
Maison >Périphériques technologiques >IA >L'open source de l'équipe de Cambridge : renforcer les applications RAG multimodales à grand modèle, le premier outil de récupération de connaissances post-interactif multimodal universel pré-entraîné
L'open source de l'équipe de Cambridge : renforcer les applications RAG multimodales à grand modèle, le premier outil de récupération de connaissances post-interactif multimodal universel pré-entraîné

- PHPzavant
- 2024-03-25 20:50:47618parcourir

- Lien papier : https://arxiv.org/abs/2402.08327
- Lien DEMO : https://u60 544-b8d4-53eaa55d. westx .seetacloud.com:8443/
- Lien vers la page d'accueil du projet : https://preflmr.github.io/
- Titre de l'article : PreFLMR : Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers
Contexte
Bien que les grands modèles multimodaux (tels que GPT4-Vision, Gemini, etc.) démontrent de puissantes capacités générales de compréhension d'images et de textes, leurs performances ne sont pas satisfaisantes lorsqu'il s'agit de résoudre des problèmes. qui nécessitent des connaissances professionnelles. Même GPT4-Vision ne peut pas répondre efficacement aux questions à forte intensité de connaissances (comme le montre la figure 1), ce qui pose des défis à de nombreuses applications au niveau de l'entreprise.
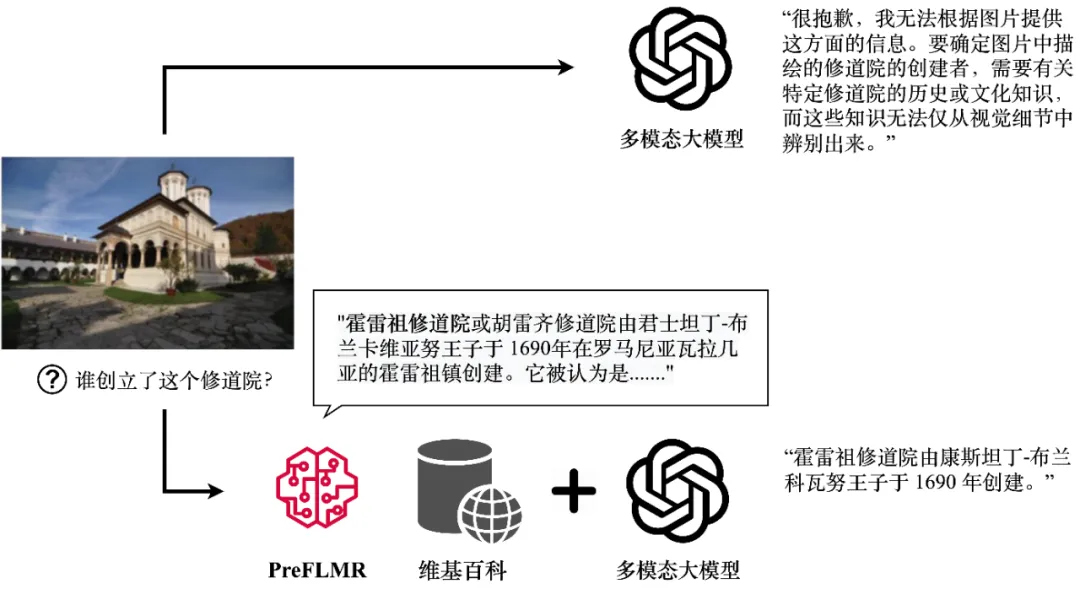
GPT4-Vision peut obtenir des connaissances pertinentes grâce à l'outil de récupération de connaissances multimodal PreFLMR et générer des réponses précises. La figure montre la sortie réelle du modèle.
Retrieval-Augmented Generation (RAG) fournit un moyen simple et efficace de résoudre ce problème, permettant aux grands modèles multimodaux de devenir comme des « experts de domaine » dans un certain domaine. Son principe de fonctionnement est le suivant : tout d'abord, utiliser un outil de récupération de connaissances léger (Knowledge Retriever) pour récupérer les connaissances professionnelles pertinentes à partir de bases de données professionnelles (telles que Wikipédia ou les bases de connaissances d'entreprise), puis le modèle à grande échelle prend ces connaissances et ces questions en entrée ; et produit une réponse précise. La « capacité de rappel » des connaissances des extracteurs de connaissances multimodaux affecte directement la capacité des modèles à grande échelle à obtenir des connaissances professionnelles précises lorsqu'ils répondent à des questions de raisonnement.
Récemment, Le Laboratoire d'Intelligence Artificielle du Département d'Ingénierie de l'Information de l'Université de Cambridge a entièrement open source le premier système de récupération de connaissances multimodales et multimodales pré-entraînées et universelles à interaction tardive, PreFLMR (Pre-trained Fine-grained Retriever multimodal à interaction tardive) . Par rapport aux modèles courants du passé, PreFLMR présente les caractéristiques suivantes :
PreFLMR est un modèle général de pré-formation qui peut résoudre efficacement plusieurs sous-tâches telles que la récupération de texte, la récupération d'images et la récupération de connaissances. Pré-entraîné sur des millions de niveaux de données multimodales, le modèle fonctionne bien dans plusieurs tâches de récupération en aval. De plus, en tant qu'excellent modèle de base, PreFLMR peut rapidement devenir un excellent modèle spécifique à un domaine après un ajustement précis pour les données privées.
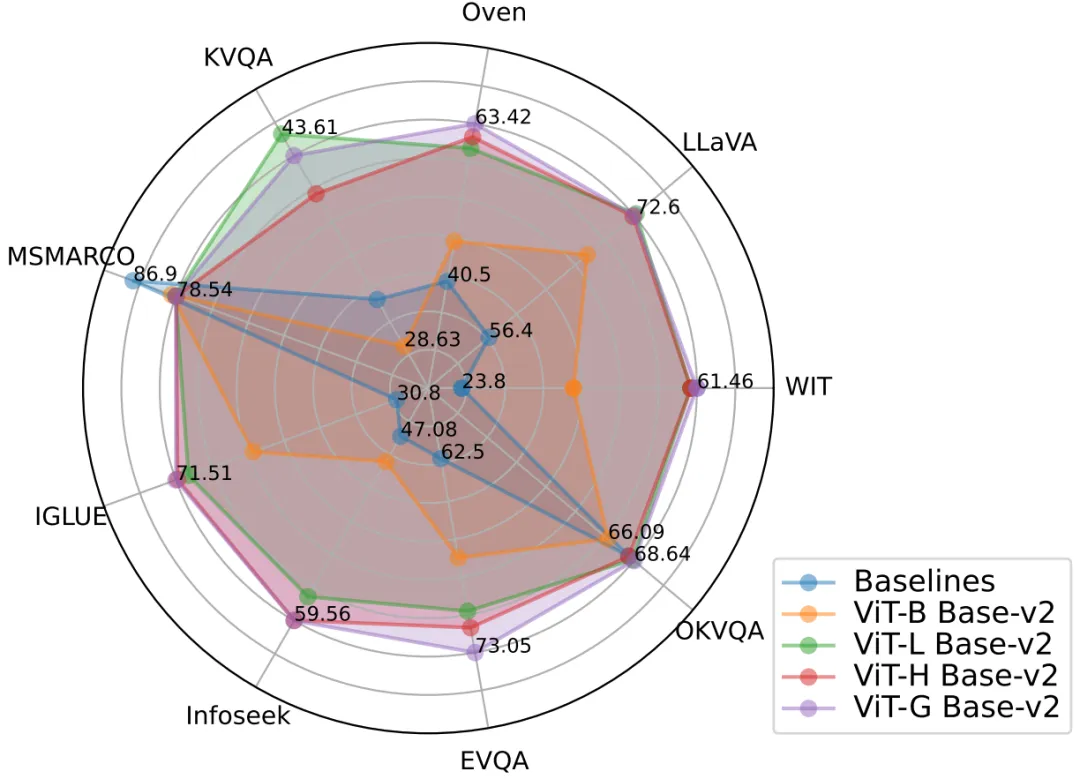
Figure 2 : Le modèle PreFLMR atteint d'excellentes performances de récupération multimodale sur plusieurs tâches en même temps et constitue un modèle de base de pré-entraînement extrêmement solide.
2. La récupération de passages denses traditionnelle (DPR) n'utilise qu'un seul vecteur pour représenter la requête (Requête) ou le document (Document). Le modèle FLMR publié par l'équipe de Cambridge à NeurIPS 2023 a prouvé que la conception de représentation à vecteur unique du DPR peut entraîner une perte d'informations fine, ce qui entraîne de mauvaises performances du DPR dans les tâches de récupération qui nécessitent une correspondance fine des informations. En particulier dans les tâches multimodales, la requête de l'utilisateur contient des informations de scène complexes, et sa compression dans un vecteur unidimensionnel inhibe considérablement la capacité d'expression des fonctionnalités. PreFLMR hérite et améliore la structure de FLMR, lui conférant des avantages uniques dans la récupération de connaissances multimodales.
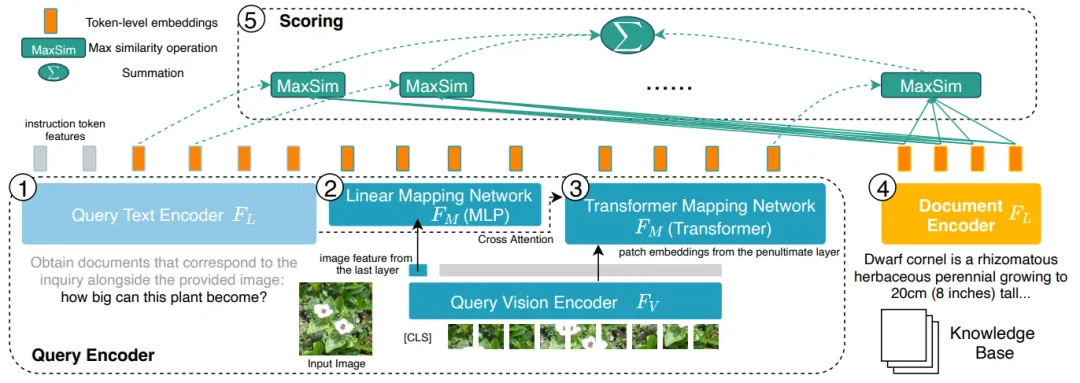
Figure 3 : PreFLMR encode la requête (Requête, 1, 2, 3 à gauche) et le document (Document, 4 à droite) au niveau du caractère (Niveau Token), par rapport à le codage de tous les systèmes DPR qui compressent les informations en vecteurs unidimensionnels présente l'avantage d'obtenir des informations à granularité fine.
3. PreFLMR peut extraire des documents pertinents d'une vaste base de connaissances en fonction des instructions saisies par l'utilisateur (telles que "Extraire les documents pouvant être utilisés pour répondre aux questions suivantes" ou "Extraire les documents liés aux éléments de l'image "), Aide les grands modèles multimodaux à améliorer considérablement les performances des tâches de questions et réponses de connaissances professionnelles.


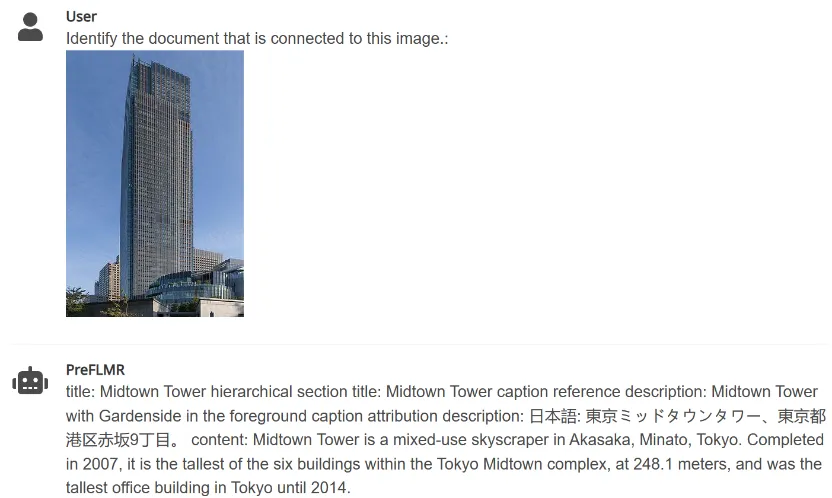
Figure 4 : PreFLMR peut gérer simultanément des tâches de requête multimodales consistant à extraire des documents basés sur des images, à extraire des documents basés sur des questions et à extraire ensemble des documents basés sur des questions et des images. .
L'équipe de l'Université de Cambridge a open source trois modèles de tailles différentes. Les paramètres des modèles du petit au grand sont : PreFLMR_ViT-B (207M), PreFLMR_ViT-L (422M), PreFLMR_ViT-G (2B). , Pour que les utilisateurs choisissent en fonction des conditions réelles.
En plus du modèle open source PreFLMR lui-même, ce projet a également apporté deux contributions importantes dans cette direction de recherche :
- Le projet a également open source un ensemble de données à grande échelle pour la formation et l'évaluation de la récupération de connaissances générales, Multi-tâches Multi-modal Knowledge Retrieval Benchmark (M2KR), qui contient 10 sous-tâches de récupération qui ont été largement étudiées dans le monde universitaire et un total de plus d'un million de paires de récupération.
- Dans cet article, l'équipe de l'Université de Cambridge a comparé des encodeurs d'images et des encodeurs de texte de différentes tailles et performances, et a résumé les meilleures pratiques pour étendre les paramètres et pré-entraîner les systèmes multimodaux de récupération de connaissances post-interaction pour le futur Récupération générale les modèles fournissent des conseils empiriques.
Ce qui suit présentera brièvement l'ensemble de données M2KR, le modèle PreFLMR et l'analyse des résultats expérimentaux.
Ensemble de données M2KR
Pour pré-entraîner et évaluer des modèles généraux de récupération multimodaux à grande échelle, les auteurs ont compilé dix ensembles de données accessibles au public et les ont convertis en un format unifié de récupération de documents-problèmes. Les tâches originales de ces ensembles de données incluent le sous-titrage d'images, le dialogue multimodal, etc. La figure ci-dessous montre les questions (première ligne) et les documents correspondants (deuxième ligne) pour cinq des tâches.

Figure 5 : Une partie de la tâche d'extraction des connaissances dans l'ensemble de données M2KR
Modèle de récupération PreFLMR
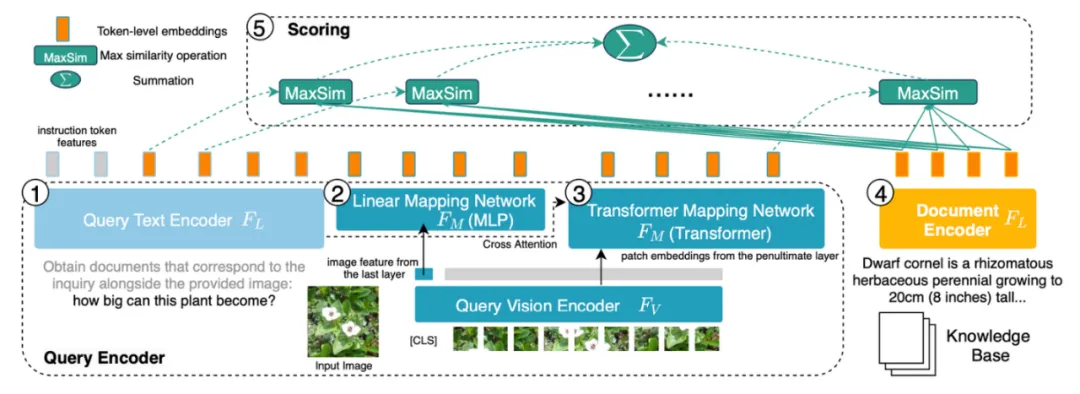
Figure 6 : Structure du modèle de PreFLMR. La requête est codée en tant que fonctionnalité au niveau du jeton. Pour chaque vecteur de la matrice de requête, PreFLMR trouve le vecteur le plus proche dans la matrice du document et calcule le produit scalaire, puis additionne ces produits scalaires maximum pour obtenir la pertinence finale.
Le modèle PreFLMR est basé sur le Fine-graine Late-interaction Multi-modal Retriever (FLMR) publié dans NeurIPS 2023 et subit des améliorations de modèle et une pré-formation à grande échelle sur M2KR. Par rapport au DPR, FLMR et PreFLMR utilisent une matrice composée de tous les vecteurs de jetons pour caractériser les documents et les requêtes. Les jetons comprennent des jetons de texte et des jetons d'image projetés dans l'espace de texte. L'interaction tardive est un algorithme permettant de calculer efficacement la corrélation entre deux matrices de représentation. La méthode spécifique est la suivante : pour chaque vecteur de la matrice de requête, recherchez le vecteur le plus proche dans la matrice du document et calculez le produit scalaire. Ces produits scalaires maximum sont ensuite additionnés pour obtenir la corrélation finale. De cette manière, la représentation de chaque jeton peut affecter explicitement la corrélation finale, préservant ainsi les informations fines au niveau du jeton. Grâce à un moteur de récupération post-interaction dédié, PreFLMR ne prend que 0,2 seconde pour extraire 100 documents pertinents sur 400 000 documents, ce qui améliore considérablement la convivialité dans les scénarios RAG.
La pré-formation au PreFLMR comprend les quatre étapes suivantes :
- Pré-formation de l'encodeur de texte : Tout d'abord, un modèle de récupération de texte post-interactif est pré-entraîné sur MSMARCO (un ensemble de données de récupération de connaissances textuelles pures) en tant qu'encodeur de texte de PreFLMR.
- Pré-formation de la couche de projection image-texte : Deuxièmement, entraînez la couche de projection image-texte sur M2KR et figez les autres parties. Cette étape utilise uniquement des vecteurs d'images projetés pour la récupération, dans le but d'éviter que le modèle ne s'appuie trop sur des informations textuelles.
- Pré-formation continue : L'encodeur de texte et la couche de projection d'image en texte sont ensuite formés en continu sur une tâche de réponse visuelle à des questions de haute qualité et à forte intensité de connaissances dans E-VQA, M2KR. Cette étape vise à améliorer les capacités de récupération de connaissances fines du PreFLMR.
- Formation de récupération universelle : Enfin, entraînez tous les poids sur l'ensemble de données M2KR, en gelant uniquement l'encodeur d'image. Dans le même temps, les paramètres de l'encodeur de texte de requête et de l'encodeur de texte de document sont déverrouillés et entraînés séparément. Cette étape vise à améliorer les capacités générales de récupération de PreFLMR.
Dans le même temps, les auteurs montrent que PreFLMR peut être affiné davantage sur des sous-ensembles de données (tels que OK-VQA, Infoseek) pour obtenir de meilleures performances de récupération sur des tâches spécifiques.
Résultats expérimentaux et expansion verticale
Meilleurs résultats de récupération : le modèle PreFLMR le plus performant utilise ViT-G comme encodeur d'image et ColBERT-base-v2 comme encodeur de texte, avec un total de deux milliards de paramètres. Il atteint des performances au-delà des modèles de base sur 7 sous-tâches de récupération M2KR (WIT, OVEN, Infoseek, E-VQA, OKVQA, etc.).
L'encodage visuel étendu est plus efficace : l'auteur a constaté que la mise à niveau de l'encodeur d'image ViT de ViT-B (86 M) vers ViT-L (307 M) apportait des améliorations significatives des performances, mais la mise à niveau de l'encodeur de texte ColBERT à partir de la base (110 M) ) étendu à une taille importante (345 M) a entraîné une dégradation des performances et des problèmes d'instabilité de la formation. Les résultats expérimentaux montrent que pour les systèmes de récupération multimodaux interactifs ultérieurs, l'augmentation des paramètres de l'encodeur visuel apporte de meilleurs résultats. Dans le même temps, l'utilisation de plusieurs couches d'attention croisée pour la projection image-texte a le même effet que l'utilisation d'une seule couche, de sorte que la conception du réseau de projection image-texte n'a pas besoin d'être trop compliquée.
PreFLMR rend RAG plus efficace : pour les tâches de réponse visuelle à des questions à forte intensité de connaissances, l'utilisation de PreFLMR pour l'amélioration de la récupération améliore considérablement les performances du système final : 94 % et 275 % d'améliorations des performances ont été obtenues sur Infoseek et EVQA respectivement. simple réglage fin, le modèle basé sur BLIP-2 peut vaincre le modèle PALI-X avec des centaines de milliards de paramètres et le système PaLM-Bison+Lens amélioré avec l'API Google.
Conclusion
Le modèle PreFLMR proposé par le Cambridge Artificial Intelligence Laboratory est le premier modèle de récupération multimodale interactive tardive générale open source. Après une pré-formation sur des millions de données sur M2KR, PreFLMR affiche de solides performances dans plusieurs sous-tâches de récupération. L'ensemble de données M2KR, les poids et le code du modèle PreFLMR sont disponibles sur la page d'accueil du projet https://preflmr.github.io/.
Développer les ressources
- Article FLMR (NeurIPS 2023) : https://proceedings.neurips.cc/paper_files/paper/2023/hash/47393e8594c82ce8fd83adc672cf 9872-Résumé-Conférence.html
- Base de code : https://github.com/LinWeizheDragon/Retrieval-Augmented-Visual-Question-Answering
- Blog version anglaise : https://www.jinghong-chen.net/preflmr-sota-open- sourced -multi/
- FLMR Introduction : https://www.jinghong-chen.net/fined-grained-late-interaction-multimodal-retrieval-flmr/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!