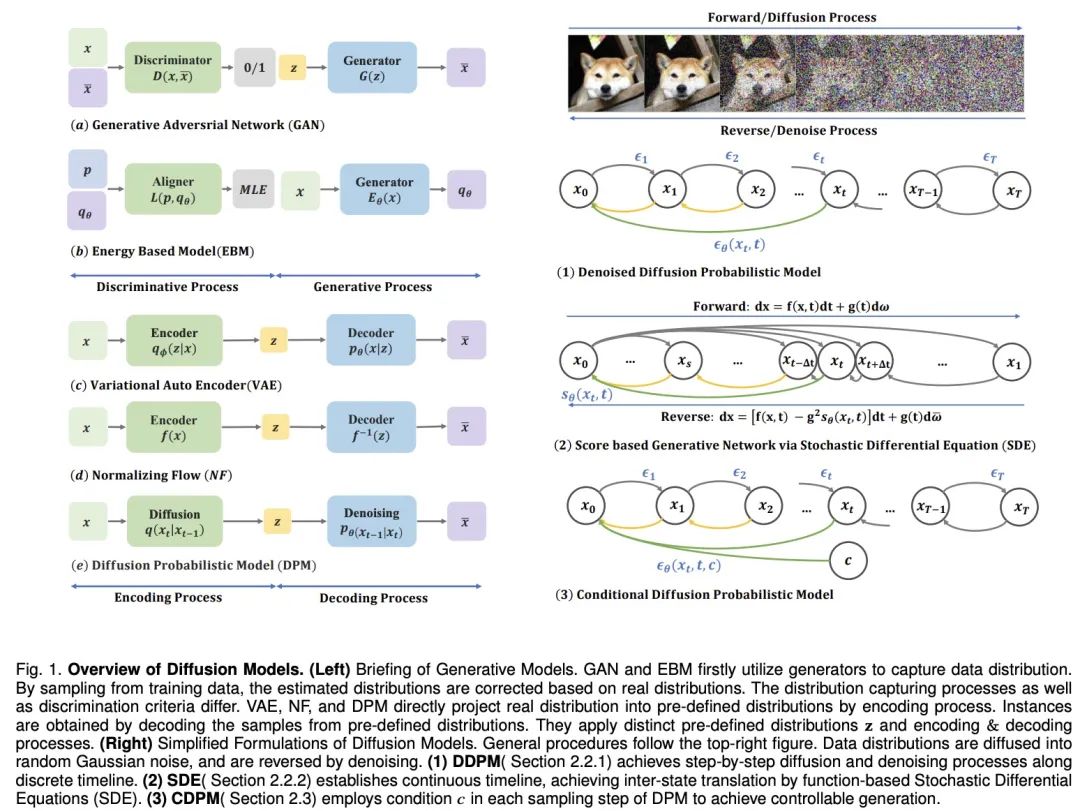
Pour doter les machines de l'imagination humaine, des modèles génératifs profonds ont fait des progrès significatifs. Ces modèles créent des échantillons réalistes, en particulier le modèle de diffusion, qui fonctionne bien dans plusieurs domaines. Le modèle de diffusion résout les limites d'autres modèles, tels que le problème d'alignement de distribution postérieure des VAE, l'instabilité des GAN, la complexité de calcul des EBM et le problème de contrainte de réseau des NF. Par conséquent, les modèles de diffusion ont attiré beaucoup d’attention dans des aspects tels que la vision par ordinateur et le traitement du langage naturel. Le modèle de diffusion se compose de deux processus : le processus direct et le processus inverse. Le processus direct transforme les données en une simple distribution a priori, tandis que le processus inverse inverse ce changement et génère les données à l'aide d'un réseau neuronal entraîné pour simuler des équations différentielles. Comparé à d'autres modèles, le modèle de diffusion offre un objectif de formation plus stable et de meilleurs résultats de génération. 
Cependant, le processus d'échantillonnage du modèle de diffusion s'accompagne de raisonnements et d'évaluations répétés. Ce processus est confronté à des défis tels que l'instabilité, les exigences informatiques de grande dimension et l'optimisation de vraisemblance complexe. Les chercheurs ont proposé diverses solutions à cet effet, telles que l'amélioration des solveurs ODE/SDE et l'adoption de stratégies de distillation de modèles pour accélérer l'échantillonnage, ainsi que de nouveaux processus avancés pour améliorer la stabilité et réduire la dimensionnalité. Récemment, la langue et la littérature chinoises de Hong Kong, l'université de West Lake, le MIT et le laboratoire Zhijiang ont publié un article de synthèse intitulé « Une enquête sur les modèles de diffusion générative » sur IEEE TKDE, qui discutait des derniers progrès dans les modèles de diffusion de quatre aspects : accélération de l'échantillonnage, conception de processus, optimisation de la vraisemblance et pontage de distribution. L'analyse fournit également un examen approfondi du succès des modèles de diffusion dans différents domaines d'application tels que la synthèse d'images, la génération vidéo, la modélisation 3D, l'analyse médicale et la génération de texte. A travers ces cas d’application, la praticité et le potentiel du modèle de diffusion dans le monde réel sont démontrés.
- Adresse papier : https://arxiv.org/pdf/2209.02646.pdf
- Adresse du projet : https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab= fichier readme-ov
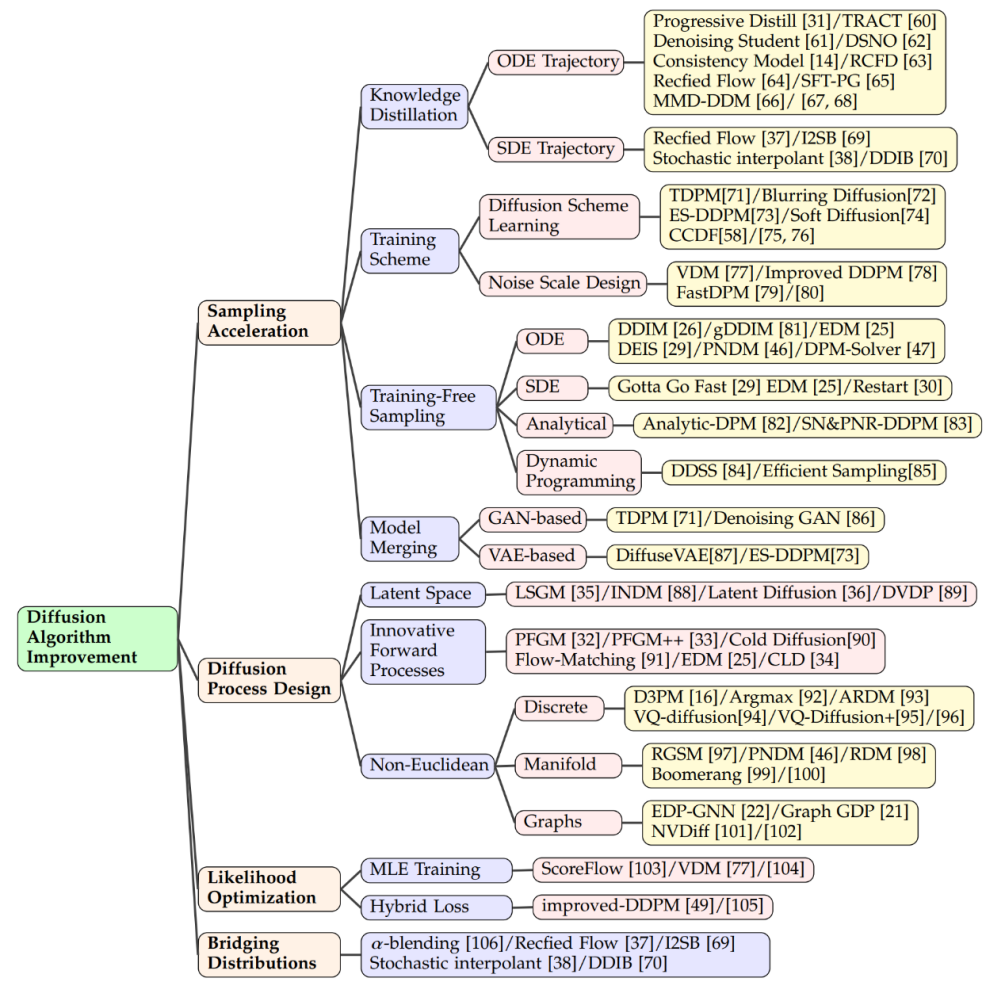
Amélioration de l'algorithmeAccélération de l'échantillonnage
Dans le domaine du modèle de diffusion, améliorer vitesse d'échantillonnage L'une des technologies clés est la distillation des connaissances. Ce processus consiste à extraire des connaissances d'un modèle vaste et complexe et à les transférer vers un modèle plus petit et plus efficace. Par exemple, en utilisant la distillation des connaissances, nous pouvons simplifier la trajectoire d'échantillonnage du modèle afin que la distribution cible soit approchée avec une plus grande efficacité à chaque étape. Salimans et al.
Améliorer la méthode de formation est aussi un moyen d'améliorer l'efficacité de l'échantillonnage. Certaines recherches se concentrent sur l'apprentissage de nouveaux schémas de diffusion, dans lesquels les données ne sont plus simplement enrichies de bruit gaussien, mais mappées sur l'espace latent par des méthodes plus complexes. Certaines de ces méthodes se concentrent sur l'optimisation du processus de décodage inverse, comme l'ajustement de la profondeur de codage, tandis que d'autres explorent de nouvelles conceptions d'échelle de bruit afin que l'ajout de bruit ne soit plus statique, mais devienne une variable pouvant être modifiée au cours du processus de formation. .paramètres appris. - Échantillonnage sans formation
En plus de former de nouveaux modèles pour améliorer l'efficacité, il existe également des techniques dédiées à accélérer le processus d'échantillonnage de modèles de diffusion déjà pré-entraînés. L'accélération ODE est l'une de ces techniques qui utilise les ODE pour décrire le processus de diffusion, permettant ainsi à l'échantillonnage de se dérouler plus rapidement. Par exemple, DDIM est une méthode qui utilise l'ODE pour l'échantillonnage, et des recherches ultérieures ont introduit des solveurs ODE plus efficaces, tels que PNDM et EDM, pour améliorer encore la vitesse d'échantillonnage. - Combinée avec d'autres modèles génératifs
De plus, certains chercheurs ont proposé des méthodes analytiques pour accélérer l'échantillonnage. Ces méthodes tentent de trouver un moyen de récupérer directement des données propres à partir de données bruitées sans itération. .Solution analytique. Ces méthodes incluent Analytic-DPM et sa version améliorée Analytic-DPM++, qui fournissent une stratégie d'échantillonnage rapide et précise. Conception du processus de diffusion
Les modèles de diffusion en espace latent tels que LSGM et INDM combinent des modèles VAE ou à flux normalisé pour débruiter grâce à une pondération partagée Fr la perte de correspondance actionnelle est utilisé pour optimiser le codec et le modèle de diffusion, de sorte que l'optimisation de l'ELBO ou du log-vraisemblance vise à construire un espace latent facile à apprendre et à générer des échantillons. Par exemple, Stable Diffusion utilise d'abord un VAE pour apprendre un espace latent, puis entraîne un modèle de diffusion pour accepter la saisie de texte. DVDP ajuste dynamiquement les composantes orthogonales de l'espace des pixels lors de la perturbation de l'image. - Processus avancé innovant
Afin d'améliorer l'efficacité et la solidité du modèle génératif, les chercheurs ont exploré de nouvelles conceptions de processus avancés. Le modèle de génération de champ de Poisson traite les données comme des charges, dirigeant une distribution simple vers la distribution des données le long des lignes de champ électrique, ce qui fournit un rétro-échantillonnage plus puissant que les modèles de diffusion traditionnels. PFGM++ pousse ce concept plus loin dans les variables de grande dimension. Le modèle de diffusion Langevin à amortissement critique de Dockhorn et al. simplifie l'apprentissage des fonctions fractionnaires des distributions de vitesse conditionnelles à l'aide de variables de vitesse dans la dynamique hamiltonienne.
Dans le modèle de diffusion de données spatiales discrètes (telles que le texte, les données catégorielles), D3PM définit le processus avancé de l'espace discret. Sur la base de cette méthode, la recherche a été étendue à la génération de texte en langage, à la segmentation de graphiques et à la compression sans perte. Dans les défis multimodaux, les données vectorielles quantifiées sont converties en codes, affichant des résultats supérieurs. Les données de collecte dans les variétés riemanniennes, telles que la robotique et la modélisation des protéines, nécessitent que l'échantillonnage par diffusion soit incorporé dans la variété riemannienne. Des combinaisons de réseaux de neurones graphiques et de théorie de la diffusion, telles que EDP-GNN et GraphGDP, traitent les données graphiques pour capturer l'invariance de permutation. Optimisation de la vraisemblance Bien que les modèles de diffusion optimisent ELBO, l'optimisation de la vraisemblance reste un défi, en particulier pour les modèles de diffusion en temps continu. Des méthodes telles que ScoreFlow et les modèles de diffusion variationnelle (VDM) établissent le lien entre la formation MLE et les objectifs du DSM, dans lesquels le théorème de Girsanov joue un rôle clé. Le modèle probabiliste de diffusion de débruitage amélioré (DDPM) propose un objectif d'apprentissage hybride qui combine des limites inférieures variationnelles et DSM, ainsi qu'une technique de reparamétrage simple.Les modèles de diffusion fonctionnent bien dans la conversion de distributions gaussiennes en distributions complexes, mais présentent des défis lors de la jonction de distributions arbitraires. Les méthodes alpha-hybrides créent des ponts déterministes en mélangeant et en mélangeant de manière itérative. Le flux de correction ajoute des étapes supplémentaires pour corriger le chemin du pont. Une autre méthode consiste à réaliser la connexion entre deux distributions via ODE, et la méthode du pont de Schrödinger ou distribution gaussienne comme point de connexion intermédiaire est également à l'étude.
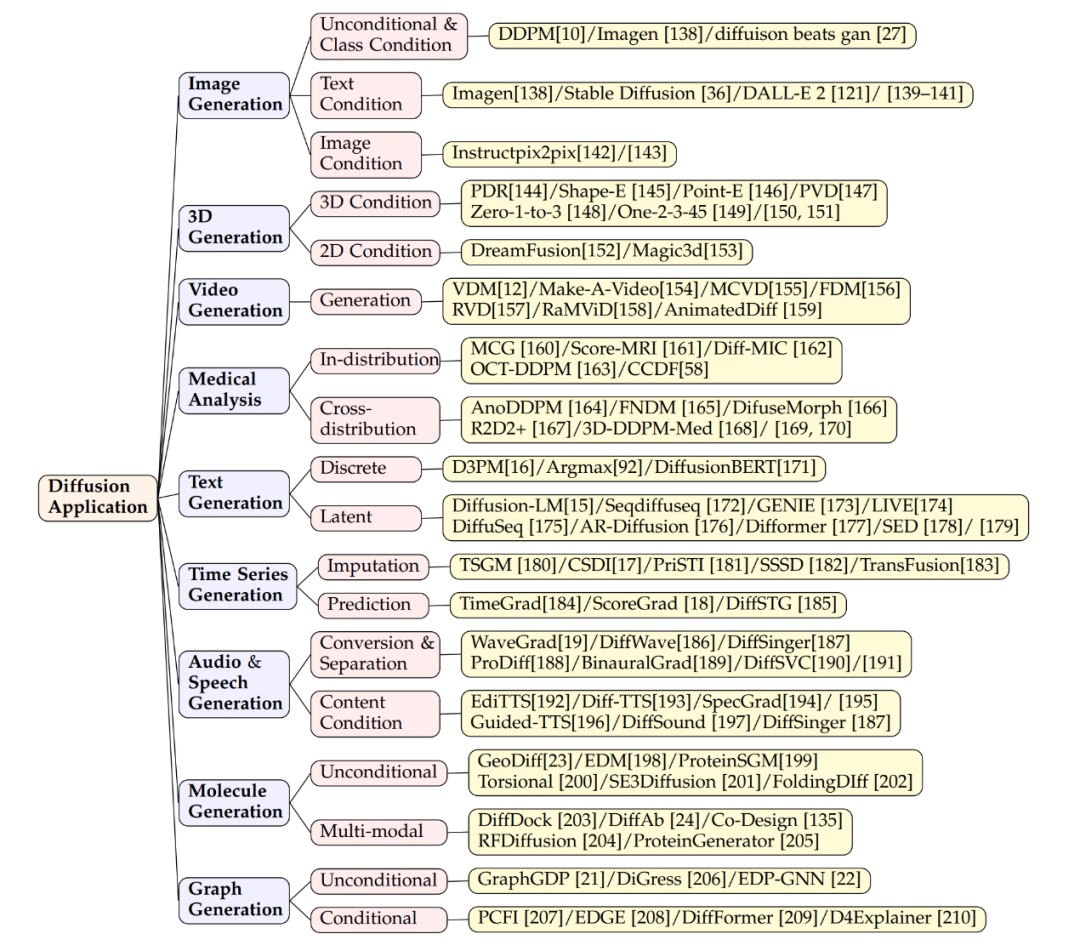
Le modèle de diffusion est très efficace dans la génération d'images. Il peut non seulement générer des images ordinaires, mais également effectuer des tâches complexes, telles que la conversion de texte en images. Des modèles tels que Imagen, Stable Diffusion et DALL-E 2 font preuve d'une grande compétence à cet égard. Ils utilisent une structure de modèle de diffusion, combinée à des techniques de couche d'attention croisée, pour intégrer des informations textuelles dans les images générées. En plus de générer de nouvelles images, ces modèles peuvent éditer des images sans nécessiter de recyclage. L'édition est réalisée en ajustant les couches d'attention (clés, valeurs, matrices d'attention). Par exemple, ajouter de nouveaux concepts en ajustant les cartes de fonctionnalités pour modifier les éléments de l'image ou en introduisant de nouvelles intégrations de texte. Des recherches sont en cours pour garantir que le modèle prête attention à tous les mots-clés du texte lors de sa génération afin de garantir que l'image reflète fidèlement la description. Les modèles de diffusion peuvent également gérer des entrées conditionnelles basées sur des images, telles que des images sources, des cartes de profondeur ou des squelettes humains, en codant et en intégrant ces fonctionnalités pour guider la génération d'images. Certaines études ajoutent des fonctionnalités de codage d'image source à la couche de départ du modèle pour réaliser une édition image à image, qui s'applique également aux scènes dans lesquelles des cartes de profondeur, une détection de contours ou des squelettes sont utilisés comme conditions. En termes de génération 3D, il existe deux méthodes principales à travers les modèles de diffusion. La première consiste à entraîner des modèles directement sur des données 3D, qui ont été appliquées efficacement à diverses représentations 3D telles que NeRF, les nuages de points ou les voxels. Par exemple, des chercheurs ont montré comment générer directement des nuages de points d’objets 3D. Afin d'améliorer l'efficacité de l'échantillonnage, certaines études ont introduit une représentation hybride point-voxel ou une synthèse d'image comme condition supplémentaire pour la génération de nuages de points. D'autre part, certaines études utilisent des modèles de diffusion pour traiter les représentations NeRF d'objets 3D, synthétiser de nouvelles vues et optimiser les représentations NeRF en entraînant des modèles de diffusion conditionnelles en perspective. La deuxième approche met l'accent sur l'utilisation de connaissances préalables sur les modèles de diffusion 2D pour générer du contenu 3D. Par exemple, le projet Dreamfusion utilise des cibles d'échantillonnage de distillation de scores pour extraire le NeRF d'un modèle texte-image pré-entraîné et obtient des images rendues à faible perte grâce à un processus d'optimisation de descente de gradient. Ce processus a également été étendu pour accélérer la génération. Les modèles de diffusion vidéo sont des extensions des modèles de diffusion d'images 2D, ils génèrent des séquences vidéo en ajoutant une dimension temporelle. L'idée de base de cette approche est d'ajouter des couches temporelles à la structure 2D existante pour modéliser la continuité et les dépendances entre les images vidéo. Des travaux connexes montrent comment utiliser des modèles de diffusion vidéo pour générer du contenu dynamique, tels que Make-A-Video, AnimatedDiff et d'autres modèles. Plus précisément, le modèle RaMViD utilise un réseau neuronal convolutif 3D pour étendre le modèle de diffusion d'images à la vidéo et développe une série de techniques conditionnelles spécifiques à la vidéo. Les modèles de diffusion aident à résoudre le défi de l'obtention d'ensembles de données de haute qualité en analyse médicale, en particulier en imagerie médicale. Ces modèles ont réussi à améliorer la résolution, la classification et le traitement du bruit des images grâce à leurs puissantes capacités de capture d’images. Par exemple, Score-MRI et Diff-MIC utilisent des techniques avancées pour accélérer la reconstruction des images IRM et permettre une classification plus précise. MCG utilise de multiples corrections dans la super-résolution des images CT, améliorant ainsi la vitesse et la précision de la reconstruction. En termes de génération d'images rares, le modèle peut convertir entre différents types d'images grâce à des techniques spécifiques. Par exemple, FNDM et DiffuseMorph sont utilisés respectivement pour la détection des anomalies cérébrales et l'enregistrement des images IRM. Certaines nouvelles méthodes synthétisent des ensembles de données d'entraînement à partir d'un petit nombre d'échantillons de haute qualité, comme un modèle utilisant 31 740 échantillons qui a synthétisé un ensemble de données de 100 000 instances et a obtenu des scores FID très faibles. La technologie de génération de texte est un pont important entre les humains et l'IA, et peut créer un langage fluide et naturel. Les modèles de langage autorégressifs génèrent du texte avec une forte cohérence mais sont lents, tandis que les modèles de diffusion peuvent générer du texte rapidement mais avec une cohérence relativement faible. Les deux méthodes principales sont la génération discrète et la génération latente. La génération discrète s'appuie sur des techniques avancées et des modèles pré-entraînés ; par exemple, D3PM et Argmax traitent les mots comme des vecteurs catégoriels, tandis que DiffusionBERT combine des modèles de diffusion avec des modèles de langage pour améliorer la génération de texte. La génération latente génère du texte dans l'espace latent des jetons. Par exemple, des modèles tels que LM-Diffusion et GENIE fonctionnent bien dans diverses tâches, montrant le potentiel des modèles de diffusion dans la génération de texte. Les modèles de diffusion devraient améliorer les performances du traitement du langage naturel, s'intégrer à de grands modèles de langage et permettre la génération multimodale. Génération de séries chronologiquesLa modélisation de données de séries chronologiques est une technologie clé pour la prévision et l'analyse dans des domaines tels que la finance, la science du climat et la médecine. Les modèles de diffusion ont été utilisés pour la génération de données de séries chronologiques en raison de leur capacité à générer des échantillons de données de haute qualité.In diesem Bereich werden Diffusionsmodelle häufig so konzipiert, dass sie die zeitliche Abhängigkeit und Periodizität von Zeitreihendaten berücksichtigen. Beispielsweise ist CSDI (Conditional Sequence Diffusion Interpolation) ein Modell, das eine bidirektionale Faltungs-Neuronale Netzwerkstruktur nutzt, um Zeitreihen-Datenpunkte zu generieren oder zu interpolieren. Es zeichnet sich durch die Generierung medizinischer Daten und Umweltdaten aus. Andere Modelle wie DiffSTG und TimeGrad können die dynamischen Eigenschaften von Zeitreihen besser erfassen und realistischere Zeitreihenstichproben generieren, indem sie raumzeitliche Faltungsnetzwerke kombinieren. Diese Modelle stellen durch Selbstkonditionierungsführung nach und nach aussagekräftige Zeitreihendaten aus dem Gaußschen Rauschen wieder her. Die Audiogenerierung umfasst mehrere Anwendungsszenarien von der Sprachsynthese bis zur Musikgenerierung. Da Audiodaten in der Regel komplexe zeitliche Strukturen und reichhaltige spektrale Informationen enthalten, zeigen Diffusionsmodelle auch in diesem Bereich Potenzial. WaveGrad und DiffSinger sind beispielsweise zwei Diffusionsmodelle, die einen bedingten Generierungsprozess nutzen, um hochwertige Audiowellenformen zu erzeugen. WaveGrad verwendet das Mel-Spektrum als bedingte Eingabe, während DiffSinger darüber hinaus zusätzliche musikalische Informationen wie Tonhöhe und Tempo hinzufügt, um eine feinere stilistische Kontrolle zu ermöglichen. In Text-to-Speech-Anwendungen (TTS) kombinieren Guided-TTS und Diff-TTS die Konzepte von Textkodierern und akustischen Klassifikatoren, um Sprache zu erzeugen, die sowohl dem Textinhalt entspricht als auch einem bestimmten Klangstil folgt. Guide-TTS2 demonstriert außerdem, wie Sprache ohne einen expliziten Klassifikator generiert werden kann, indem die Klangerzeugung durch vom Modell selbst gelernte Funktionen gesteuert wird. In Bereichen wie Arzneimitteldesign, Materialwissenschaften und chemischer Biologie ist molekulares Design ein wichtiger Schritt bei der Entdeckung und Synthese neuer Verbindungen. Diffusionsmodelle dienen hier als leistungsstarkes Werkzeug, um den chemischen Raum effizient zu erkunden und Moleküle mit spezifischen Eigenschaften zu erzeugen. Bei der bedingungslosen Molekülgenerierung erzeugt das Diffusionsmodell spontan molekulare Strukturen, ohne sich auf Vorkenntnisse zu verlassen. Bei der modalübergreifenden Generierung kann das Modell spezifische funktionelle Bedingungen wie die Arzneimittelwirksamkeit oder die Bindungsneigung eines Zielproteins berücksichtigen, um Moleküle mit den gewünschten Eigenschaften zu erzeugen. Sequenzbasierte Methoden berücksichtigen möglicherweise die Proteinsequenz als Steuerung für die Erzeugung von Molekülen, während strukturbasierte Methoden die dreidimensionalen Strukturinformationen des Proteins nutzen können. Solche Strukturinformationen können als Vorwissen beim molekularen Andocken oder beim Antikörperdesign genutzt werden, wodurch die Qualität der erzeugten Moleküle verbessert wird. Verwendet ein Diffusionsmodell zur Generierung von Diagrammen mit dem Ziel, reale Netzwerkstrukturen und Ausbreitungsprozesse besser zu verstehen und zu simulieren. Dieser Ansatz hilft Forschern, Muster und Wechselwirkungen in komplexen Systemen zu ermitteln und mögliche Ergebnisse vorherzusagen. Zu den Anwendungen gehören soziale Netzwerke, biologische Netzwerkanalysen und die Erstellung von Diagrammdatensätzen. Herkömmliche Methoden basieren auf der Generierung von Adjazenzmatrizen oder Knotenmerkmalen, diese Methoden weisen jedoch eine schlechte Skalierbarkeit und eine begrenzte Praktikabilität auf. Daher bevorzugen moderne Techniken zur Diagrammgenerierung die Erstellung von Diagrammen basierend auf bestimmten Bedingungen. Beispielsweise verwendet das PCFI-Modell einen Teil der Merkmale des Diagramms und Vorhersagen des kürzesten Pfads, um den Generierungsprozess zu steuern. EDGE und DiffFormer nutzen Knotengrad- und Energiebeschränkungen, um die Generierung zu optimieren. Diese Methoden verbessern die Genauigkeit und Praktikabilität der Diagrammerstellung.
Fazit und Ausblick auf neue Szenarien oder Datensätze verallgemeinern. Darüber hinaus entstehen beim Umgang mit großen Datensätzen rechnerische Herausforderungen, wie z. B. längere Trainingszeiten, übermäßige Speichernutzung oder die Unfähigkeit, gewünschte Zustände zu erreichen, wodurch die Größe und Komplexität des Modells begrenzt wird. Darüber hinaus kann eine verzerrte oder ungleichmäßige Datenerfassung die Fähigkeit eines Modells einschränken, Ergebnisse zu generieren, die an verschiedene Domänen oder Populationen angepasst werden können.
Kontrollierbare verteilungsbasierte Generierung Die Verbesserung der Fähigkeit des Modells, Stichproben innerhalb einer bestimmten Verteilung zu verstehen und zu generieren, ist entscheidend für eine bessere Verallgemeinerung mit begrenzten Daten. Durch die Konzentration auf die Identifizierung von Mustern und Korrelationen in den Daten kann das Modell Stichproben generieren, die den Trainingsdaten genau entsprechen und spezifische Anforderungen erfüllen. Dies erfordert eine effiziente Datenerfassung, Nutzungstechniken und die Optimierung von Modellparametern und -strukturen. Letztendlich ermöglicht dieses verbesserte Verständnis eine kontrolliertere und präzisere Generierung und verbessert dadurch die Generalisierungsleistung.
Erweiterte multimodale Generierung unter Verwendung großer Sprachmodelle Zukünftige Richtungen für Diffusionsmodelle umfassen die Weiterentwicklung der multimodalen Generierung durch Integration großer Sprachmodelle (LLMs). Durch diese Integration kann das Modell Ausgaben generieren, die Kombinationen aus Text, Bildern und anderen Modalitäten enthalten. Durch die Einbeziehung von LLMs wird das Verständnis des Modells für die Wechselwirkungen zwischen verschiedenen Modalitäten verbessert und die generierten Ergebnisse sind vielfältiger und realistischer. Darüber hinaus verbessern LLMs die Effizienz der prompt-basierten Generierung erheblich, indem sie die Verbindungen zwischen Text und anderen Modalitäten effektiv nutzen. Darüber hinaus verbessern LLMs als Katalysatoren die Generierungsfähigkeiten von Diffusionsmodellen und erweitern das Spektrum der Bereiche, in denen sie Moden erzeugen können.
Integration mit dem Bereich des maschinellen Lernens Die Kombination des Diffusionsmodells mit der traditionellen Theorie des maschinellen Lernens bietet neue Möglichkeiten, die Leistung verschiedener Aufgaben zu verbessern. Halbüberwachtes Lernen ist besonders wertvoll für die Lösung inhärenter Herausforderungen von Diffusionsmodellen, wie z. B. Generalisierungsproblemen, und für die Ermöglichung einer effizienten Bedingungsgenerierung bei begrenzten Daten. Durch die Nutzung unbeschrifteter Daten werden die Generalisierungsfähigkeiten von Diffusionsmodellen verbessert und eine ideale Leistung bei der Generierung von Proben unter bestimmten Bedingungen erzielt.
Darüber hinaus spielt das Reinforcement Learning eine entscheidende Rolle, indem es Feinabstimmungsalgorithmen verwendet, um eine gezielte Anleitung während des Sampling-Prozesses des Modells bereitzustellen. Diese Anleitung gewährleistet eine gezielte Erkundung und fördert eine kontrollierte Erzeugung. Darüber hinaus wird das verstärkende Lernen durch die Integration zusätzlicher Rückmeldungen bereichert und dadurch die Fähigkeit des Modells verbessert, kontrollierbare Bedingungen zu erzeugen.
Algorithmus-Verbesserungsmethode (Anhang)
Feldanwendungsmethode (Anhang)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!