
Maison >Périphériques technologiques >IA >Accélérer encore la mise en œuvre : compresser le modèle de planification de mouvement de bout en bout de la conduite autonome
Accélérer encore la mise en œuvre : compresser le modèle de planification de mouvement de bout en bout de la conduite autonome

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-16 16:01:021221parcourir
Titre original : Sur la route de la portabilité : Compresser un planificateur de mouvement de bout en bout pour la conduite autonome
Lien papier : https://arxiv.org/pdf/2403.01238.pdf
Lien code : https://github .com/tulerfeng/PlanKD
Affiliation de l'auteur : Institut de technologie de Pékin ALLRIDE.AI Laboratoire clé provincial du Hebei pour la science du Big Data et la technologie intelligente

Idée de thèse
Un modèle de planification de mouvement de bout en bout équipé avec un réseau neuronal profond, montrant un grand potentiel pour réaliser une conduite entièrement autonome. Cependant, les réseaux neuronaux trop grands les rendent impropres au déploiement sur des systèmes aux ressources limitées, qui nécessitent sans aucun doute plus de temps et de ressources de calcul. Pour résoudre ce problème, la distillation des connaissances offre une approche prometteuse en compressant les modèles en faisant apprendre à un modèle d'étudiant plus petit à partir d'un modèle d'enseignant plus grand. Néanmoins, la manière d’appliquer la distillation des connaissances pour compresser les planificateurs de mouvements reste jusqu’à présent inexplorée. Cet article propose PlanKD, le premier cadre de distillation de connaissances adapté aux planificateurs de mouvements compressifs de bout en bout. Premièrement, étant donné que les scénarios de conduite sont intrinsèquement complexes et contiennent souvent des informations non pertinentes pour la planification, voire bruyantes, le transfert de ces informations ne serait pas bénéfique pour l'étudiant planificateur. Par conséquent, cet article conçoit une stratégie basée sur le goulot d'étranglement de l'information, qui distille uniquement les informations liées à la planification au lieu de migrer toutes les informations sans discernement. Deuxièmement, différents points de cheminement dans la trajectoire planifiée en sortie peuvent varier en importance pour la planification du mouvement, et de légers écarts dans certains points de cheminement critiques peuvent conduire à des collisions. Par conséquent, cet article conçoit un module de distillation attentif aux points de cheminement et soucieux de la sécurité pour attribuer des poids adaptatifs à différents points de cheminement en fonction de leur importance afin d'encourager les modèles d'étudiants à imiter plus précisément des points de cheminement plus critiques, améliorant ainsi la sécurité globale. Les expériences montrent que notre PlanKD peut améliorer considérablement les performances des petits planificateurs et réduire considérablement leur temps de référence.
Principales contributions :
- Cet article constitue la première tentative d'exploration de méthodes dédiées de distillation des connaissances pour compresser les planificateurs de mouvement de bout en bout dans la conduite autonome.
- Cet article propose un cadre général et innovant PlanKD, qui permet aux étudiants planificateurs d'hériter des connaissances liées à la planification dans la couche intermédiaire et facilite la correspondance précise des points de cheminement clés pour améliorer la sécurité.
- Les expériences montrent que PlanKD dans cet article peut améliorer considérablement les performances des petits planificateurs, fournissant ainsi une solution plus portable et plus efficace pour un déploiement avec des ressources limitées.
Conception de réseau :
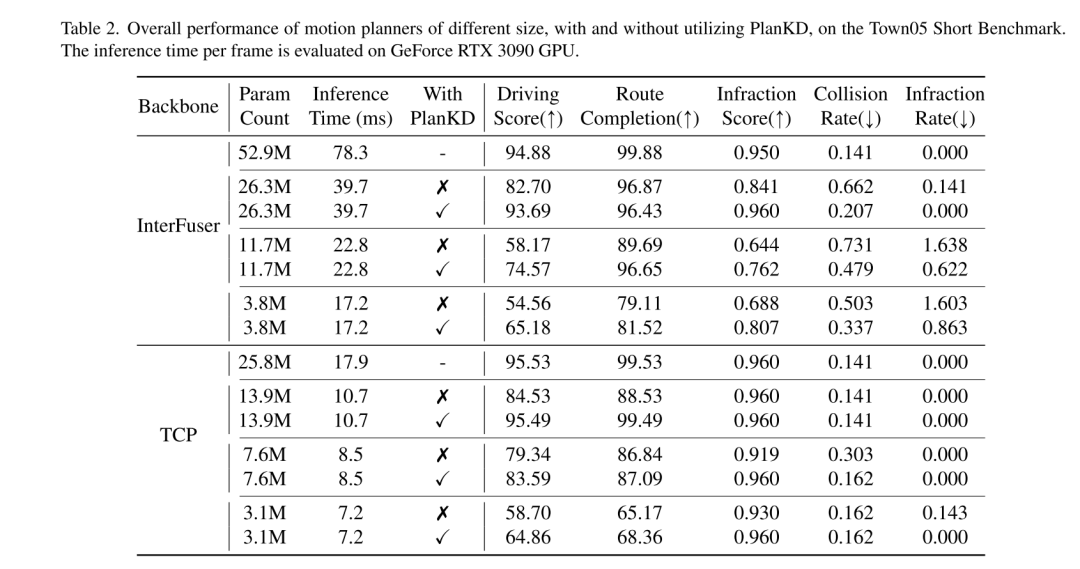
La planification de mouvement de bout en bout est récemment apparue comme une direction prometteuse dans la conduite autonome [3, 10, 30, 31, 40, 47, 48], qui mappe directement les données brutes des capteurs à actions planifiées. Ce paradigme basé sur l'apprentissage présente les avantages de réduire la dépendance à l'égard de règles élaborées à la main et d'atténuer l'accumulation d'erreurs au sein de modules en cascade complexes (généralement détection-suivi-prédiction-planification) [40, 48]. Malgré leur succès, l'architecture volumineuse des réseaux neuronaux profonds dans les planificateurs de mouvement pose des défis pour le déploiement dans des environnements aux ressources limitées, tels que les robots de livraison autonomes qui s'appuient sur la puissance de calcul des appareils de pointe. De plus, même dans les véhicules conventionnels, les ressources informatiques embarquées sont souvent limitées [34]. Par conséquent, le déploiement direct de planificateurs approfondis et de grande envergure nécessite inévitablement plus de temps de calcul et de ressources, ce qui rend difficile la réponse rapide aux dangers potentiels. Pour atténuer ce problème, une approche simple consiste à réduire le nombre de paramètres de réseau en utilisant un réseau fédérateur plus petit, mais cet article observe que les performances du modèle de planification de bout en bout chuteront fortement, comme le montre la figure 1. Par exemple, bien que le temps d'inférence d'InterFuser [33], un planificateur de mouvement de bout en bout typique, ait été réduit de 52,9 M à 26,3 M, son score de conduite a également chuté de 53,44 à 36,55. Il est donc nécessaire de développer une méthode de compression de modèle adaptée à la planification de mouvement de bout en bout.
Afin d'obtenir un planificateur de mouvement portable, cet article utilise la distillation des connaissances [19] pour compresser le modèle de planification de mouvement de bout en bout. La distillation des connaissances (KD) a été largement étudiée pour la compression de modèles dans diverses tâches, telles que la détection d'objets [6, 24], la segmentation sémantique [18, 28], etc. L'idée de base de ces travaux est de former un modèle d'étudiant simplifié en héritant des connaissances d'un modèle d'enseignant plus large et d'utiliser le modèle d'étudiant pour remplacer le modèle d'enseignant lors du déploiement. Bien que ces études aient connu un succès significatif, leur application directe à la planification de mouvements de bout en bout conduit à des résultats sous-optimaux. Cela découle de deux défis émergents inhérents aux tâches de planification de mouvement : (i) Les scénarios de conduite sont de nature complexe [46], impliquant plusieurs objets dynamiques et statiques, des scènes d'arrière-plan complexes et des routes et un trafic à multiples facettes, y compris des informations diverses. Cependant, toutes ces informations ne sont pas utiles à la planification. Par exemple, les bâtiments en arrière-plan et les véhicules éloignés ne sont pas pertinents, voire bruyants, pour la planification [41], tandis que les véhicules et les feux de circulation à proximité ont un impact déterministe. Par conséquent, il est crucial d’extraire automatiquement du modèle d’enseignant uniquement les informations pertinentes pour la planification, ce que les méthodes précédentes de KD ne peuvent pas réaliser. (ii) Différents points de cheminement dans la trajectoire de planification de sortie ont généralement une importance différente pour la planification de mouvement. Par exemple, lors de la navigation à une intersection, les waypoints d'une trajectoire proches d'autres véhicules peuvent avoir une plus grande importance que les autres waypoints. En effet, à ces moments-là, le véhicule autonome doit interagir activement avec les autres véhicules, et même de petits écarts peuvent entraîner des collisions. Cependant, la manière de déterminer de manière adaptative les points de cheminement clés et de les imiter avec précision constitue un autre défi majeur des méthodes KD précédentes.
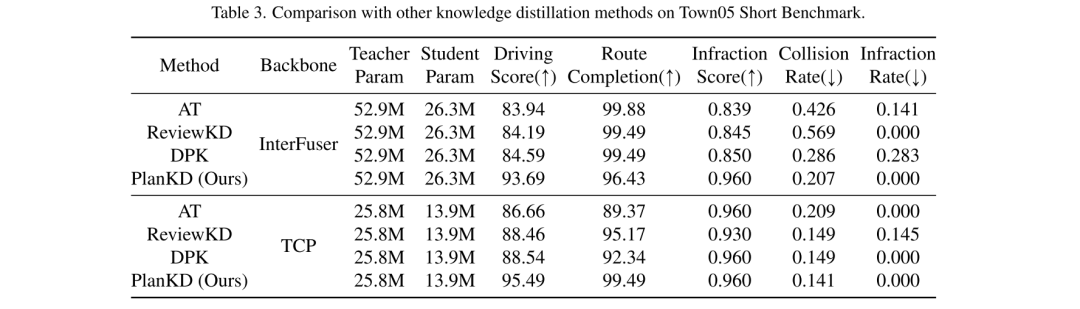
Pour relever les deux défis ci-dessus, cet article propose la première méthode de distillation des connaissances adaptée aux planificateurs de mouvements de bout en bout en conduite autonome compressée, appelée PlanKD. Tout d'abord, cet article propose une stratégie basée sur le principe du goulot d'étranglement de l'information [2], dont le but est d'extraire des fonctionnalités liées à la planification qui contiennent un minimum et suffisamment d'informations de planification. Plus précisément, cet article maximise les informations mutuelles entre les fonctionnalités extraites liées à la planification et les valeurs réelles des états de planification définis dans cet article, tout en minimisant les informations mutuelles entre les fonctionnalités extraites et les cartes de fonctionnalités intermédiaires. Cette stratégie permet à cet article d'extraire des informations clés pertinentes pour la planification uniquement au niveau de la couche intermédiaire, améliorant ainsi l'efficacité du modèle étudiant. Deuxièmement, afin d'identifier dynamiquement les points de cheminement clés et de les imiter fidèlement, cet article adopte un mécanisme d'attention [38] pour calculer chaque point de cheminement et son poids d'attention entre lui et le contexte associé dans la vue à vol d'oiseau (BEV). Pour promouvoir une imitation précise des points de cheminement critiques pour la sécurité pendant la distillation, nous concevons une perte de classement soucieuse de la sécurité qui encourage à accorder une plus grande attention aux points de cheminement proches d'obstacles en mouvement. En conséquence, la sécurité des planificateurs étudiants peut être considérablement améliorée. Les preuves présentées dans la figure 1 montrent que le score de conduite des étudiants planificateurs peut être considérablement amélioré grâce à notre PlanKD. De plus, notre méthode peut réduire le temps de référence d'environ 50 % tout en conservant des performances comparables à celles du planificateur d'enseignant sur le Town05 Long Benchmark.
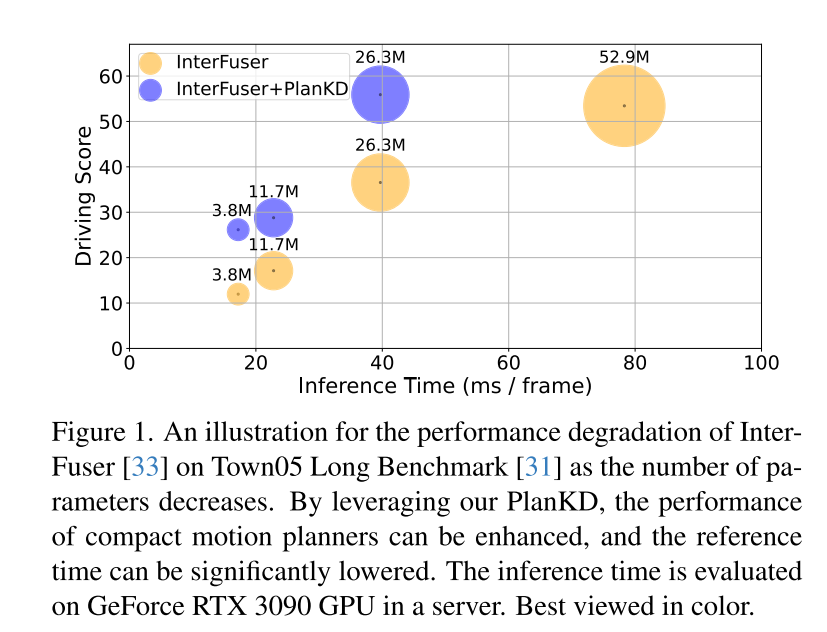
Figure 1. Diagramme schématique de la dégradation des performances d'InterFuser[33] à mesure que le nombre de paramètres diminue sur le Town05 Long Benchmark [31]. En tirant parti de notre PlanKD, nous pouvons améliorer les performances des planificateurs de mouvements compacts et réduire considérablement les temps de référence. Les temps d'inférence sont évalués sur un GPU GeForce RTX 3090 sur le serveur.
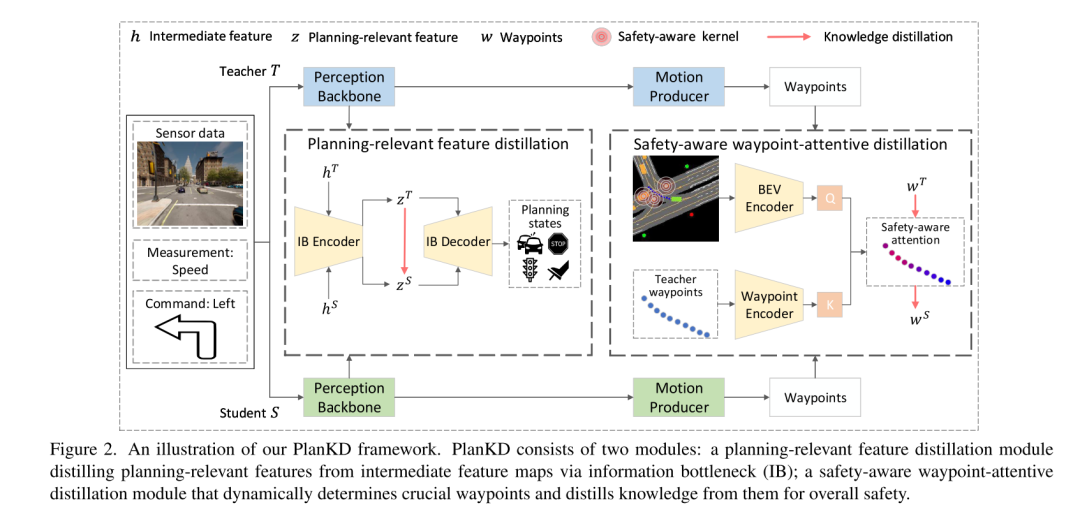
Figure 2. Diagramme schématique du framework PlanKD de cet article. PlanKD se compose de deux modules : un module de distillation des caractéristiques liées à la planification qui extrait les caractéristiques liées à la planification des cartes de caractéristiques intermédiaires via des goulots d'étranglement d'informations (IB) ; un module de distillation attentif aux points de cheminement et soucieux de la sécurité qui détermine dynamiquement les points de cheminement clés et en extrait les connaissances pour améliorer la sécurité globale.
Résultats expérimentaux :
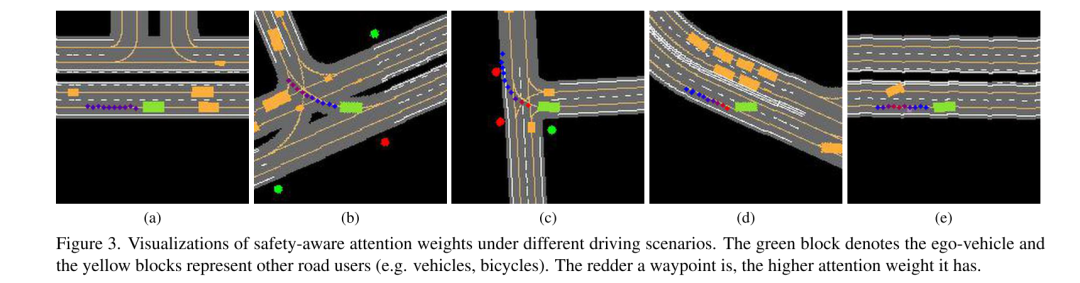
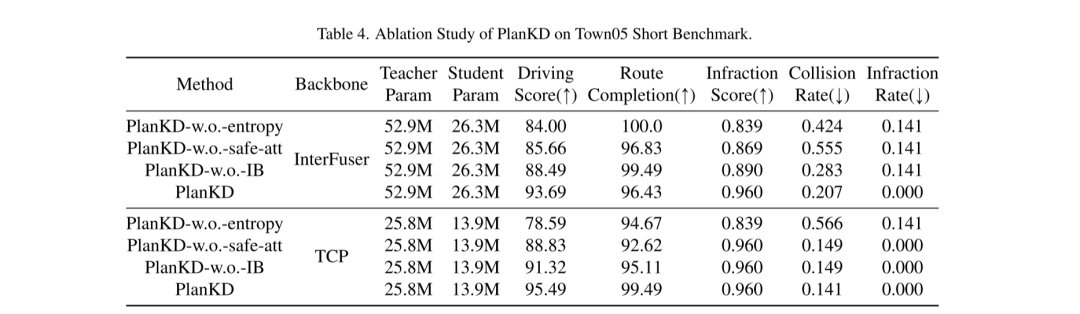
Figure 3. Visualisation de poids d'attention soucieux de la sécurité dans différents scénarios de conduite. Les blocs verts représentent l'ego-véhicule et les blocs jaunes représentent les autres usagers de la route (par exemple les voitures, les vélos). Plus un waypoint est rouge, plus son poids d’attention est élevé.
Résumé :
Cet article propose PlanKD, une méthode de distillation des connaissances adaptée aux planificateurs de mouvements compressifs de bout en bout. La méthode proposée peut apprendre des fonctionnalités liées à la planification à travers des goulots d'étranglement d'informations pour obtenir une distillation efficace des fonctionnalités. De plus, cet article conçoit un mécanisme de distillation attentif aux points de cheminement, soucieux de la sécurité, pour décider de manière adaptative de l'importance de chaque point de cheminement pour la distillation de points de cheminement. Des expériences approfondies valident l'efficacité de notre approche, démontrant que PlanKD peut servir de solution portable et sécurisée pour les déploiements aux ressources limitées.
Citation :
Feng K, Li C, Ren D, et al. Sur la route de la portabilité : compression d'un planificateur de mouvement de bout en bout pour la conduite autonome [J].
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les modèles de données couramment utilisés ?
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Qu'est-ce qu'un modèle de développement logiciel et quels sont les modèles de développement logiciels courants ?
- Conversation avec Tsinghua Huang Minlie : Empruntant la définition hiérarchique du système de dialogue IA pour la conduite autonome, le compagnon virtuel du Metaverse pourrait être situé en L5
- Lorsque l'apprentissage automatique est mis en œuvre dans la conduite autonome, le cœur n'est pas le modèle, mais le pipeline