
Maison >Périphériques technologiques >IA >La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA
La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA

- WBOYavant
- 2024-02-26 09:58:241204parcourir
Après que le modèle vidéo d'IA Sora soit devenu populaire, de grandes entreprises telles que Meta et Google se sont retirées pour faire des recherches et rattraper OpenAI.
Récemment, des chercheurs de l'équipe Google ont proposé un encodeur vidéo universel - VideoPrism.
Il peut gérer diverses tâches de compréhension vidéo via un seul modèle figé.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2402.13217.pdf
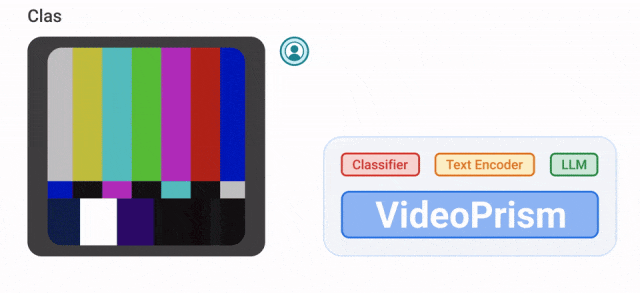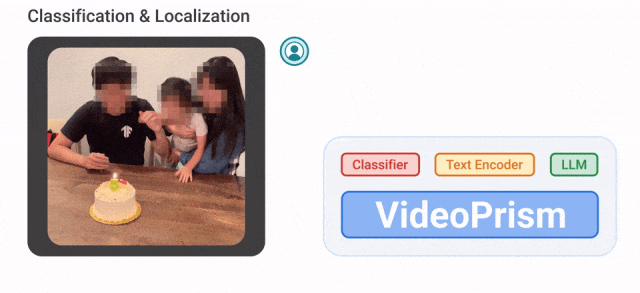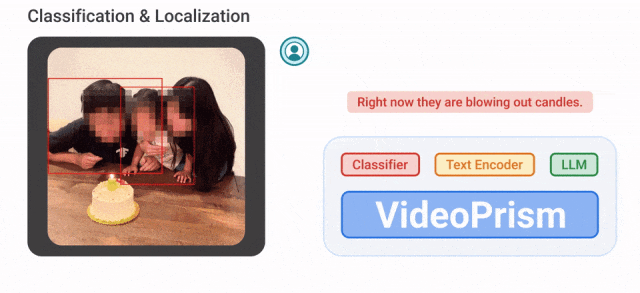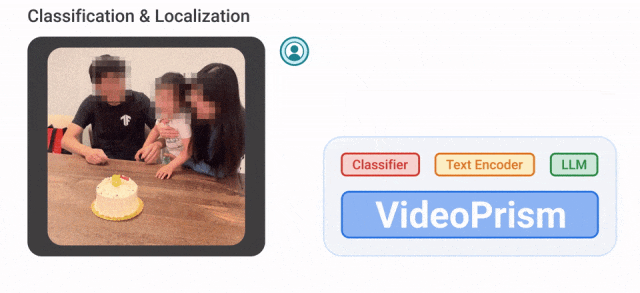
Par exemple, VideoPrism peut classer et localiser les personnes soufflant des bougies dans la vidéo ci-dessous.
 Images
Images
Récupération vidéo-texte, en fonction du contenu du texte, le contenu correspondant dans la vidéo peut être récupéré.
 Photos
Photos
Pour un autre exemple, décrivez la vidéo ci-dessous : une petite fille joue avec des blocs de construction.
Vous pouvez également mener des questions et réponses d'assurance qualité.
- De quelle couleur est le bloc qu'elle a placé au dessus du bloc vert ?
- Violet.
 Pictures
Pictures
Les chercheurs ont pré-entraîné VideoPrism sur un corpus hétérogène contenant 36 millions de paires de sous-titres vidéo de haute qualité et 582 millions de clips vidéo avec du texte parallèle bruité (tel que du texte transcrit ASR).
Il convient de mentionner que VideoPrism a actualisé 30 SOTA dans 33 tests de référence de compréhension vidéo.
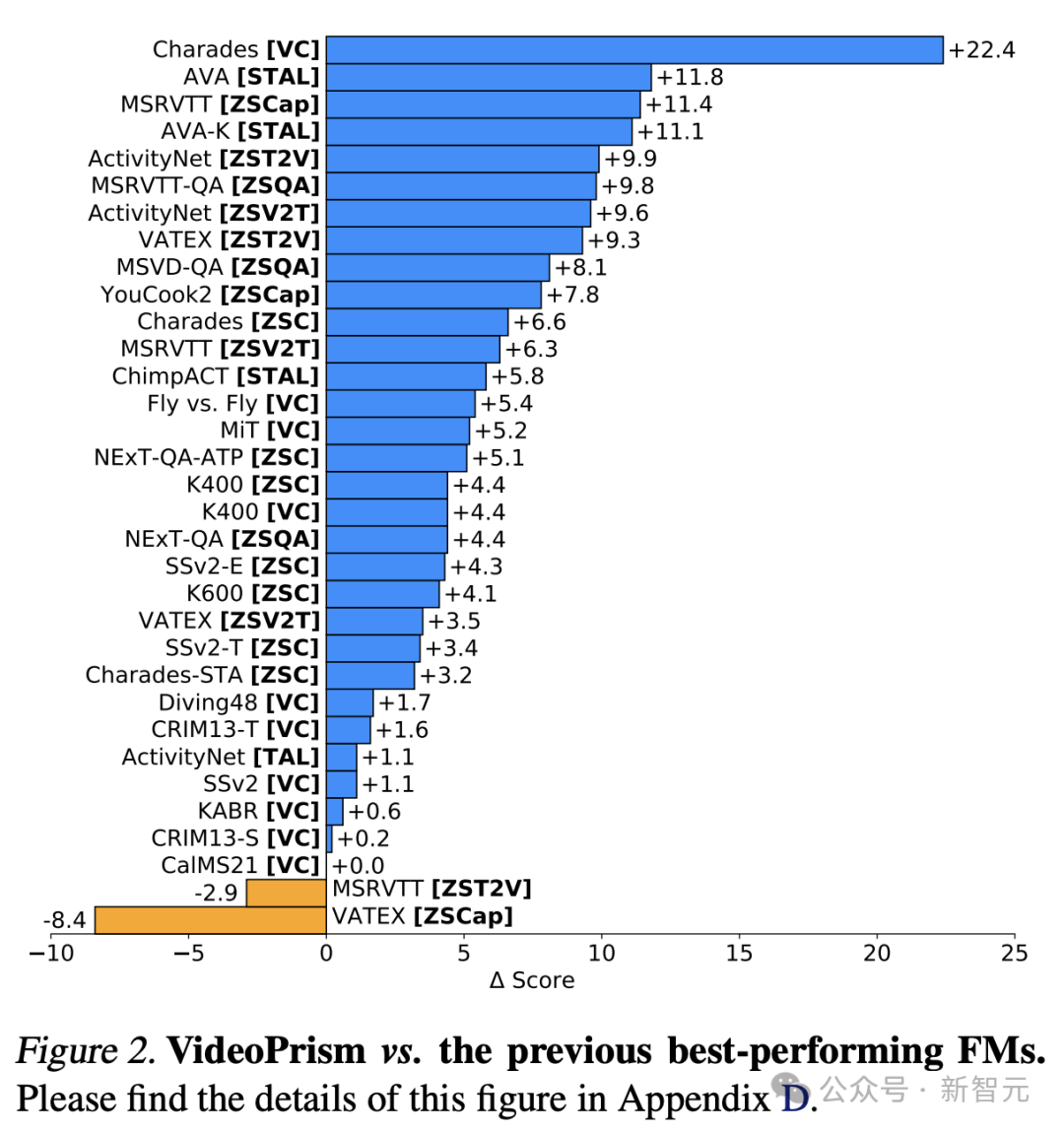 Pictures
Pictures
Universal Visual Encoder VideoPrism
Actuellement, le Video Foundation Model (ViFM) a un énorme potentiel pour débloquer de nouvelles fonctionnalités à travers d'énormes corpus.
Bien que des recherches antérieures aient fait de grands progrès dans la compréhension générale de la vidéo, la construction d'un véritable « modèle vidéo de base » reste un objectif insaisissable.
En réponse, Google a lancé VideoPrism, un encodeur visuel à usage général conçu pour résoudre un large éventail de tâches de compréhension vidéo, notamment la classification, la localisation, la récupération, les sous-titres et la réponse aux questions (QA).
VideoPrism est largement évalué sur des ensembles de données de CV, ainsi que sur des tâches de CV dans des domaines scientifiques tels que les neurosciences et l'écologie.
Obtenez des performances de pointe avec une condition physique minimale en utilisant un seul modèle gelé.
De plus, les chercheurs de Google affirment que ce réglage de l'encodeur figé suit simultanément des recherches antérieures et prend en compte son aspect pratique, ainsi que le coût élevé du calcul et du réglage fin du modèle vidéo.
 Photos
Photos
Structure de conception, méthode de formation en deux étapes
Le concept de conception derrière VideoPrism est le suivant.
Les données de pré-entraînement sont la base du modèle de base (FM). Les données de pré-entraînement idéales pour ViFM sont un échantillon représentatif de toutes les vidéos du monde.
Dans cet exemple, la plupart des vidéos n'ont pas de texte parallèle décrivant le contenu.
Cependant, s'il est formé sur un tel texte, il peut fournir des indices sémantiques inestimables sur l'espace vidéo.
Ainsi, la stratégie de pré-formation de Google devrait se concentrer principalement sur le mode vidéo tout en exploitant pleinement toutes les paires vidéo-texte disponibles.
Du côté des données, les chercheurs de Google ont approximé la pré-formation requise en regroupant 36 millions de paires de sous-titres vidéo de haute qualité et 582 millions de clips vidéo avec du texte parallèle bruité (tels que des transcriptions ASR, des sous-titres générés et du texte récupéré).
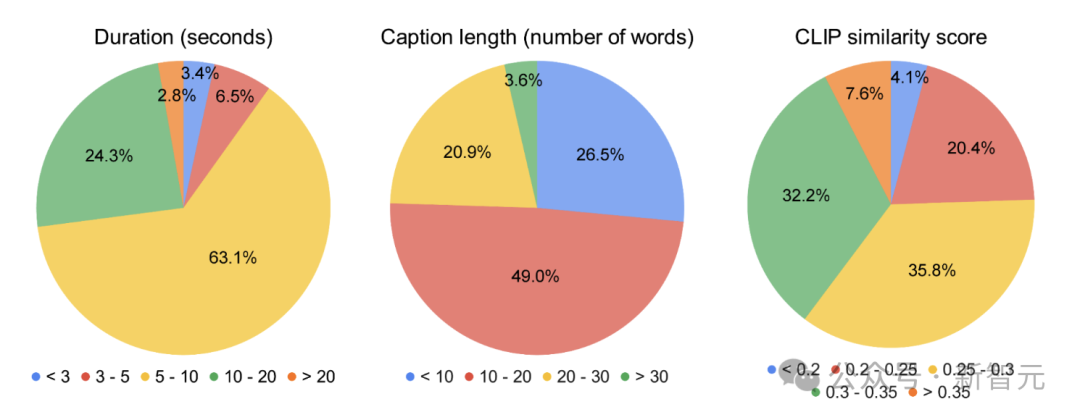 Photos
Photos
 Pictures
Pictures
En termes de modélisation, les auteurs apprennent d'abord de manière comparative les intégrations vidéo sémantiques de toutes les paires vidéo-texte de qualités différentes.
Les intégrations sémantiques sont ensuite affinées globalement et étiquetées à l'aide de nombreuses données vidéo pures, améliorant ainsi la modélisation vidéo masquée décrite ci-dessous.
Malgré le succès du langage naturel, la modélisation des données masquées reste un défi pour les CV en raison du manque de sémantique dans le signal visuel brut.
Les recherches existantes combinent taux de masquage élevé et légèreté en empruntant une sémantique indirecte (comme l'utilisation de CLIP pour guider les modèles ou les tokenizers, ou une sémantique implicite pour relever ce défi) ou en les généralisant implicitement (comme l'étiquetage des correctifs visuels) Combinaison de décodeur.
Sur la base des idées ci-dessus, l'équipe Google a adopté une approche en deux étapes basée sur les données de pré-formation.
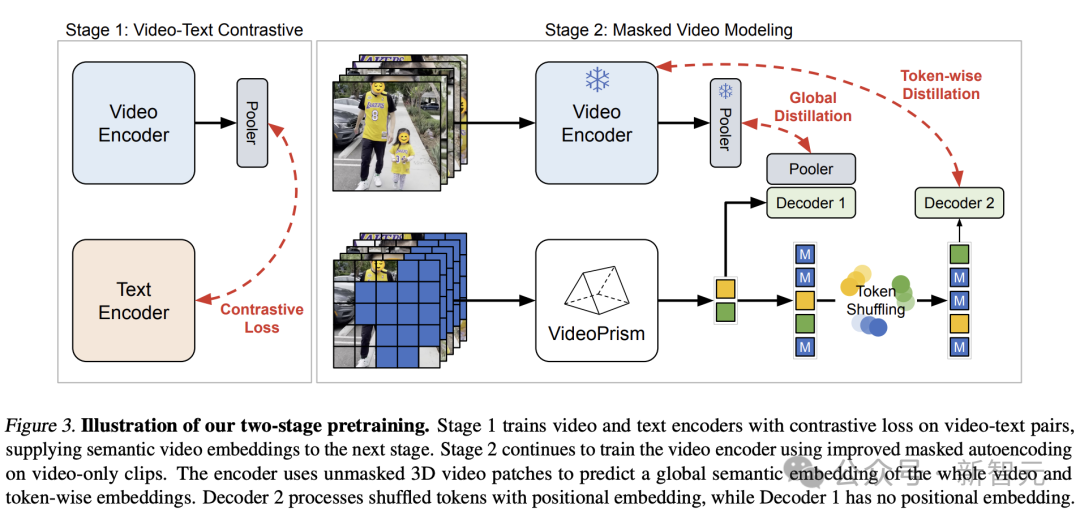 Images
Images
Dans la première étape, un apprentissage contrastif est effectué pour aligner l'encodeur vidéo avec l'encodeur de texte en utilisant toutes les paires vidéo-texte.
Sur la base de recherches antérieures, l'équipe de Google a minimisé les scores de similarité de toutes les paires vidéo-texte du lot, en minimisant symétriquement les pertes d'entropie croisée.
Et utilisez le modèle d'image de CoCa pour initialiser le module d'encodage spatial et intégrer WebLI dans la pré-formation.
Avant de calculer la perte, les fonctionnalités de l'encodeur vidéo sont agrégées via un pool d'attention multi-têtes (MAP).
Cette étape permet à l'encodeur vidéo d'apprendre une sémantique visuelle riche à partir de la supervision linguistique, et le modèle résultant fournit des intégrations vidéo sémantiques pour la formation de la deuxième étape.
 Images
Images
Dans la deuxième étape, l'encodeur continue d'être formé et deux améliorations sont apportées :
- Le modèle doit prédire l'intégration globale au niveau vidéo et le jeton de la première étape en fonction de l'entrée vidéo non masquée. Intégration de patchs
- Le jeton de sortie de l'encodeur est mélangé aléatoirement avant d'être transmis au décodeur pour éviter d'apprendre des raccourcis.
Notamment, la pré-formation des chercheurs exploite deux signaux de supervision : la description textuelle de la vidéo et l'autosupervision contextuelle, permettant à VideoPrism de bien fonctionner sur les tâches centrées sur l'apparence et l'action.
En fait, des recherches antérieures montrent que les sous-titres vidéo révèlent principalement des indices d'apparence, tandis que la supervision contextuelle aide à apprendre les actions.
 Photos
Photos
Résultats expérimentaux
Ensuite, les chercheurs ont évalué VideoPrism sur un large éventail de tâches de compréhension centrées sur la vidéo, démontrant ses capacités et sa généralité.
Principalement divisé en quatre catégories suivantes :
(1) Généralement uniquement la compréhension de la vidéo, y compris la classification et le positionnement spatio-temporel
(2) Récupération de texte vidéo sans prise de vue
(3) Sous-titres vidéo sans prise de vue et inspection de la qualité
(4) Tâches CV en sciences
Classification et localisation spatio-temporelle
Le tableau 2 montre les résultats du backbone gelé sur VideoGLUE.
VideoPrism surpasse considérablement la ligne de base sur tous les ensembles de données. De plus, l’augmentation de la taille du modèle sous-jacent de VideoPrism de ViT-B à ViT-g améliore considérablement les performances.
Il convient de noter qu'aucune méthode de référence n'obtient le deuxième meilleur résultat parmi tous les benchmarks, ce qui suggère que des méthodes précédentes peuvent avoir été développées pour cibler certains aspects de la compréhension vidéo.
Et VideoPrism continue de s'améliorer sur ce large éventail de tâches.
Ce résultat montre que VideoPrism intègre divers signaux vidéo dans un seul encodeur : sémantique à plusieurs granularités, signaux d'apparence et de mouvement, informations spatio-temporelles et robustesse à différentes sources vidéo (telles que les vidéos en ligne et les performances scénarisées).
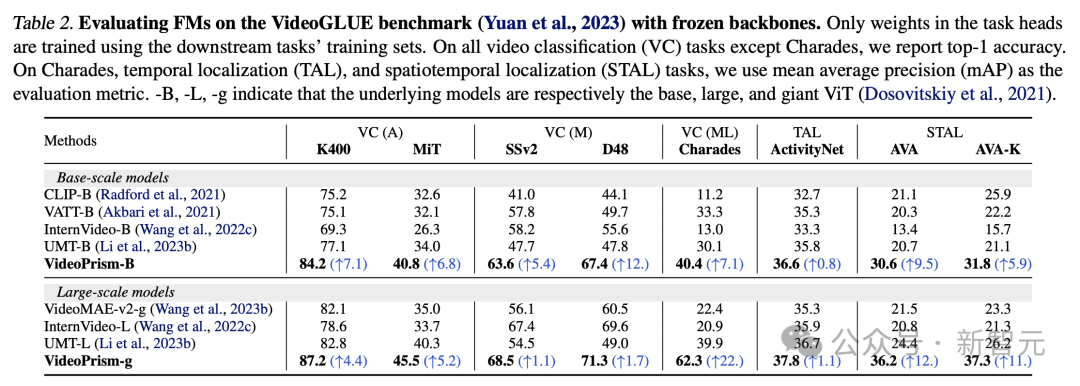 Image
Image
Récupération et classification de texte vidéo Zero-shot
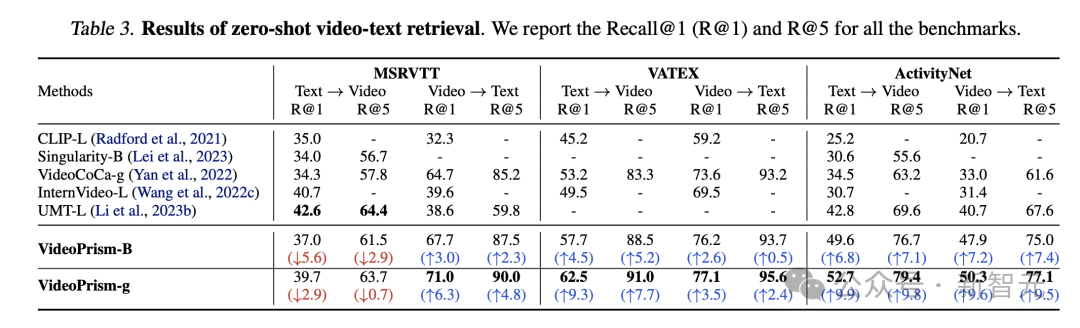
Le Tableau 3 et le Tableau 4 résument respectivement les résultats de la récupération de texte vidéo et de la classification vidéo.
Les performances de VideoPrism actualisent plusieurs références, et sur des ensembles de données difficiles, VideoPrism a réalisé des améliorations très significatives par rapport aux technologies précédentes.
 Photos
Photos
La plupart des résultats pour le modèle de base VideoPrism-B surpassent en fait les modèles existants à plus grande échelle.
De plus, VideoPrism est comparable, voire meilleur, aux modèles du tableau 4 pré-entraînés à l'aide de données dans le domaine et de modalités supplémentaires (par exemple audio). Ces améliorations dans les tâches de récupération et de classification sans tir reflètent les puissantes capacités de généralisation de VideoPrism.
 Photos
Photos
Sous-titres vidéo sans échantillon et contrôle de qualité
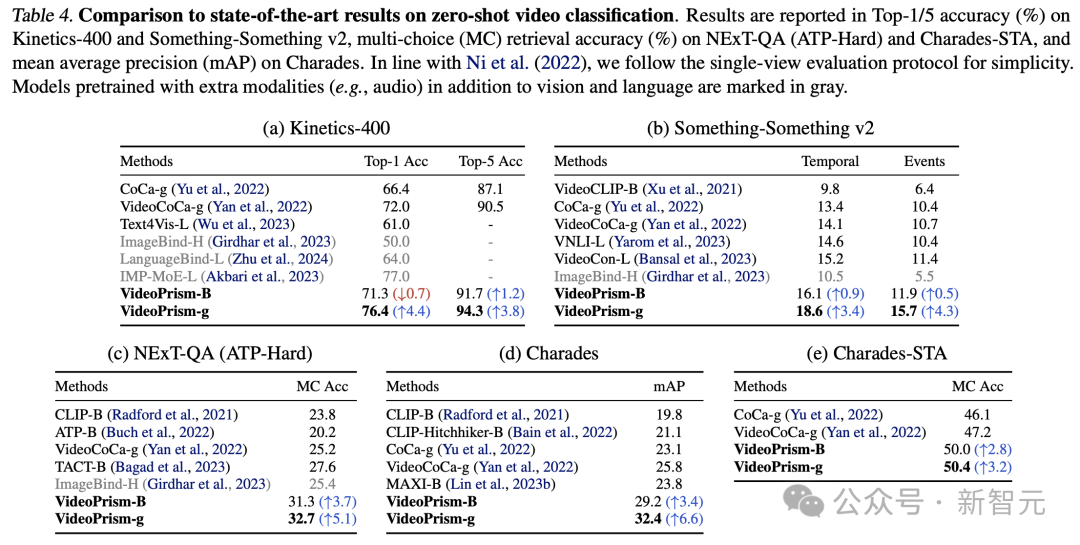
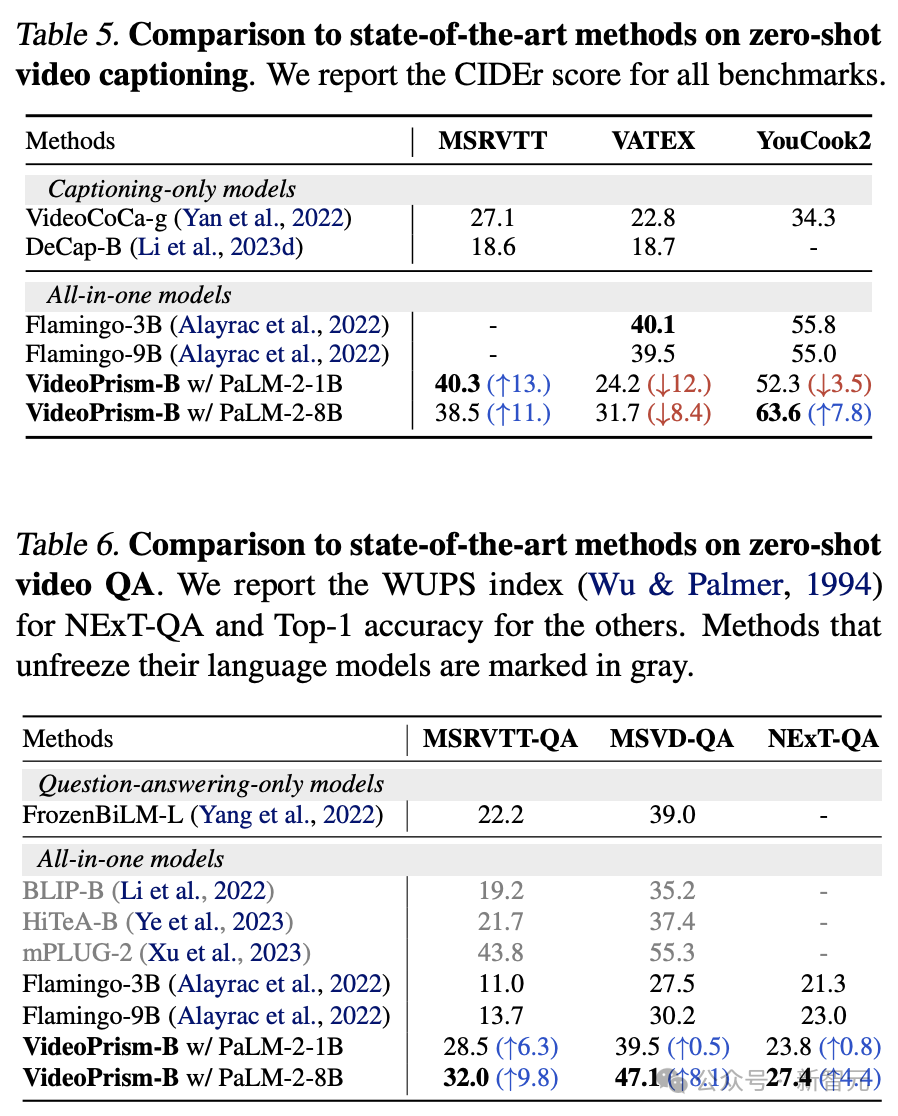
Le Tableau 5 et le Tableau 6 montrent, respectivement, les résultats des sous-titres vidéo sans échantillon et du contrôle qualité.
Malgré l'architecture simple du modèle et le petit nombre de paramètres d'adaptateur, les derniers modèles restent compétitifs et, à l'exception de VATEX, se classent parmi les meilleures méthodes de gel des modèles visuels et linguistiques.
Les résultats montrent que l'encodeur VideoPrism se généralise bien aux tâches de génération vidéo-parole.
 Photos
Photos
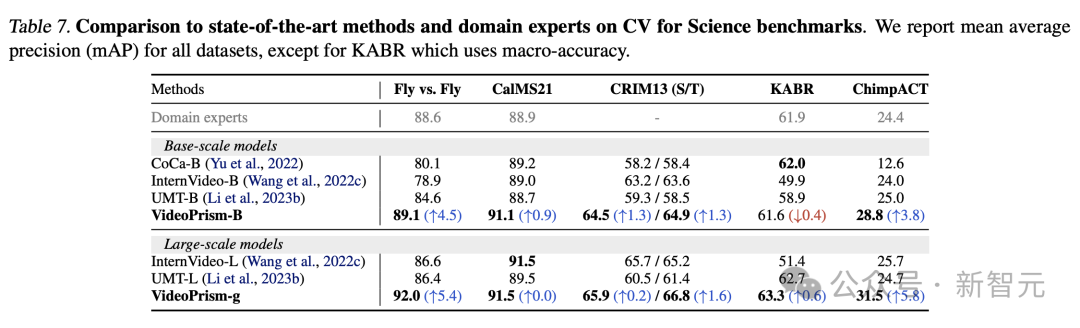
Tâches CV dans les domaines scientifiques
Universal ViFM utilise un encodeur gelé partagé dans toutes les évaluations, avec des performances comparables aux modèles spécifiques à un domaine dédiés à une seule tâche.
En particulier, VideoPrism est souvent plus performant et surpasse les modèles experts de domaine avec les modèles à l'échelle de base.
La mise à l'échelle vers des modèles à grande échelle peut améliorer encore les performances sur tous les ensembles de données. Ces résultats démontrent que ViFM a le potentiel d’accélérer considérablement l’analyse vidéo dans différents domaines.
Étude sur l'ablation
La figure 4 montre les résultats de l'ablation. Notamment, les améliorations continues de VideoPrism sur SSv2 démontrent l’efficacité des efforts de gestion des données et de conception de modèles pour promouvoir la compréhension du mouvement dans la vidéo.
Bien que la base de comparaison ait déjà obtenu des résultats compétitifs sur le K400, la distillation globale et le brassage de jetons proposés améliorent encore la précision.
 Photos
Photos
Références :
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder .html
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment enregistrer des images PS au format AI
- Que dois-je faire si phpstorm ne parvient pas à ouvrir Google Chrome ?
- Comment diviser correctement un ensemble de données ? Résumé de trois méthodes courantes
- Comment améliorer la vitesse des requêtes sur de grands ensembles de données grâce au multithreading PHP