
Maison >Périphériques technologiques >IA >Utilisant un modèle de diffusion pour générer des paramètres de réseau, LeCun fait l'éloge de la nouvelle recherche de l'équipe de You Yang
Utilisant un modèle de diffusion pour générer des paramètres de réseau, LeCun fait l'éloge de la nouvelle recherche de l'équipe de You Yang

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-26 08:10:03606parcourir
Si vous avez été choqué par les vidéos générées par Sora, alors vous avez vu l'énorme potentiel des modèles de diffusion en génération visuelle. Bien entendu, le potentiel du modèle de diffusion ne s'arrête pas là. Il offre également des perspectives d'application passionnantes dans de nombreux autres domaines. Pour plus de cas, veuillez vous référer à notre récent rapport « La technologie derrière l'explosion de Sora, un article résumant la diffusion. dernière direction de développement des modèles》.
Des recherches récentes menées par l'équipe de You Yang à l'Université nationale de Singapour, à l'Université de Californie à Berkeley et à Meta AI Research ont découvert une nouvelle application du modèle de diffusion : utilisé pour générer des paramètres de modèle pour les réseaux de neurones.

Adresse papier : https://arxiv.org/pdf/2402.13144.pdf
Adresse du projet : https://github.com/NUS-HPC-AI-Lab/Neural-Network- Diffusion
Titre de l'article : Neural Network Diffusion
Cette méthode semble permettre de générer facilement de nouveaux modèles en utilisant les réseaux de neurones existants ! Yann LeCun l'apprécie et le partage. Le modèle généré maintient non seulement les performances du modèle original, mais peut même les surpasser.
Le modèle de diffusion est à l'origine dérivé du concept de thermodynamique hors équilibre. En 2015, Jascha Sohl-Dickstein et al., dans leur article « Deep Unsupervised Learning using Nonequilibrium Thermodynamics » ont pour la première fois utilisé un processus de diffusion pour supprimer progressivement le bruit de l'entrée, ce qui a permis d'obtenir des images claires.
Des travaux de recherche ultérieurs tels que DDPM et DDIM ont optimisé le modèle de diffusion et ont donné à son paradigme de formation les caractéristiques distinctes des processus directs et inverses.
A cette époque, la qualité des images générées par le modèle de diffusion n'avait pas encore atteint le niveau idéal.
GuidedDiffusion Ce travail mène des études approfondies sur l'ablation et découvre une meilleure architecture ; ce travail pionnier commence à permettre aux modèles de diffusion de surpasser les méthodes basées sur le GAN en termes de qualité d'image. Les modèles ultérieurs tels que GLIDE, Imagen, DALL·E 2 et Stable Diffusion peuvent déjà générer des images photoréalistes.
Bien que les modèles de diffusion aient connu un grand succès dans le domaine de la génération de vision, leur potentiel dans d'autres domaines est relativement sous-exploré.
Cette étude récente menée par l'Université nationale de Singapour, l'Université de Californie à Berkeley et Meta AI Research a découvert une capacité étonnante du modèle de diffusion : générer des paramètres de modèle hautes performances.
Vous devez savoir que cette tâche est fondamentalement différente des tâches de génération visuelle traditionnelles ! La tâche de génération de paramètres se concentre sur la création de paramètres de réseau neuronal qui fonctionnent bien pour une tâche donnée. Les chercheurs ont déjà exploré cette tâche à partir de perspectives de modélisation a priori et probabilistes, telles que les réseaux de neurones stochastiques et les réseaux de neurones bayésiens. Cependant, personne n’a étudié auparavant l’utilisation de modèles de diffusion pour générer des paramètres.
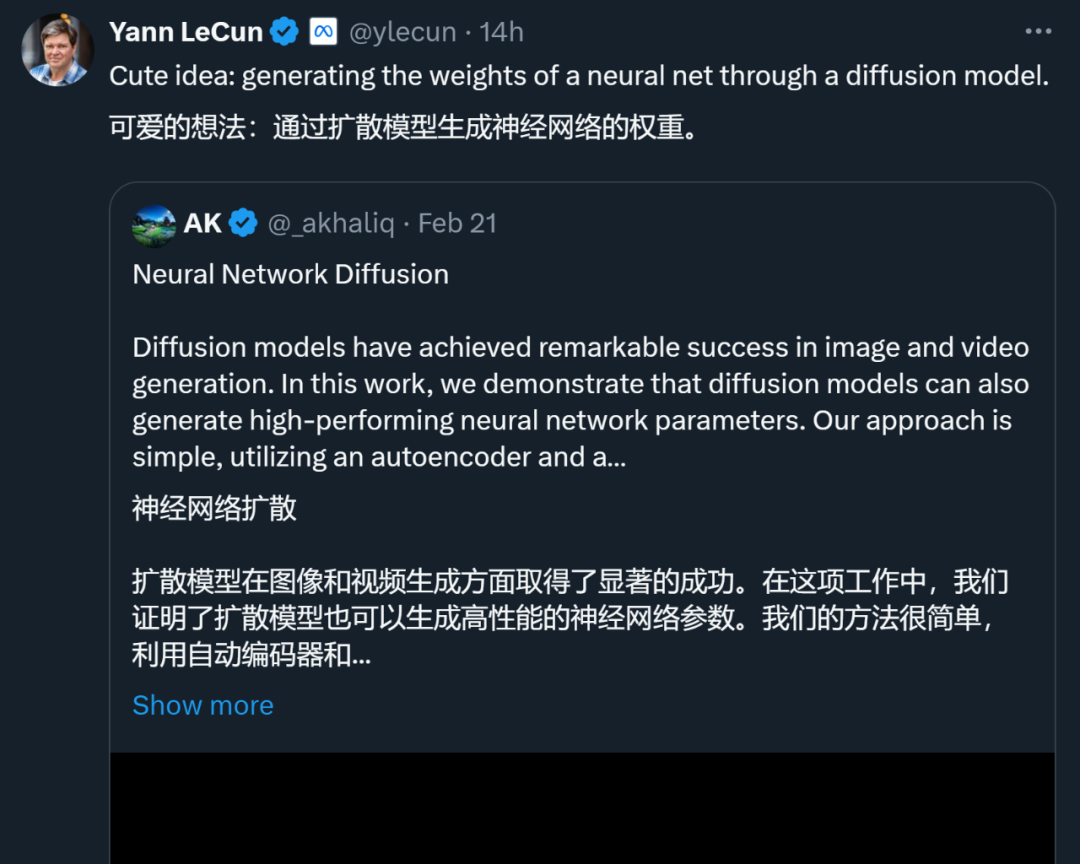
Comme le montre la figure 1, en observant attentivement le processus de formation et le modèle de diffusion du réseau neuronal, nous pouvons constater que la méthode de génération d'images basée sur la diffusion et le processus d'apprentissage par descente de gradient stochastique (SGD) ont certains points communs : 1) Le processus de formation et de diffusion du réseau neuronal Le processus inverse du modèle peut être vu comme le processus de conversion d'un bruit/initialisation aléatoire en une distribution spécifique 2) En ajoutant du bruit plusieurs fois, des images de haute qualité et des paramètres de haute performance ; peut être rétrogradé en distributions simples, telles que les distributions gaussiennes.
Sur la base des observations ci-dessus, l'équipe a proposé une nouvelle méthode de génération de paramètres : la diffusion sur réseau neuronal, abrégé en p-diff, où p fait référence au paramètre.
L'idée decette méthode est très simple, qui consiste à utiliser le modèle de diffusion implicite standard pour synthétiser l'ensemble des paramètres du réseau neuronal, car le modèle de diffusion peut convertir une distribution aléatoire donnée en une distribution spécifique.
Leur approche est simple : utilisez une combinaison d'un auto-encodeur et d'un modèle de diffusion latente standard pour apprendre des distributions de paramètres hautes performances.
Tout d'abord, pour un sous-ensemble de paramètres de modèle entraînés à l'aide de l'optimiseur SGD, un auto-encodeur est entraîné pour extraire les représentations latentes de ces paramètres. Ensuite, un modèle standard de diffusion latente est utilisé pour synthétiser des représentations latentes à partir du bruit. Enfin, l'auto-encodeur entraîné est utilisé pour traiter la représentation latente synthétisée afin d'obtenir de nouveaux paramètres de modèle hautes performances.
Cette nouvelle méthode présente ces deux caractéristiques : 1) Sur plusieurs ensembles de données et architectures, ses performances sont comparables à ses données d'entraînement (c'est-à-dire le modèle entraîné par l'optimiseur SGD) en quelques secondes, et encore mieux dépassées ; Le modèle est assez différent du modèle entraîné, ce qui montre que la nouvelle méthode peut synthétiser de nouveaux paramètres au lieu de mémoriser des échantillons d'apprentissage.
Diffusion sur réseau neuronal
Introduction aux modèles de diffusion
Les modèles de diffusion consistent généralement en des processus aller et retour qui forment un processus en chaîne à plusieurs étapes et peuvent être indexés par étapes de temps.
Processus avancé. Étant donné un échantillon x_0 ∼ q(x), le processus direct consiste à ajouter progressivement du bruit gaussien par étapes T pour obtenir x_1, x_2...x_T.
Processus inverse. Contrairement au processus direct, l'objectif du processus arrière est de former un réseau de débruitage capable de supprimer de manière récursive le bruit dans x_t. Le processus est l’inverse de plusieurs étapes, où t diminue de T jusqu’à 0.
Présentation des méthodes de diffusion sur réseau neuronal
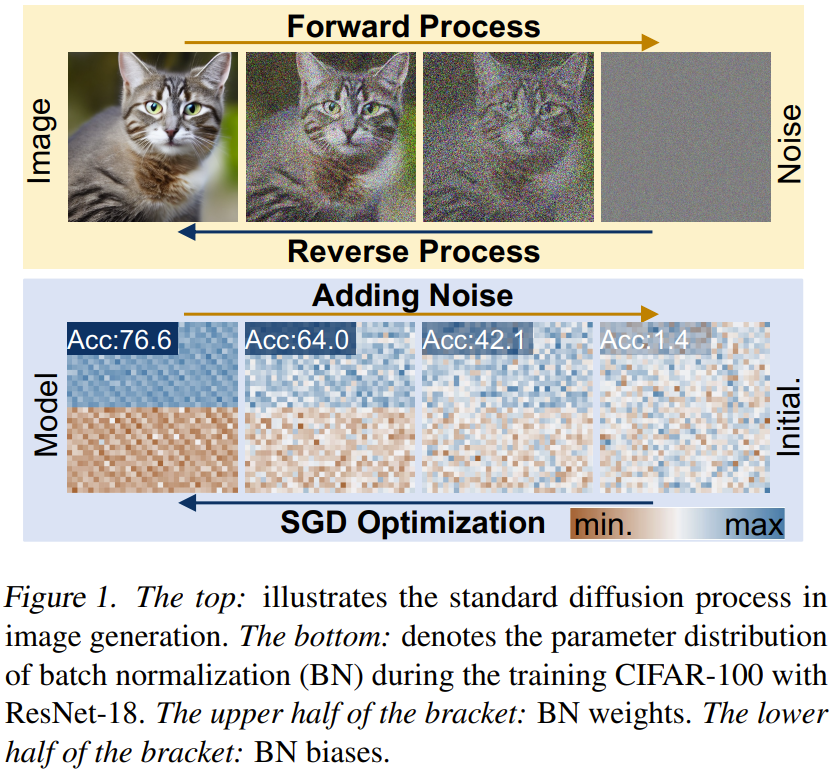
Diffusion sur réseau neuronal (p-diff) Le but de cette nouvelle méthode est de générer des paramètres hautes performances basés sur du bruit aléatoire. Comme le montre la figure 2, cette méthode comprend deux processus : l'auto-encodeur de paramètres et la génération de paramètres.
Étant donné un ensemble de modèles hautes performances entraînés, sélectionnez d'abord un sous-ensemble de ses paramètres et aplatissez-les en un vecteur unidimensionnel.
Après cela, un encodeur est utilisé pour extraire les représentations implicites de ces vecteurs, et un décodeur se charge de reconstruire les paramètres en fonction de ces représentations implicites.
Ensuite, un modèle de diffusion latente standard est entraîné pour synthétiser cette représentation latente basée sur un bruit aléatoire.
Après la formation, vous pouvez utiliser p-diff pour générer de nouveaux paramètres via un tel processus en chaîne : bruit aléatoire → processus inverse → décodeur entraîné → paramètres générés.
Expérience
L'équipe a donné des paramètres expérimentaux détaillés dans l'article, ce qui peut aider d'autres chercheurs à reproduire leurs résultats. Veuillez consulter l'article original pour plus de détails. Ici, nous nous concentrons davantage sur ses résultats et la recherche sur l'ablation.
Résultats
Le Tableau 1 est une comparaison des résultats avec deux méthodes de base sur 8 ensembles de données et 6 architectures.

Sur la base de ces résultats, les observations suivantes peuvent être faites : 1) Dans la plupart des cas expérimentaux, la nouvelle méthode peut obtenir des résultats comparables ou meilleurs que les deux méthodes de base. Cela montre que la méthode nouvellement proposée peut apprendre efficacement la distribution des paramètres de haute performance et générer de meilleurs modèles basés sur un bruit aléatoire. 2) La nouvelle méthode fonctionne bien sur plusieurs ensembles de données différents, ce qui montre que cette méthode a de bonnes performances de généralisation.
Étude et analyse d'ablation
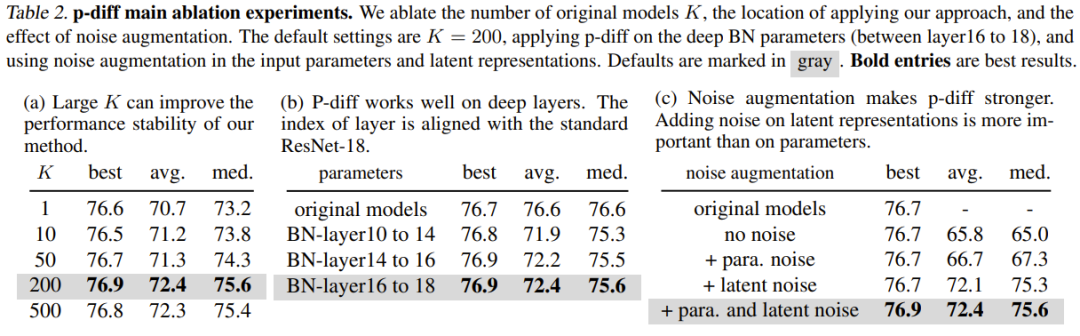
Le tableau 2 (a) montre l'impact des différentes tailles de données d'entraînement (c'est-à-dire le nombre de modèles originaux). Comme on peut le constater, la différence de performances entre les meilleurs résultats pour différents nombres de modèles originaux n’est en réalité pas si grande.
Pour étudier l'efficacité de p-diff à d'autres profondeurs de couche de normalisation, l'équipe a également exploré les performances de nouvelles méthodes de synthèse d'autres paramètres peu profonds. Pour garantir un nombre égal de paramètres BN, l’équipe a mis en œuvre la méthode nouvellement proposée pour trois ensembles de couches BN (situées entre des couches de profondeurs différentes). Les résultats expérimentaux sont présentés dans le tableau 2 (b). On peut voir que les performances (meilleure précision) de la nouvelle méthode sont meilleures que celles du modèle original à toutes les profondeurs des paramètres de couche BN.
Le but de l'amélioration du bruit est d'améliorer la robustesse et la capacité de généralisation des auto-encodeurs entraînés. L'équipe a mené des études d'ablation sur l'application de l'amélioration du bruit aux paramètres d'entrée et aux représentations implicites. Les résultats sont présentés dans le tableau 2 (c).
Auparavant, des expériences évaluaient l'efficacité de nouvelles méthodes pour synthétiser un sous-ensemble de paramètres de modèle (c'est-à-dire les paramètres de normalisation par lots). Nous ne pouvons donc nous empêcher de nous demander : les paramètres globaux du modèle peuvent-ils être synthétisés à l’aide de cette méthode ?
Pour répondre à cette question, l'équipe a mené des expérimentations en utilisant deux petites architectures : MLP-3 et ConvNet-3. Parmi eux, MLP-3 contient trois couches linéaires et une fonction d'activation ReLU, et ConvNet-3 contient trois couches convolutives et une couche linéaire. Contrairement à la stratégie de collecte de données de formation mentionnée précédemment, l’équipe a formé ces architectures à partir de zéro, sur la base de 200 graines aléatoires différentes.
Le Tableau 3 donne les résultats expérimentaux, où la nouvelle méthode est comparée à deux méthodes de base (méthode originale et méthode d'ensemble). Il rapporte la comparaison des résultats et du nombre de paramètres de ConvNet-3 sur CIFAR-10/100 et MLP-3 sur CIFAR-10 et MNIST.

Ces expériences démontrent l'efficacité et la capacité de généralisation de la nouvelle méthode dans la synthèse des paramètres globaux du modèle, ce qui signifie que la nouvelle méthode atteint des performances comparables ou supérieures à la méthode de base. Ces résultats peuvent également démontrer le potentiel d’application pratique de la nouvelle méthode.
Mais l'équipe a également montré dans l'article qu'elle est actuellement incapable de synthétiser les paramètres globaux des grandes architectures telles que ResNet, ViT et ConvNeXt. Ceci est principalement limité par les limites de la mémoire GPU.
Quant à la raison pour laquelle cette nouvelle méthode peut générer efficacement des paramètres de réseau neuronal, l'équipe a également tenté d'explorer et d'analyser les raisons. Ils ont formé ResNet-18 à partir de zéro en utilisant 3 graines aléatoires et ont visualisé ses paramètres comme le montre la figure 3.
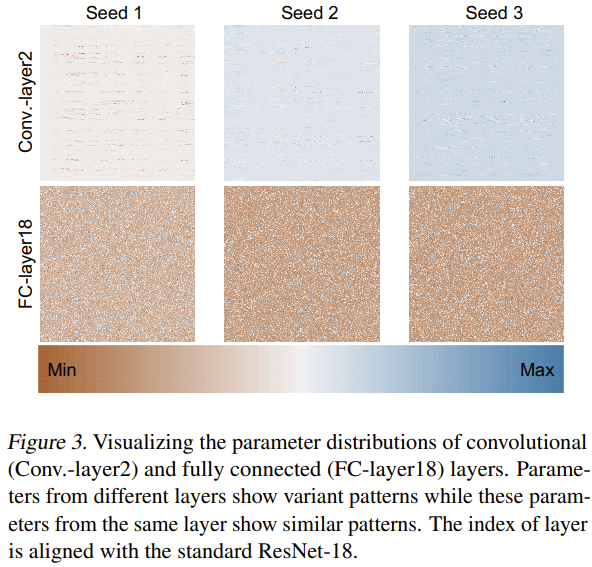
Ils ont utilisé la méthode de normalisation min-max pour obtenir des cartes thermiques des distributions de paramètres de différentes couches. Sur la base des résultats de visualisation de la couche convolutive (Conv.-layer2) et de la couche entièrement connectée (FC-layer18), on peut voir que certains modèles de paramètres existent dans ces couches. En apprenant ces modèles, la nouvelle méthode peut générer des paramètres de réseau neuronal hautes performances.
Est-ce que p-diff repose uniquement sur la mémoire ?
p-diff semble être capable de générer des paramètres de réseau neuronal, mais génère-t-il des paramètres ou s'en souvient-il simplement ? L'équipe a effectué des recherches à ce sujet et comparé les différences entre le modèle original et le modèle généré.
Pour une comparaison quantitative, ils ont proposé un indice de similarité. En termes simples, cet indicateur détermine la similarité entre deux modèles en calculant le ratio d'intersection sur union (IoU) de leurs résultats de prédiction incorrects. Ensuite, ils ont réalisé des études comparatives et des visualisations basées sur cela. Les résultats de la comparaison sont présentés dans la figure 4.
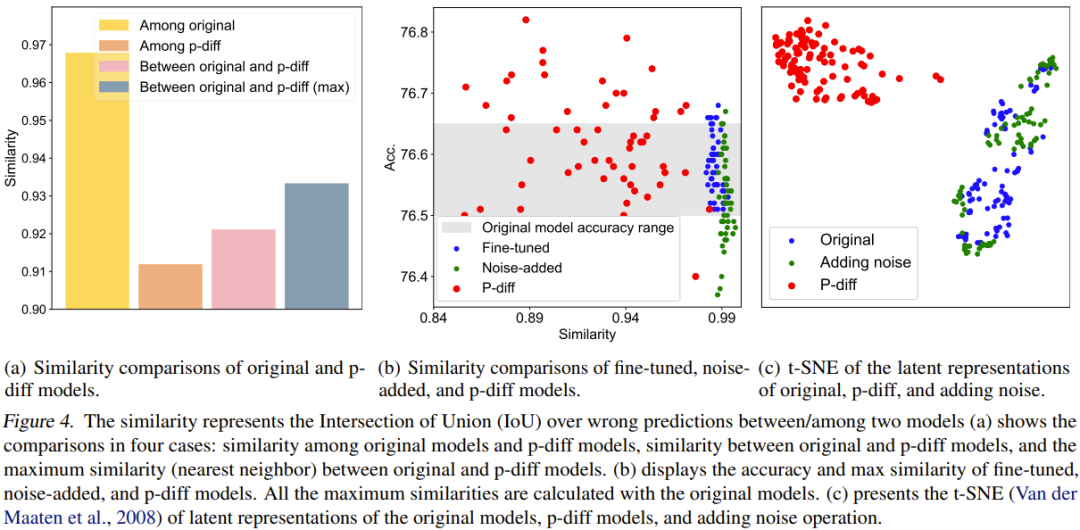
La figure 4(a) présente la comparaison de similarité entre le modèle original et le modèle p-diff, qui implique 4 schémas de comparaison.
Comme vous pouvez le constater, les différences entre les modèles générés sont bien plus importantes que les différences entre les modèles originaux. De plus, la similarité maximale entre le modèle original et le modèle généré est également inférieure à la similarité entre les modèles originaux. Cela suffit pour montrer que p-diff peut générer de nouveaux paramètres différents de ses données d'entraînement (c'est-à-dire le modèle d'origine).
L'équipe a également comparé la nouvelle méthode avec des modèles affinés et des modèles avec bruit ajouté. Les résultats sont présentés à la figure 4 (b).
On voit qu'il est difficile pour le modèle affiné et le modèle avec bruit supplémentaire de surpasser le modèle original. De plus, la similitude entre le modèle affiné ou le modèle avec bruit ajouté et le modèle original est très élevée, indiquant que ces deux modes opératoires ne peuvent pas obtenir un modèle complètement nouveau et performant. Cependant, les modèles générés par la nouvelle méthode présentent diverses similitudes et de meilleures performances que le modèle original.
L'équipe a également comparé les représentations implicites. Les résultats sont présentés à la figure 4 (c). Comme on peut le voir, p-diff peut générer une toute nouvelle représentation latente, tandis que les méthodes d'ajout de bruit n'interpolent qu'autour de la représentation latente du modèle d'origine.
L'équipe a également visualisé la trajectoire du processus p-diff. Plus précisément, ils ont tracé les trajectoires des paramètres générées à différents pas de temps de la phase d’inférence. La figure 5 (a) montre 5 trajectoires (utilisant 5 initialisations de bruit aléatoire différentes). Le centre rouge de la figure est le paramètre moyen du modèle d'origine et la zone grise est son écart type (std).
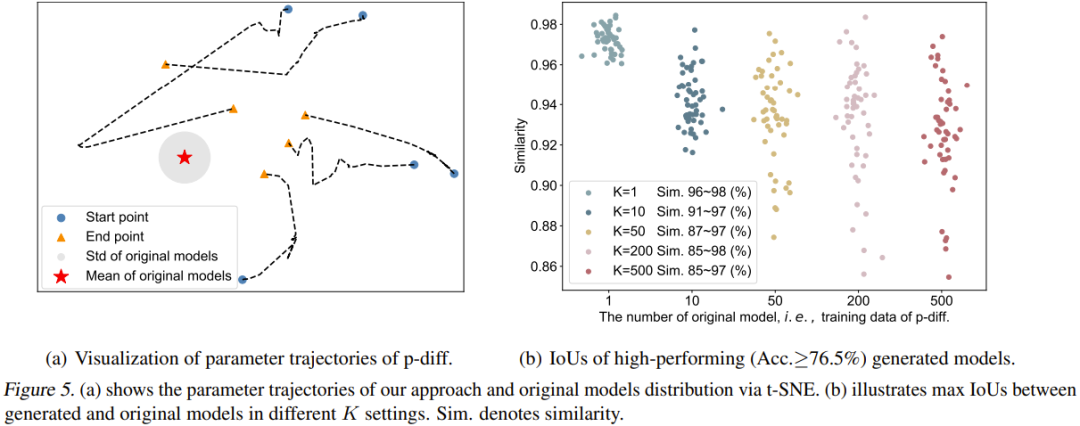
À mesure que les pas de temps augmentent, les paramètres générés seront plus proches du modèle d'origine dans son ensemble. Cependant, on constate également que les extrémités de ces trajectoires (triangles orange) sont encore assez éloignées des paramètres moyens. De plus, les formes de ces cinq trajectoires sont également très diverses.
Enfin, l'équipe a étudié l'impact du nombre de modèles originaux (K) sur la diversité des modèles générés. La figure 5 (b) montre visuellement la similarité maximale entre le modèle d'origine et le modèle généré à différents K. Plus précisément, ils ont généré 50 modèles en continuant à générer des paramètres jusqu'à ce que les 50 modèles générés aient des performances supérieures à 76,5 % dans tous les cas.
On peut voir que lorsque K=1, la similarité est très élevée et la plage est étroite, indiquant que le modèle généré à ce moment mémorise essentiellement les paramètres du modèle d'origine. À mesure que K augmente, la plage de similarité s’élargit également, ce qui indique que la nouvelle méthode peut générer des paramètres différents de ceux du modèle d’origine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que fait un ingénieur de développement Python ?
- Comment créer un projet vscode
- Pas aussi bon que GAN ! Google, DeepMind et d'autres ont publié des articles : les modèles de diffusion sont « copiés » directement à partir de l'ensemble de formation
- Associé au moteur physique, le modèle de diffusion GPT-4+ génère des vidéos réalistes, cohérentes et raisonnables
- Analyse complète du modèle de diffusion stable (y compris les principes, les techniques, les applications et les erreurs courantes)