
Maison >Périphériques technologiques >IA >Le premier grand modèle MoE de Yuanxiang est open source : paramètres d'activation 4,2B, l'effet est comparable au modèle 13B
Le premier grand modèle MoE de Yuanxiang est open source : paramètres d'activation 4,2B, l'effet est comparable au modèle 13B

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-02 13:25:081324parcourir
Yuanxiang lance le grand modèle XVERSE-MoE-A4.2B, qui adopte l'architecture de modèle Mélange d'experts la plus avancée de l'industrie (Mélange d'experts), active le paramètre 4.2B et l'effet est comparable au modèle 13B. Ce modèle est entièrement open source et inconditionnellement gratuit pour un usage commercial, permettant à un grand nombre de petites et moyennes entreprises, de chercheurs et de développeurs de l'utiliser à la demande dans le « seau familial » haute performance de Yuanxiang, favorisant un déploiement à faible coût. .

Le développement de grands modèles grand public tels que GPT3, Llama et XVERSE suit la loi de mise à l'échelle Pendant le processus de formation et d'inférence du modèle, tous les paramètres sont activés au cours d'un seul calcul avant et arrière. activation (densément activée). Lorsque l’échelle du modèle augmente, le coût de la puissance de calcul augmente fortement.
De plus en plus de chercheurs pensent que le modèle MoE peu activé peut être une méthode plus efficace sans augmenter de manière significative le coût de calcul de la formation et de l'inférence lors de l'augmentation de la taille du modèle. La technologie étant relativement nouvelle, la plupart des modèles open source ou des recherches universitaires en Chine ne sont pas encore populaires. Dans l'auto-recherche des éléments, en utilisant le même corpus pour former 2,7 quadrillions de jetons, XVERSE-MoE-A4.2B a en fait activé 4,2B de paramètres, et les performances ont "sauté" au-delà de XVERSE-13B-2, seul le montant du calcul a été réduit de 50 % du temps de formation. Comparé à plusieurs benchmarks open source Llama, ce modèle surpasse largement Llama2-13B et est proche de Llama1-65B (photo ci-dessous).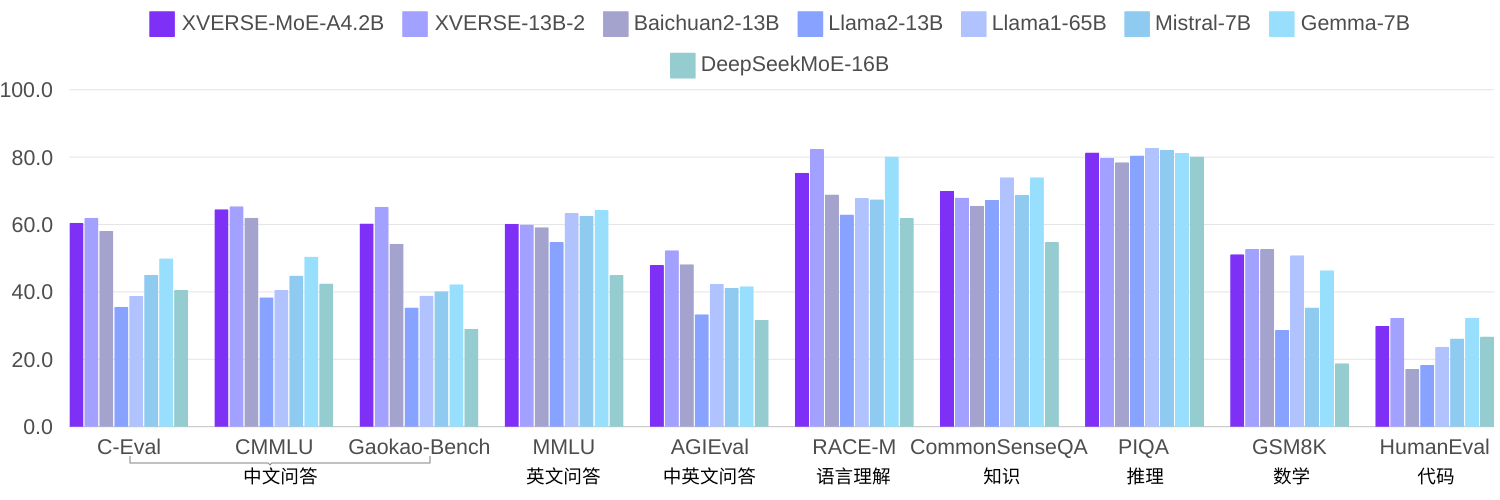
MoEAuto-recherche et innovation technologiques
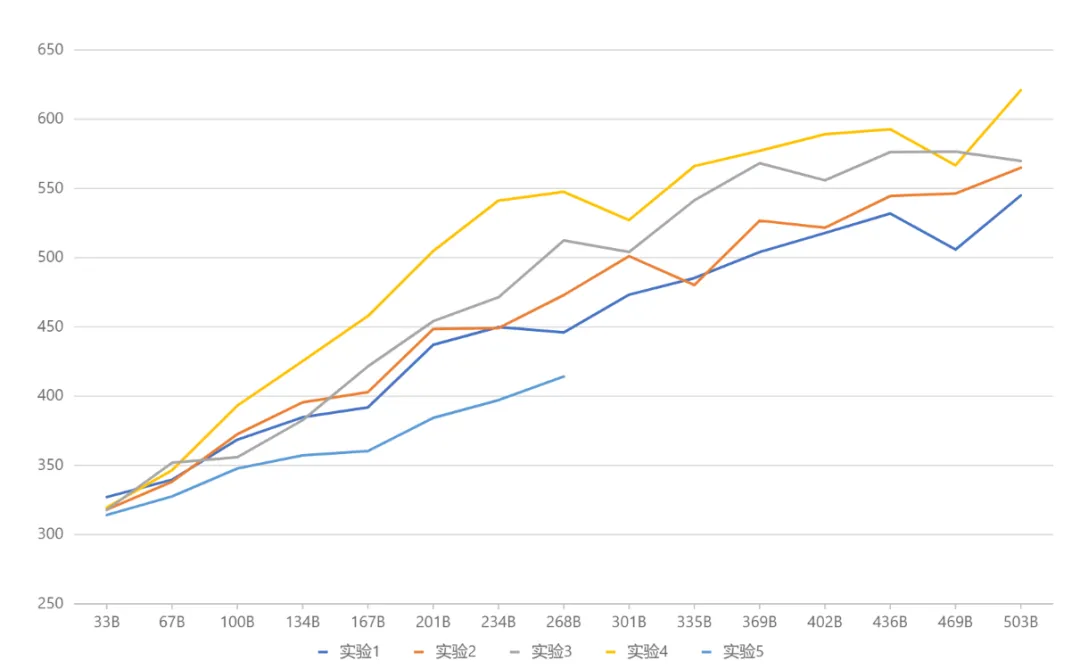
Le ministère de l'Éducation (MoE) est actuellement le cadre modèle le plus avant-gardiste de l'industrie. En raison de la technologie plus récente, les modèles open source nationaux ou la recherche universitaire ne l'ont pas été. pourtant devenu populaire. MetaObject a développé indépendamment le cadre efficace de formation et d'inférence du MoE et a innové dans trois directions : En termes de performances, un ensemble d'opérateurs de fusion efficaces ont été développés sur la base de la logique unique de routage expert et de calcul de poids de l'architecture MoE, ce qui a considérablement amélioré le calcul. Efficacité ; visant à relever les défis liés à une utilisation élevée de la mémoire et à un volume de communication important dans le modèle MoE, les opérations superposées de calcul, de communication et de déchargement de mémoire sont conçues pour améliorer efficacement le débit de traitement global. En termes d'architecture, contrairement au MoE traditionnel (comme Mixtral 8x7B), qui assimile la taille de chaque expert au FFN standard, Yuanxiang adopte une conception d'expert plus fine, et la taille de chaque expert n'est qu'un quart de le FFN standard, qui améliore la flexibilité et les performances du modèle ; les experts sont également divisés en deux catégories : les experts partagés et les experts non partagés. Les experts partagés restent actifs pendant les calculs, tandis que les experts non partagés sont activés de manière sélective selon les besoins. Cette conception est propice à la compression des connaissances générales en paramètres experts partagés et à la réduction de la redondance des connaissances parmi les paramètres experts non partagés. En termes de formation, inspiré de Switch Transformers, ST-MoE et DeepSeekMoE, Yuanxiang introduit le terme de perte d'équilibrage de charge pour mieux équilibrer la charge entre les experts ; le terme de perte z du routeur est utilisé pour garantir une formation efficace et stable. La sélection de l'architecture a été obtenue grâce à une série d'expériences comparatives (image ci-dessous). Dans l'expérience 3 et l'expérience 2, la quantité totale de paramètres et la quantité de paramètres d'activation étaient les mêmes, mais la conception experte à grain fin de la première a apporté des performances plus élevées. . Sur cette base, l’expérience 4 a divisé les experts en deux types : partagés et non partagés, ce qui a considérablement amélioré l’effet. L'expérience 5 explore la méthode d'introduction d'experts partagés lorsque la taille de l'expert est égale au FFN standard, mais l'effet n'est pas idéal.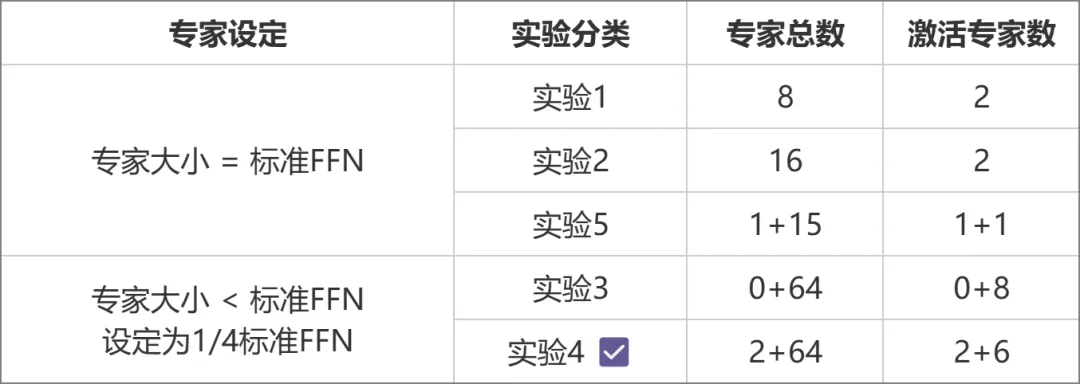
- Hugging Face : https://huggingface.co/xverse/XVERSE-MoE-A4.2B
- ModelScope : https://modelscope.cn / models/xverse/XVERSE-MoE-A4.2B
- Github : https://github.com/xverse-ai/XVERSE-MoE-A4.2B
- Pour toute demande de renseignements, veuillez envoyer : opensource@xverse.cn
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Huawei Cloud et un certain nombre d'entreprises ont lancé une initiative d'action : construire conjointement un écosystème industriel ouvert pour la conduite autonome
- Tesla envisage de créer une usine de véhicules électriques en Inde pour dynamiser l'industrie indienne des véhicules électriques
- Xiaoyu Yilian est apparue à l'Exposition internationale de l'industrie intelligente de Chine
- Comment les robots collaboratifs peuvent-ils permettre la fabrication intelligente et la modernisation de l'industrie chimique quotidienne ? Écoutez ce que disent les experts
- Industrie de la robotique : le prochain domaine brûlant de l'ère de l'IA, l'une des neuf industries majeures du futur !