
Maison >Périphériques technologiques >IA >'À la recherche d'une aiguille dans une botte de foin' ! 'Compter les étoiles' devient une méthode plus précise pour mesurer la longueur du texte, de Goose Factory
'À la recherche d'une aiguille dans une botte de foin' ! 'Compter les étoiles' devient une méthode plus précise pour mesurer la longueur du texte, de Goose Factory

- PHPzavant
- 2024-04-02 11:55:30827parcourir
Il existe une nouvelle méthode pour tester la capacité du texte long en grand modèle !
Tencent MLPD Lab utilise la nouvelle méthode open source "Counting Stars" pour remplacer le test traditionnel de "l'aiguille dans la botte de foin".
En revanche, la nouvelle méthode accorde plus d'attention à l'examen de la capacité du modèle à gérer de longues dépendances , et l'évaluation du modèle est plus complète et plus précise.

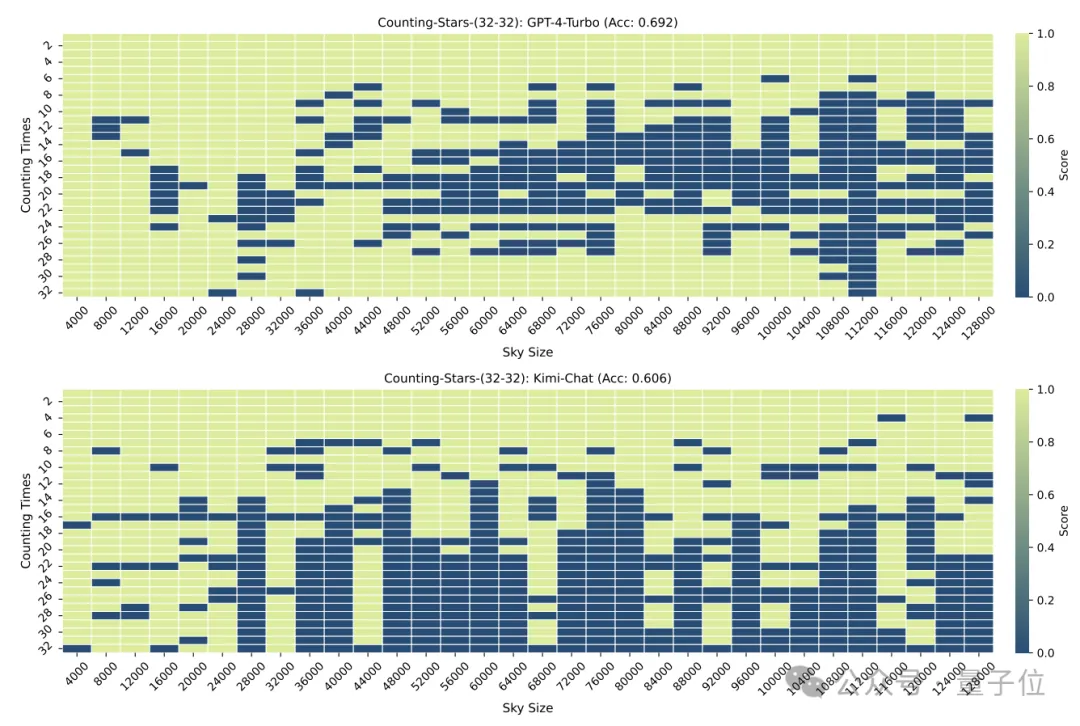
En utilisant cette méthode, les chercheurs ont effectué un test de « comptage des étoiles » sur GPT-4 et le célèbre Kimi Chat domestique.
En conséquence, dans des conditions expérimentales différentes, les deux modèles ont leurs propres avantages et inconvénients, mais ils démontrent tous deux de fortes capacités de texte long.
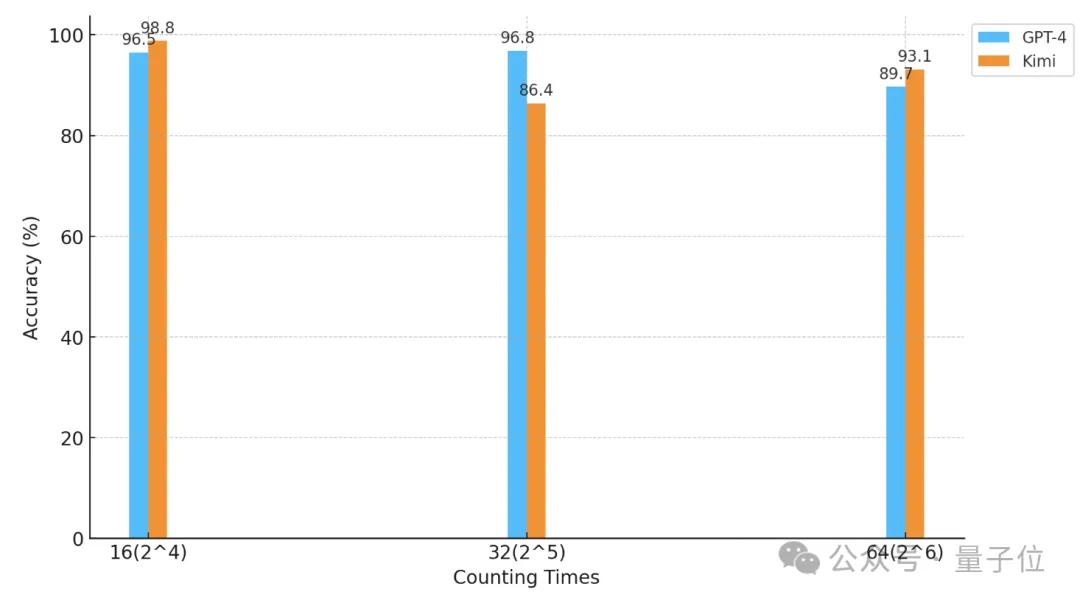
△L'axe horizontal est une coordonnée logarithmique de base 2
Alors, quel genre de test consiste à "compter les étoiles" ?
Plus précis que "trouver une aiguille dans une botte de foin"
Tout d'abord, les chercheurs ont sélectionné un long texte comme contexte Au cours du test, la longueur a progressivement augmenté, jusqu'à un maximum de 128 ko.
Ensuite, selon les différentes exigences de difficulté du test, le texte entier sera divisé en N paragraphes, et M phrases contenant des « étoiles » y seront insérées .
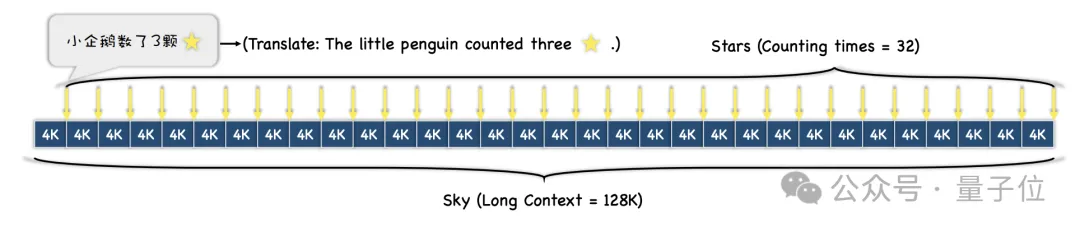
Au cours de l'expérience, les chercheurs ont choisi « Rêve de demeures rouges » comme texte contextuel et ont ajouté des phrases telles que « Le petit pingouin comptait x étoiles », et le x dans chaque phrase était différent.
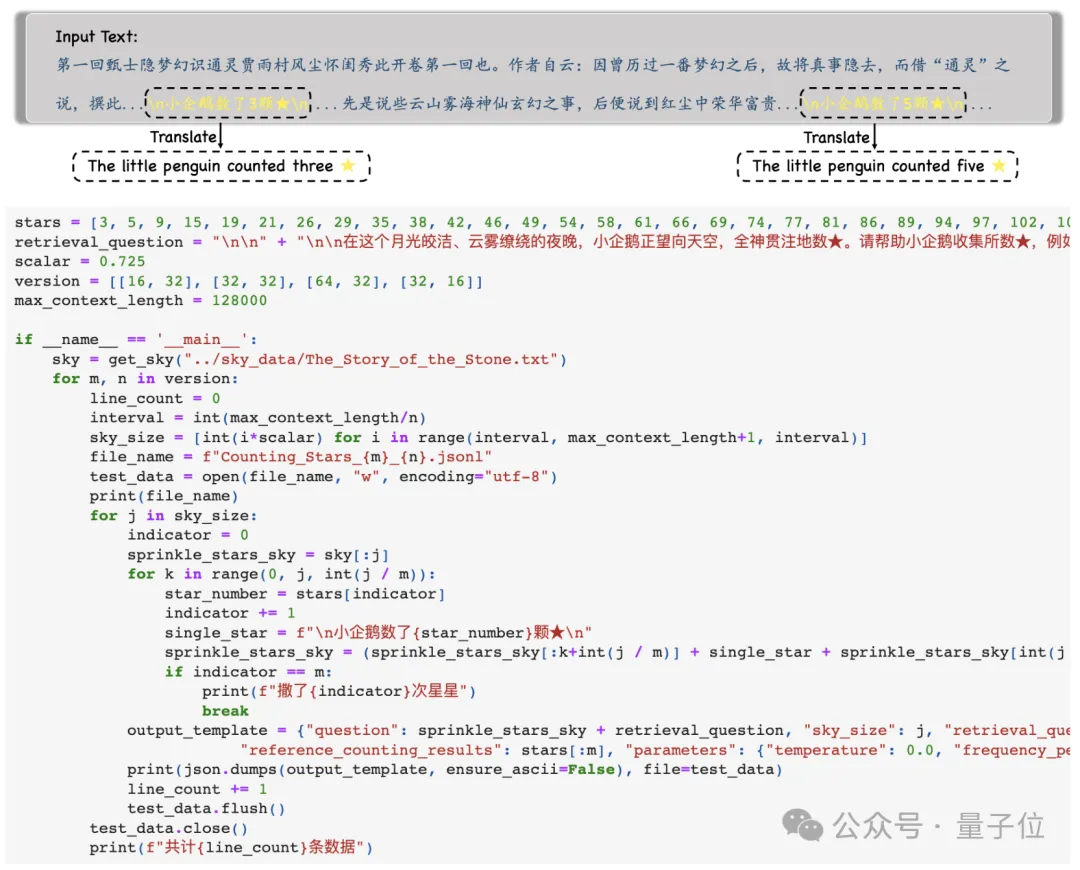
Ensuite, il est demandé au modèle de trouver toutes ces phrases et de générer tous les nombres et uniquement les nombres qu'elles contiennent au format JSON .

Après avoir obtenu les résultats du modèle, les chercheurs compareront ces chiffres avec la vérité terrain et calculeront enfin la précision des résultats du modèle.
Par rapport au test précédent "une aiguille dans une botte de foin", cette méthode de "compter les étoiles" reflète mieux la capacité du modèle à gérer de longues dépendances.
En bref, insérer plusieurs « aiguilles » dans la « botte de foin » signifie insérer plusieurs indices, puis laisser le grand modèle trouver et raisonner sur les multiples indices en série, et obtenir la réponse finale.
Mais dans le test actuel « Trouver plusieurs aiguilles dans une botte de foin », le modèle n'a pas besoin de trouver toutes les « aiguilles » pour répondre correctement à la question, et parfois il n'a même besoin que de trouver la dernière.
Mais "compter les étoiles" est différent - parce que le nombre d'"étoiles" dans chaque phrase est différent, le modèle doit trouver toutes les étoiles pour répondre correctement à la question.
Ainsi, bien que cela semble simple, du moins pour les tâches multi-« aiguilles », « Counting Stars » reflète plus précisément les capacités de texte long du modèle.
Alors, quels grands mannequins ont été les premiers à passer le test « Counting Stars » ?
GPT-4 et Kimi sont indiscernables
Les grands modèles participant à ce test sont GPT-4 et Kimi, un grand modèle domestique bien connu pour ses capacités de texte long.
Lorsque le nombre d'"étoiles" et la granularité du texte sont tous deux de 32, la précision de GPT-4 atteint 96,8 % et celle de Kimi de 86,4 %.
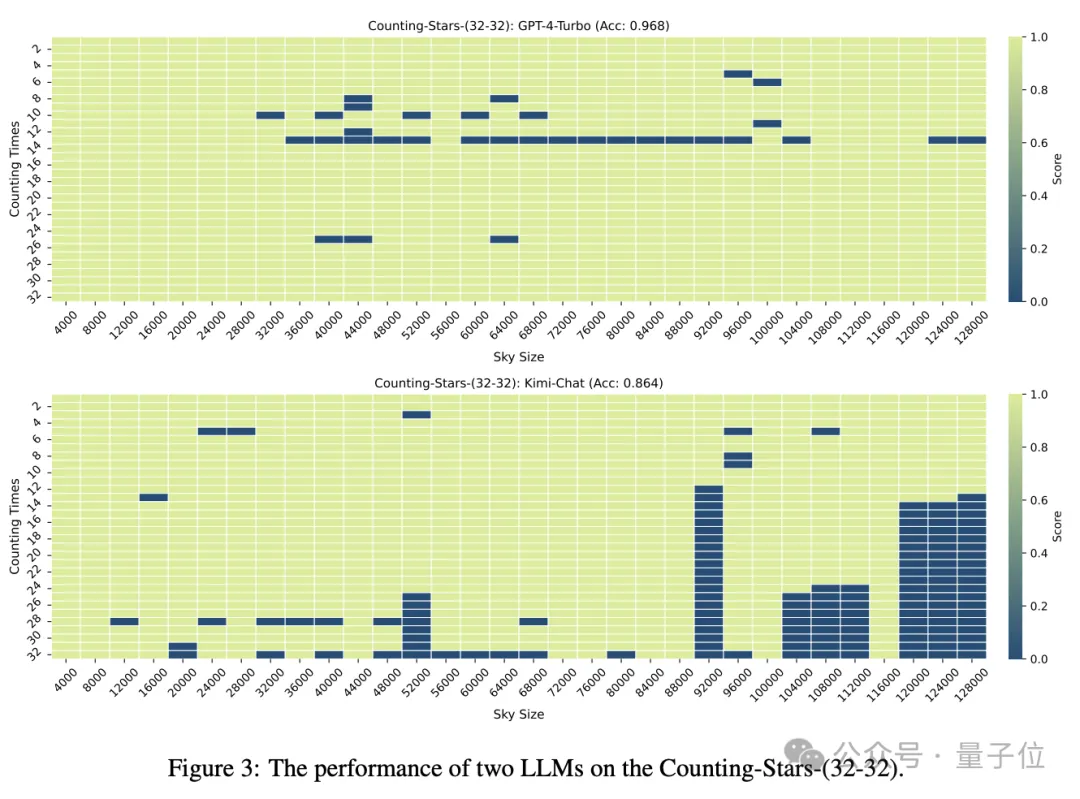
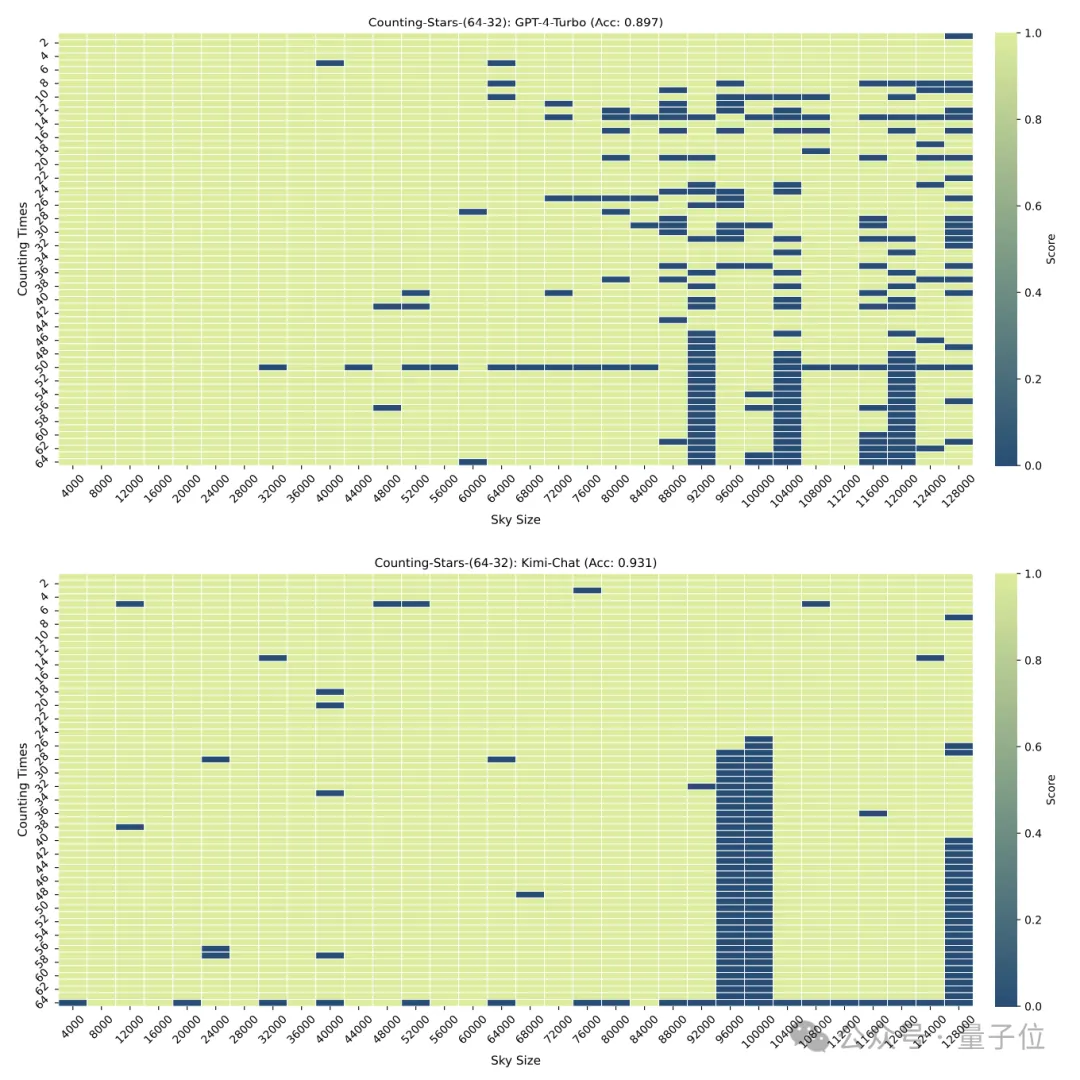
Mais lorsque les "étoiles" ont été augmentées à 64, la précision de Kimi de 93,1% a dépassé GPT-4 avec une précision de 89,7%.
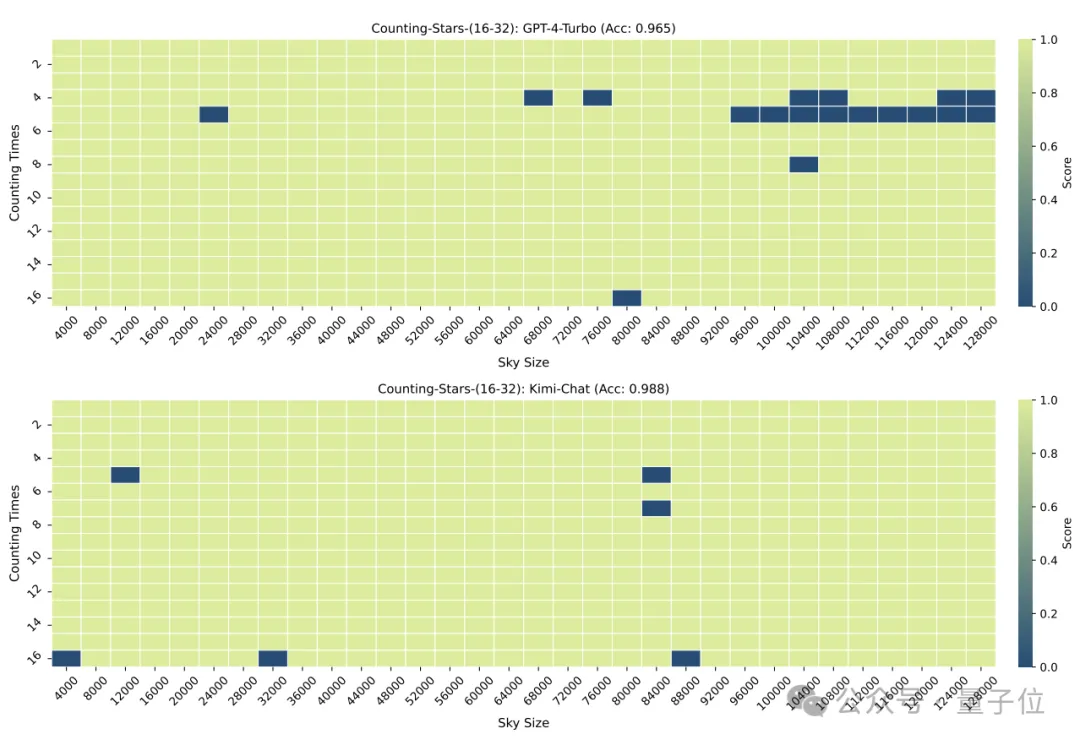
Quand elle a été réduite à 16, c'était aussi la performance de Kimi. Légèrement meilleur que GPT-4.
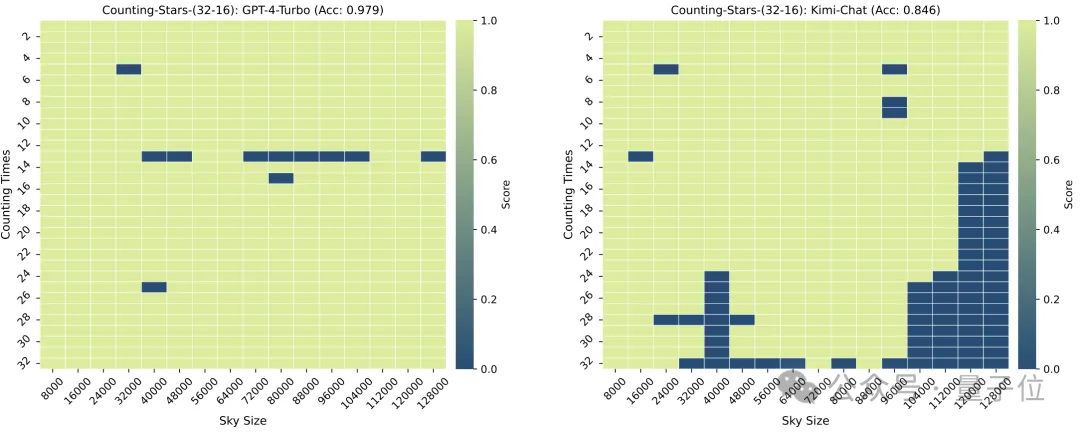
La granularité de la division aura également un certain impact sur les performances du modèle. Lorsque "l'étoile" apparaît également 32 fois, la granularité passe de 32 à 16. Le score de GPT-4 a augmenté, tandis que Kimi a diminué.
Il convient de noter que dans le test ci-dessus, le nombre d'"étoiles" a augmenté séquentiellement, mais les chercheurs ont vite découvert que dans ce cas, le grand modèle aime "être paresseux" -
Quand le modèle Il On constate que lorsque le nombre d'étoiles augmente, même si les nombres dans l'intervalle sont générés de manière aléatoire, la sensibilité du grand modèle augmentera.
Par exemple : le modèle est plus sensible à la séquence croissante de 3, 9, 10, 24, 1145, 114514 qu'à 24, 10, 3, 1145, 9, 114514
Ainsi, les chercheurs ont délibérément modifié l'ordre des chiffres Perturbé et retesté.

Après la perturbation, les performances de GPT-4 et de Kimi ont considérablement chuté, mais la précision était toujours supérieure à 60 %, avec une différence de 8,6 points de pourcentage.
One More Thing
La précision de cette méthode aura peut-être encore besoin de temps pour être testée, mais je dois dire que le nom est vraiment bon.

△Paroles de la chanson anglaise Counting Stars
Les internautes ne peuvent s'empêcher de soupirer que la recherche sur les grands modèles devient vraiment de plus en plus magique.
Mais derrière la magie, cela montre également que les gens ne comprennent pas pleinement les capacités de traitement de contexte long et les performances des grands modèles.
Il y a quelques jours à peine, un certain nombre de grands fabricants de modèles ont annoncé le lancement de modèles (bien que tous ne soient pas basés sur l'implémentation de fenêtres contextuelles) capables de gérer des textes extrêmement longs, jusqu'à des dizaines de millions, mais les performances réelles sont toujours inconnu.
L’émergence de Counting Stars pourrait bien nous aider à comprendre les véritables performances de ces modèles.
Alors, de quels autres modèles souhaitez-vous voir les résultats des tests ?
Adresse papier : https://arxiv.org/abs/2403.11802
GitHub : https://github.com/nick7nlp/Counting-Stars
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment développer efficacement des petits programmes ? Recommander un framework open source absolument facile à utiliser pour les petits programmes
- Comment effectuer des tests de lien via l'outil de ligne de commande mtr dans un environnement Linux
- Comment tester si la connexion à la base de données réussit dans MySQL
- À quoi servent principalement les tests de bases de données ?
- CMS open source bien connu : Dreamweaver CMS dira adieu au gratuit, et l'ère de l'open source décline progressivement !