
Maison >Périphériques technologiques >IA >Lorsque l'apprentissage automatique est mis en œuvre dans la conduite autonome, le cœur n'est pas le modèle, mais le pipeline
Lorsque l'apprentissage automatique est mis en œuvre dans la conduite autonome, le cœur n'est pas le modèle, mais le pipeline

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-05 11:46:061508parcourir
Cet article est reproduit à partir de Lei Feng.com Si vous devez le réimprimer, veuillez vous rendre sur le site officiel de Lei Feng.com pour demander une autorisation.
Lorsque j'ai commencé mon premier emploi après l'université, je pensais en savoir beaucoup sur l'apprentissage automatique. J'ai effectué deux stages chez Pinterest et Khan Academy pour créer des systèmes d'apprentissage automatique. Au cours de ma dernière année à Berkeley, j'ai mené des recherches sur l'apprentissage profond pour la vision par ordinateur et j'ai travaillé sur Caffe, l'une des premières bibliothèques d'apprentissage profond populaires. Après avoir obtenu mon diplôme, j'ai rejoint une petite startup appelée « Cruise », spécialisée dans la production de voitures autonomes. Je suis maintenant chez Aquarium, où j'aide les entreprises à déployer des modèles d'apprentissage profond pour résoudre d'importants problèmes sociaux.
Au fil des années, j'ai construit une pile d'apprentissage profond et de vision par ordinateur plutôt cool. De plus en plus de personnes utilisent désormais l'apprentissage profond dans les applications de production que lorsque je faisais des recherches à Berkeley. La plupart des problèmes auxquels ils sont confrontés aujourd’hui sont les mêmes que ceux auxquels j’ai été confronté chez Cruise en 2016. J’ai beaucoup de leçons apprises sur l’apprentissage profond en production que je souhaite partager avec vous, et j’espère que vous n’aurez pas à les apprendre à la dure.

Note : L'équipe de l'auteur développe le premier modèle de machine learning déployé sur une voiture# 🎜🎜 #
1 L'histoire du déploiement de modèles ML sur des voitures autonomesTout d'abord, permettez-moi de parler du tout premier modèle ML de Cruise déployé sur une voiture. Au fur et à mesure que nous développions le modèle, le flux de travail ressemblait beaucoup à celui auquel j'étais habitué pendant mes jours de recherche. Nous formons des modèles open source sur des données open source, les intégrons dans la pile logicielle de produits de l'entreprise et les déployons sur les voitures. Après quelques semaines de travail, nous avons fusionné le PR final et exécuté le modèle sur la voiture. "Mission accomplie !", me suis-je dit, nous devrions continuer à éteindre le prochain incendie. Je ne le savais pas, le vrai travail ne faisait que commencer. Le modèle a été mis en production et notre équipe d'assurance qualité a commencé à remarquer des problèmes avec ses performances. Mais nous avions d’autres modèles à construire et d’autres tâches à accomplir, nous n’avons donc pas résolu ces problèmes tout de suite. Lorsque nous avons examiné les problèmes 3 mois plus tard, nous avons découvert que les scripts de formation et de validation étaient tous cassés car la base de code avait changé depuis notre premier déploiement. Après une semaine de correctifs, nous avons examiné les échecs des derniers mois et avons réalisé que de nombreux problèmes observés lors des exécutions de production de modèles ne pouvaient pas être facilement résolus en modifiant le code du modèle et que nous devions collecter et signalez-les Nouvelles données provenant de nos véhicules d'entreprise plutôt que de s'appuyer sur des données open source. Cela signifie que nous devons établir un processus de labellisation, comprenant tous les outils, opérations et infrastructures nécessaires au processus. Encore 3 mois plus tard, nous avons exécuté un nouveau modèle qui a été formé sur les données que nous avons sélectionnées au hasard dans la voiture. Ensuite, marquez-le avec nos propres outils. Mais lorsque nous commençons à résoudre des problèmes simples, nous devons faire preuve de plus de discernement quant aux changements susceptibles d’avoir des conséquences. Environ 90 % des problèmes sont résolus grâce à une conservation minutieuse des données de scénarios difficiles ou rares, plutôt qu'à travers des modifications profondes de l'architecture du modèle ou un réglage des hyperparamètres. Par exemple, nous avons constaté que le modèle fonctionnait mal les jours de pluie (une rareté à San Francisco). Nous avons donc étiqueté davantage de données sur les jours de pluie, recyclé le modèle sur les nouvelles données et amélioré les performances du modèle. De même, nous avons constaté que le modèle fonctionnait mal sur les frustums verts (qui sont moins courants que les frustums orange). Nous avons donc collecté des données sur les frustums verts et suivi le même processus, et les performances du modèle se sont améliorées. Nous devons établir un processus permettant d'identifier et de résoudre rapidement ce type de problèmes. Il a fallu quelques semaines pour assembler la version 1.0 de ce modèle, et il a fallu encore 6 mois pour lancer une nouvelle version améliorée du modèle. Alors que nous travaillons de plus en plus sur plusieurs aspects (meilleure infrastructure d'étiquetage, traitement des données cloud, infrastructure de formation, suivi du déploiement), nous recyclons et redéployons les modèles environ tous les mois à chaque semaine. À mesure que nous construisons davantage de pipelines de modèles à partir de zéro et travaillons à les améliorer, nous commençons à voir des thèmes communs. En appliquant ce que nous avons appris aux nouveaux pipelines, il est devenu plus facile d'exécuter de meilleurs modèles plus rapidement et avec moins d'effort. 2 Continuez à apprendre de manière itérative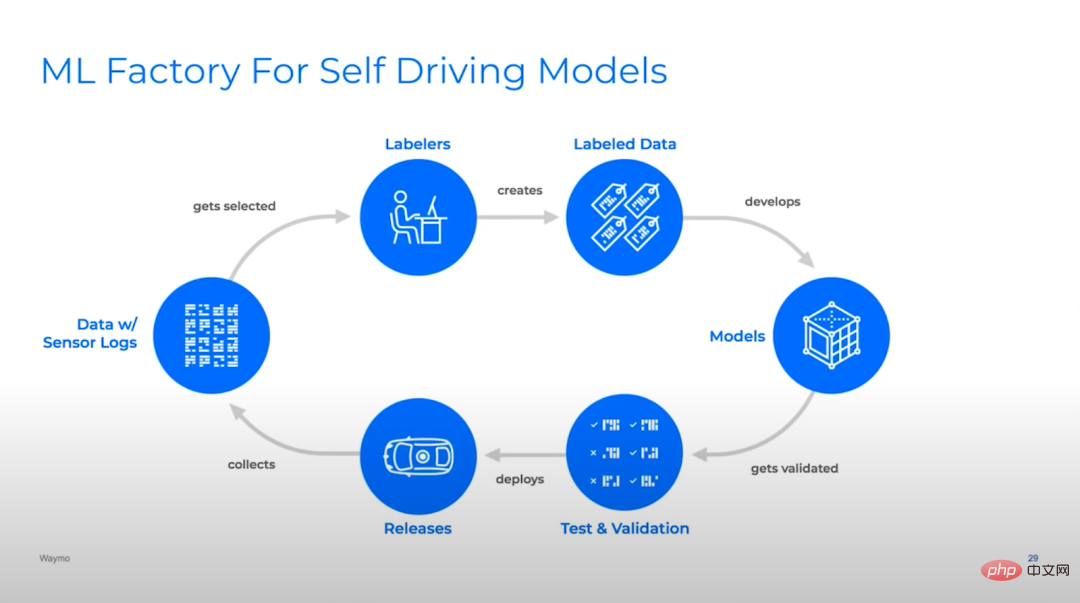
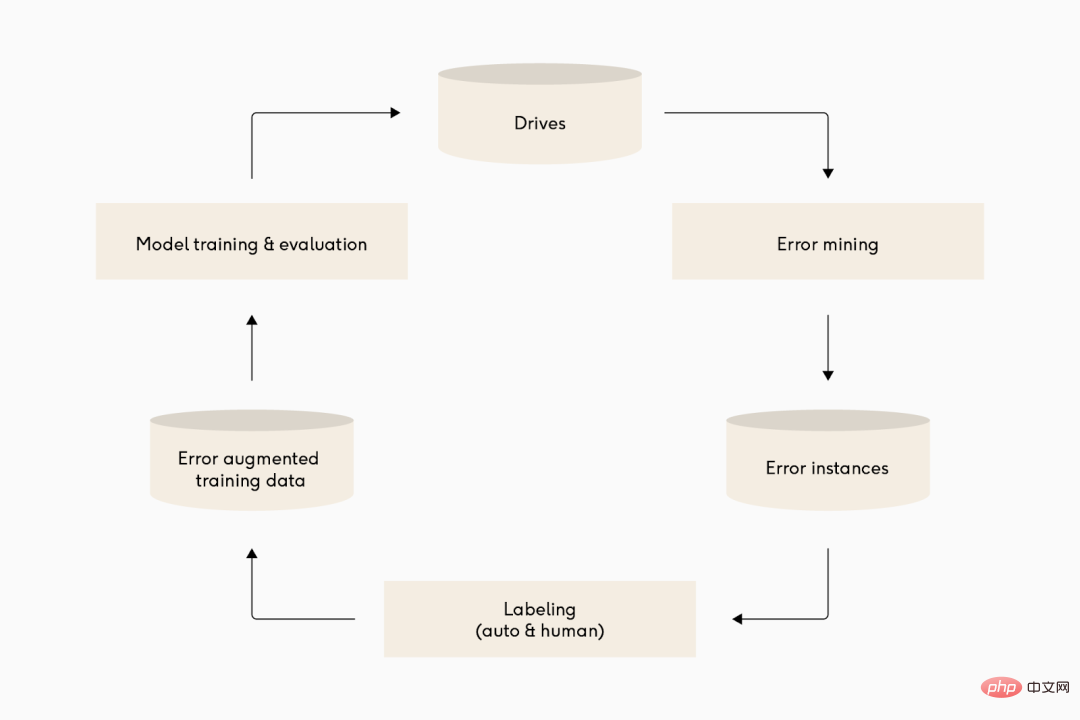
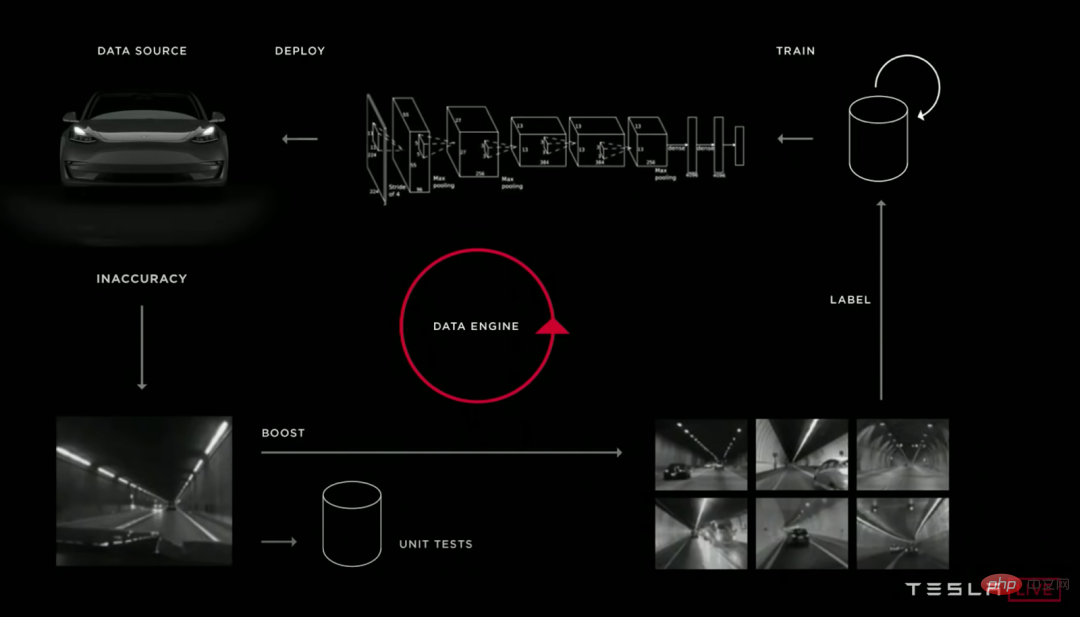
Illustration : De nombreuses équipes d'apprentissage profond de conduite autonome ont des cycles d'itération assez similaires de leurs pipelines de modèles. De haut en bas : Waymo, Cruise et Tesla.
Je pensais que l'apprentissage automatique concernait principalement les modèles. En réalité, l’apprentissage automatique dans la production industrielle relève essentiellement du pipeline. L’un des meilleurs indicateurs de succès est la capacité à itérer efficacement sur le pipeline du modèle. Cela ne signifie pas seulement itérer rapidement, cela signifie itérer intelligemment, et la deuxième partie est critique, sinon votre pipeline produira très rapidement de mauvais modèles.
La plupart des logiciels traditionnels mettent l'accent sur les itérations rapides et les processus de livraison agiles, car les exigences du produit sont inconnues et doivent être découvertes par adaptation, donc au lieu de faire une planification détaillée avec des hypothèses instables au début, il est préférable de livrer un MVP rapidement et itérer.
Tout comme les exigences logicielles traditionnelles sont complexes, le domaine de la saisie de données que les systèmes d'apprentissage automatique doivent gérer est vraiment vaste. Contrairement au développement logiciel normal, la qualité d’un modèle d’apprentissage automatique dépend de sa mise en œuvre dans le code et des données sur lesquelles repose le code. Cette dépendance aux données signifie que le modèle d'apprentissage automatique peut « explorer » le domaine d'entrée via la construction/gestion d'ensembles de données, ce qui lui permet de comprendre les exigences de la tâche et de s'y adapter au fil du temps sans avoir à modifier le code.
Pour profiter de cette fonctionnalité, le machine learning nécessite un concept d'apprentissage continu qui met l'accent sur l'itération des données et du code. Les équipes d'apprentissage automatique doivent :
- Découvrir les problèmes de performances des données ou des modèles
- Diagnostiquer pourquoi les problèmes surviennent
- Modifier le code des données ou des modèles en résoudre ces problèmes
- Vérifier que le modèle s'améliore après le recyclage
- Déployer le nouveau modèle et répéter
L'équipe devrait essayer de traverser ce cycle au moins tous les mois. Si vous êtes bon, faites-le peut-être chaque semaine.
Les grandes entreprises peuvent réaliser un cycle de déploiement de modèle en moins d'une journée, mais pour la plupart des équipes, créer une infrastructure rapidement et automatiquement est très difficile. Si le modèle est mis à jour moins fréquemment, cela peut entraîner une corruption du code (le pipeline du modèle est interrompu en raison de modifications dans la base de code) ou un changement de domaine de données (le modèle en production ne peut pas se généraliser aux modifications des données au fil du temps).
Les grandes entreprises peuvent réaliser un cycle de déploiement de modèle en une journée, mais pour la plupart des équipes, créer une infrastructure rapidement et automatiquement est très difficile. Mettre à jour le modèle moins fréquemment peut entraîner une corruption du code (le pipeline du modèle est interrompu en raison de modifications dans la base de code) ou un changement de domaine de données (le modèle en production ne peut pas se généraliser aux modifications des données au fil du temps).
Cependant, si cela est fait correctement, l'équipe peut prendre un bon rythme pour déployer le modèle amélioré en production.
3 Établir des boucles de rétroaction
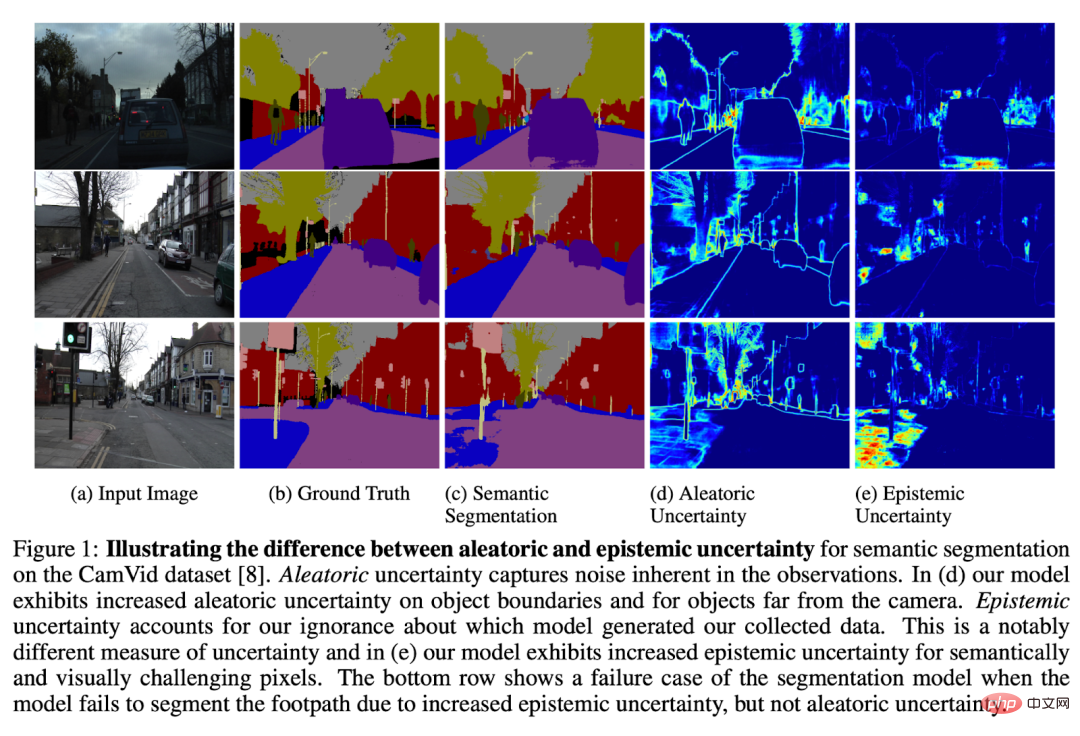
L'incertitude dans le calibrage des modèles est un domaine de recherche passionnant et les modèles peuvent le signaler. Pensez domaines d’échec possibles.
Un élément clé pour itérer efficacement sur un modèle est de se concentrer sur la résolution des problèmes les plus impactants. Pour améliorer un modèle, vous devez savoir ce qui ne va pas et être capable de catégoriser les problèmes en fonction des priorités produit/entreprise. Il existe de nombreuses façons de créer des boucles de rétroaction, mais cela commence par trouver et classer les erreurs.
Profitez des boucles de rétroaction spécifiques au domaine.
Si quoi que ce soit, cela peut être un moyen très puissant et efficace d'obtenir des commentaires sur votre modèle. Par exemple, les tâches de prédiction peuvent obtenir des données étiquetées « gratuitement » en s'entraînant sur des données historiques d'événements réels, ce qui leur permet d'être continuellement alimentées en grandes quantités de nouvelles données et de s'adapter assez automatiquement aux nouvelles situations.
Configurez un flux de travail qui permet aux utilisateurs d'examiner le résultat de votre modèle et de signaler les erreurs lorsqu'elles se produisent.
Cette approche est particulièrement utile lorsque l'on peut facilement détecter les erreurs grâce à de nombreuses inférences de modèle. Cela se produit le plus souvent lorsqu'un client remarque une erreur dans la sortie du modèle et se plaint auprès de l'équipe d'apprentissage automatique. Cela ne peut pas être sous-estimé, car ce canal vous permet d'intégrer les commentaires des clients directement dans le cycle de développement ! Une équipe pourrait demander à des humains de revérifier les sorties du modèle que les clients auraient pu manquer : imaginez un opérateur regardant un robot trier des colis sur un tapis roulant et cliquant sur un bouton lorsqu'il voit une erreur se produire.
Mettez en place un flux de travail qui permet aux utilisateurs d'examiner le résultat de votre modèle et de signaler les erreurs lorsqu'elles se produisent. Ceci est particulièrement approprié lorsque les erreurs dans un grand nombre d’inférences de modèles sont facilement détectées par un examen humain. Le moyen le plus courant est lorsqu'un client remarque une erreur dans la sortie du modèle et se plaint auprès de l'équipe ML. Cela ne doit pas être sous-estimé, car ce canal vous permet d'intégrer les commentaires des clients directement dans le cycle de développement. Une équipe peut demander à des humains d'examiner les résultats du modèle que les clients ont peut-être manqués : pensez à un opérateur qui regarde un robot trier des colis sur un tapis roulant. Cliquez sur un bouton chaque fois qu’ils voient une erreur se produire.
Pensez à configurer une révision automatique lorsque le modèle s'exécute trop fréquemment pour que les humains puissent le vérifier.
Ceci est particulièrement utile lorsqu'il est facile d'écrire des « contrôles d'intégrité » par rapport à la sortie du modèle. Par exemple, signalez chaque fois que le détecteur d'objet lidar et le détecteur d'objet image 2D sont incohérents, ou que le détecteur image par image est incohérent avec le système de suivi temporel. Lorsqu'il fonctionne, il fournit de nombreux commentaires utiles, nous indiquant où se produisent les conditions de défaillance. Lorsque cela ne fonctionne pas, cela expose simplement des bugs dans votre système de vérification ou rate toutes les fois où le système tourne mal, ce qui représente un risque très faible et une récompense élevée.
La solution la plus générale (mais difficile) consiste à analyser l'incertitude du modèle sur les données sur lesquelles il est exécuté.
Un exemple simple consiste à examiner des exemples de modèles produisant des résultats peu fiables en production. Cela peut montrer où le modèle est effectivement incertain, mais n’est pas précis à 100 %. Parfois, un modèle peut se tromper avec certitude. Parfois, les modèles sont indéterminés en raison d’un manque d’informations disponibles pour une bonne inférence (par exemple, des données d’entrée bruyantes difficiles à comprendre pour les humains). Il existe des modèles qui répondent à ces questions, mais il s'agit d'un domaine de recherche actif.
Enfin, les retours du modèle sur l'ensemble d'entraînement peuvent être utilisés.
Par exemple, la vérification des incohérences entre un modèle et son ensemble de données de formation/validation (c'est-à-dire des exemples à pertes élevées) indique des échecs de confiance élevée ou un étiquetage erroné. L'analyse d'intégration du réseau neuronal peut fournir un moyen de comprendre le modèle de modes de défaillance dans l'ensemble de données de formation/validation et peut découvrir des différences dans la distribution des données brutes dans l'ensemble de données de formation et dans l'ensemble de données de production.

Légende : Le temps de la plupart des gens est facilement retiré d'un cycle de recyclage typique. Même si cela se fait au prix d’un temps machine moins efficace, cela élimine beaucoup de tâches manuelles.
Le contenu principal de l'accélération de l'itération est de réduire la quantité de travail requise pour terminer un cycle d'itération. Cependant, il existe toujours des moyens de rendre les choses plus faciles, vous devez donc prioriser ce que vous souhaitez améliorer. J’aime penser à l’effort de deux manières : le temps de l’horloge et le temps humain.
Le temps d'horloge fait référence au temps nécessaire pour exécuter certaines tâches informatiques, telles que l'ETL des données, les modèles de formation, l'exécution de l'inférence, le calcul des métriques, etc. Le temps humain fait référence au temps pendant lequel un humain doit intervenir activement pour parcourir le pipeline, par exemple en vérifiant manuellement les résultats, en exécutant des commandes ou en déclenchant des scripts au milieu du pipeline.
Par exemple, plusieurs scripts doivent être exécutés manuellement dans l'ordre en déplaçant manuellement les fichiers entre les étapes, ce qui est très courant, mais inutile. Quelques calculs sur des serviettes en papier : si un ingénieur en apprentissage automatique coûte 90 $ de l'heure et perd 2 heures par semaine à exécuter des scripts à la main, cela représente 9 360 $ par personne et par an !
La combinaison de plusieurs scripts et interruptions humaines en un seul script entièrement automatisé rend l'exécution d'une boucle de pipeline de modèle plus rapide et plus facile, ce qui permet d'économiser des tonnes d'argent et de rendre vos ingénieurs en apprentissage automatique moins bizarres.
En revanche, l'heure doit généralement être « raisonnable » (par exemple, elle peut être effectuée pendant la nuit). Les seules exceptions sont si les ingénieurs en apprentissage automatique mènent des expériences approfondies ou s'il existe des contraintes extrêmes de coût/d'échelle. En effet, le temps d'horloge est généralement proportionnel à la taille des données et à la complexité du modèle. Lors du passage du traitement local au traitement cloud distribué, le temps d'horloge est considérablement réduit. Après cela, la mise à l’échelle horizontale dans le cloud a tendance à résoudre la plupart des problèmes de la plupart des équipes jusqu’à ce que le problème prenne de l’ampleur.
Malheureusement, il n'est pas possible d'automatiser complètement certaines tâches. Presque toutes les applications d’apprentissage automatique en production sont des tâches d’apprentissage supervisé et la plupart reposent sur une certaine quantité d’interaction humaine pour indiquer au modèle ce qu’il doit faire. Dans certains domaines, l'interaction homme-machine est gratuite (par exemple, cas d'utilisation de recommandations sur les réseaux sociaux ou d'autres applications avec de grandes quantités de commentaires directs des utilisateurs). Dans d’autres cas, le temps humain est plus limité ou plus coûteux, comme lorsque des radiologues qualifiés « étiquetent » les tomodensitogrammes pour les données de formation.
Quoi qu’il en soit, il est important de minimiser le temps de main-d’œuvre et les autres coûts nécessaires pour améliorer le modèle. Même si les premières équipes peuvent s'appuyer sur des ingénieurs en apprentissage automatique pour gérer les ensembles de données, il est souvent plus économique (ou, dans le cas des radiologues, nécessaire) de confier le gros du travail de gestion des données à un utilisateur opérationnel ou à un expert du domaine sans connaissances en apprentissage automatique. À ce stade, il devient important d'établir un processus opérationnel pour étiqueter, inspecter, améliorer et versionner les ensembles de données à l'aide de bons outils logiciels.
5 Encouragez les ingénieurs ML à se mettre en forme

Illustration : Lorsque les ingénieurs ML soulèvent des poids, ils augmentent également le poids de leur apprentissage de modèles
Créer suffisamment d'outils pour prendre en charge un nouveau domaine ou un nouveau groupe d'utilisateurs peut prendre beaucoup de temps et d'efforts, mais si c'est bien fait, les résultats en vaudront la peine. Un de mes ingénieurs chez Cruise était particulièrement intelligent (certains diraient paresseux).
L'ingénieur a établi une boucle itérative dans laquelle une combinaison de retours opérationnels et de requêtes de métadonnées extrairait les données pour l'étiquetage là où les performances du modèle étaient médiocres. Une équipe d'opérations offshore étiquetera ensuite les données et les ajoutera à une nouvelle version de l'ensemble de données de formation. Après cela, les ingénieurs ont mis en place une infrastructure qui leur a permis d'exécuter un script sur leur ordinateur et de lancer une série de tâches cloud pour recycler et valider automatiquement un modèle simple sur les données nouvellement ajoutées.
Chaque semaine, ils exécutent le script de recyclage. Puis, pendant que le modèle s'entraînait et se validait, ils se rendirent au gymnase. Après quelques heures de remise en forme et de dîner, ils revenaient vérifier les résultats. Par coïncidence, des données nouvelles et améliorées entraîneront des améliorations du modèle, et après une double vérification rapide pour s'assurer que tout a du sens, ils expédieront ensuite le nouveau modèle en production et la maniabilité de la voiture s'améliorera. Ils ont ensuite passé une semaine à améliorer l'infrastructure, à expérimenter de nouvelles architectures de modèles et à construire de nouveaux pipelines de modèles. Non seulement cet ingénieur a obtenu une promotion à la fin du trimestre, mais il était en pleine forme.
6 Conclusion
Pour résumer : Lors des phases de recherche et de développement d'un prototype, l'accent est mis sur la construction et la publication d'un modèle. Cependant, à mesure qu'un système entre en production, la tâche principale est de construire un système capable de publier régulièrement des modèles améliorés avec un minimum d'effort. Mieux vous y arriverez, plus vous pourrez construire de modèles !
Pour ce faire, nous devons nous concentrer sur les éléments suivants :
- Exécuter le pipeline de modèles à une cadence régulière et nous concentrer sur l'amélioration du modèle d'expédition qu'avant . Mettez en production un nouveau modèle amélioré chaque semaine ou moins !
- Établissez une bonne boucle de rétroaction depuis la sortie du modèle jusqu'au processus de développement. Découvrez quels exemples le modèle fonctionne mal et ajoutez d'autres exemples à votre ensemble de données d'entraînement.
- Automatisez les tâches particulièrement lourdes de votre pipeline et établissez une structure d'équipe qui permet aux membres de votre équipe de se concentrer sur leurs domaines d'expertise. Andrej Karpathy, de Tesla, appelle l'état final idéal « Opération Vacances ». Je suggère de mettre en place un flux de travail dans lequel vos ingénieurs en apprentissage automatique se rendent à la salle de sport et de laisser votre pipeline d'apprentissage automatique faire le gros du travail !
Enfin, je dois souligner que d'après mon expérience, la plupart des problèmes liés aux performances du modèle peuvent être résolus avec des données, mais certains problèmes ne peuvent être résolus qu'en modifiant le code du modèle.
Ces changements sont souvent très spécifiques à l'architecture du modèle en question, par exemple, après avoir travaillé sur un détecteur d'objet image pendant plusieurs années, j'ai passé trop de temps à me soucier de la meilleure affectation de boîte précédente pour certains azimuts rapport et résolution améliorée de la carte des caractéristiques pour les petits objets.
Cependant, comme Transformers se montre prometteur en devenant un type d'architecture de modèle universel pour de nombreuses tâches différentes d'apprentissage en profondeur, je soupçonne qu'un plus grand nombre de ces techniques deviendront moins pertinentes et que l'accent du développement de l'apprentissage automatique se concentrera davantage sur améliorer l'ensemble de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI