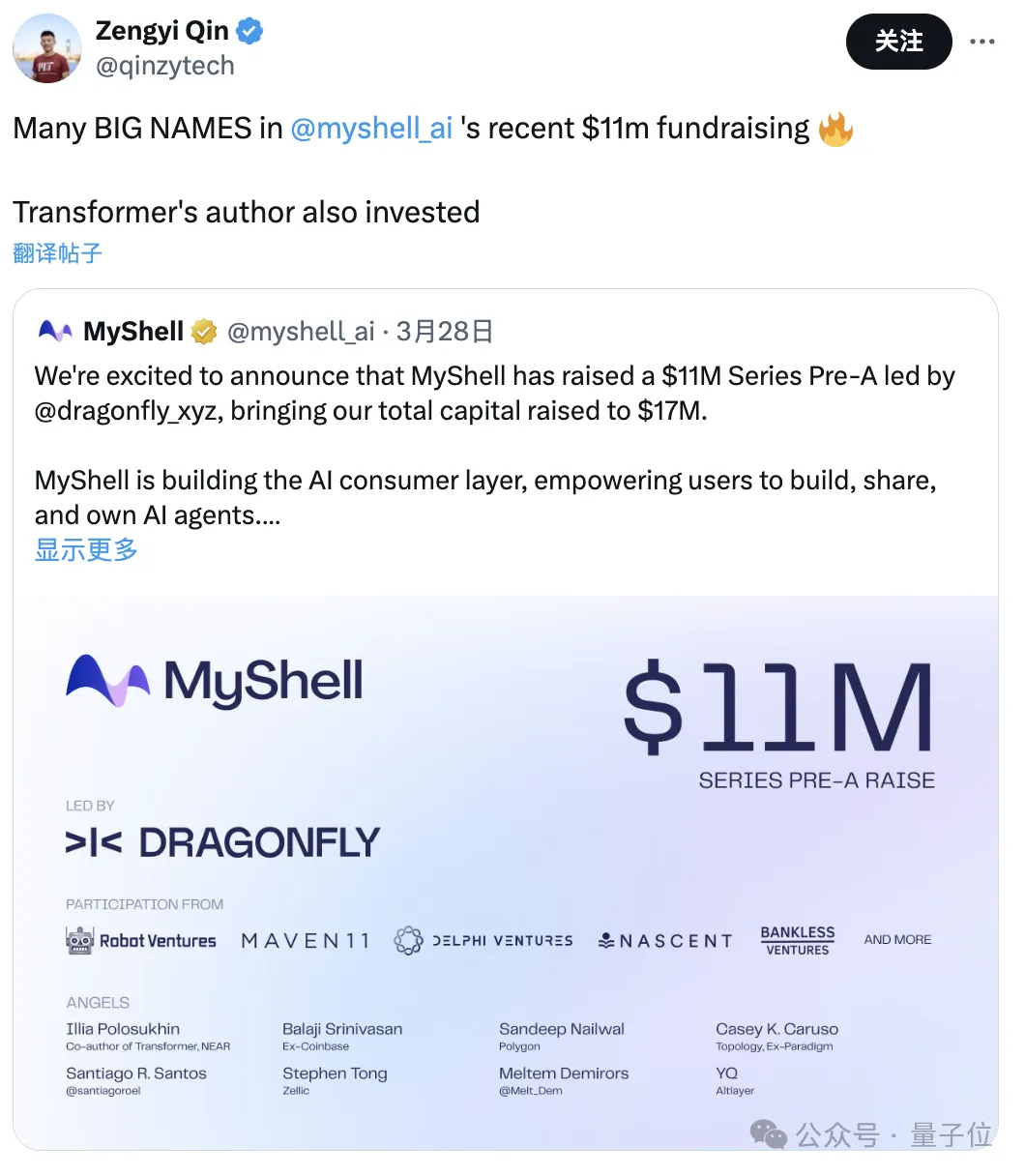
- Zengyi Qin
étudie pour un doctorat au MIT et démarre une entreprise, directeur R&D IA de MyShell.
Cette société vient de lever 11 millions de dollars, et parmi ses investisseurs figure l'auteur de Transformer.
Portail : https://github.com/myshell-ai/JetMoE
Lien de référence : https://twitter.com/jiayq/status/1775935845205463292
Vous voulez en savoir plus sur l'AIGC Pour le contenu,
veuillez visiter : 51CTO AI.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que signifie le modèle Python IPO ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- Implémentez une formation Edge avec moins de 256 Ko de mémoire et le coût est inférieur à un millième de celui de PyTorch
- IBM développe le supercalculateur d'IA cloud natif Vela pour déployer et former de manière flexible des dizaines de milliards de modèles de paramètres
- Problème de temps de formation du modèle d'apprentissage en profondeur