
Maison >Périphériques technologiques >IA >Le modèle évoluera après fusion, et gagnera directement SOTA ! Les nouvelles réalisations entrepreneuriales de l'auteur de Transformer sont populaires
Le modèle évoluera après fusion, et gagnera directement SOTA ! Les nouvelles réalisations entrepreneuriales de l'auteur de Transformer sont populaires

- 王林avant
- 2024-03-26 11:30:14650parcourir
Utilisez les modèles prêts à l'emploi sur Huggingface pour "économiser" -
Pouvez-vous combiner directement de nouveaux modèles puissants ? !
Sakana.ai, une grande entreprise de mannequins japonaise, a une grande imagination(c'est l'entreprise fondée par l'un des "Transformer Eight"), et a trouvé une manière si intelligente d'évoluer et de fusionner des modèles.

Cette méthode peut non seulement générer automatiquement un nouveau modèle de base, mais aussi les performances ne sont en aucun cas mauvaises :
Ils utilisent un grand modèle de mathématiques japonaises contenant 7 milliards de paramètres et atteignent un état de résultats de pointe dans des benchmarks pertinents. Les résultats ont dépassé les modèles précédents tels que Llama-2 avec 70 milliards de paramètres.
Le plus important est que pour arriver à un tel modèle ne nécessite aucune formation en gradient , les ressources informatiques nécessaires sont donc fortement réduites.
Le scientifique de NVIDIA, Jim Fan, l'a félicité après l'avoir lu :
C'est l'un des articles les plus imaginatifs que j'ai lu récemment.

Fusionnez l'évolution et générez automatiquement de nouveaux modèles de base
La plupart des modèles les plus performants du classement des grands modèles open source ne sont plus des modèles "originaux" comme LLaMA ou Mistral, mais certains modèles affinés ou fusionnés Après cela, on peut constater :
Une nouvelle tendance a émergé.
Sakana.ai introduit que le modèle de base open source peut être facilement étendu et affiné dans des centaines de directions différentes, puis générer de nouveaux modèles qui fonctionnent bien dans de nouveaux domaines.
Parmi ceux-ci, la Fusion de modèles est très prometteuse.

Cependant, il peut s'agir d'une sorte de « magie noire » qui s'appuie fortement sur l'intuition et l'expertise.
Par conséquent, nous avons besoin d’une approche plus systématique.
Inspiré par la sélection naturelle dans la nature, Sakana.ai se concentre sur les algorithmes évolutifs, introduit le concept de "Evolutionary Model Merge" et propose une méthode générale permettant de découvrir la meilleure combinaison de modèles.
Cette méthode combine deux idées différentes :
(1) fusion de modèles dans l'espace de flux de données (couches) , et (2) fusion de modèles dans l'espace de paramètres (poids) .
Plus précisément, la première méthode spatiale de flux de données consiste à découvrir la meilleure combinaison de différentes couches de modèle à travers l'évolution pour former un nouveau modèle.
Dans le passé, la communauté s'appuyait sur son intuition pour déterminer comment et quelles couches d'un modèle peuvent être combinées avec les couches d'un autre modèle.
Mais en fait, Sakana.ai a introduit que ce problème a un espace de recherche avec un grand nombre de combinaisons, ce qui est le plus approprié pour la recherche par des algorithmes d'optimisation tels que les algorithmes évolutifs.
L'exemple d'opération est le suivant :
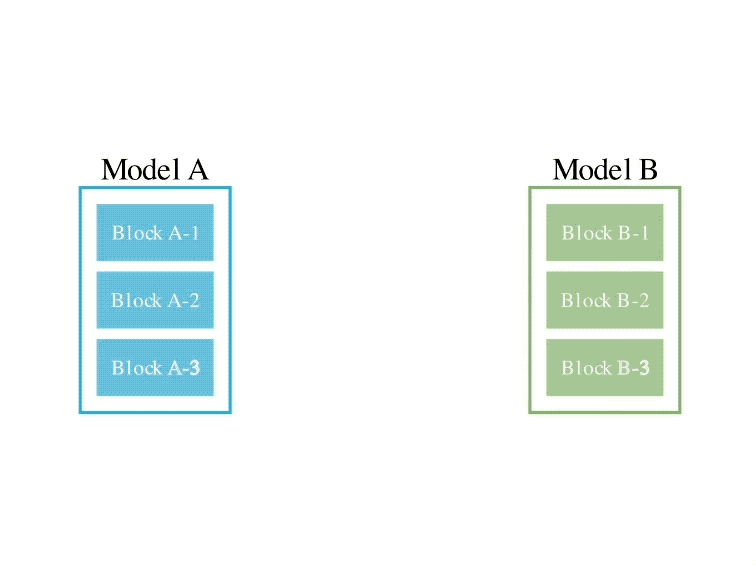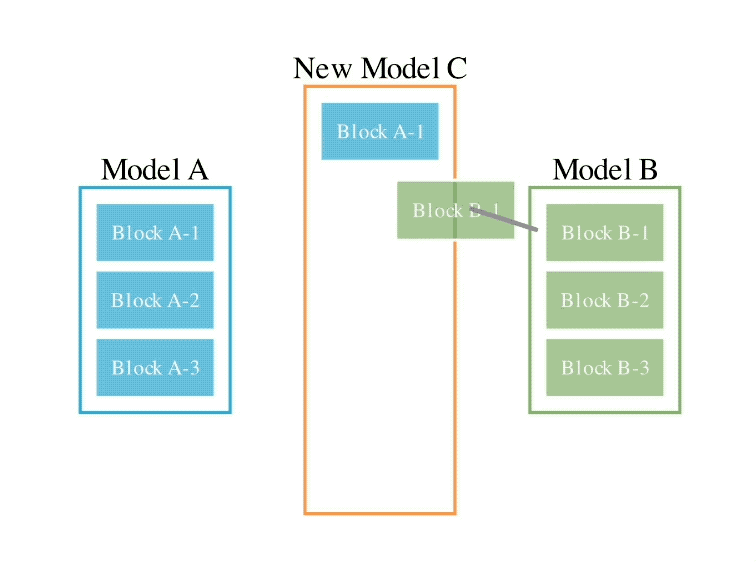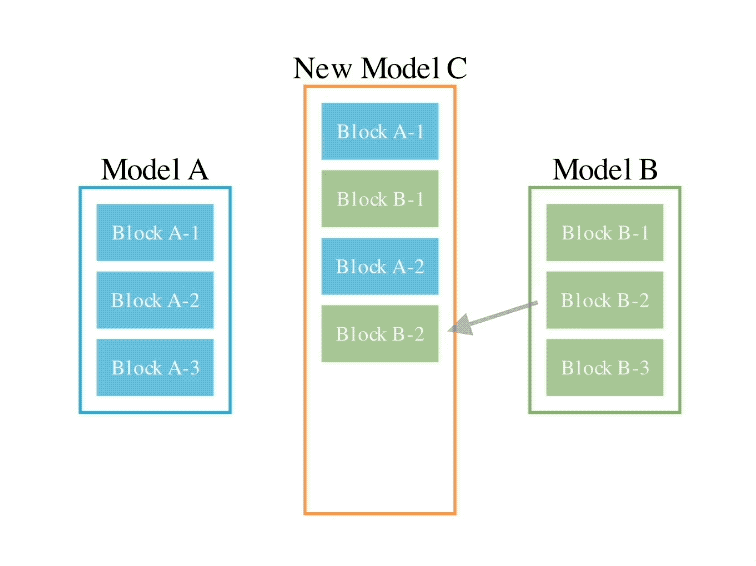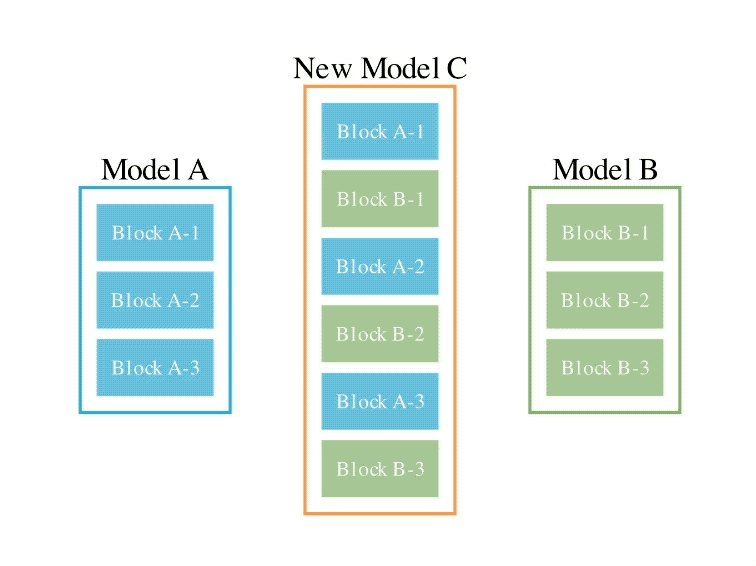
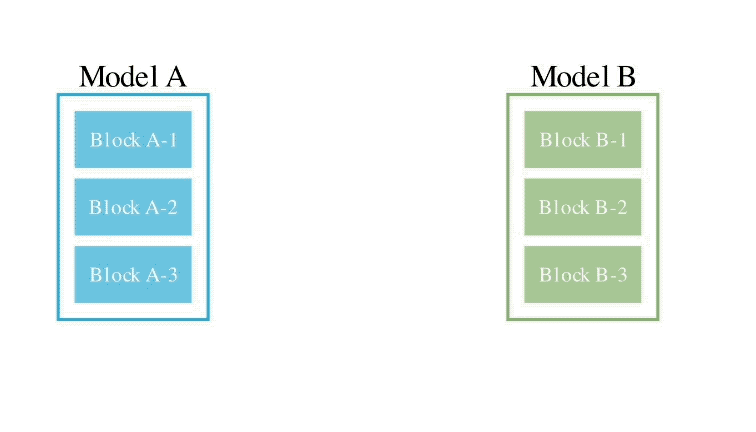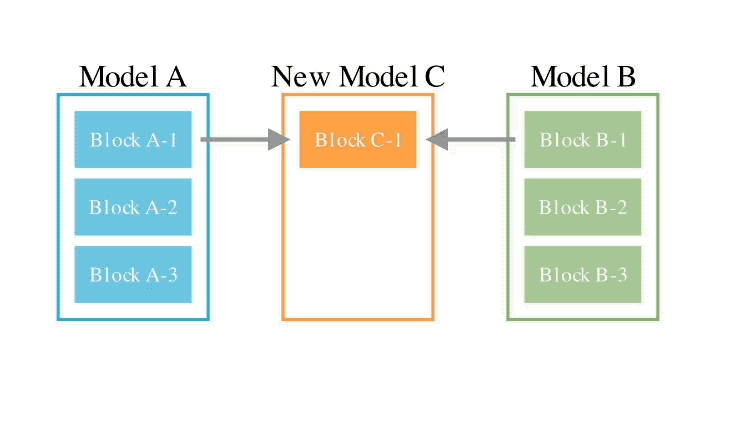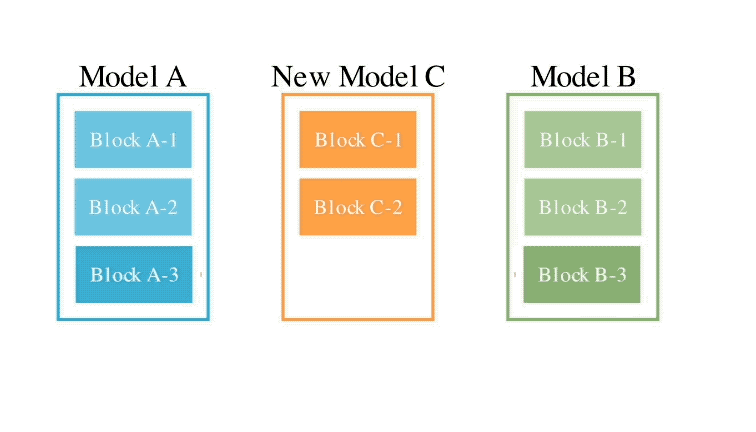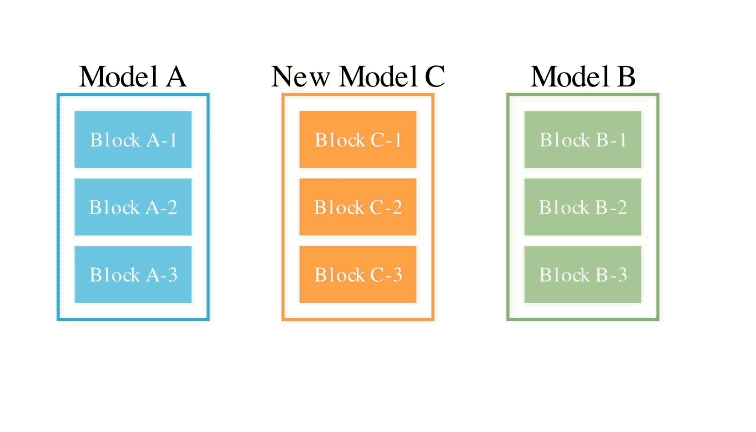
En ce qui concerne la deuxième méthode d'espace de paramètres, plusieurs poids de modèle sont mélangés pour former un nouveau modèle.
Il existe en fait d'innombrables façons de mettre en œuvre cette méthode, et en principe, chaque couche de mélange peut utiliser des ratios de mélange différents, voire plus.
Et ici, en utilisant des méthodes évolutives, nous pouvons effectivement trouver des stratégies hybrides plus nouvelles.
Ce qui suit est un exemple de mélange des poids de deux modèles différents pour obtenir un nouveau modèle :
En combinant les deux méthodes ci-dessus, voici à quoi cela ressemble :
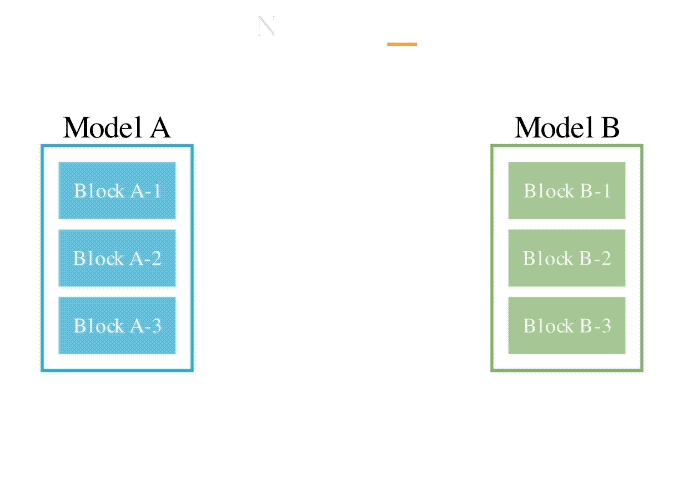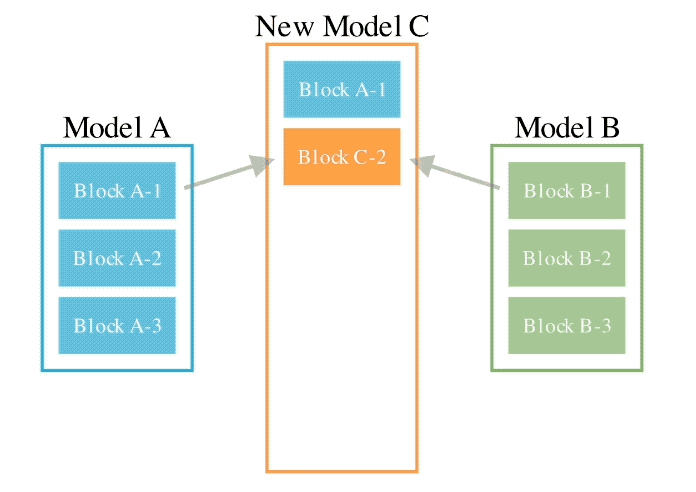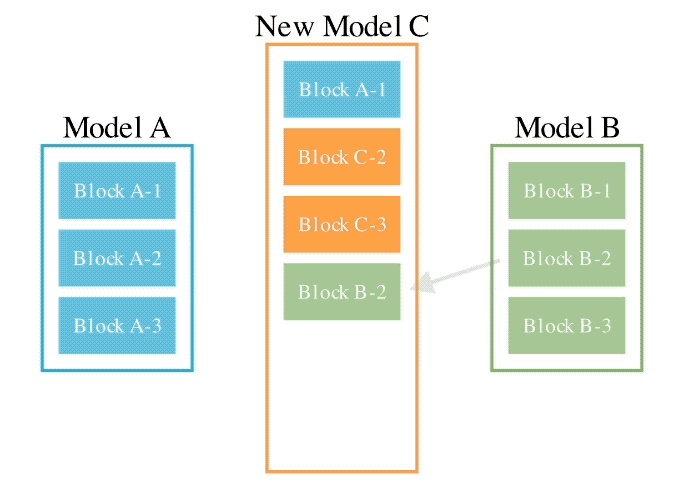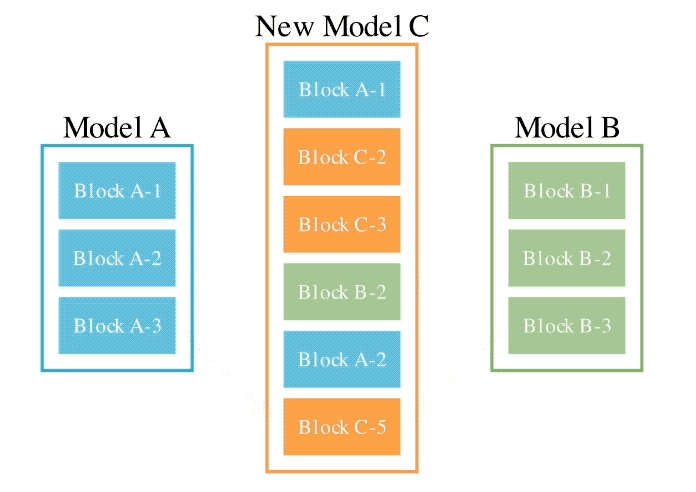
L'auteur a présenté qu'il espérait pour atteindre l'objectif de combiner les poids de deux domaines différents, tels que les mathématiques et les langues non anglaises, la vision et les langues non anglaises, pour former des combinaisons émergentes qui n'ont jamais été explorées auparavant.
Le résultat est vraiment surprenant.
Le nouveau modèle gagne facilement SOTA
En utilisant la méthode de fusion évolutive ci-dessus, l'équipe a obtenu 3 modèles de base :
- Grand modèle de langage EvoLLM-JP
Il est composé du grand modèle japonais Shisa-Gamma et grand modèle mathématique. Le modèle est une fusion de WizardMath/Abel, qui est efficace pour résoudre les problèmes mathématiques japonais et a évolué sur 100 à 150 générations.
- Modèle de langage visuel EvoVLM-JP
Grand modèle japonais Shisa Gamma 7B v1+LLaVa-1.6-Mistral-7B, est un VLM avec des capacités de langue japonaise.
- Modèle de génération d'images EvoSDXL-JP
Prend en charge le modèle de diffusion SDXL japonais.
Les deux premiers ont été publiés sur Hugging Face et GitHub, et le dernier sera bientôt lancé.
Regardez-le spécifiquement.
1. EvoLLM-JP
Il a obtenu les résultats suivants sur l'ensemble d'évaluation japonais de MGSM, une version multilingue de l'ensemble de données GSM8K :
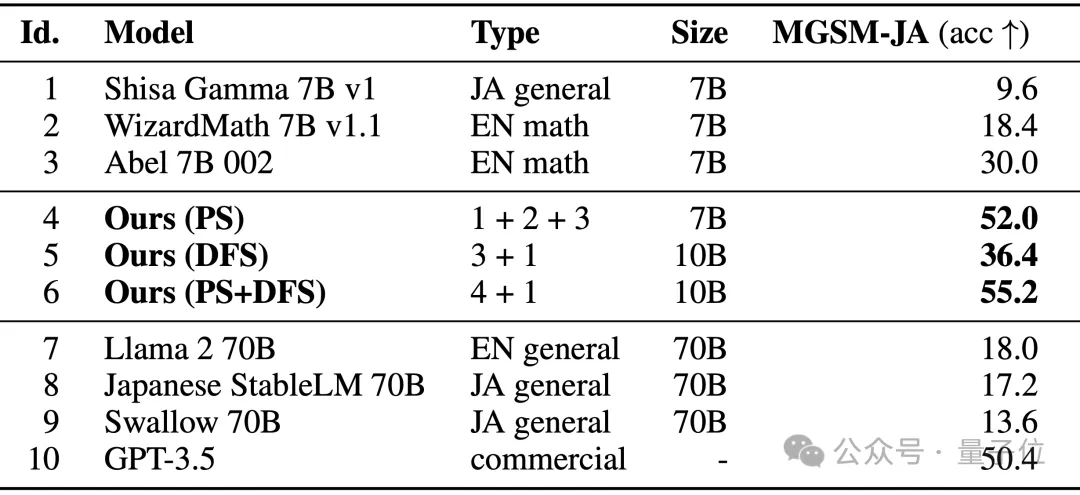
Comme vous pouvez le voir, EvoLLM-JP résout les mathématiques en japonais Les performances du problème dépassent leurs modèles d'origine, ainsi que les modèles hautes performances tels que Llama-2 et GPT-3.5.
Parmi eux, le modèle 4 est optimisé uniquement dans l'espace des paramètres, et le modèle 6 est le résultat d'une optimisation plus poussée dans l'espace des flux de données à l'aide du modèle 4.
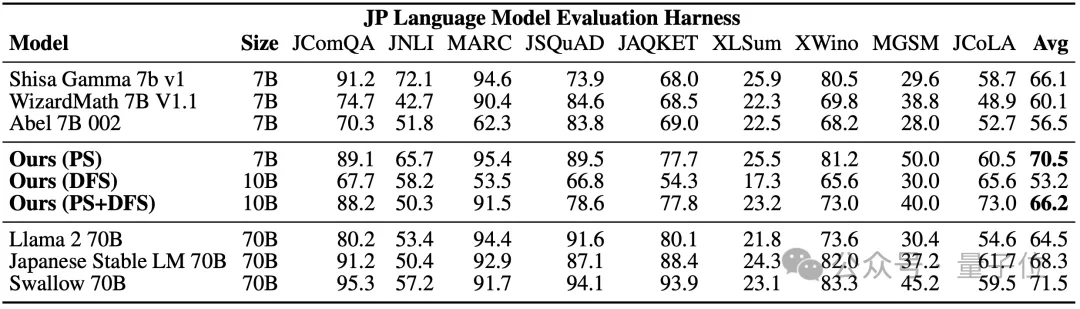
Sur le benchmark japonais lm-evaluation-harness, qui évalue à la fois les capacités de données et les compétences générales en langue japonaise, EvoLLM-JP a obtenu le score moyen le plus élevé de 70,5 sur 9 tâches - en utilisant seulement 7 milliards de paramètres, il a vaincu 70 milliards de Llama-2. et d'autres modèles.
L'équipe a déclaré qu'EvoLLM-JP est suffisamment bon pour être utilisé comme modèle japonais général à grande échelle et résoudre quelques exemples intéressants :
tels que des problèmes mathématiques qui nécessitent une connaissance spécifique de la culture japonaise ou raconter des blagues japonaises. en dialecte du Kansai.
2, EvoVLM-JP
Sur les deux ensembles de données de référence suivants de questions et réponses d'images, plus le score est élevé, plus la description de la réponse du modèle en japonais est précise.
En conséquence, il est non seulement meilleur que le VLM anglais LLaVa-1.6-Mistral-7B sur lequel il est basé, mais aussi meilleur que le VLM japonais existant.

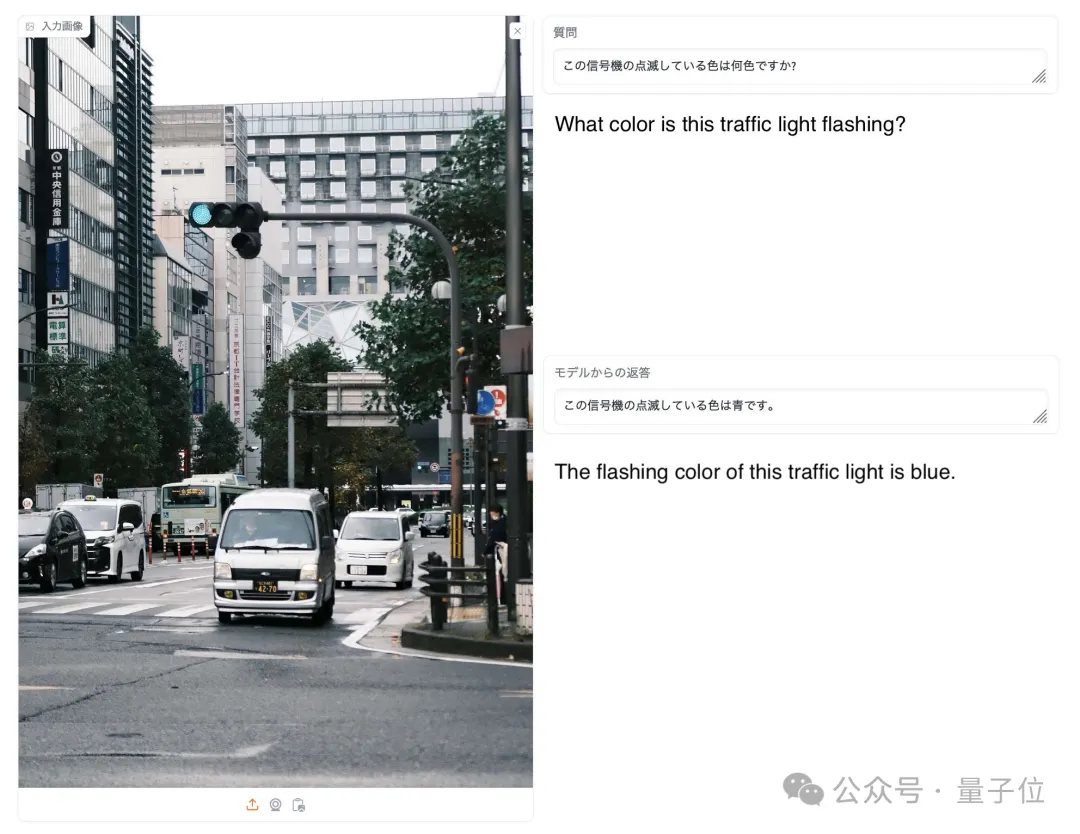
Comme le montre l'image ci-dessous, lorsqu'on lui a demandé quelle est la couleur du signal lumineux sur l'image, seul EvoVLM-JP a répondu correctement : bleu.
3, EvoSDXL-JP
Ce modèle SDXL qui prend en charge le japonais ne nécessite que 4 modèles de diffusion pour effectuer l'inférence, et la vitesse de génération est assez rapide.
Les scores spécifiques de course à pied n'ont pas encore été publiés, mais l'équipe a révélé qu'ils sont "assez prometteurs".
Vous pouvez profiter de quelques exemples :
Les mots rapides incluent : Miso ラーメン, Ukiyoe de la plus haute qualité, Katsushika Hokusai, Période Edo.

Pour les 3 nouveaux modèles ci-dessus, l'équipe a souligné :
En principe, nous pouvons utiliser la rétropropagation basée sur le gradient pour améliorer encore les performances de ces modèles.
Mais nous n'utilisons pas , car le but est maintenant de montrer que même sans rétropropagation, nous pouvons toujours obtenir un modèle de base suffisamment avancé pour remettre en question le « paradigme coûteux » actuel.
Les internautes ont aimé cela les uns après les autres.
Jim Fan a également ajouté :
Dans le domaine des modèles de base, actuellement, la communauté est presque entièrement axée sur l'apprentissage du modèle, et ne prête pas beaucoup d'attention à la recherche , mais cette dernière est la formation (qui c'est-à-dire l'algorithme évolutif proposé dans cet article) et l'étape de raisonnement ont en fait un énorme potentiel.
△Aimé par Musk
Donc, comme l'ont dit les internautes :
Sommes-nous maintenant dans l'ère de l'explosion cambrienne du modèle ?

Adresse papier : https://arxiv.org/abs/2403.13187
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les raisons et les solutions à l'échec de la connexion à la base de données ?
- Comment utiliser vlookup d'Excel pour faire correspondre plusieurs colonnes de données à la fois
- Le meilleur expert en IA de Google rejoint OpenAI et avertit Google de ne pas utiliser les données ChatGPT pour former Bard
- Musk annonce qu'il poursuivra Microsoft pour avoir utilisé les données de Twitter pour entraîner un système d'intelligence artificielle
- Comment utiliser PyTorch pour la formation aux réseaux neuronaux