
Maison >Périphériques technologiques >IA >Utilisez la vision pour inciter ! Shen Xiangyang a présenté le nouveau modèle de l'Institut de recherche IDEA, qui ne nécessite aucune formation ni réglage précis et peut être utilisé directement.
Utilisez la vision pour inciter ! Shen Xiangyang a présenté le nouveau modèle de l'Institut de recherche IDEA, qui ne nécessite aucune formation ni réglage précis et peut être utilisé directement.

- 王林avant
- 2023-11-26 20:22:581685parcourir
Quel type d'expérience cela apportera-t-il lors de l'utilisation d'invites visuelles ?
Dessinez simplement un croquis au hasard sur l'image et les mêmes catégories seront marquées instantanément !

Même le lien grain-de-mètre est difficile à gérer pour le GPT-4V. Il vous suffit de tirer manuellement la boîte pour trouver tous les grains de riz.

Avec un nouveau paradigme de détection d'objets !
Lors de la conférence annuelle IDEA qui vient de se terminer, Shen Xiangyang, président fondateur de l'Institut IDEA et académicien étranger de l'Académie nationale d'ingénierie, a présenté les derniers résultats de recherche -
Le contenu du T-Rex basé sur le modèle Visual Prompt doit être réécrit

L'ensemble du processus est interactif, prêt à l'emploi et peut être complété en quelques étapes seulement.
Auparavant, le SAM open source de Meta segmentait tous les modèles, ce qui inaugurait directement le moment GPT-3 dans le domaine des CV. Cependant, il était toujours basé sur le paradigme de l'invite de texte, ce qui serait plus difficile à gérer pour certains complexes et rares. scénarios.
Vous pouvez désormais facilement résoudre le problème en changeant les images.
De plus, l'ensemble de la conférence regorge également d'informations utiles, telles que le grand modèle basé sur les connaissances Think-on-Graph, la plate-forme de développement MoonBit, l'artefact de recherche scientifique sur l'IA ReadPaper mise à jour 2.0, le coprocesseur informatique confidentiel SPU, la vidéo portrait contrôlable. plateforme de génération HiveNet et ainsi de suite.
Enfin, Shun Xiangyang a également partagé le projet sur lequel il a consacré le plus de temps ces dernières années : Low-altitude Economy.
Je crois que lorsque l'économie de basse altitude sera relativement mature, il y aura 100 000 drones dans le ciel de Shenzhen chaque jour et des millions de drones décolleront chaque jour
Utilisez la vision pour faire des invites
T -In En plus de la fonction d'invite de base à un seul tour, Rex prend également en charge trois modes avancés
- Mode positif à plusieurs tours
Ceci est similaire au dialogue à plusieurs tours, qui peut produire des résultats plus précis et éviter les détections manquées
- Positif + Le mode négatif
convient aux scénarios dans lesquels les signaux visuels sont ambigus et provoquent de fausses détections.
Le mode Graphique croisé vous permet de repenser et de disposer des graphiques pour visualiser facilement les données et les informations
En utilisant un graphique de référence pour détecter d'autres images

Selon les rapports, le T-Rex n'est pas limité par des catégories prédéfinies et peut Des exemples visuels sont utilisés pour spécifier les cibles de détection, résolvant ainsi le problème de la difficulté à exprimer pleinement certains objets avec des mots et améliorant l'efficacité des incitations. Surtout dans le cas de composants complexes dans certaines scènes industrielles, l'effet est particulièrement évident
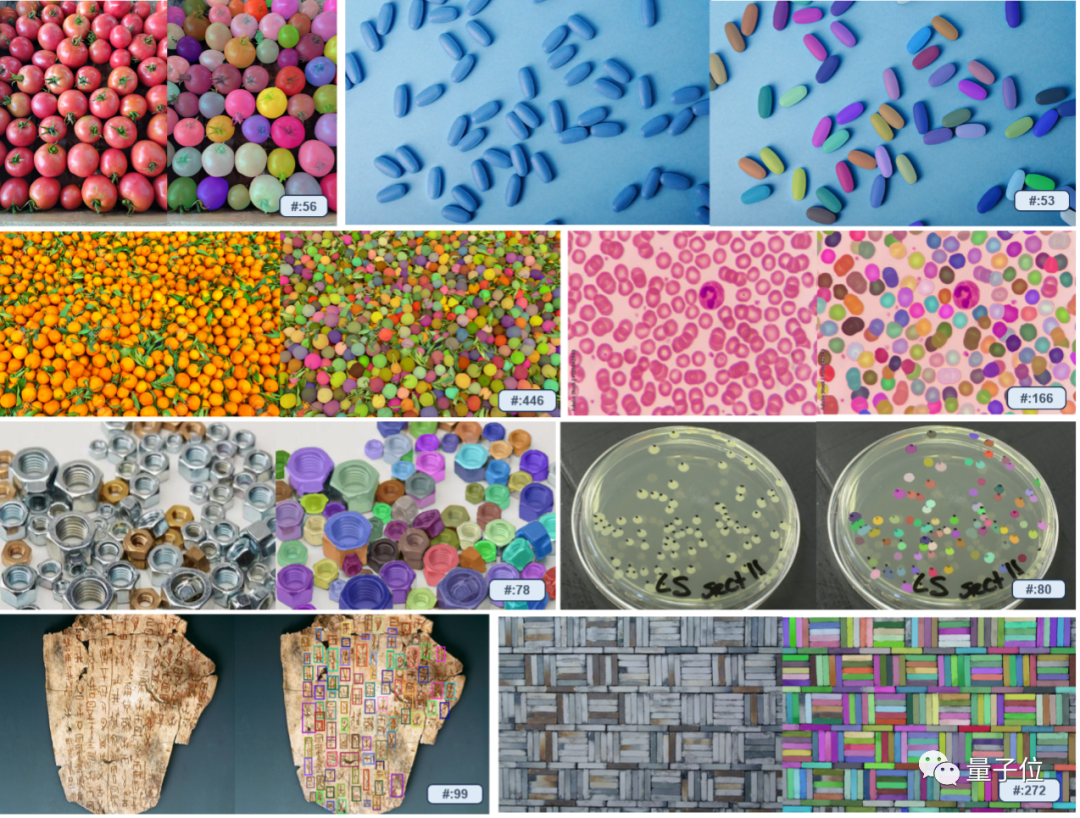
De plus, en interagissant avec les utilisateurs, les résultats de détection peuvent également être rapidement évalués à tout moment et des corrections d'erreurs peuvent être apportées.
T-Rex se compose principalement de trois composants : un encodeur d'image, un encodeur d'indices et un décodeur d'images
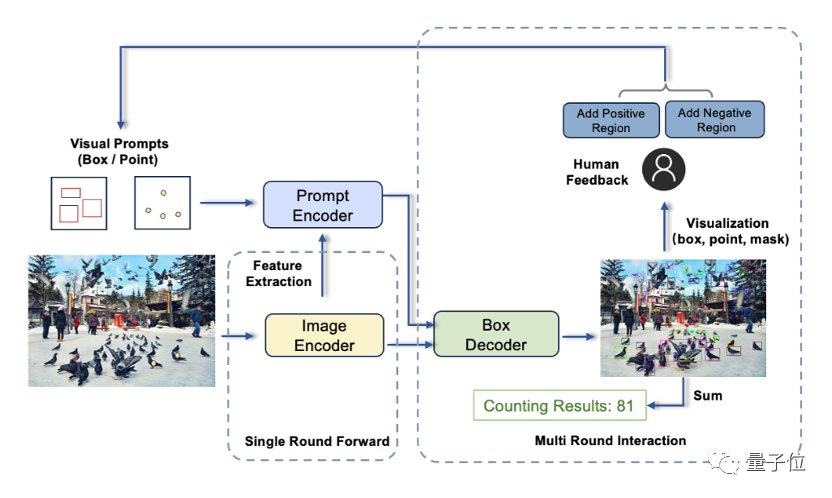
Ce travail provient du Centre de recherche en vision par ordinateur et en robotique de l'Institut de recherche IDEA.
Le modèle de détection de cible précédemment open source de l'équipe, DINO, est le premier modèle DETR à se classer premier dans la liste de détection de cible COCO ; le détecteur à échantillon zéro Grounding DINO est très populaire sur Github (il a reçu 11 000 étoiles jusqu'à présent) et Un SAM ancré qui peut tout détecter et tout segmenter. Pour plus de détails techniques, veuillez cliquer sur le lien à la fin de l'article.
L'ensemble de la conférence regorge d'informations utiles
De plus, plusieurs résultats de recherche ont également été mis en avant lors de la conférence IDEA.
Par exemple, le grand modèle basé sur les connaissances Think-on-Graph, en termes simples, combine de grands modèles avec des graphiques de connaissances.
Les grands modèles sont bons en compréhension des intentions et en apprentissage autonome, tandis que les graphiques de connaissances sont meilleurs en raisonnement en chaîne logique en raison de leurs méthodes structurées de stockage des connaissances.Think-on-Graph amène l'agent grand modèle à "penser" sur le graphe de connaissances, et recherche et déduit progressivement la réponse optimale (recherche et raisonnement étape par étape sur les entités associées du graphe de connaissances). À chaque étape du raisonnement, le grand modèle est personnellement impliqué et apprend des forces et des faiblesses de chacun grâce au graphe de connaissances.

MoonBit est une plateforme de développement optimisée par Wasm et conçue pour le cloud computing et l'edge computing.
Ce système fournit non seulement une conception de langage de programmation universel, mais intègre également des compilateurs, des systèmes de construction, des environnements de développement intégrés (IDE), des outils de déploiement et d'autres modules pour améliorer l'expérience et l'efficacité du développement
L'artefact de recherche scientifique précédemment publié ReadPaper Il a également été mis à jour vers la version 2.0 et de nouvelles fonctions telles que le copilote de lecture et le copilote de polissage ont été présentées lors de la conférence de presse.

À la fin de la conférence de presse, Shen Xiangyang a publié le « Livre blanc sur le développement économique à basse altitude (2.0) - Solution entièrement numérique », proposant le processus spatial temporel dans son système intelligent intégré d'espace aérien inférieur (SILAS) Processus) nouveau concept.
Lien T-Rex :
https://trex-counting.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire s'il n'y a pas d'option de servlet lors de la création d'une nouvelle idée ?
- Quelle est la touche de raccourci pour revenir à l'étape précédente dans Idea ?
- Quelles sont les applications de la vision industrielle dans le domaine industriel ?
- Comment télécharger le code de l'idée sur gitlab
- Un article pour comprendre la perception lidar et fusion visuelle de la conduite autonome