Maintenant, le robot a appris des tâches précises de contrôle d'usine.
 Ces dernières années, des progrès significatifs ont été réalisés dans le domaine des technologies d'apprentissage par renforcement des robots, comme la marche des quadrupèdes, la préhension, la manipulation adroite, etc., mais la plupart d'entre eux se limitent à la démonstration en laboratoire. scène. L’application généralisée de la technologie d’apprentissage par renforcement robotique aux environnements de production réels se heurte encore à de nombreux défis, ce qui limite dans une certaine mesure sa portée d’application dans des scénarios réels. Dans le processus d'application pratique de la technologie d'apprentissage par renforcement, il est nécessaire de surmonter plusieurs problèmes complexes, notamment la configuration du mécanisme de récompense, la réinitialisation de l'environnement, l'amélioration de l'efficacité des échantillons et la garantie de la sécurité des actions. Les experts du secteur soulignent que la résolution des nombreux problèmes liés à la mise en œuvre réelle de la technologie d’apprentissage par renforcement est aussi importante que l’innovation continue de l’algorithme lui-même. Face à ce défi, des chercheurs de l'Université de Californie à Berkeley, de l'Université de Stanford, de l'Université de Washington et de Google ont développé conjointement un cadre logiciel open source appelé Efficient Robot Reinforcement Learning Suite (SERL), dédié à la promotion technologie d'apprentissage par renforcement Largement utilisée dans les applications robotiques pratiques.
Ces dernières années, des progrès significatifs ont été réalisés dans le domaine des technologies d'apprentissage par renforcement des robots, comme la marche des quadrupèdes, la préhension, la manipulation adroite, etc., mais la plupart d'entre eux se limitent à la démonstration en laboratoire. scène. L’application généralisée de la technologie d’apprentissage par renforcement robotique aux environnements de production réels se heurte encore à de nombreux défis, ce qui limite dans une certaine mesure sa portée d’application dans des scénarios réels. Dans le processus d'application pratique de la technologie d'apprentissage par renforcement, il est nécessaire de surmonter plusieurs problèmes complexes, notamment la configuration du mécanisme de récompense, la réinitialisation de l'environnement, l'amélioration de l'efficacité des échantillons et la garantie de la sécurité des actions. Les experts du secteur soulignent que la résolution des nombreux problèmes liés à la mise en œuvre réelle de la technologie d’apprentissage par renforcement est aussi importante que l’innovation continue de l’algorithme lui-même. Face à ce défi, des chercheurs de l'Université de Californie à Berkeley, de l'Université de Stanford, de l'Université de Washington et de Google ont développé conjointement un cadre logiciel open source appelé Efficient Robot Reinforcement Learning Suite (SERL), dédié à la promotion technologie d'apprentissage par renforcement Largement utilisée dans les applications robotiques pratiques.
- Page d'accueil du projet : https://serl-robot.github.io/
- Code source ouvert : https://github.com/rail-berkeley/serl
- Titre de l'article : SERL : un logiciel Suite for Sample-Efficient Robotic Reinforcement Learning
Le framework SERL comprend principalement les composants suivants :1. Apprentissage par renforcement efficaceDans le domaine de l'apprentissage par renforcement, les agents intelligents (tels que robots) réussir Interagissez avec l’environnement pour apprendre à effectuer des tâches. Il apprend un ensemble de stratégies conçues pour maximiser les récompenses cumulées en essayant divers comportements et en obtenant des signaux de récompense basés sur les résultats comportementaux. SERL utilise l'algorithme RLPD pour permettre aux robots d'apprendre simultanément des interactions en temps réel et des données hors ligne précédemment collectées, réduisant ainsi considérablement le temps de formation nécessaire aux robots pour maîtriser de nouvelles compétences. 2. Diverses méthodes d'attribution de récompensesSERL propose une variété de méthodes d'attribution de récompenses, permettant aux développeurs de personnaliser la structure des récompenses en fonction des besoins de tâches spécifiques. Par exemple, les tâches d'installation à position fixe peuvent avoir des récompenses adaptées à la position du robot, et les tâches plus complexes peuvent utiliser des classificateurs ou VICE pour apprendre un mécanisme de récompense précis. Cette flexibilité permet de guider précisément le robot pour apprendre la stratégie la plus efficace pour une tâche spécifique. 3. Aucune fonction de reproductionLes algorithmes d'apprentissage des robots traditionnels doivent réinitialiser régulièrement l'environnement pour le prochain cycle d'apprentissage interactif. Dans de nombreuses tâches, cela ne peut pas être effectué automatiquement. Les capacités d'apprentissage sans renforcement fournies par SERL entraînent simultanément les deux politiques avant-arrière, fournissant des réinitialisations d'environnement l'une pour l'autre. 4. Interface de contrôle du robot SERL fournit une série d'interfaces d'environnement Gym pour les tâches du manipulateur Franka à titre d'exemples standard, permettant aux utilisateurs d'étendre facilement SERL à différents bras robotiques. 5. Contrôleur d'impédanceAfin de garantir que le robot puisse explorer et fonctionner en toute sécurité et avec précision dans des environnements physiques complexes, SERL fournit un contrôleur d'impédance spécial pour le bras robotique Franka, tout en garantissant la précision au niveau en même temps, assurez-vous qu'aucun couple excessif n'est généré après un contact avec des objets externes. Grâce à la combinaison de ces technologies et méthodes, SERL réduit considérablement le temps de formation tout en maintenant un taux de réussite et une robustesse élevés, permettant aux robots d'apprendre à accomplir des tâches complexes en peu de temps et d'être appliqués efficacement dans le monde réel. Figure 1, 2 : Comparaison du taux de réussite et du nombre de battements entre SERL et les méthodes de clonage comportemental dans diverses tâches. Avec une quantité de données similaire, le taux de réussite du SERL est plusieurs fois supérieur (jusqu'à 10 fois) à celui des clones, et la fréquence de battement est au moins deux fois plus rapide.
1. Assemblage de composants PCB : L'assemblage de composants perforés sur des cartes PCB est une tâche robotique courante mais difficile. Les broches des composants électroniques sont très faciles à plier et la tolérance entre la position du trou et la broche est très faible, ce qui nécessite que le robot soit à la fois précis et doux lors de l'assemblage. Avec seulement 21 minutes d’apprentissage autonome, SERL a permis au robot d’atteindre un taux d’achèvement des tâches de 100 %. Même face à des interférences inconnues telles que la position du circuit imprimé en mouvement ou la ligne de vue partiellement bloquée, le robot peut terminer le travail d'assemblage de manière stable.
: Figure 3, 4, 5 : Lors de l'exécution de la mission du composant du circuit imprimé, le robot peut gérer les diverses interférences qui n'ont pas été rencontrées lors de la phase de formation et terminer la tâche en douceur.
2. Acheminement des câbles :
Dans le processus d'assemblage de nombreux équipements mécaniques et électroniques, nous devons installer les câbles avec précision le long d'un chemin spécifique. Cette tâche nécessite précision et adaptabilité. Des exigences élevées. ont été faites. Étant donné que les câbles flexibles sont sujets à la déformation pendant le processus de câblage et que le processus de câblage peut être soumis à diverses perturbations, telles qu'un mouvement accidentel du câble ou des changements de position du support, il est difficile de gérer l'utilisation de câbles non traditionnels traditionnels. méthodes d'apprentissage. SERL est capable d’atteindre un taux de réussite de 100 % en seulement 30 minutes. Même lorsque la position de la pince est différente de celle qu'elle était pendant la formation, le robot est capable de généraliser les compétences acquises et de s'adapter aux nouveaux défis de câblage, garantissant ainsi une exécution correcte du travail de câblage. : Figure 6, 7, 8 : La robotique peut faire passer directement le câble à travers le clip, ce qui est différent de l'entraînement pendant l'entraînement sans entraînement plus particulier.
3. Opérations de saisie et de placement d'objets :
Dans la gestion d'entrepôt ou dans le secteur de la vente au détail, les robots doivent souvent déplacer des articles d'un endroit à un autre, ce qui nécessite que le robot soit capable de les identifier et de les transporter. éléments spécifiques. Au cours du processus de formation par apprentissage par renforcement, il est difficile de réinitialiser automatiquement les objets sous-actionnés. Tirant parti des capacités d'apprentissage par renforcement sans réinitialisation de SERL, le robot a appris simultanément deux politiques avec un taux de réussite de 100/100 en 1 heure et 45 minutes. Utilisez la stratégie avant pour placer les objets de la boîte A dans la boîte B, puis utilisez la stratégie arrière pour remettre les objets de la boîte B dans la boîte A.
Figures 9, 10, 11 : SERL a entraîné deux ensembles de stratégies, une pour transporter des objets de droite à gauche et une pour déplacer des objets de gauche vers la droite. Le robot atteint non seulement un taux de réussite de 100 % sur les objets d'entraînement, mais peut également manipuler intelligemment des objets qu'il n'a jamais vus auparavant. Jianlan Luo est actuellement chercheur postdoctoral au Département d'électronique et d'informatique de l'Université de Californie à Berkeley. au Berkeley Artificial Intelligence Center (BAIR) en collaboration avec le professeur Sergey Levine. Ses principaux intérêts de recherche portent sur l'apprentissage automatique, la robotique et le contrôle optimal. Avant de retourner au monde universitaire, il était chercheur à temps plein chez Google X, en collaboration avec le professeur Stefan Schaal. Avant cela, il a obtenu une maîtrise en informatique et un doctorat en génie mécanique de l'Université de Californie à Berkeley ; durant cette période, il a travaillé avec le professeur Alice Agogino et le professeur Pieter Abbeel. Il a également été chercheur invité au siège de Deepmind à Londres. Il est diplômé de l'Université de Californie à Berkeley, avec une spécialisation en informatique et en mathématiques appliquées. Actuellement, il mène des recherches au laboratoire RAIL dirigé par le professeur Sergey Levine. Il s'intéresse vivement au domaine de l'apprentissage robotique, en se concentrant sur le développement de méthodes permettant aux robots d'acquérir rapidement et largement des compétences de manipulation adroites dans le monde réel. Il est étudiant en quatrième année de premier cycle avec spécialisation en génie électrique et informatique à l'Université de Californie à Berkeley. Actuellement, il mène des recherches au laboratoire RAIL dirigé par le professeur Sergey Levine. Ses intérêts de recherche se situent à l’intersection de la robotique et de l’apprentissage automatique, visant à construire des systèmes de contrôle autonomes hautement robustes et capables de généralisation. Il est ingénieur de recherche au laboratoire Berkeley RAIL, supervisé par le professeur Sergey Levine. Il a auparavant obtenu sa licence à l'Université technologique de Nanyang, à Singapour, et a complété sa maîtrise au Georgia Institute of Technology, aux États-Unis. Avant cela, il était membre de l’Open Robotics Foundation. Son travail se concentre sur les applications concrètes des technologies logicielles d’apprentissage automatique et de robotique. Il a obtenu son doctorat en génie mécanique et intelligence artificielle de l'Université technique de Munich, en Allemagne, en 1991. Il est chercheur postdoctoral au Département des sciences du cerveau et des sciences cognitives et au Laboratoire d'intelligence artificielle du MIT, chercheur invité au Laboratoire de recherche sur le traitement de l'information humaine ATR au Japon et professeur adjoint adjoint au Département de kinésiologie du Georgia Institute of Technology. et l'Université d'État de Pennsylvanie aux États-Unis. Il a également été chef du groupe d'apprentissage informatique au cours du projet japonais ERATO, le Jawa Kinetic Brain Project (ERATO/JST). En 1997, il est devenu professeur d'informatique, de neurosciences et de génie biomédical à l'USC et a été promu professeur titulaire. Ses intérêts de recherche comprennent des sujets tels que les statistiques et l'apprentissage automatique, les réseaux neuronaux et l'intelligence artificielle, les neurosciences computationnelles, l'imagerie fonctionnelle du cerveau, la dynamique non linéaire, la théorie du contrôle non linéaire, la robotique et les robots biomimétiques. Il est l'un des directeurs fondateurs de l'Institut Max Planck pour les systèmes intelligents en Allemagne, où il a dirigé le département de mouvement autonome pendant de nombreuses années. Il est actuellement scientifique en chef chez Intrinsic, la nouvelle filiale robotique d'Alphabet [Google]. Stefan Schaal est membre de l'IEEE. Elle est professeure adjointe d'informatique et de génie électrique à l'Université de Stanford. Son laboratoire, IRIS, explore l'intelligence grâce à l'interaction robotique à grande échelle et fait partie de SAIL et du groupe ML. Elle est également membre de l'équipe Google Brain. Elle s'intéresse à la capacité des robots et autres agents intelligents à développer un large éventail de comportements intelligents grâce à l'apprentissage et à l'interaction. Elle a précédemment obtenu un doctorat en informatique de l'Université de Californie à Berkeley, ainsi qu'un baccalauréat en génie électrique et en informatique du Massachusetts Institute of Technology. Il est professeur adjoint à la Paul G. Allen School of Computer Science and Engineering de l'Université de Washington, où il dirige le WEIRD Lab. Auparavant, il était chercheur postdoctoral au MIT, travaillant avec Russ Tedrake et Pulkit Agarwal. Il a complété son doctorat sur l'apprentissage automatique et la robotique au BAIR, UC Berkeley, sous la direction des professeurs Sergey Levine et Pieter Abbeel. Avant cela, il a également obtenu son baccalauréat à l'Université de Californie à Berkeley. Son principal objectif de recherche est de développer des algorithmes permettant aux systèmes robotiques d’apprendre à effectuer des tâches complexes dans divers environnements non structurés, tels que les bureaux et les maisons.Il est professeur agrégé au Département de génie électrique et d'informatique de l'Université de Californie à Berkeley. Ses recherches portent sur les algorithmes qui permettent aux agents autonomes d'apprendre des comportements complexes, en particulier sur les méthodes générales qui permettent à tout système autonome d'apprendre à résoudre n'importe quelle tâche. Les applications de ces méthodes incluent la robotique, ainsi que toute une série d’autres domaines où une prise de décision autonome est requise. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


 Ces dernières années, des progrès significatifs ont été réalisés dans le domaine des technologies d'apprentissage par renforcement des robots, comme la marche des quadrupèdes, la préhension, la manipulation adroite, etc., mais la plupart d'entre eux se limitent à la démonstration en laboratoire. scène. L’application généralisée de la technologie d’apprentissage par renforcement robotique aux environnements de production réels se heurte encore à de nombreux défis, ce qui limite dans une certaine mesure sa portée d’application dans des scénarios réels. Dans le processus d'application pratique de la technologie d'apprentissage par renforcement, il est nécessaire de surmonter plusieurs problèmes complexes, notamment la configuration du mécanisme de récompense, la réinitialisation de l'environnement, l'amélioration de l'efficacité des échantillons et la garantie de la sécurité des actions. Les experts du secteur soulignent que la résolution des nombreux problèmes liés à la mise en œuvre réelle de la technologie d’apprentissage par renforcement est aussi importante que l’innovation continue de l’algorithme lui-même.
Ces dernières années, des progrès significatifs ont été réalisés dans le domaine des technologies d'apprentissage par renforcement des robots, comme la marche des quadrupèdes, la préhension, la manipulation adroite, etc., mais la plupart d'entre eux se limitent à la démonstration en laboratoire. scène. L’application généralisée de la technologie d’apprentissage par renforcement robotique aux environnements de production réels se heurte encore à de nombreux défis, ce qui limite dans une certaine mesure sa portée d’application dans des scénarios réels. Dans le processus d'application pratique de la technologie d'apprentissage par renforcement, il est nécessaire de surmonter plusieurs problèmes complexes, notamment la configuration du mécanisme de récompense, la réinitialisation de l'environnement, l'amélioration de l'efficacité des échantillons et la garantie de la sécurité des actions. Les experts du secteur soulignent que la résolution des nombreux problèmes liés à la mise en œuvre réelle de la technologie d’apprentissage par renforcement est aussi importante que l’innovation continue de l’algorithme lui-même. 
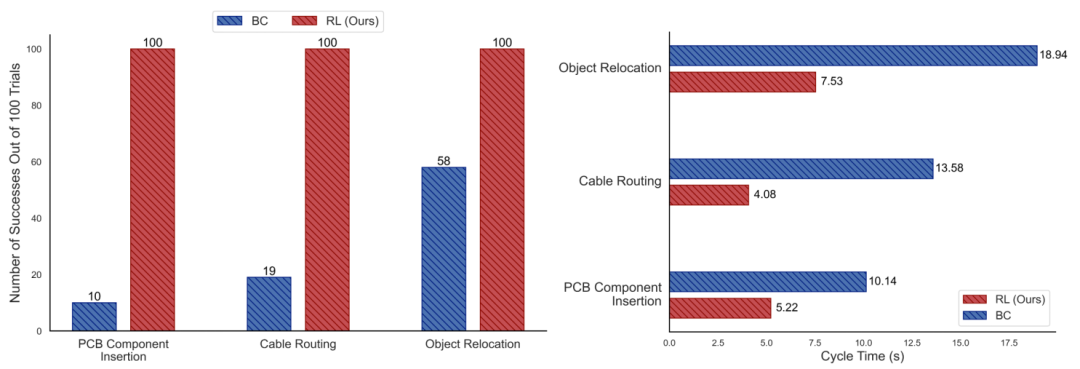 Figure 1, 2 : Comparaison du taux de réussite et du nombre de battements entre SERL et les méthodes de clonage comportemental dans diverses tâches. Avec une quantité de données similaire, le taux de réussite du SERL est plusieurs fois supérieur (jusqu'à 10 fois) à celui des clones, et la fréquence de battement est au moins deux fois plus rapide.
Figure 1, 2 : Comparaison du taux de réussite et du nombre de battements entre SERL et les méthodes de clonage comportemental dans diverses tâches. Avec une quantité de données similaire, le taux de réussite du SERL est plusieurs fois supérieur (jusqu'à 10 fois) à celui des clones, et la fréquence de battement est au moins deux fois plus rapide. 




 Dans la gestion d'entrepôt ou dans le secteur de la vente au détail, les robots doivent souvent déplacer des articles d'un endroit à un autre, ce qui nécessite que le robot soit capable de les identifier et de les transporter. éléments spécifiques. Au cours du processus de formation par apprentissage par renforcement, il est difficile de réinitialiser automatiquement les objets sous-actionnés. Tirant parti des capacités d'apprentissage par renforcement sans réinitialisation de SERL, le robot a appris simultanément deux politiques avec un taux de réussite de 100/100 en 1 heure et 45 minutes. Utilisez la stratégie avant pour placer les objets de la boîte A dans la boîte B, puis utilisez la stratégie arrière pour remettre les objets de la boîte B dans la boîte A.
Dans la gestion d'entrepôt ou dans le secteur de la vente au détail, les robots doivent souvent déplacer des articles d'un endroit à un autre, ce qui nécessite que le robot soit capable de les identifier et de les transporter. éléments spécifiques. Au cours du processus de formation par apprentissage par renforcement, il est difficile de réinitialiser automatiquement les objets sous-actionnés. Tirant parti des capacités d'apprentissage par renforcement sans réinitialisation de SERL, le robot a appris simultanément deux politiques avec un taux de réussite de 100/100 en 1 heure et 45 minutes. Utilisez la stratégie avant pour placer les objets de la boîte A dans la boîte B, puis utilisez la stratégie arrière pour remettre les objets de la boîte B dans la boîte A.