Les modèles AniPortrait sont open source et peuvent être joués librement.
"Un nouvel outil de productivité pour Xiaopozhan Ghost Zone." Récemment, un nouveau projet publié par Tencent Open Source a reçu une telle évaluation sur le pouce. Ce projet est AniPortrait, qui génère des portraits animés de haute qualité basés sur l'audio et une image de référence. Sans plus attendre, jetons un œil à la démo qui peut être prévenue par une lettre d'avocat :  Les images d'anime peuvent aussi parler facilement :
Les images d'anime peuvent aussi parler facilement :  Le projet vient d'être en ligne depuis un quelques jours, et il a déjà reçu de nombreux éloges : le nombre de GitHub Stars a dépassé les 2 800.
Le projet vient d'être en ligne depuis un quelques jours, et il a déjà reçu de nombreux éloges : le nombre de GitHub Stars a dépassé les 2 800. 
Jetons un coup d'œil aux innovations d'AniPortrait. 
- Titre de l'article : AniPortrait : Synthèse audio-pilotée de l'animation de portraits photoréalistes
- Adresse de l'article : https://arxiv.org/pdf/2403.17694.pdf
- Adresse du code : https:/ /arxiv.org/pdf/2403.17694.pdf /github.com/Zejun-Yang/AniPortrait
Le nouveau framework AniPortrait de Tencent contient deux modules : Audio2Lmk et Lmk. 2Vidéo. Audio2Lmk est utilisé pour extraire des séquences Landmark, qui peuvent capturer des expressions faciales complexes et des mouvements de lèvres à partir d'une entrée audio. Lmk2Video utilise cette séquence Landmark pour générer des vidéos de portrait de haute qualité, stables dans le temps et cohérentes. La figure 1 donne un aperçu du framework AniPortrait. 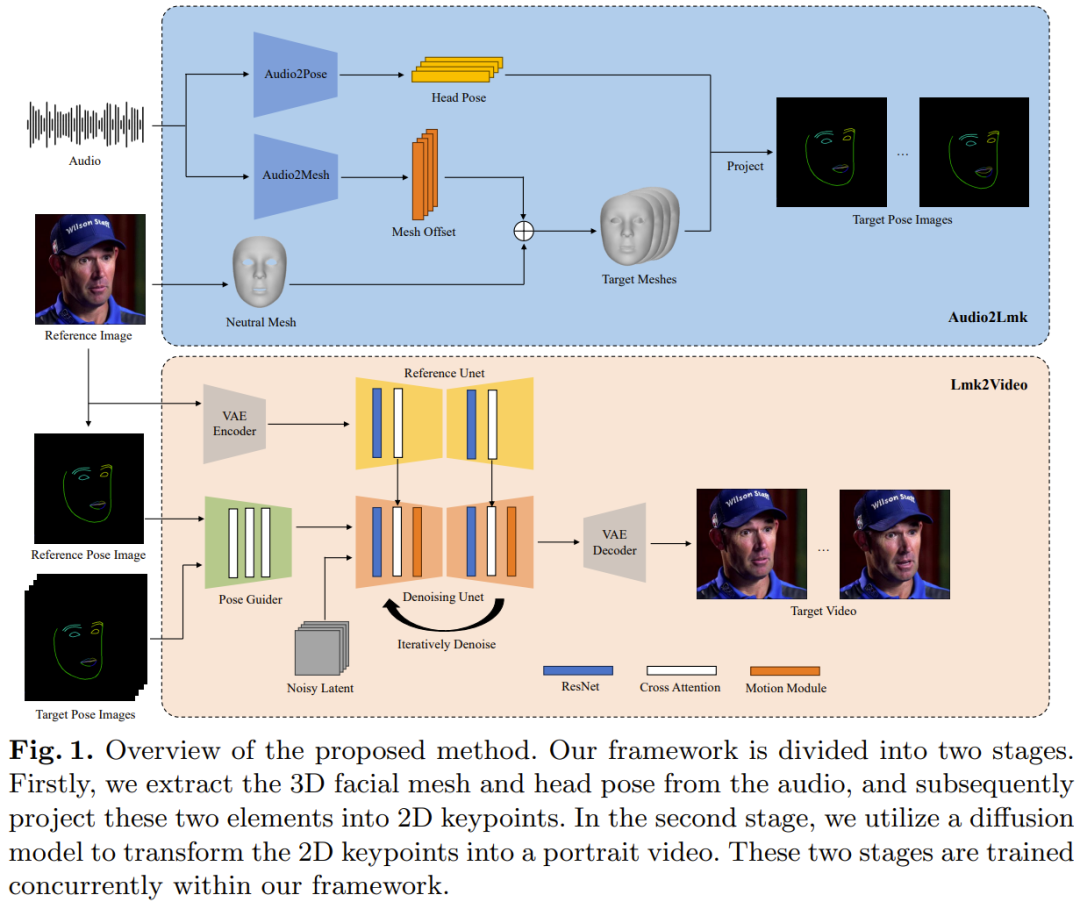
Pour une séquence de clips vocaux, le but ici est de prédire la séquence de maillage de visage 3D et la séquence de gestes correspondantes. L'équipe a utilisé wav2vec pré-entraîné pour extraire les fonctionnalités audio. Le modèle se généralise bien et peut reconnaître avec précision la prononciation et l'intonation de l'audio, ce qui est crucial pour générer des animations faciales réalistes. En exploitant les caractéristiques vocales robustes obtenues, ils peuvent être efficacement convertis en maillages de visage 3D en utilisant une architecture simple composée de deux couches FC. L’équipe a observé que cette conception simple et directe garantit non seulement l’exactitude, mais améliore également l’efficacité du processus d’inférence. Dans la tâche de conversion de l'audio en gestes, le réseau fédérateur utilisé par l'équipe est toujours le même wav2vec. Cependant, les poids de ce réseau sont différents de ceux du réseau du module audio-to-mesh. En effet, les gestes sont plus étroitement liés au rythme et à la hauteur de l'audio, tandis que les tâches audio-grille se concentrent sur un objectif différent (prononciation et intonation). Pour prendre en compte l’impact des états précédents, l’équipe a utilisé un décodeur de transformateur pour décoder la séquence de poses. Dans ce processus, le module utilise un mécanisme d'attention croisée pour intégrer des fonctionnalités audio dans le décodeur. Pour les deux modules ci-dessus, la fonction de perte utilisée pour la formation est une simple perte L1. Après avoir obtenu le maillage et la séquence de pose, utilisez la projection en perspective pour les convertir en une séquence de points de repère de visage 2D. Ces repères sont les signaux d’entrée pour l’étape suivante. Étant donné un portrait de référence et une séquence de visage Landmark, le Lmk2Video proposé par l'équipe peut créer des animations de portrait temporellement cohérentes. Ce processus d'animation aligne le mouvement sur la séquence Landmark tout en conservant une apparence cohérente avec l'image de référence. L'idée adoptée par l'équipe est de représenter l'animation de portraits comme une séquence de cadres de portraits. Cette conception de structure de réseau de Lmk2Video est inspirée d'AnimateAnyone. Le réseau fédérateur est SD1.5, qui intègre un module de mouvement temporel qui convertit efficacement l'entrée de bruit multi-images en une séquence d'images vidéo. De plus, ils ont également utilisé un ReferenceNet, qui utilise également la structure SD1.5. Sa fonction est d'extraire les informations d'apparence de l'image de référence et de l'intégrer dans le réseau fédérateur. Cette conception stratégique garantit que Face ID reste cohérent tout au long de la vidéo de sortie. Contrairement à AnimateAnyone, la complexité de la conception de PoseGuider est améliorée ici. La version originale a simplement intégré plusieurs couches convolutives, puis les fonctionnalités Landmark ont été fusionnées avec les fonctionnalités latentes de la couche d'entrée du réseau fédérateur. L’équipe de Tencent a constaté que cette conception rudimentaire ne pouvait pas capturer les mouvements complexes des lèvres. Par conséquent, ils ont adopté la stratégie multi-échelles de ControlNet : intégrer les fonctionnalités Landmark des échelles correspondantes dans différents modules du réseau fédérateur. Malgré ces améliorations, le nombre de paramètres dans le modèle final reste encore assez faible. L'équipe a également introduit une autre amélioration : utiliser le Landmark de l'image de référence comme entrée supplémentaire. Le module d'attention croisée de PoseGuider facilite l'interaction entre les repères de référence et les repères cibles dans chaque image. Ce processus fournit au réseau des indices supplémentaires qui lui permettent de comprendre le lien entre les repères du visage et l'apparence, ce qui peut aider l'animation du portrait à générer des mouvements plus précis. Le réseau fédérateur utilisé dans l'étape Audio2Lmk est wav2vec2.0. L'outil utilisé pour extraire les maillages 3D et les poses 6D est MediaPipe. Les données de formation d'Audio2Mesh proviennent de l'ensemble de données interne de Tencent, qui contient près d'une heure de données vocales de haute qualité provenant d'un seul locuteur. Pour assurer la stabilité du maillage 3D extrait par MediaPipe, la position de la tête de l'interprète est stable et face à la caméra pendant l'enregistrement. La formation Audio2Pose utilise HDTF. Toutes les opérations de formation sont effectuées sur un seul A100, à l'aide de l'optimiseur Adam, et le taux d'apprentissage est fixé à 1e-5.Le processus Lmk2Video utilise une méthode de formation en deux étapes. La phase initiale se concentre sur la formation du réseau fédérateur ReferenceNet et du composant 2D de PoseGuider, quel que soit le module de mouvement. Dans les étapes suivantes, tous les autres composants seront gelés pour se concentrer sur la formation du module de mouvement. Pour entraîner le modèle, deux ensembles de données vidéo faciales à grande échelle et de haute qualité sont utilisés ici : VFHQ et CelebV-HQ. Toutes les données sont transmises via MediaPipe pour extraire les repères de visage 2D. Pour améliorer la sensibilité du réseau aux mouvements des lèvres, l'approche de l'équipe a consisté à annoter les lèvres supérieures et inférieures avec des couleurs différentes lors du rendu d'images de pose basées sur des repères 2D. Toutes les images ont été redimensionnées à 512x512.Le modèle a été entraîné à l'aide de 4 GPU A100, chaque étape prenant 2 jours. L'optimiseur est AdamW et le taux d'apprentissage est fixé à 1e-5. Comme le montre la figure 2, l'animation obtenue par la nouvelle méthode est excellente en qualité et en réalisme. 
De plus, les utilisateurs peuvent modifier la représentation 3D au milieu pour modifier la sortie finale. Par exemple, les utilisateurs peuvent extraire des monuments d'une source et modifier leurs informations d'identification pour obtenir une reproduction faciale, comme le montre la vidéo suivante :  Veuillez vous référer à l'article original pour plus de détails.
Veuillez vous référer à l'article original pour plus de détails. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

