
Maison >Périphériques technologiques >IA >Papier de score parfait VPR 2024 ! Meta propose EfficientSAM : divisez tout rapidement !
Papier de score parfait VPR 2024 ! Meta propose EfficientSAM : divisez tout rapidement !

- 王林avant
- 2024-03-02 10:10:021426parcourir
EfficientSAM Ce travail a été inclus dans le CVPR 2024 avec une note parfaite de 5/5/5 ! L'auteur a partagé le résultat sur les réseaux sociaux, comme le montre l'image ci-dessous :
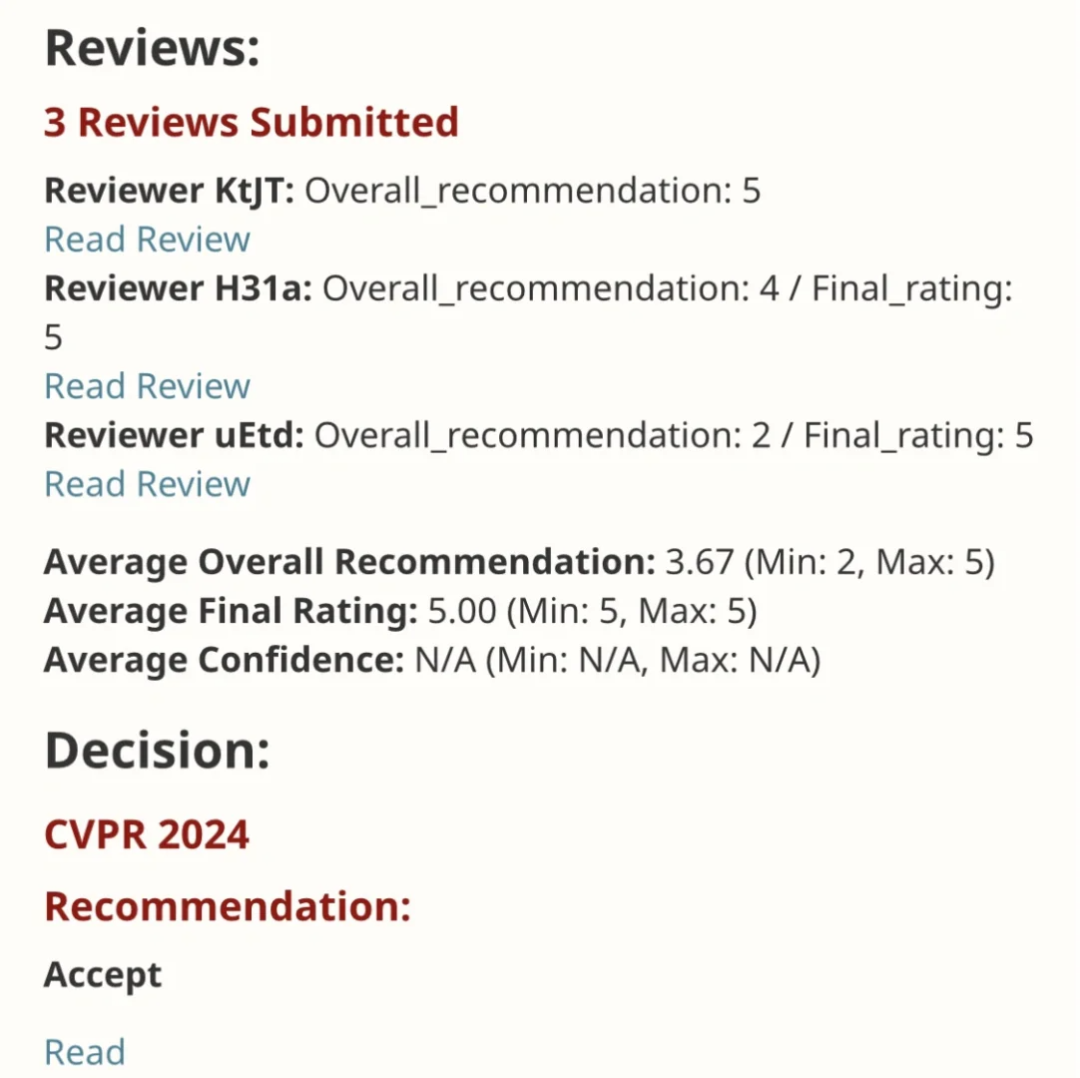
Le lauréat du prix LeCun Turing a également fortement recommandé ce travail !

Dans des recherches récentes, des chercheurs de Meta ont proposé une nouvelle méthode améliorée, le pré-entraînement par image masquée utilisant SAM (SAMI). Cette approche combine des techniques de pré-formation MAE et des modèles SAM pour obtenir des encodeurs ViT pré-entraînés de haute qualité. Grâce à SAMI, les chercheurs tentent d'améliorer les performances et l'efficacité du modèle et de proposer de meilleures solutions pour les tâches de vision. La proposition de cette méthode apporte de nouvelles idées et opportunités pour explorer et développer davantage les domaines de la vision par ordinateur et de l’apprentissage profond. En combinant différentes techniques de pré-formation et structures modèles, les chercheurs continuent de

- Lien papier : https://arxiv.org/pdf/2312.00863
- Code : github.com/yformer/EfficientSAM
- Page d'accueil : https://yformer.github.io/efficient-sam/
Cette approche réduit la complexité du SAM tout en conservant de bonnes performances. Plus précisément, SAMI utilise l'encodeur SAM ViT-H pour générer des intégrations de fonctionnalités et entraîne un modèle d'image de masque avec un encodeur léger, reconstruisant ainsi les fonctionnalités du ViT-H de SAM au lieu des correctifs d'image, et l'épine dorsale universelle ViT résultante peut être utilisée en aval. comme la classification d'images, la détection et la segmentation d'objets, etc. Nous utilisons ensuite le décodeur SAM pour affiner l'encodeur léger pré-entraîné afin d'effectuer toute tâche de segmentation.
Pour vérifier l'efficacité de cette méthode, les chercheurs ont utilisé un cadre d'apprentissage par transfert pré-entraîné sur des images masquées. Plus précisément, ils ont d’abord pré-entraîné le modèle avec perte de reconstruction sur l’ensemble de données ImageNet avec une résolution d’image de 224 × 224. Ils affinent ensuite le modèle à l’aide des données supervisées de la tâche cible. Cette méthode d'apprentissage par transfert peut aider le modèle à apprendre rapidement et à améliorer les performances sur de nouvelles tâches, car le modèle a appris à extraire des fonctionnalités des données d'origine tout au long de la phase de pré-formation. Cette stratégie d'apprentissage par transfert utilise efficacement les connaissances acquises sur des ensembles de données à grande échelle, ce qui facilite l'adaptation du modèle à différentes tâches. Dans le même temps, grâce à la pré-formation SAMI, ViT-Tiny/- peut être formé sur ImageNet-1K Small. /-Base et autres modèles, et améliorer les performances de généralisation. Pour le modèle ViT-Small, après 100 réglages précis sur ImageNet-1K, les chercheurs ont atteint une précision Top-1 de 82,7 %, ce qui est meilleur que les autres références de pré-entraînement d'images de pointe.
Les chercheurs ont affiné le modèle pré-entraîné sur la détection de cibles, la segmentation d'instance et la segmentation sémantique. Dans toutes ces tâches, notre méthode obtient de meilleurs résultats que les autres bases de référence pré-entraînées et, plus important encore, réalise des gains significatifs sur de petits modèles.
Yunyang Xiong, l'auteur de l'article, a déclaré : Les paramètres EfficientSAM proposés dans cet article sont réduits de 20 fois, mais le temps d'exécution est 20 fois plus rapide. La différence avec le modèle SAM d'origine n'est que de 2 points de pourcentage. , ce qui est bien meilleur que MobileSAM/FastSAM.
Dans la démo, cliquez sur l'animal dans l'image, et EfficientSAM peut rapidement segmenter l'objet : 
EfficientSAM peut également identifier avec précision les personnes dans l'image : 
Adresse d'essai : https://ab348ea7942fe2af48.gradio.live/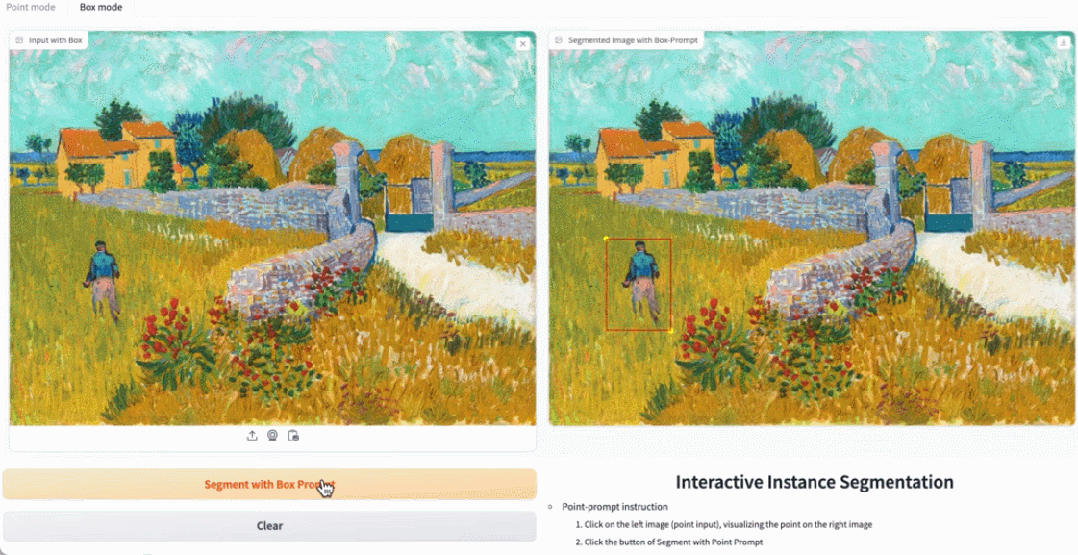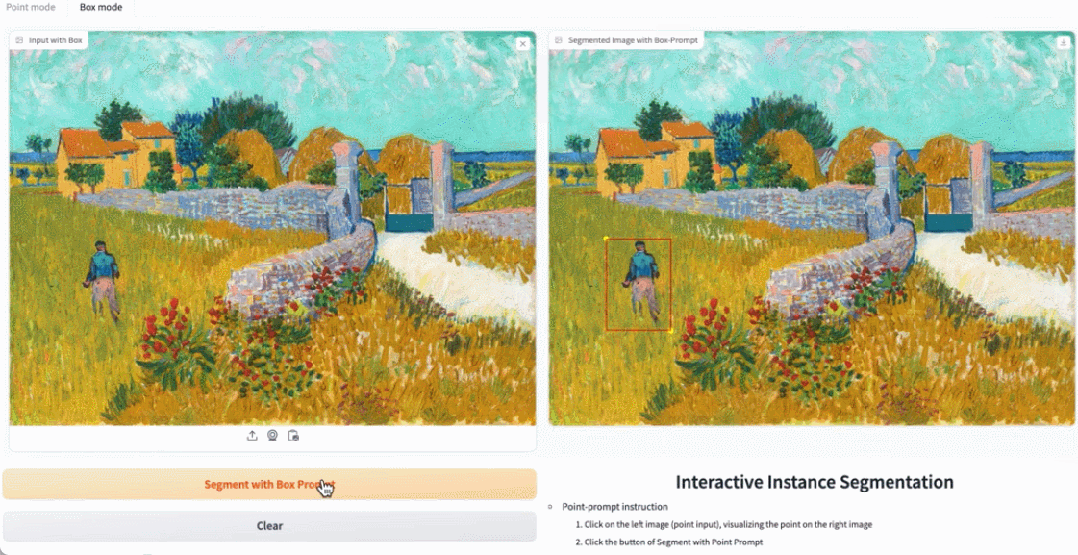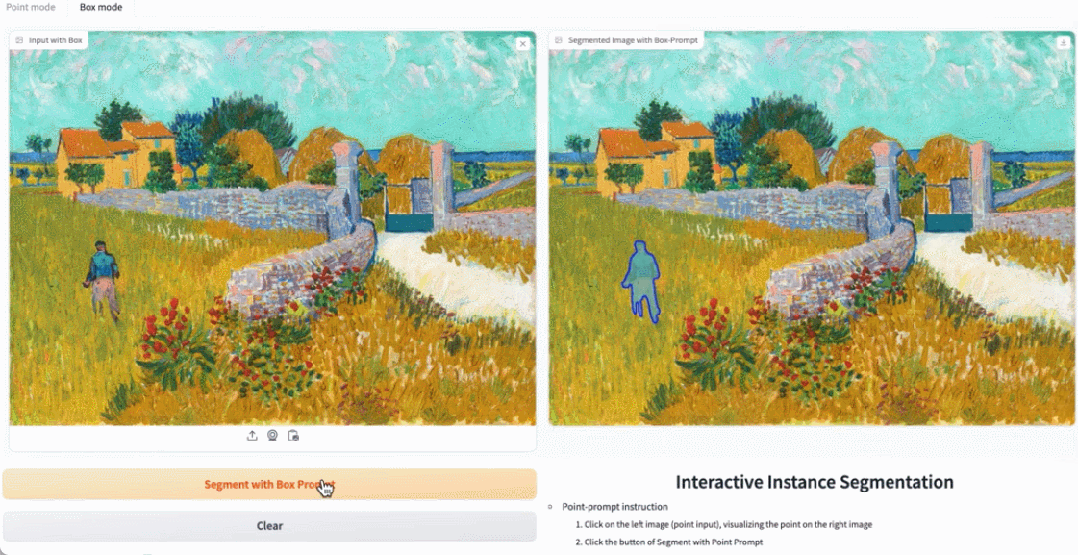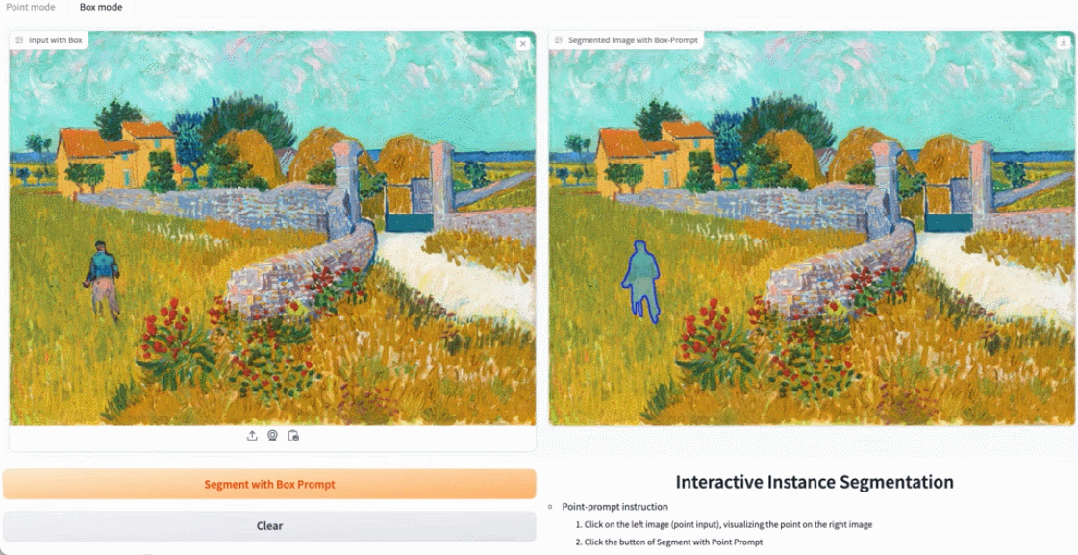
Method
EfficientSAM contient deux étapes : 1) pré-formation SAMI sur ImageNet (Partie 1) SA-1B réglage fin ; le SAM (en bas).
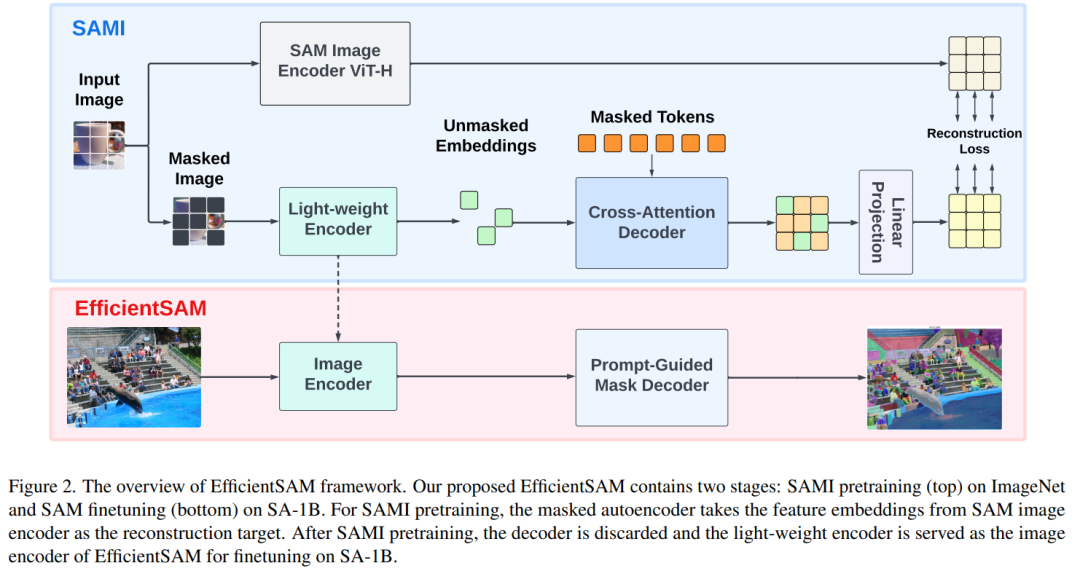
EfficientSAM contient principalement les composants suivants :
Décodeur d'attention croisée : sous la supervision des fonctionnalités de SAM, cet article observe que seul le jeton de masque doit être reconstruit par le décodeur, tandis que la sortie de l'encodeur peuvent être reconstruits au cours du processus de reconstruction et servent de points d’ancrage. Dans le décodeur d'attention croisée, la requête provient des jetons masqués, et les clés et valeurs sont dérivées des fonctionnalités non masquées et des fonctionnalités masquées de l'encodeur. Cet article fusionne les caractéristiques de sortie des jetons masqués du décodeur d'attention croisée et les caractéristiques de sortie des jetons non masqués de l'encodeur pour l'intégration de la sortie MAE. Ces fonctionnalités combinées seront ensuite réorganisées aux positions d'origine des jetons d'image d'entrée dans la sortie MAE finale.
Tête de projection linéaire. Nous avons ensuite introduit les sorties d'image obtenues via l'encodeur et le décodeur d'attention croisée dans une petite tête de projet pour aligner les fonctionnalités de l'encodeur d'image SAM. Par souci de simplicité, cet article utilise uniquement une tête de projection linéaire pour résoudre l'inadéquation des dimensions des caractéristiques entre l'encodeur d'image SAM et la sortie MAE.
Reconstruire les pertes. Dans chaque itération de formation, SAMI inclut l'extraction de caractéristiques directes à partir de l'encodeur d'image SAM et les processus de propagation avant et arrière du MAE. Les sorties du codeur d'image SAM et de la tête de projection linéaire MAE sont comparées pour calculer la perte de reconstruction.
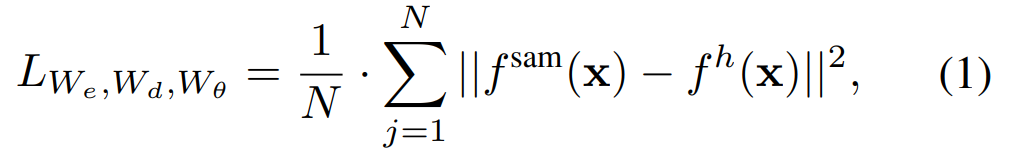
Après la pré-formation, l'encodeur peut extraire des représentations de fonctionnalités pour diverses tâches visuelles, et le décodeur sera également supprimé. En particulier, afin de créer un modèle SAM efficace pour toute tâche de segmentation, cet article adopte des encodeurs légers pré-entraînés SAMI (tels que ViT-Tiny et ViT-Small) comme encodeur d'image d'EfficientSAM et décodeur de masque par défaut de SAM. , comme le montre la figure 2 (en bas). Cet article affine le modèle EfficientSAM sur l'ensemble de données SA-1B pour réaliser la segmentation de n'importe quelle tâche.
Expérience
Classification des images. Afin d'évaluer l'efficacité de cette méthode sur les tâches de classification d'images, les chercheurs ont appliqué les idées SAMI au modèle ViT et comparé leurs performances sur ImageNet-1K.
Comme le montre le tableau 1, SAMI est comparé aux méthodes de pré-formation telles que MAE, iBOT, CAE et BEiT, et aux méthodes de distillation telles que DeiT et SSTA.
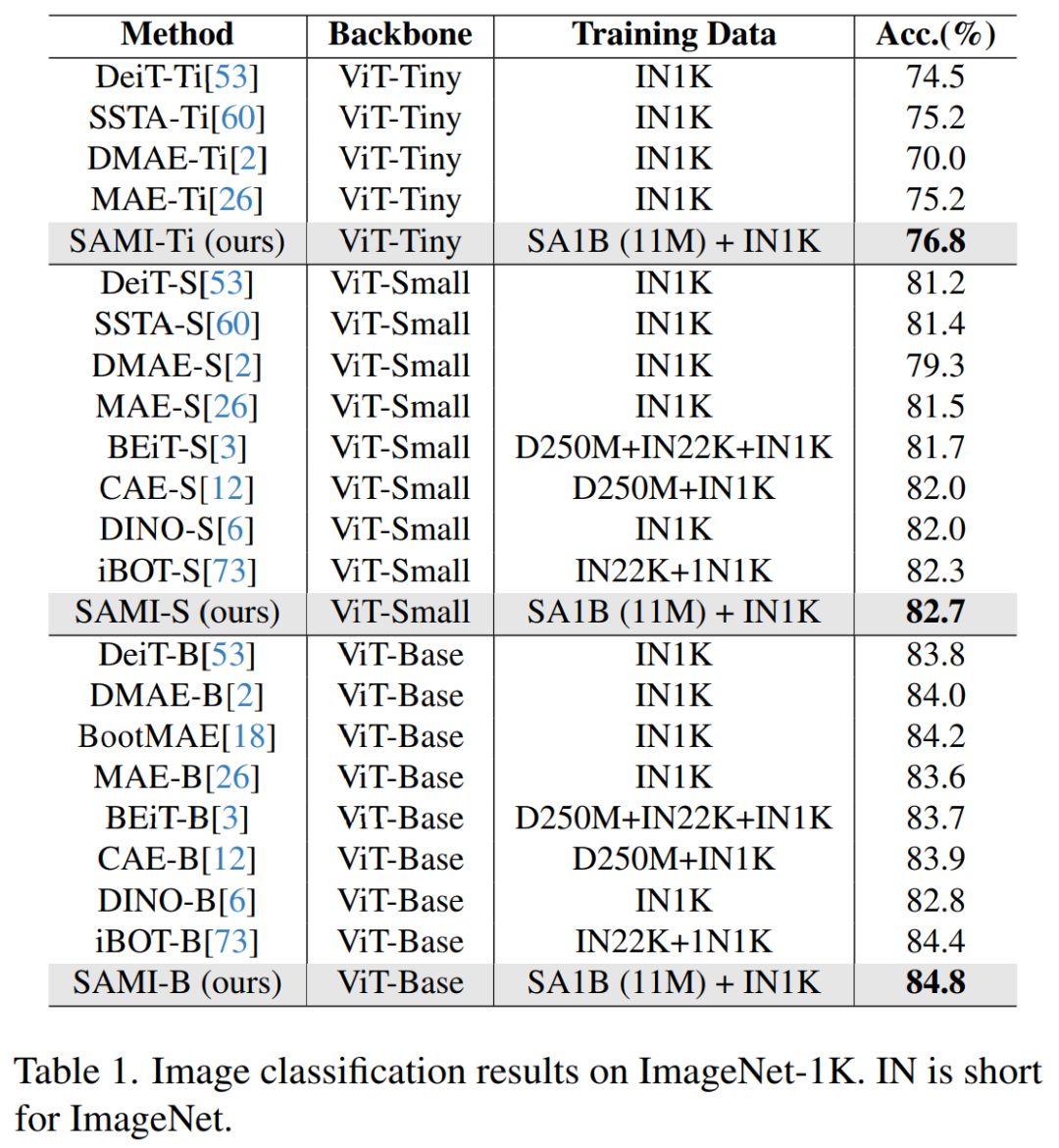
La précision top1 de SAMI-B atteint 84,8 %, ce qui est supérieur à la ligne de base pré-entraînée, MAE, DMAE, iBOT, CAE et BEiT. SAMI présente également de grandes améliorations par rapport aux méthodes de distillation telles que DeiT et SSTA. Pour les modèles légers tels que ViT-Tiny et ViT-Small, les résultats SAMI montrent des gains significatifs par rapport à DeiT, SSTA, DMAE et MAE.
Détection d'objets et segmentation d'instances. Cet article étend également le squelette ViT pré-entraîné par SAMI aux tâches de détection d'objets et de segmentation d'instance en aval et le compare à une ligne de base pré-entraînée sur l'ensemble de données COCO. Comme le montre le tableau 2, SAMI surpasse systématiquement les performances des autres références.
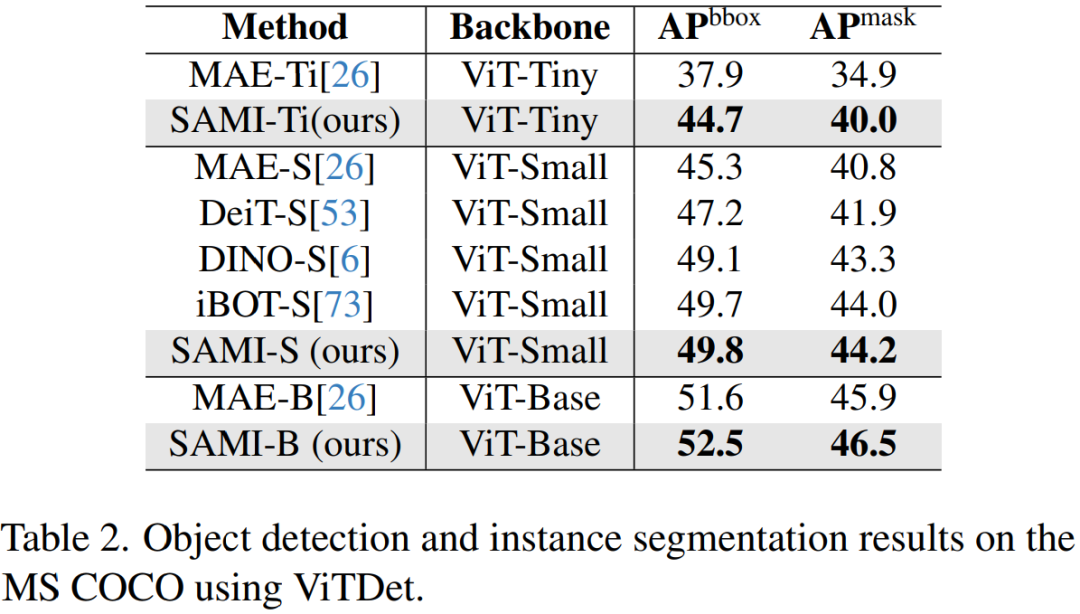
Ces résultats expérimentaux montrent que le squelette de détecteur pré-entraîné fourni par SAMI est très efficace dans les tâches de détection d'objets et de segmentation d'instances.
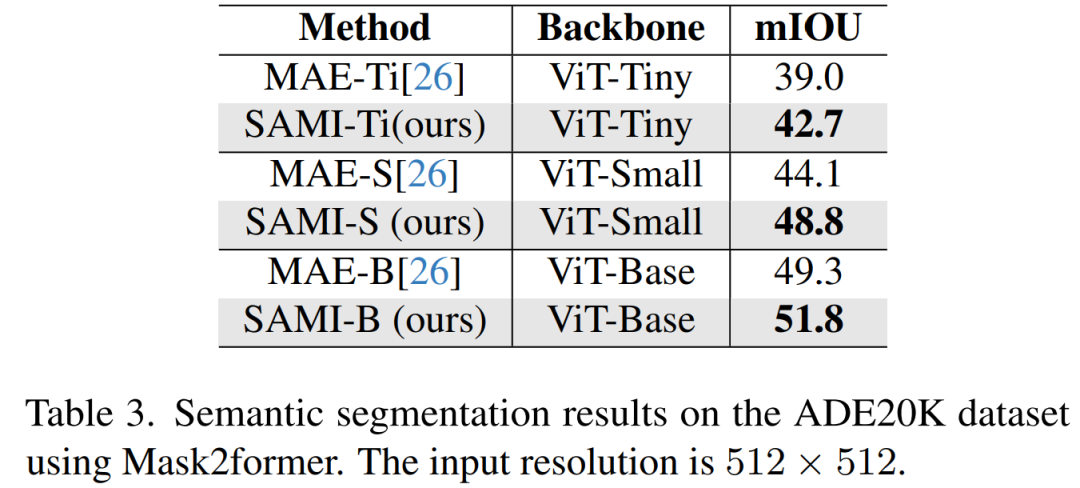
Segmentation sémantique. Cet article étend davantage l'épine dorsale pré-entraînée aux tâches de segmentation sémantique pour évaluer son efficacité. Les résultats sont présentés dans le tableau 3. Mask2former utilisant le backbone pré-entraîné SAMI permet d'obtenir un meilleur mIoU sur ImageNet-1K que l'utilisation du backbone pré-entraîné MAE. Ces résultats expérimentaux vérifient que la technologie proposée dans cet article peut bien se généraliser à diverses tâches en aval.
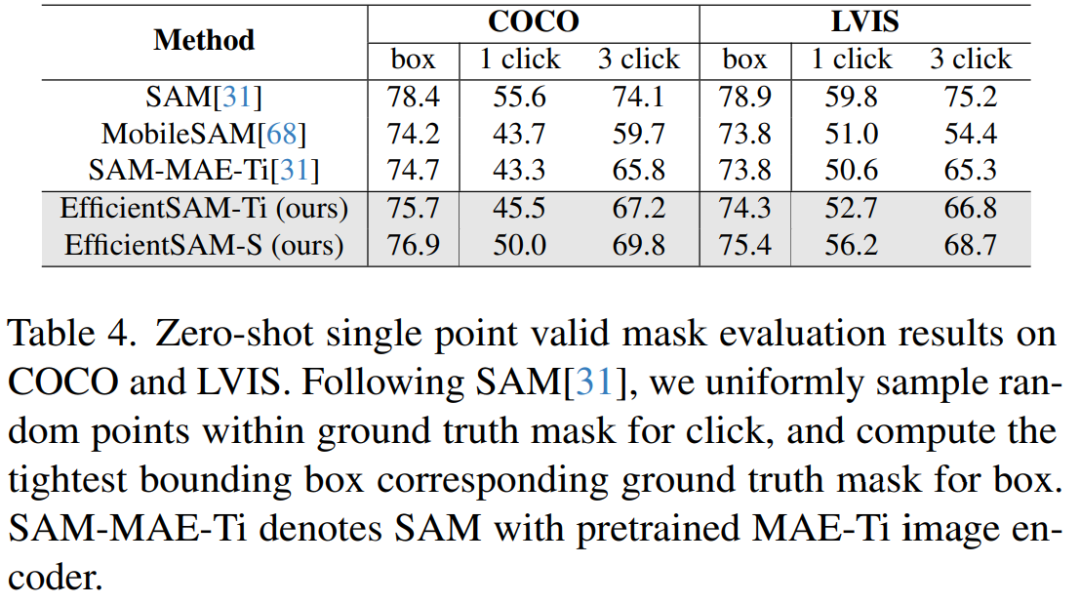
Le tableau 4 compare les EfficientSAM avec SAM, MobileSAM et SAM-MAE-Ti. Sur COCO, EfficientSAM-Ti surpasse MobileSAM. EfficientSAM-Ti est doté de poids pré-entraînés SAMI et fonctionne également mieux que les poids pré-entraînés MAE.
De plus, EfficientSAM-S est seulement 1,5 mIoU inférieur à SAM sur la box COCO et 3,5 mIoU inférieure à SAM sur la box LVIS, avec 20 fois moins de paramètres. Cet article a également révélé qu'EfficientSAM affichait également de bonnes performances en plusieurs clics par rapport à MobileSAM et SAM-MAE-Ti.
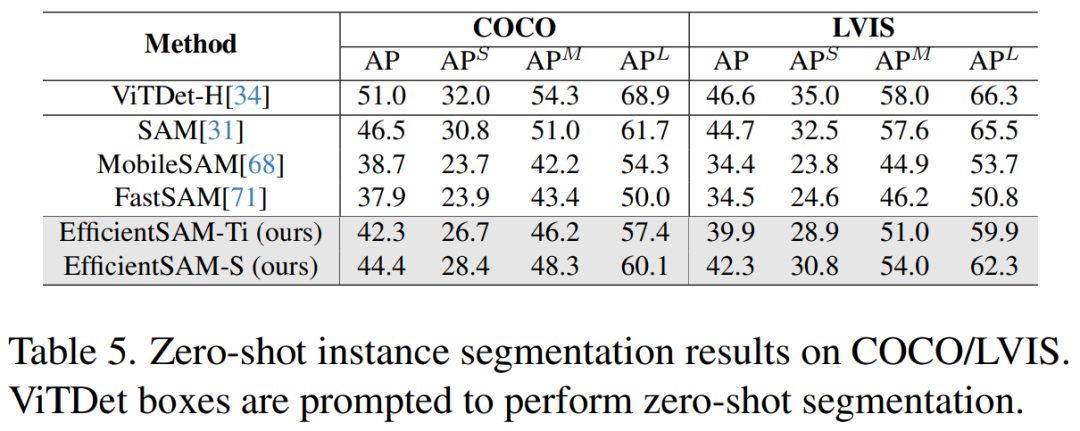
Le tableau 5 montre les AP, APS, APM et APL de la segmentation des instances sans tir. Les chercheurs ont comparé EfficientSAM avec MobileSAM et FastSAM, et on peut constater que par rapport à FastSAM, EfficientSAM-S a gagné plus de 6,5 AP sur COCO et 7,8 AP sur LVIS. Dans le cas d'EffidientSAM-Ti, il est toujours nettement meilleur que FastSAM, avec 4,1 AP sur COCO et 5,3 AP sur LVIS, tandis que MobileSAM a 3,6 AP sur COCO et 5,5 AP sur LVIS.
De plus, EfficientSAM est beaucoup plus léger que FastSAM, les paramètres d'efficaceSAM-Ti sont de 9,8M, tandis que les paramètres de FastSAM sont de 68M.
Les figures 3, 4 et 5 fournissent des résultats qualitatifs afin que les lecteurs puissent avoir une compréhension supplémentaire des capacités de segmentation d'instance d'EfficientSAM.



Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Pourquoi rechercher des mots-clés ?
- Méthodes de recherche et de réparation des failles de sécurité internes dans le framework Vue
- Recherche sur la psychologie des attaques de pirates de réseau
- Utilisez la vision pour inciter ! Shen Xiangyang a présenté le nouveau modèle de l'Institut de recherche IDEA, qui ne nécessite aucune formation ni réglage précis et peut être utilisé directement.