
Maison >Périphériques technologiques >IA >Que Siri ne soit plus retardé mental ! Apple définit un nouveau modèle côté appareil, qui est « bien meilleur que GPT-4. Il supprime le texte et simule visuellement les informations à l'écran. Le modèle à paramètres minimaux est toujours 5 % meilleur que le système de base.
Que Siri ne soit plus retardé mental ! Apple définit un nouveau modèle côté appareil, qui est « bien meilleur que GPT-4. Il supprime le texte et simule visuellement les informations à l'écran. Le modèle à paramètres minimaux est toujours 5 % meilleur que le système de base.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-02 21:20:21820parcourir
Écrit par Noah
Produit | 51CTO Technology Stack (WeChat ID : blog51cto)
Siri, qui est toujours critiquée par les utilisateurs pour être "un peu mentalement retardée", est sauvée !
Siri est l'un des représentants dans le domaine des assistants vocaux intelligents depuis sa naissance, mais ses performances ont longtemps été insatisfaisantes. Cependant, les derniers résultats de recherche publiés par l'équipe d'intelligence artificielle d'Apple devraient modifier considérablement le statu quo. Ces résultats sont passionnants et suscitent de grandes attentes pour l’avenir de ce domaine.
Dans des articles de recherche connexes, les experts en IA d'Apple décrivent un système dans lequel Siri peut non seulement reconnaître le contenu des images, mais aussi faire plus, devenant ainsi plus intelligent et plus utile. Ce modèle fonctionnel s'appelle ReALM, qui est basé sur la norme GPT 4.0 et possède de meilleures capacités de référence que GPT 4.0. Ces experts estiment que le modèle qu'ils ont développé est utilisé pour mettre en œuvre une fonction qu'ils ont développée, qui peut rendre Siri plus intelligent, plus pratique et plus adapté à divers scénarios.
1. Motivation : résoudre la résolution de référence de différentes entités
Selon l'équipe de recherche d'Apple : « Il est très essentiel de permettre à l'assistant de conversation de comprendre le contexte, y compris le pointage du contenu associé. écran en fonction de ce qu'ils voient. Poser des questions est une étape importante pour garantir une expérience de commande vocale. comme demander à l'assistant vocal d'appeler un numéro de téléphone, de naviguer vers un endroit spécifique sur une carte, d'ouvrir une application ou une page Web spécifique, et bien plus encore. Si l'assistant conversationnel ne peut pas comprendre la référence d'entité derrière les instructions de l'utilisateur, il ne sera pas en mesure d'exécuter ces commandes avec précision.
De plus, le phénomène de référence floue est courant dans les conversations humaines. Afin d'obtenir une interaction homme-machine naturelle et de comprendre avec précision le contexte lorsque les utilisateurs posent des questions sur le contenu de l'écran avec les assistants vocaux, la capacité à résoudre les références est cruciale.
L'avantage du modèle appelé ReALM (Reference Resolution As Language Modeling) mentionné par Apple dans le document est qu'il peut prendre en compte simultanément le contenu sur l'écran de l'utilisateur et la tâche en cours, et utiliser de grands modèles de langage pour résoudre différents problèmes. Le problème de la résolution de référence des entités de type (y compris les entités conversationnelles et les entités non conversationnelles).
Bien que la modalité de texte traditionnelle ne soit pas pratique pour gérer les entités affichées à l'écran, le système ReALM convertit l'analyse des références en un problème de modélisation du langage et utilise avec succès les LLM pour gérer la référence des entités non-conversation à l'écran, ce qui est extrêmement efficace. La terre facilite cet objectif. De cette manière, il devrait offrir une expérience utilisateur hautement intelligente et plus immersive.
2. Reconstruction : dépasser les limites du modal de texte traditionnel
Le modal de texte traditionnel n'est pas pratique pour traiter les entités affichées à l'écran, car les entités à l'écran contiennent généralement des informations visuelles riches et des structures de mise en page, telles que images, icônes, boutons et leurs relations de position relative, etc. Ces informations sont difficiles à exprimer pleinement dans une description textuelle pure.
Pour relever ce défi, le système ReALM propose de manière créative de reconstruire l'écran en analysant les entités sur l'écran et leurs informations de position, et génère une représentation textuelle pure qui peut refléter visuellement le contenu de l'écran.
Les parties de l'entité seront spécialement marquées afin que le modèle de langage comprenne où l'entité apparaît et quel est le texte qui l'entoure, afin qu'il puisse simuler "voir" les informations à l'écran et comprendre et analyser les instructions à l'écran. . Fournissez les informations contextuelles nécessaires. Cette approche est la première tentative d'utilisation d'un grand modèle de langage pour encoder le contexte à partir du contenu de l'écran, surmontant ainsi le problème des entités d'écran difficiles à gérer avec les modalités de texte traditionnelles.
Plus précisément, pour que le grand modèle de langage « comprenne » et traite les entités affichées à l'écran, le système ReALM adopte les étapes suivantes :
Tout d'abord, les entités dans le texte à l'écran sont extraites avec le À l'aide des détecteurs de données de couche supérieure, ces entités auront un type, un cadre de délimitation et une liste d'éléments de texte non-entités entourant l'entité. Cela signifie que pour chaque entité visuelle à l'écran, le système capture ses informations de base et le contexte dans lequel elle existe.
Ensuite, ReALM propose de manière innovante un algorithme pour trier les points centraux des boîtes englobantes des entités et des objets environnants dans l'ordre vertical (de haut en bas) et horizontal (de gauche à droite) et stabiliser l'arrangement. Si la distance entre les entités est proche, elles sont considérées comme étant sur la même ligne et séparées par des tabulations ; si la distance dépasse la marge définie, elles sont placées sur la ligne suivante ; De cette manière, en appliquant continuellement la méthode ci-dessus, le contenu de l'écran peut être codé dans un format de texte brut de gauche à droite et de haut en bas, conservant efficacement la relation spatiale relative entre les entités.
De cette façon, les informations visuelles de l'écran difficiles à traiter directement par LLM sont converties en une forme de texte adaptée à la saisie du modèle de langage, permettant à LLM de prendre pleinement en compte la position et l'emplacement spécifiques des entités de l'écran lors du traitement. tâches séquence à séquence pour obtenir une identification correcte et une résolution de référence des entités d’écran.
Cela permet au système ReALM non seulement de bien fonctionner dans la résolution du problème de référence des entités conversationnelles, mais montre également une amélioration significative des performances lorsqu'il s'agit d'entités non conversationnelles, c'est-à-dire des entités à l'écran.
3. Détails : définition de la tâche et ensemble de données
Pour faire simple, la tâche du système ReALM est de trouver les entités liées à la requête actuelle de l'utilisateur dans la collection d'entités donnée en fonction des tâches que l'utilisateur souhaite effectuer. effectuer.
Cette tâche est structurée comme une question à choix multiples pour un grand modèle de langage, et elle est censée sélectionner une ou plusieurs options comme réponse parmi les entités affichées sur l'écran de l'utilisateur. Bien entendu, dans certains cas, la réponse peut être « ni l’un ni l’autre ».
En fait, le document de recherche divise les entités impliquées dans la tâche en trois catégories :
1 Entités d'écran : fait référence aux entités actuellement visibles sur l'interface utilisateur.
2. Entités de dialogue : entités liées au contenu de la conversation, qui peuvent provenir du discours précédent de l'utilisateur (par exemple, si l'utilisateur mentionne « appeler maman », l'entrée de « maman » dans la liste de contacts est l'entité pertinente) , ou peuvent être générés par des assistants virtuels sont fournis dans les conversations (comme une liste de lieux parmi lesquels l'utilisateur peut choisir).
3. Entités d'arrière-plan : entités associées provenant de processus en arrière-plan et qui ne sont pas nécessairement directement reflétées dans l'affichage de l'écran de l'utilisateur ou dans l'interaction avec l'assistant virtuel, comme un réveil qui sonnera par défaut ou une musique diffusée en arrière-plan.
Quant à l'ensemble de données utilisé pour entraîner et tester ReALM, il est constitué de données synthétiques et de données annotées manuellement, qui peuvent également être divisées en trois catégories :
Premièrement, l'ensemble de données de dialogue : contient l'interaction entre l'utilisateur et l'agent Points de données pour les entités associées. Ces données ont été collectées en demandant aux évaluateurs de visualiser des captures d'écran contenant des listes d'entités synthétiques et de leur demander de fournir des requêtes pointant explicitement vers n'importe quelle entité sélectionnée dans la liste.
Deuxième ensemble de données synthétiques : utilisez la méthode de génération de modèle pour obtenir des données. Cette méthode est particulièrement utile lorsque la requête de l'utilisateur et le type d'entité sont suffisants pour déterminer la référence sans s'appuyer sur une description détaillée. L'ensemble de données synthétiques peut également contenir plusieurs entités correspondant à la même requête.
Troisièmement, ensemble de données d'écran : il couvre principalement les données des entités actuellement affichées sur l'écran de l'utilisateur. Chaque élément de données contient la requête de l'utilisateur, la liste des entités et l'entité correcte (ou la collection d'entités) correspondant à la requête. Les informations sur chaque entité comprennent le type d'entité et d'autres propriétés telles que le nom et d'autres détails textuels associés à l'entité (par exemple, l'étiquette et l'heure d'un réveil).
Pour les points de données contenant un contexte lié à l'écran, les informations contextuelles sont fournies sous la forme du cadre de délimitation de l'entité et d'une liste d'autres objets entourant l'entité, ainsi que des informations d'attribut telles que le type, le contenu du texte et l'emplacement. de ces objets environnants. La taille de l'ensemble des données est divisée en ensemble d'entraînement et en ensemble de test selon les catégories, et chacun a une certaine taille.
4. Résultats : le plus petit modèle a également obtenu une amélioration des performances de 5 %
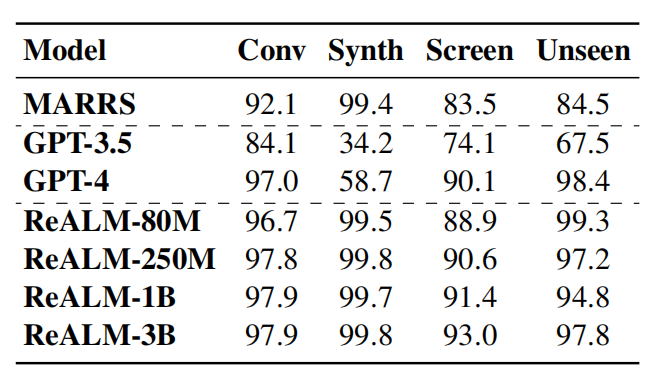
Dans le test de référence, Apple a comparé son propre système avec GPT 3.5 et GPT 4.0. Le modèle ReALM montre une excellente compétitivité dans la résolution de différents types de tâches d'analyse référentielle.
 Picture
Picture
Selon le document, même la version avec le moins de paramètres dans ReALM a obtenu une amélioration des performances de plus de 5 % par rapport au système de base. Sur la version plus grande, ReALM surpasse clairement GPT-4. En particulier lors du traitement des entités affichées à l'écran, à mesure que la taille du modèle augmente, l'amélioration des performances de ReALM sur l'ensemble de données à l'écran devient plus significative.
De plus, les performances du modèle ReALM sont assez proches de GPT-4 dans des scénarios d'apprentissage zéro-shot dans de nouveaux domaines. Lors du traitement des requêtes dans des champs spécifiques, le modèle ReALM fonctionne avec plus de précision que GPT-4 grâce à un réglage fin basé sur les demandes des utilisateurs.
Par exemple, pour une demande d'utilisateur visant à régler la luminosité, GPT-4 associe uniquement la demande aux paramètres, ignorant que les appareils intelligents existants en arrière-plan sont également des entités liées, et ReALM est formé avec des données spécifiques au domaine. données, peuvent mieux comprendre et résoudre correctement les problèmes de référence dans des domaines aussi spécifiques.
« Nous démontrons que RealLM surpasse les méthodes précédentes et obtient des résultats comparables même lorsqu'il s'agit de références à l'écran uniquement basées sur des champs de texte, malgré beaucoup moins de paramètres que le LLM de pointe actuel, GPT-4. Un niveau de performances considérable. De plus, RealLM fonctionne mieux que GPT-4 pour les déclarations des utilisateurs dans des domaines spécifiques. Par conséquent, RealLM peut être considéré comme adapté au développement d'environnements d'application pratiques et peut être implémenté localement sur l'appareil tout en garantissant ces performances. n'est pas compromis. La solution privilégiée pour un système de résolution de référence efficace. En outre, les chercheurs ont également déclaré que dans les scénarios d'application pratiques où les ressources sont limitées, des réponses à faible latence sont requises ou une intégration en plusieurs étapes est impliquée, comme les appels d'API. Les modèles de bout en bout à grande échelle ne sont souvent pas applicables.
Dans ce contexte, le système ReALM de conception modulaire présente plus d'avantages, permettant au module de résolution de référence d'origine d'être facilement remplacé et mis à niveau sans affecter l'architecture globale, tout en offrant un meilleur potentiel d'optimisation et une meilleure interprétabilité.
Mit Blick auf die Zukunft weist die Forschungsrichtung auf komplexere Methoden hin, wie z. B. die Unterteilung der Bildschirmfläche in Raster und die Codierung relativer räumlicher Positionen in Textform. Obwohl dies eine große Herausforderung darstellt, ist dies ein vielversprechender Weg, den es zu erkunden gilt.
5. Geschrieben am Ende
Im Bereich der künstlichen Intelligenz war Apple zwar schon immer vorsichtiger, investiert aber auch im Stillen. Ob es sich um das multimodale Großmodell MM1, das KI-gesteuerte Animationsgenerierungstool Keyframer oder das heutige ReALM handelt, Apples Forschungsteam hat weiterhin technologische Durchbrüche erzielt.
Beobachten Sie, wie Konkurrenten wie Google, Microsoft und Amazon KI in die Suche, Cloud-Dienste und Bürosoftware einbauen und dabei nach und nach ihre Muskeln spielen lassen. Apple versucht offensichtlich, nicht ins Hintertreffen zu geraten. Da die Ergebnisse der generativen KI-Implementierung weiterhin sichtbar werden, hat Apple sein Aufholtempo beschleunigt. Mit der Angelegenheit vertraute Personen haben schon lange verraten, dass Apple sich auf der Global Developers Conference im Juni auf den Bereich der künstlichen Intelligenz konzentrieren wird und die neue Strategie für künstliche Intelligenz wahrscheinlich zum Kerninhalt des iOS 18-Upgrades werden wird. Bis dahin kann es Überraschungen für Sie bereithalten.
Referenzlink:
https://apple.slashdot.org/story/24/04/01/1959205/apple-ai-researchers-boast-useful-on-device-model-that-substantial-outperforms -gpt-4
https://arxiv.org/pdf/2403.20329.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les quatre éléments d'un système d'intelligence artificielle ?
- Quelle est la stratégie de développement de l'intelligence artificielle ?
- Comment organiser le texte plus bas en CSS
- Résumé des systèmes autonomes basés sur GPT-4 : AutoGPT, AgentGPT, BabyAGI, HuggingGPT, CAMEL
- Apprenez les requêtes réseau et les appels API en JavaScript