
Maison >Périphériques technologiques >IA >La technologie de redessinage partiel Meitu AI révélée ! Changez-le comme vous le souhaitez ! Le redessinage partiel de belles images vous permet de faire ce que vous voulez
La technologie de redessinage partiel Meitu AI révélée ! Changez-le comme vous le souhaitez ! Le redessinage partiel de belles images vous permet de faire ce que vous voulez

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-02 09:55:561575parcourir
Récemment, la fonction « AI Image Enlargement » a fait sensation avec son effet d'agrandissement soudain. Ses résultats de remplissage automatique amusants et intéressants sont souvent devenus populaires et ont déclenché un engouement sur Internet. Les utilisateurs ont activement essayé cette fonctionnalité, et son énorme transformation à 180 degrés a également émerveillé les gens, et la popularité du sujet a continué d'augmenter.
Tout en suscitant le rire et l'enthousiasme, cela signifie également que les gens sont constamment attentifs à savoir si l'IA peut vraiment les aider à résoudre des problèmes du monde réel et à améliorer l'expérience utilisateur. Avec le développement rapide de la technologie AIGC, la mise en œuvre des scénarios d’application de l’IA s’accélère, ce qui indique que nous allons inaugurer une nouvelle révolution de la productivité.
Récemment, WHEE de Meitu et d'autres produits ont lancé des fonctions d'agrandissement d'image AI et de modification d'image AI. Avec une simple saisie rapide, les utilisateurs peuvent modifier les images, supprimer des éléments de l'écran et agrandir l'écran à volonté. Avec des opérations pratiques et un superbe effet réduit. le seuil d'utilisation des outils et offre aux utilisateurs une expérience de création d'images efficace et de haute qualité.
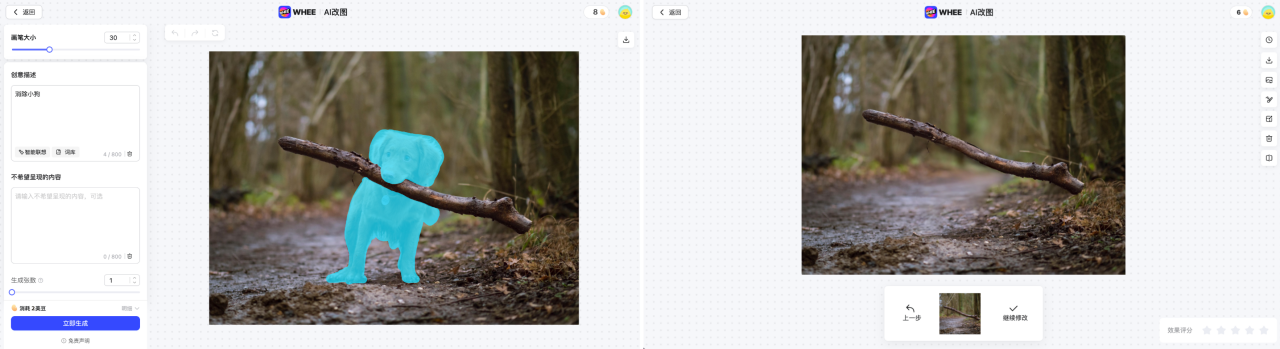
MiracleVision (MiracleVision) élimine le résultat
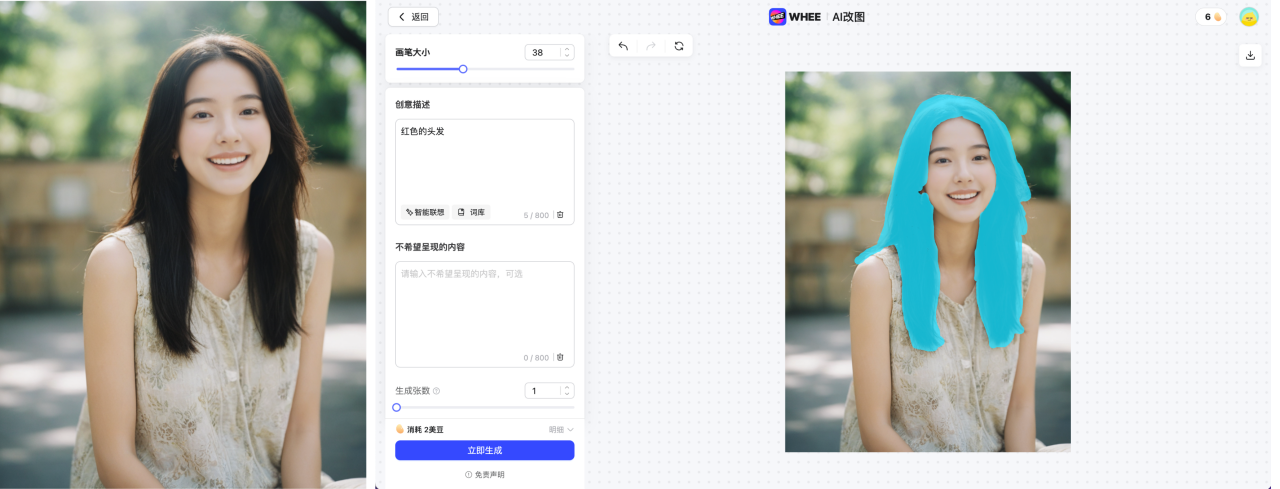
MiracleVision (MiracleVision) avant l'effet de remplacement
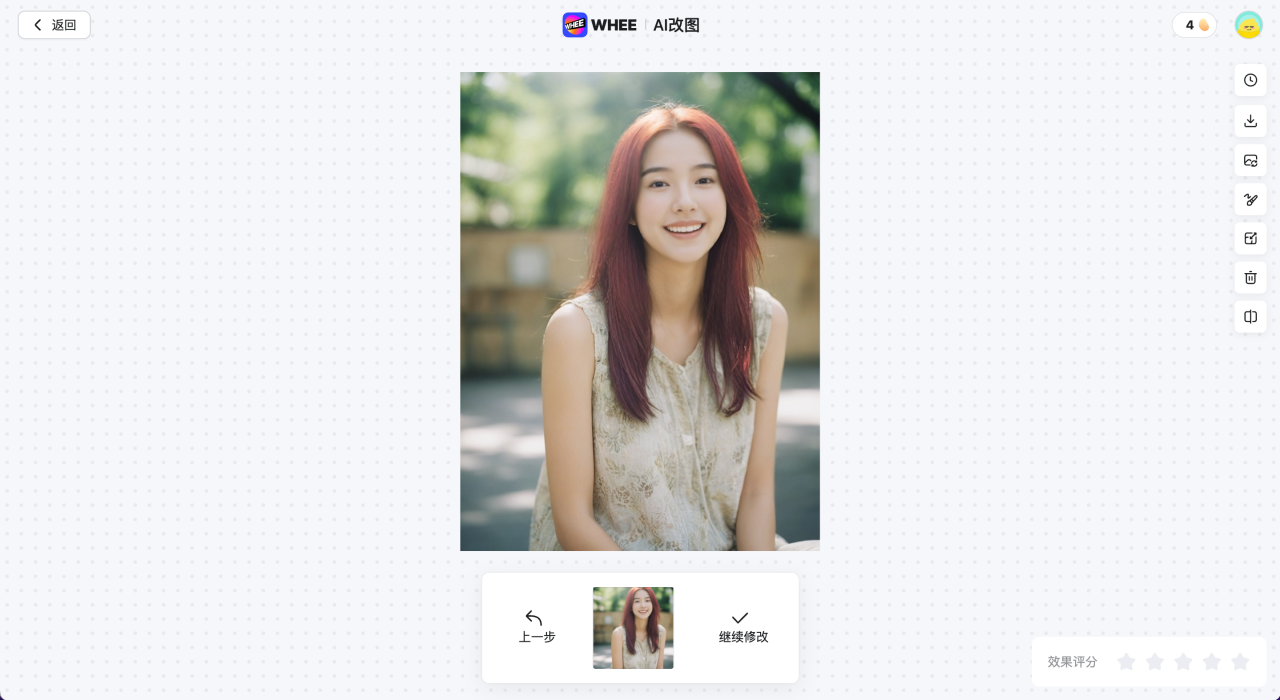
MiracleVision (MiracleVision) après l'effet de remplacement 
Miracle Vision AI modification Effets d'image
De puissantes capacités de modèle vous permettent d'éditer des images à votre guise
Le modèle de redessin local Meitu AI crée un cadre complet de modèle d'inpaint et d'outpaint basé sur la technologie de modèle de diffusion pour redessiner les zones internes et éliminer les cibles de premier plan. L'expansion de la zone externe et d'autres tâches sont unifiés dans la même solution à résoudre, et des conceptions d'optimisation spéciales sont élaborées pour certains problèmes d'effets spécifiques.
Le modèle MiracleVision est un modèle de graphique vincentien. Bien qu'il puisse être adapté à la tâche d'inpaint en transformant la première couche de convolution et en affinant l'ensemble d'unet, cela nécessite de modifier les poids d'origine d'unet dans les données d'entraînement. entraîner une baisse des performances du modèle.
Par conséquent, afin d'utiliser pleinement les capacités de génération existantes de MiracleVision, l'équipe n'affine pas directement le modèle unet de MiracleVision dans le modèle de redessin partiel, mais utilise la méthode controlnet pour ajouter une branche d'entrée de masque Take. contrôle.
Dans le même temps, afin de réduire les coûts de formation et d'accélérer l'inférence, le module controlnet compressé est utilisé pour la formation afin de réduire autant que possible la quantité de calcul. Au cours du processus de formation, les paramètres du modèle unet seront corrigés et seul le module controlnet sera mis à jour, permettant éventuellement à l'ensemble du modèle d'acquérir la capacité d'inpainting.
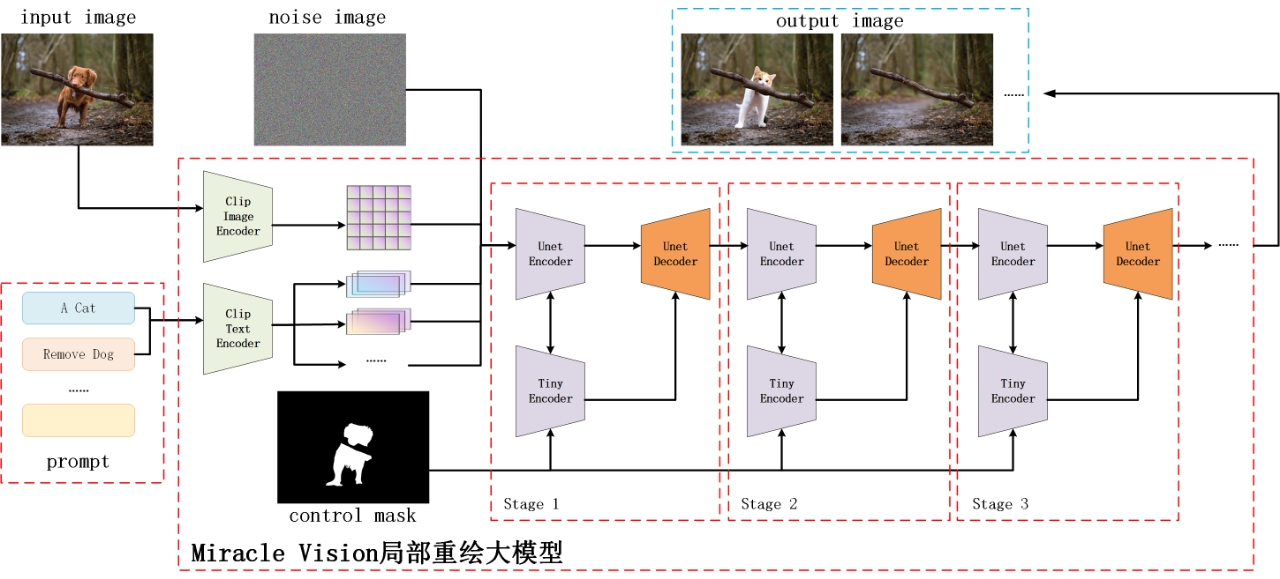
Meitu AI redessine partiellement le diagramme d'architecture du modèle
la tâche d'outpaint est l'opération inverse de la tâche de recadrage. La tâche de recadrage consiste à recadrer l'image originale le long de la limite de l'image, en ne conservant que la partie requise, qui est une opération de soustraction du contenu de l'image, tandis que la tâche externe consiste à s'étendre vers l'extérieur le long de la limite de l'image, en utilisant la capacité de génération du modèle ; créer à partir de rien Extraire un contenu qui n'existe pas à l'origine est une opération supplémentaire du contenu de l'image.
Essentiellement, la tâche d'outpaint peut également être considérée comme une tâche spéciale d'inpaint, sauf que la zone de masque est située à la périphérie de l'image.


Effet d'expansion de l'image MiracleVision AI
Étant donné que la zone de masque dans la tâche de peinture ne peut obtenir des informations de guidage que de l'intérieur de l'image, les autres directions sont des limites de l'image, le contenu généré est donc plus unique. Le hasard sera plus divergent. Afin de remplir les zones vides à la périphérie de l'image et d'assurer la précision de l'expansion de l'image, l'équipe s'est appuyée sur des algorithmes de reconnaissance de scène pour déduire le style et le contenu de l'image, et a pleinement utilisé la corrélation du contenu de l'image pour copier les pixels de l'image originale en les reflétant sur les bords élargis. Et superposez un bruit aléatoire pour fournir un a priori initial approprié pour le modèle, garantissant ainsi la rationalité du contenu généré et rendant la transition des limites plus fluide.
Contrôlez librement la génération et l'élimination d'objets grâce à une variété de stratégies d'entraînement
Les modèles de diffusion générale sont plus efficaces pour remplacer que pour éliminer lors de l'exécution de tâches de peinture. Lorsqu'une certaine cible doit être éliminée, le modèle peut facilement dessiner de nouvelles cibles de premier plan dans la zone du masque qui n'existent pas à l'origine, en particulier lorsque la zone de la zone du masque est grande. Ce phénomène est particulièrement évident lorsque la cible est relativement grande, même si ces cibles n'apparaissent pas dans l'invite. Les raisons proviennent principalement des trois aspects suivants :
1. Les invites de l'ensemble de formation décrivent généralement uniquement ce qui est dans l'image, mais pas ce qui n'est pas dans l'image. Par conséquent, le modèle entraîné est autorisé à générer une certaine image. en fonction des invites, le ciblage est facile, mais il est difficile de ne pas le laisser générer des cibles. Même avec la stratégie de guidage sans classificateur, la génération de cette cible peut être supprimée en ajoutant des objets indésirables aux mots négatifs, mais il n'est jamais possible d'écrire toutes les cibles possibles dans des mots négatifs, le modèle aura donc toujours tendance à générer des cibles inattendues.
2. D'après la distribution des données d'entraînement, étant donné que la plupart des images de l'ensemble d'entraînement d'images à grande échelle sont composées d'images de premier plan et d'arrière-plan, la proportion d'images d'arrière-plan pures est relativement faible. a appris une règle potentielle pendant la formation, c'est-à-dire qu'il existe une forte probabilité qu'un certain premier plan cible soit présent dans une image (même si elle n'est pas mentionnée dans l'invite), ce qui entraîne également l'échec du modèle lors de l'exécution de la tâche de peinture. plus enclin à générer quelque chose dans la zone du masque, afin que l'image de sortie soit plus proche de la distribution lors de l'entraînement
3 La forme de la zone du masque à remplir contient parfois aussi certaines informations sémantiques, comme lorsqu'il n'y en a pas d'autre ; Dans cette condition, le modèle sera plus enclin à remplir un nouveau chat dans une zone de masque avec la forme d'un chat, provoquant l'échec de la tâche d'élimination.
Afin de rendre MiracleVision capable à la fois de génération et d'élimination de cibles, l'équipe a adopté une stratégie d'entraînement multitâche :
1 Dans la phase d'entraînement, lorsque la zone du masque tombe sur une zone de fond pure avec moins de texture, ajoutez. un mot-clé d'invite spécifique comme mot guide de déclenchement, et lors de l'étape d'inférence du modèle, ajoutez ce mot-clé comme mot guide avant à l'intégration de l'invite, invitant le modèle à générer davantage de zones d'arrière-plan.
2. Étant donné que les images d'arrière-plan pures représentent une proportion relativement faible dans l'ensemble de la formation, afin d'augmenter sa contribution à la formation, dans chaque lot de formation, une certaine proportion d'images d'arrière-plan est échantillonnée manuellement et ajoutée à la formation, donc que les images d'arrière-plan sont incluses dans les échantillons d'apprentissage. La proportion globale reste stable.
3. Afin de réduire la dépendance sémantique du modèle à la forme du masque, divers masques de formes différentes seront générés aléatoirement pendant la phase d'entraînement pour augmenter la diversité des formes de masques.
Génération de texture haute précision, fusion plus naturelle
Étant donné que les données de texture haute définition dans l'ensemble d'entraînement ne représentent qu'une petite partie des données d'entraînement totales, lors de l'exécution de la tâche d'inpaint, des résultats très riches en textures sont généralement pas généré, ce qui donne lieu à des scènes originales avec des textures d'image riches, il est facile d'avoir une fusion non naturelle et un sentiment de frontière.
Afin de résoudre ce problème, l'équipe a utilisé le modèle de détail de texture auto-développé comme modèle guide pour aider MiracleVision à améliorer la qualité de la génération, à supprimer le surajustement et à établir la relation entre la zone générée et d'autres zones de la l'image originale s'emboîte mieux.

Image originale vs. sans ajouter de détails de texture vs.sEffet d'agrandissement de l'image MiracleVision
Plus rapide, meilleur effet, interaction plus efficace !
Les solutions de modèles de diffusion nécessitent généralement un processus de diffusion inverse en plusieurs étapes pendant l'inférence, ce qui rend le traitement d'une seule image trop long. Afin d'optimiser l'expérience utilisateur tout en maintenant la qualité de la génération, l'équipe du Meitu Imaging Research Institute (MT Lab) a créé une solution de réglage spéciale pour la technologie de redessinage partiel de l'IA, obtenant finalement le meilleur équilibre entre performances et effet.
Tout d'abord, un grand nombre de calculs matriciels dans les processus de pré- et post-traitement et d'inférence de MiracleVision sont transplantés sur le GPU pour un calcul parallèle autant que possible, accélérant ainsi efficacement le calcul et réduisant la charge sur le CPU. Dans le même temps, pendant le processus d'assemblage des images, nous fusionnons les couches autant que possible, utilisons FlashAttention pour réduire l'utilisation de la mémoire vidéo, améliorons les performances d'inférence et ajustons l'implémentation du noyau pour maximiser l'utilisation de la puissance de calcul du GPU pour différents graphiques NVIDIA. cartes.
De plus, en s'appuyant sur la méthode de quantification des paramètres du modèle auto-développée, MiracleVision est quantifié à 8 bits sans perte évidente de précision. Étant donné que différentes cartes graphiques GPU prennent en charge différemment la quantification 8 bits, nous adoptons de manière innovante une stratégie de précision mixte pour sélectionner de manière adaptative l'opérateur optimal dans différents environnements de ressources de serveur afin d'obtenir la solution optimale pour l'accélération globale.
Pour les images saisies par l'utilisateur avec une résolution plus élevée, il est difficile d'effectuer directement une inférence à la résolution d'origine en raison des limitations des ressources du serveur et des coûts de temps. À cet égard, l'équipe a d'abord compressé la résolution de l'image à une taille appropriée, puis effectué une inférence basée sur MiracleVision, puis utilisé un algorithme de super-résolution pour restaurer l'image à la résolution d'origine, puis effectué une fusion d'image avec l'image d'origine. conservant ainsi les deux. Il génère des images claires et économise l'utilisation de la mémoire et le temps d'exécution pendant le processus d'inférence.
Meitu a une coopération approfondie avec Samsung pour créer une nouvelle expérience d'édition d'images mobiles utilisant l'IA
Le 25 janvier, Samsung Electronics a organisé une conférence de lancement de nouveau produit pour la série Galaxy S24 en Chine. Meitu a approfondi sa coopération avec Samsung pour créer une nouvelle expérience d'édition d'images IA pour les nouveaux albums de téléphones mobiles de la série Galaxy S24 de Samsung. L'édition générative développée indépendamment par le Meitu Imaging Research Institute (MT Lab) - les fonctions d'expansion et de modification d'images IA sont également. Il a été officiellement lancé pour ouvrir un nouvel espace pour l'édition et la création d'images mobiles.
Avec la fonction d'édition d'image AI, les utilisateurs peuvent facilement déplacer, supprimer ou redimensionner l'image en appuyant simplement longuement sur l'image qu'ils souhaitent modifier. De plus, lorsque la ligne horizontale de l'image n'est pas verticale, la fonction d'expansion de l'image AI peut remplir intelligemment les zones manquantes de la photo et corriger la composition de l'image une fois que l'utilisateur a ajusté l'angle.
Basé sur les fonctions d'IA apportées par MiracleVision, Meitu aide non seulement les utilisateurs à obtenir facilement des effets d'édition de niveau professionnel sur les téléphones mobiles et à créer des travaux photo plus personnalisés, mais continuera également à promouvoir et à améliorer l'IA dans l'ensemble de l'industrie de la téléphonie mobile. . Capacités de traitement d'images.
S'appuyant sur les puissantes capacités techniques du Meitu Imaging Research Institute (MT Lab), MiracleVision a été itéré vers la version 4.0 en moins de six mois. À l'avenir, Meitu continuera de s'efforcer d'améliorer l'expérience utilisateur dans les secteurs du commerce électronique, de la publicité, des jeux et autres, et d'aider les praticiens dans différents scénarios à améliorer l'efficacité de leur flux de travail.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser le redessin et la redistribution
- [Trend Weekly] Tendance mondiale du développement de l'industrie de l'intelligence artificielle : OpenAI a soumis une demande de marque 'GPT-5' auprès de l'Office américain des brevets
- La taille de l'industrie informatique de la Chine atteint 2 600 milliards de yuans, avec plus de 20,91 millions de serveurs à usage général et 820 000 serveurs d'IA livrés au cours des six dernières années.
- Améliorer les performances des pages Web : conseils pour réduire les redessins et les redistributions
- Stratégies clés pour réduire la redistribution et le redessinage HTML : optimisation des performances frontales