
Maison >Périphériques technologiques >IA >Pas aussi bon que GAN ! Google, DeepMind et d'autres ont publié des articles : les modèles de diffusion sont « copiés » directement à partir de l'ensemble de formation
Pas aussi bon que GAN ! Google, DeepMind et d'autres ont publié des articles : les modèles de diffusion sont « copiés » directement à partir de l'ensemble de formation

- PHPzavant
- 2023-04-16 14:10:031322parcourir
L'année dernière, les modèles de génération d'images sont devenus populaires. Après un carnaval d'art populaire, des problèmes de droits d'auteur ont suivi.
Les modèles d'apprentissage profond comme DALL-E 2, Imagen et Stable Diffusion sont formés sur des centaines de millions de données Il n'y a aucun moyen de se débarrasser de l'influence de l'ensemble d'entraînement, mais si certaines images générées le sont . Complètement issu du set de formation ? Si l'image générée est très similaire à l'image originale, À qui appartiennent les droits d'auteur ?
Récemment, des chercheurs de nombreuses universités et entreprises renommées telles que Google, Deepmind et l'ETH Zurich ont publié conjointement un article. Ils ont découvert que le modèle de diffusion peut effectivement mémoriser les échantillons de l'ensemble de formation, et dans. Reproduire pendant le processus de génération.

Lien papier :https://arxiv.org/abs/2301.13188
Dans ce travail, les chercheurs montrent comment le modèle de diffusion se souvient dans ses données d'entraînement d'une seule image et reproduisez-le une fois généré.

L'article propose un pipeline generate-and-filter(generate-and-filter), qui extrait plus d'un millier d'exemples de formation à partir des modèles les plus avancés, couvrant les photos et les marques de personnes d'entreprise logo, etc Nous avons également formé des centaines de modèles de diffusion dans différents environnements pour analyser l'impact des différentes décisions en matière de modélisation et de données sur la confidentialité.
En général, les résultats expérimentaux montrent que le modèle de diffusion offre une protection de la vie privée bien pire pour l'ensemble de formation que les modèles génératifs précédents (tels que les GAN).
Je m'en souviens, mais pas beaucoup
Le modèle de diffusion de débruitage est un nouveau réseau neuronal génératif qui a émergé récemment. Il génère des images à partir de la distribution de formation via un processus de débruitage itératif, qui est meilleur que le GAN couramment utilisé auparavant. Ou la génération de modèles VAE est meilleure, et il est plus facile d'étendre la génération de modèles et de contrôler l'image, elle est donc rapidement devenue une méthode courante pour diverses générations d'images haute résolution.
Surtout après la sortie de DALL-E 2 par OpenAI, le modèle de diffusion est rapidement devenu populaire dans tout le domaine de la génération d'IA.
L'attrait des modèles de diffusion générative vient de leur capacité à synthétiser de nouvelles images ostensiblement différentes de tout ce qui se trouve dans l'ensemble de formation. En fait, les efforts de formation à grande échelle passés "n'ont pas trouvé de problèmes de surapprentissage", ont déclaré les chercheurs dans le domaine privé. domaine sensible a même proposé que le modèle de diffusion puisse « protéger la confidentialité des images réelles » en synthétisant des images.
Cependant, ces travaux reposent tous sur une hypothèse :C'est-à-dire que le modèle de diffusion ne mémorisera pas et ne régénérera pas les données d'entraînement, sinon il violerait la garantie de confidentialité et causerait de nombreux problèmes de généralisation du modèle et de falsification numérique.

Pour déterminer si l'image générée provient de l'ensemble d'entraînement, vous devez d'abord définir
qu'est-ce que la « mémorisation ».
Les travaux connexes précédents se sont principalement concentrés sur les modèles de langage textuel. Si le modèle peut récupérer textuellement une séquence enregistrée textuellement à partir de l'ensemble d'entraînement, alors cette séquence est appelée « extraction » et « mémoire » mais parce que ce travail est basé sur des valeurs élevées ; -images à haute résolution, donc la correspondance mot à mot des définitions de mémoire n'est pas adaptée.Ce qui suit est une mémoire basée sur des mesures de similarité d'images définies par les chercheurs.
Si la distance entre une image générée x et plusieurs échantillons dans l'ensemble d'apprentissage est inférieure à un seuil donné, alors l'échantillon est considéré comme obtenu à partir de l'ensemble d'apprentissage, c'est-à-dire la mémorisation eidétique. Ensuite, l'article a conçu une attaque d'extraction de donnéesMéthode : 1 Générer un grand nombre d'images Bien que la première étape soit très simple, elle est coûteuse en calcul. Très élevé : génère des images sous forme de boîte noire en utilisant l'invite sélectionnée comme entrée. Les chercheurs ont généré 500 images candidates pour chaque invite de texte afin d'augmenter les chances de découvrir des souvenirs. 2. Effectuez une inférence d'adhésion et marquez les images suspectées d'être générées en fonction de la mémoire de l'ensemble d'entraînement. La stratégie d'attaque par inférence de membres conçue par les chercheurs repose sur l'idée suivante : pour deux graines initiales aléatoires différentes, la probabilité de similarité entre les deux images générées par le modèle de diffusion sera très grande, et il est possible de être considéré en fonction de la mémoire sous la métrique de distance générée. Pour évaluer l'efficacité de l'attaque, les chercheurs ont sélectionné les 350 000 exemples les plus répétés de l'ensemble de données de formation et ont généré 500 images candidates pour chaque invite (un total de 175 millions d'images ont été générées). Triez d'abord toutes ces images générées en fonction de la distance moyenne entre les images dans la clique pour identifier celles qui ont probablement été générées par la mémorisation des données d'entraînement. Ensuite, ces images générées ont été comparées aux images d'entraînement, et chaque image a été marquée comme « extraite » et « non extraite ». Finalement, 94 images ont été trouvées soupçonnées d'être extraites de l'ensemble d'entraînement. Grâce à une analyse visuelle, les 1 000 premières images ont été manuellement étiquetées comme « mémorisées » ou « non mémorisées », et il a été constaté que 13 images avaient été générées en copiant des échantillons d'entraînement. Résultats de l'extraction
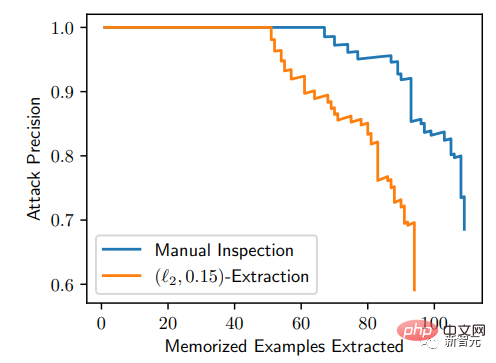
À partir de la courbe P-R, cette méthode d'attaque est très précise : sur 175 millions d'images générées, 50 images mémorisées peuvent être identifiées, et le taux de faux positifs est de 0 ; peut être extrait avec une précision supérieure à 50 %
Afin de mieux comprendre comment et pourquoi la mémoire se produit, les chercheurs ont également formé des centaines d'images comparatives sur le modèle de petite diffusion CIFAR10 pour analyser l'impact de la précision du modèle, des hyperparamètres, de l'augmentation, et la déduplication sur la confidentialité.

Diffusion vs GAN
Contrairement aux modèles de diffusion, les GAN ne sont pas explicitement formés pour mémoriser et reconstruire leurs ensembles de données de formation.
Les GAN sont constitués de deux réseaux de neurones concurrents : un générateur et un discriminateur. Le générateur reçoit également du bruit aléatoire en entrée, mais contrairement au modèle de diffusion, il doit convertir ce bruit en une image valide en un seul passage.
Dans le processus de formation du GAN, le discriminateur doit prédire si l'image provient du générateur, et le générateur doit s'améliorer pour tromper le discriminateur.
Donc, la différence entre les deux est que le générateur de GAN n'utilise que des informations indirectes sur les données d'entraînement pour l'entraînement (c'est-à-dire en utilisant le gradient du discriminateur) et ne reçoit pas directement les données d'entraînement en entrée.

1 million d'images d'entraînement générées de manière inconditionnelle extraites de différents modèles de génération pré-entraînés, puis le modèle GAN trié par FID (le plus bas est le mieux) est placé en haut, et le modèle de diffusion est placé en dessous.
Les résultats montrent que le modèle de diffusion mémorise plus que le modèle GAN, et que les meilleurs modèles génératifs (FID inférieur) ont tendance à mémoriser plus de données, c'est-à-dire que le modèle de diffusion est l'image la moins privée. La forme du modèle fuit plus de deux fois plus autant de données de formation que les GAN.

Et à partir des résultats ci-dessus, nous pouvons également constater que la technologie d'amélioration de la confidentialité existante ne fournit pas un compromis acceptable en matière de confidentialité et de performances. Si vous souhaitez améliorer la qualité de la génération, vous devez mémoriser davantage de données. dans l'ensemble de formation.

Dans l'ensemble, cet article met en évidence la tension entre les modèles génératifs de plus en plus puissants et la confidentialité des données, et soulève des questions sur le fonctionnement des modèles de diffusion et sur la manière dont ils peuvent être déployés de manière responsable.
Problèmes de droit d'auteur
Techniquement parlant, la reconstruction est l'avantage du modèle de diffusion mais du point de vue du droit d'auteur, la reconstruction est sa faiblesse ;
En raison de la similitude excessive entre les images générées par le modèle de diffusion et les données de formation, les artistes ont divers différends sur leurs problèmes de droits d'auteur.
Par exemple, il est interdit à l'IA d'utiliser ses propres œuvres pour la formation, les œuvres publiées ajoutent un grand nombre de filigranes, etc. ; et Stable Diffusion a également annoncé qu'elle prévoyait d'utiliser uniquement des ensembles de données de formation contenant du contenu autorisé dans le étape suivante et fournit un mécanisme de sortie d'artiste.
Nous sommes également confrontés à ce problème dans le domaine de la PNL. Certains internautes ont déclaré que des millions de mots de texte ont été publiés depuis 1993, et que toutes les IA, y compris ChatGPT-3, sont formées sur le « contenu volé », en utilisant des modèles génératifs basés sur l'IA. est contraire à l’éthique.
Bien que de nombreux articles dans le monde soient plagiés, pour les gens ordinaires, le plagiat n'est qu'un raccourci inutile, mais pour les créateurs, le contenu plagié est leur travail acharné.
Le modèle de diffusion aura-t-il encore des avantages à l'avenir ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI