
Maison >Périphériques technologiques >IA >Réglage LLM efficace sur GPU local à l'aide de GaLore
Réglage LLM efficace sur GPU local à l'aide de GaLore

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-26 08:26:351084parcourir
La formation de grands modèles de langage (llm) est une tâche gourmande en calcul, même ceux avec "seulement" 7 milliards de paramètres. Ce niveau de formation nécessite des ressources dépassant les capacités de la plupart des passionnés. Pour combler cette lacune, des méthodes efficaces en termes de paramètres, telles que l'adaptation de bas rang (LoRA), ont vu le jour, permettant d'affiner un grand nombre de modèles sur des GPU grand public.
GaLore est une méthode innovante qui utilise un entraînement optimisé des paramètres pour réduire les besoins en VRAM au lieu de simplement réduire le nombre de paramètres. Cela signifie que GaLore est une nouvelle stratégie de formation de modèle qui permet au modèle d'utiliser pleinement tous les paramètres d'apprentissage et d'économiser de la mémoire plus efficacement que LoRA.
GaLore réduit efficacement la charge de calcul en cartographiant ces gradients dans un espace de faible dimension tout en conservant les informations clés d'entraînement. Contrairement aux optimiseurs traditionnels qui mettent à jour toutes les couches en même temps pendant la rétropropagation, GaLore utilise une méthode de mise à jour couche par couche pour la rétropropagation. Cette stratégie réduit considérablement l'empreinte mémoire pendant l'entraînement et optimise davantage les performances.
Tout comme LoRA, GaLore nous permet d'affiner le modèle 7B sur un GPU grand public équipé jusqu'à 24 Go de VRAM. Les résultats montrent que les performances du modèle sont comparables à celles du réglage fin de tous les paramètres et semblent même meilleures que celles de LoRA.
est meilleur que Hugging Face. Il n'y a actuellement pas de code officiel. Utilisons manuellement le code du papier pour la formation et comparons-le avec LoRA. GaLore
pip install galore-torch
Ensuite, nous devons également consulter ces bibliothèques, et veuillez faire attention à la version
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
classes de planificateur et d'optimiseur
Galore L'optimiseur hiérarchique est activé via le crochet de poids modèle. Puisque nous utilisons Hugging Face Trainer, nous devons également implémenter nous-mêmes une classe abstraite d’optimiseur et de planificateur. Les structures de ces classes n’effectuent aucune opération.
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs
Load GaLore Optimizer
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()
HF Trainer
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "user", response_template = "assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()
L'optimiseur GaLore a quelques hyperparamètres qui doivent être définis comme suit :
target_modules_list : Spécifiez la couche des cibles GaLore
rank : Le rang de la matrice de projection. Semblable à LoRA, plus le rang est élevé, plus le réglage fin est proche du réglage fin de tous les paramètres. L'auteur de GaLore recommande à 7B d'utiliser 1024
update_proj_gap : Le nombre d'étapes pour mettre à jour la projection. C'est une étape coûteuse et prend environ 15 minutes pour 7B. Définit l'intervalle de mise à jour de la projection, la plage recommandée est comprise entre 50 et 1000 pas.
scale : Un facteur d'échelle similaire à l'alpha de LoRA, utilisé pour ajuster l'intensité de la mise à jour. Après avoir essayé plusieurs valeurs, j'ai trouvé que scale=2 est le plus proche du réglage fin classique de tous les paramètres.
Comparaison des effets de réglage fin
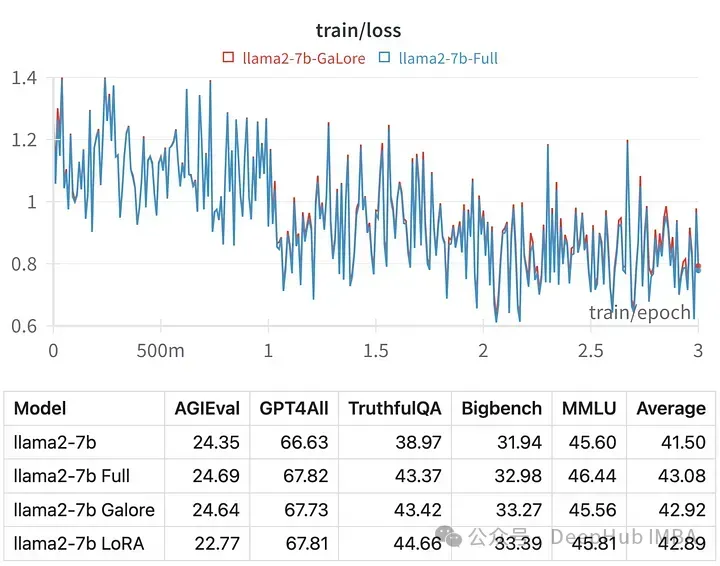
La perte d'entraînement pour un hyperparamètre donné est très similaire à la trajectoire de réglage complet des paramètres, indiquant que la méthode en couches GaLore est effectivement équivalente.
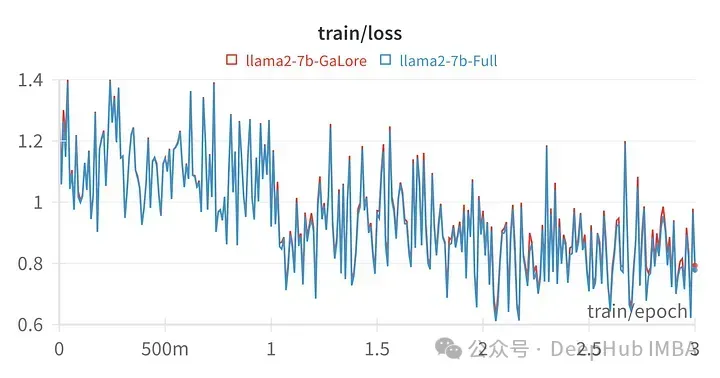
Les scores des modèles formés avec GaLore sont très similaires au réglage fin des paramètres complets.
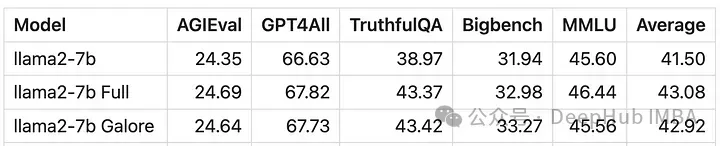
GaLore peut économiser environ 15 Go de VRAM, mais l'entraînement prend plus de temps en raison des mises à jour régulières des projections.
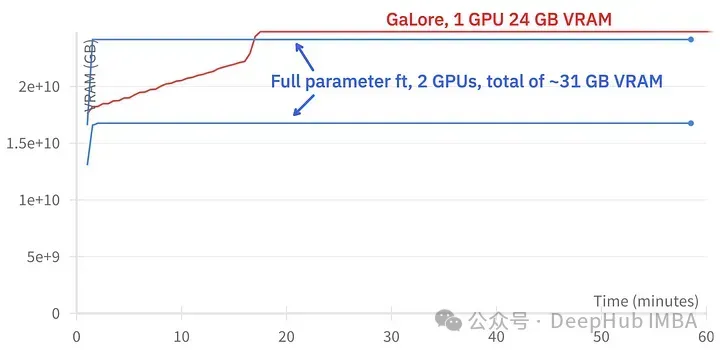
L'image ci-dessus montre la comparaison de l'utilisation de la mémoire de deux 3090
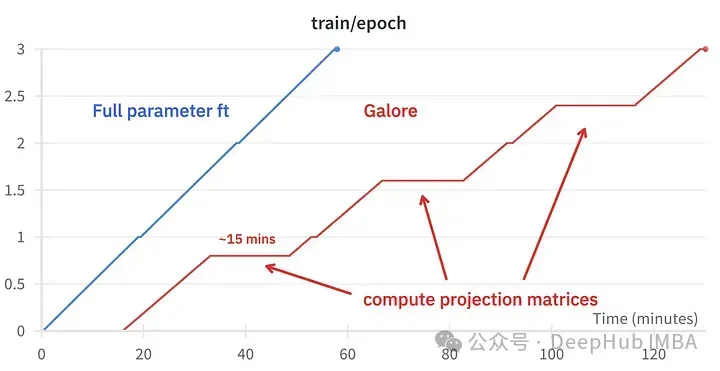
Comparaison des événements d'entraînement, réglage fin : ~ 58 minutes. GaLore : environ 130 minutes
Enfin, jetons un coup d'œil à la comparaison entre GaLore et LoRA
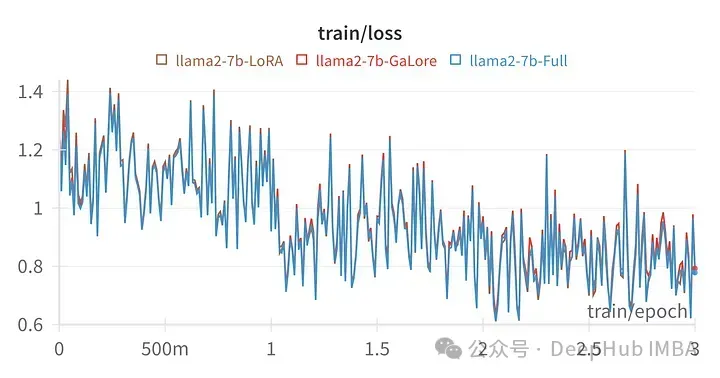
L'image ci-dessus est le tableau des pertes de LoRA affinant toutes les couches linéaires, rang 64, alpha 16
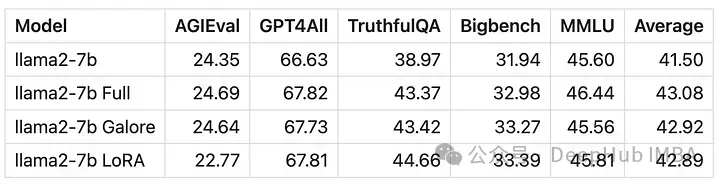
D'un point de vue numérique, on peut voir que GaLore est une nouvelle méthode qui se rapproche de l'entraînement complet, et ses performances sont équivalentes à un réglage fin et bien meilleures que LoRA.
Résumé
GaLore économise la VRAM et permet l'entraînement de modèles 7B sur des GPU grand public, mais est plus lent et prend presque deux fois plus de temps que le réglage fin et LoRA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- ChatGPT et grands modèles de langage : quels risques ?
- Meta lance le modèle de langage IA LLaMA, un modèle de langage à grande échelle avec 65 milliards de paramètres
- Un autre 'acteur fort' a été ajouté dans le domaine de l'IA, Meta publie un nouveau modèle de langage à grande échelle LLaMA
- Windows sur Ollama : un nouvel outil pour exécuter des modèles de langage étendus (LLM) localement