
Maison >Périphériques technologiques >IA >Vous pouvez démarrer directement avec Windows et Office. Il est si simple d'utiliser un ordinateur avec un grand agent modèle.
Vous pouvez démarrer directement avec Windows et Office. Il est si simple d'utiliser un ordinateur avec un grand agent modèle.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-19 23:33:221259parcourir
Quand on parle de l'avenir des assistants IA, les gens peuvent facilement penser à l'assistant IA Jarvis dans la série "Iron Man". Jarvis montre des fonctions éblouissantes dans le film. Il est non seulement le bras droit de Tony Stark, mais aussi son pont pour communiquer avec la technologie de pointe. Avec l’émergence de modèles à grande échelle, la manière dont les humains utilisent les outils connaît des changements révolutionnaires, et peut-être nous rapprochons-nous d’un scénario de science-fiction. Imaginez un agent multimodal capable de contrôler directement les ordinateurs qui nous entourent via le clavier et la souris, comme les humains. Cette percée sera passionnante.
Jarvis, assistant IA
La dernière recherche "ScreenAgent : un agent de contrôle informatique piloté par un modèle de langage de vision" de l'école d'intelligence artificielle de l'université de Jilin démontre l'imagination liée à l'utilisation d'un grand modèle de langage visuel pour contrôler directement l'interface graphique de l'ordinateur. Cette étude a proposé le modèle ScreenAgent, qui a exploré pour la première fois le contrôle direct de la souris et du clavier d'un ordinateur via VLM Agent sans avoir besoin d'une assistance supplémentaire en matière d'étiquettes, atteignant ainsi l'objectif d'un fonctionnement informatique direct de modèles à grande échelle. De plus, ScreenAgent utilise pour la première fois un processus automatisé « planifier-exécuter-réfléchir » pour obtenir un contrôle continu de l'interface graphique. Ce travail explore et innove dans les méthodes d'interaction homme-machine, ainsi que dans les ressources open source, notamment les ensembles de données, les contrôleurs et les codes de formation contenant des informations de positionnement précises.

- Adresse papier : https://arxiv.org/abs/2402.07945
- Adresse du projet : https://github.com/niuzaisheng/ScreenAgent
ScreenAgent offre aux utilisateurs des expériences pratiques de divertissement, de shopping, de voyage et de lecture en ligne. Il peut également être utilisé comme majordome personnel pour aider à gérer les ordinateurs personnels et à réaliser un travail rapide. Il peut devenir un puissant assistant de bureau sans aucun effort. Grâce à des effets pratiques, les utilisateurs peuvent comprendre sa fonctionnalité.
vous emmène surfer sur Internet et atteindre la liberté de divertissement
ScreenAgent recherche et lit des vidéos spécifiées en ligne en fonction des descriptions textuelles de l'utilisateur :
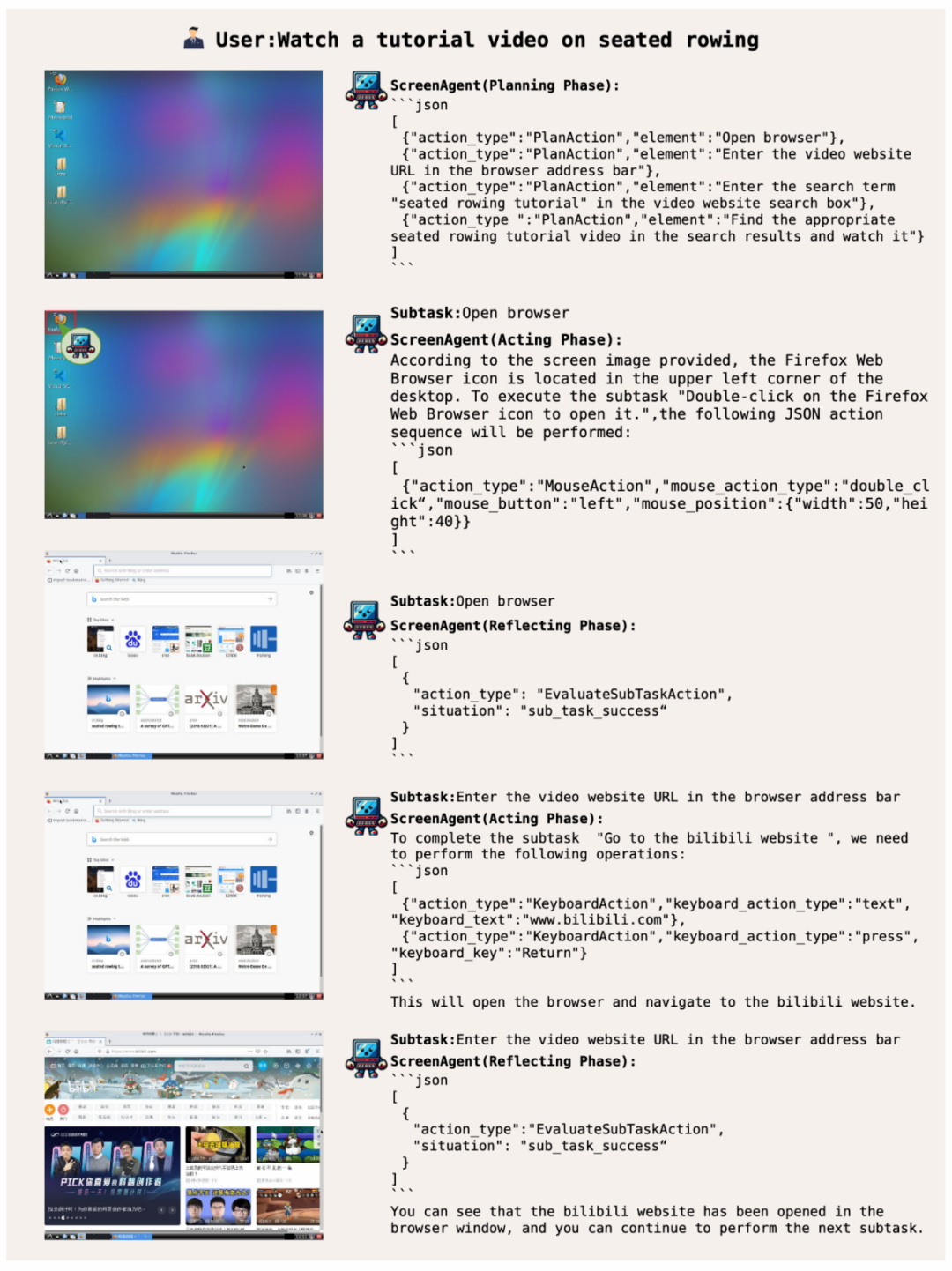
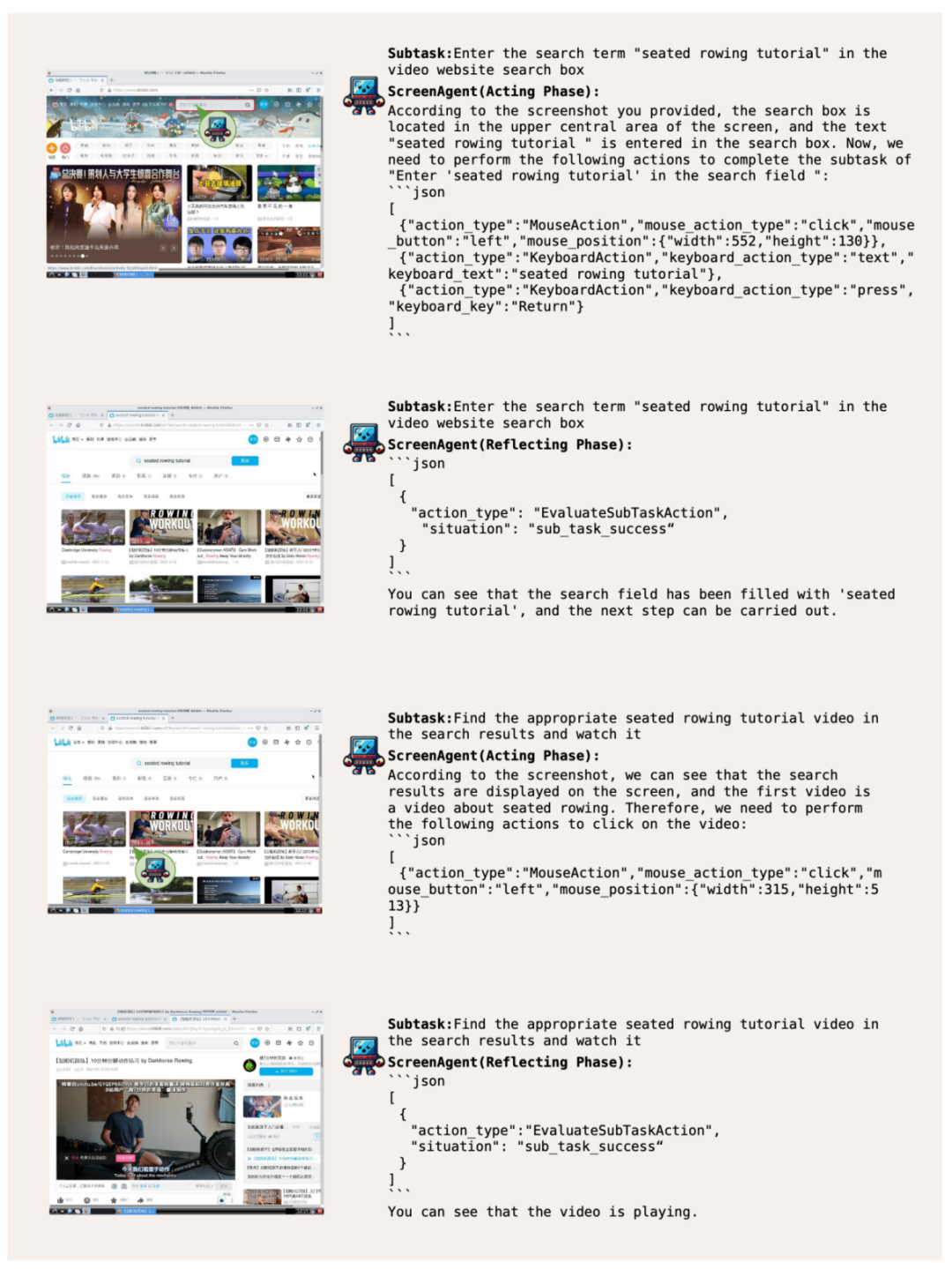
Gestionnaire d'exploitation du système, donnant Compétences de haut niveau des utilisateurs
Laissez ScreenAgent ouvrir l'observateur d'événements Windows :
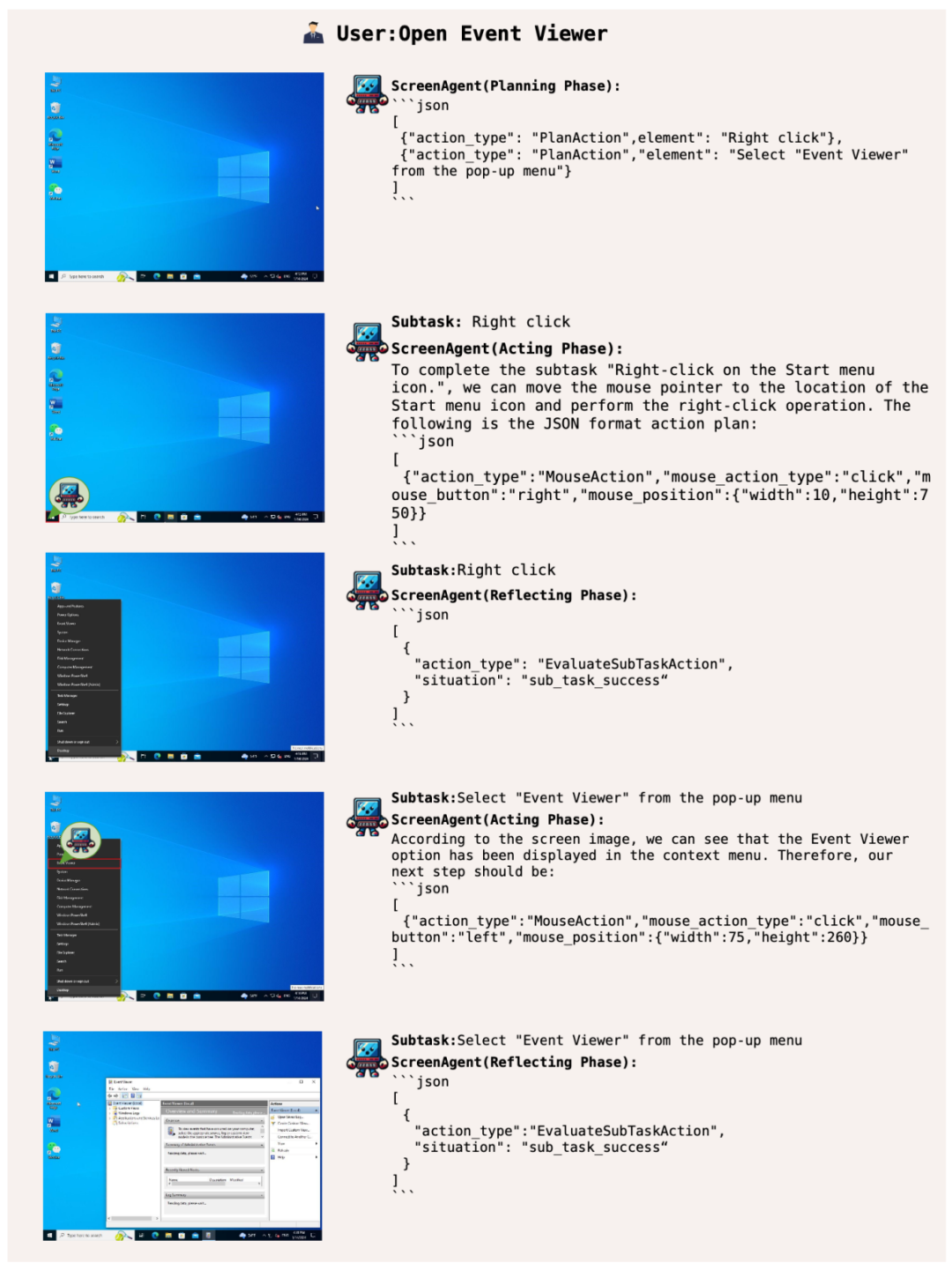
Maîtrisez les compétences bureautiques et jouez facilement avec Office
De plus, ScreenAgent peut utiliser des logiciels de bureau. Par exemple, selon la description du texte de l'utilisateur, supprimez le PPT sur la deuxième page ouverte :
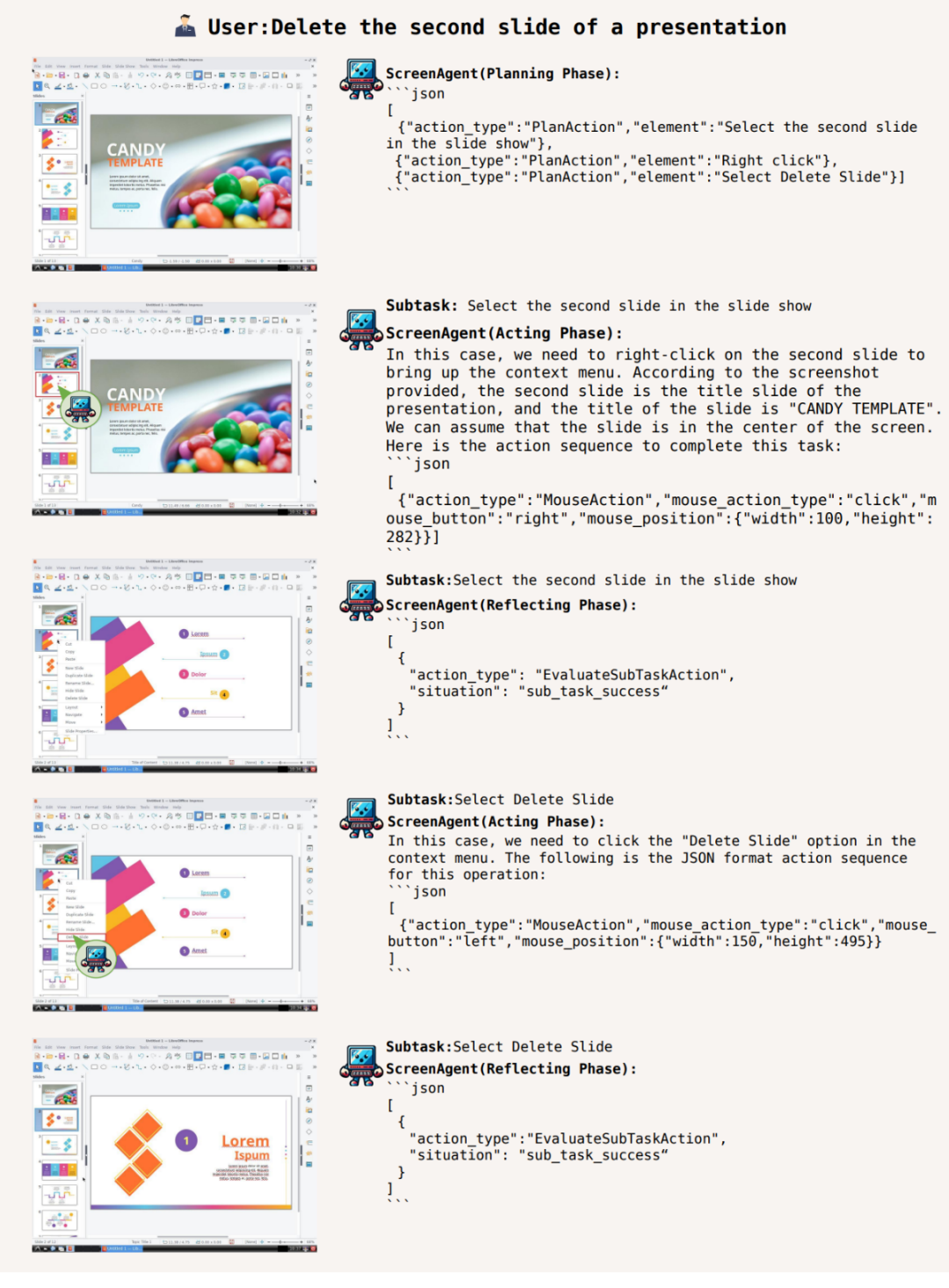
Planifiez avant d'agir, sachez où vous arrêter et gagnez
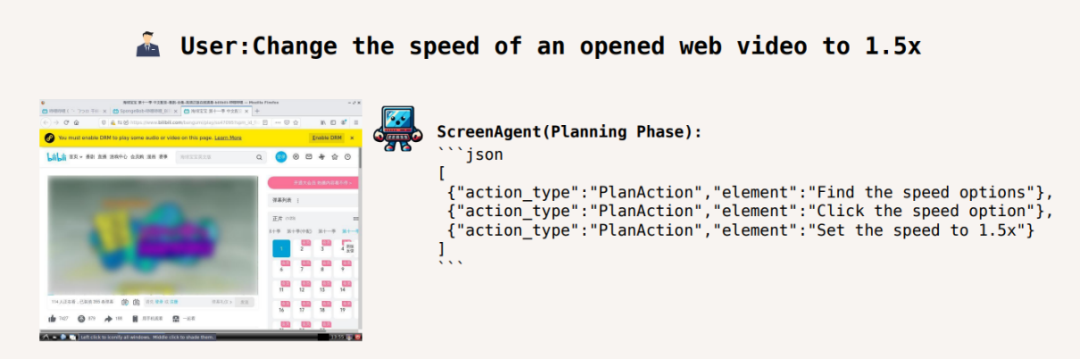
Pour accomplir une certaine tâche , cela doit être fait avant que la tâche ne soit exécutée. Faites du bon travail dans la planification des activités. ScreenAgent peut faire des plans en fonction des images observées et des besoins de l'utilisateur avant de commencer la tâche, par exemple :
Ajuster la vitesse de lecture vidéo à 1,5 fois :
Rechercher des voitures Magotan d'occasion sur 58 villes sites Web Prix :

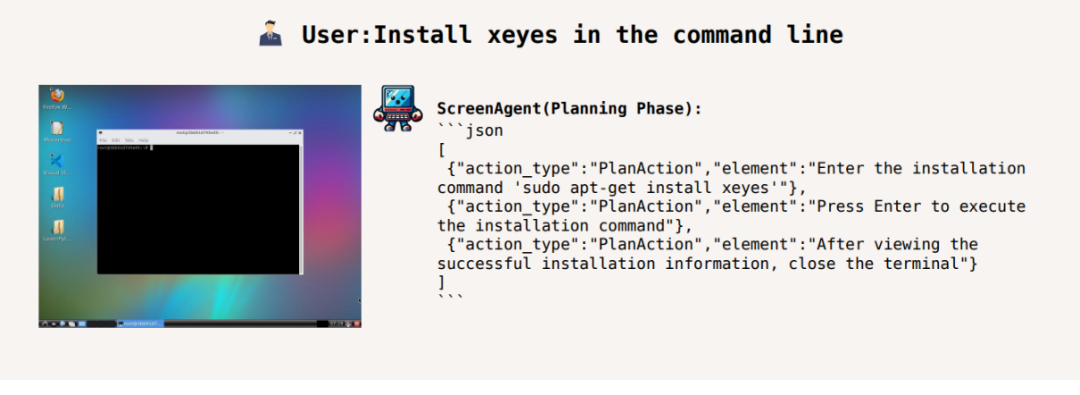
Installez xeyes dans la ligne de commande :
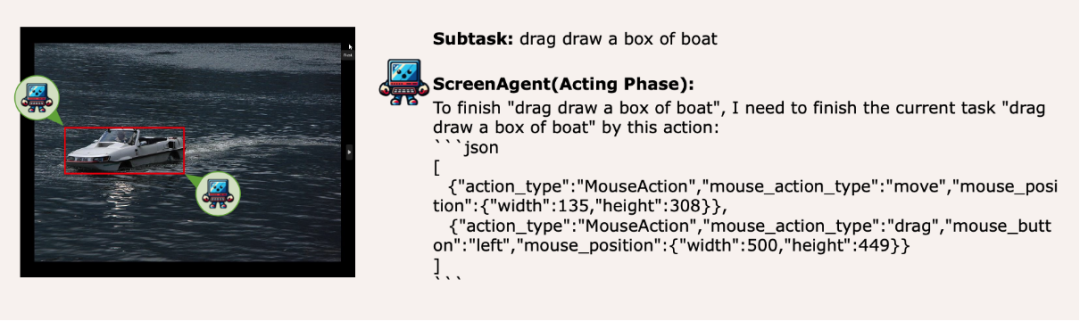
Migration de la capacité de positionnement visuel, la sélection de la souris se fait sans stress
ScreenAgent conserve également la capacité de localiser visuellement des objets naturels, et peut dessiner un cadre de sélection d'un objet en faisant glisser la souris :

méthode
En fait, l'Agent doit être appris à interagir avec L'interaction directe avec l'interface graphique utilisateur n'est pas une question simple. Elle nécessite que l'agent dispose de plusieurs capacités complètes telles que la planification des tâches, la compréhension des images, le positionnement visuel et l'utilisation des outils. Il existe certains compromis dans les modèles ou solutions d'interaction existants. Par exemple, des modèles tels que LLaVA-1.5 manquent de capacités de positionnement visuel précis sur des images de grande taille ; GPT-4V possède de très bonnes capacités de planification de mission, de compréhension d'image et d'OCR, mais refuse de céder. Obtenez des coordonnées précises. Les solutions existantes nécessitent l'annotation manuelle d'étiquettes numériques supplémentaires sur les images et permettent au modèle de sélectionner les éléments de l'interface utilisateur sur lesquels il faut cliquer, tels que Mobile-Agent, UFO et d'autres projets. De plus, des modèles tels que CogAgent et Fuyu-8B peuvent prendre en charge ; images haute résolution Il dispose de capacités de saisie et de positionnement visuel précis, mais CogAgent ne dispose pas de capacités complètes d'appel de fonctions et Fuyu-8B ne dispose pas de capacités linguistiques.
Afin de résoudre les problèmes ci-dessus, l'article propose de créer un nouvel environnement permettant à l'agent de modèle de langage visuel (VLM Agent) d'interagir avec l'écran réel de l'ordinateur. Dans cet environnement, l'agent peut observer des captures d'écran et manipuler l'interface utilisateur graphique en affichant les actions de la souris et du clavier. Afin de guider l'agent VLM pour interagir en permanence avec l'écran de l'ordinateur, l'article construit un processus opérationnel qui inclut la « planification-exécution-réflexion ». Lors de la phase de planification, il est demandé à l'agent de décomposer les tâches utilisateur en sous-tâches. Pendant la phase d'exécution, l'agent observera des captures d'écran, donnant des actions spécifiques de la souris et du clavier pour effectuer des sous-tâches. Le contrôleur exécutera ces actions et transmettra les résultats de l'exécution à l'agent. Pendant la phase de réflexion, l'agent observe les résultats de l'exécution, détermine l'état actuel et choisit de poursuivre l'exécution, de réessayer ou d'ajuster le plan. Ce processus se poursuit jusqu'à ce que la tâche soit terminée. Il convient de mentionner que ScreenAgent n'a pas besoin d'utiliser de modules de reconnaissance de texte ou d'icônes et utilise une approche de bout en bout pour entraîner toutes les capacités du modèle.
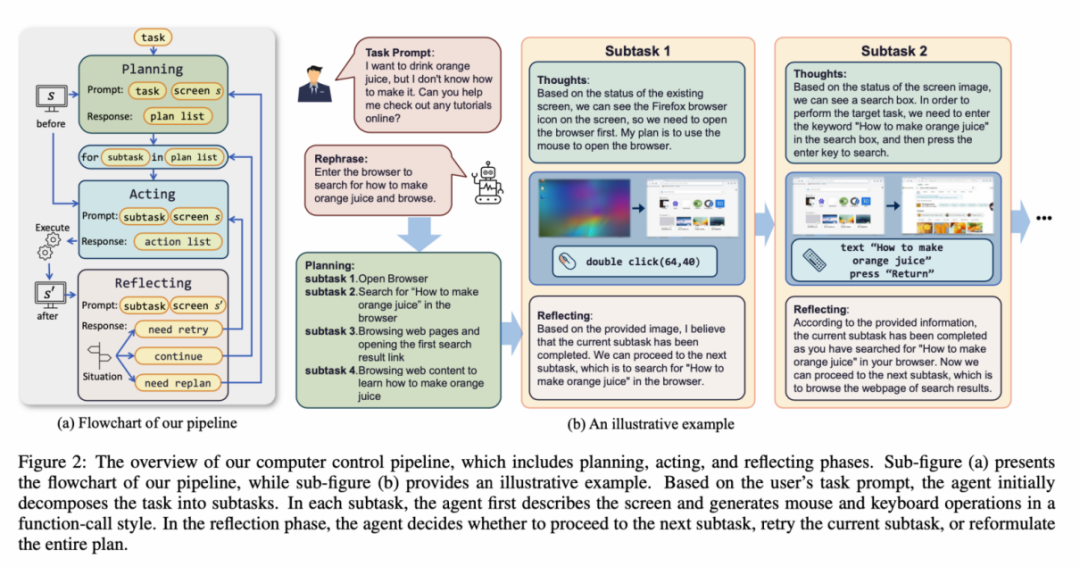
L'environnement ScreenAgent fait référence au protocole de connexion au bureau à distance VNC pour concevoir l'espace d'action de l'agent, y compris les opérations de clic de souris et de clavier les plus élémentaires, nécessitant que l'agent donne des coordonnées d'écran précises. Par rapport à l'appel d'API spécifiques pour effectuer des tâches, cette méthode est plus générale et peut être appliquée à divers systèmes d'exploitation et applications de bureau tels que Windows et Linux Desktop.
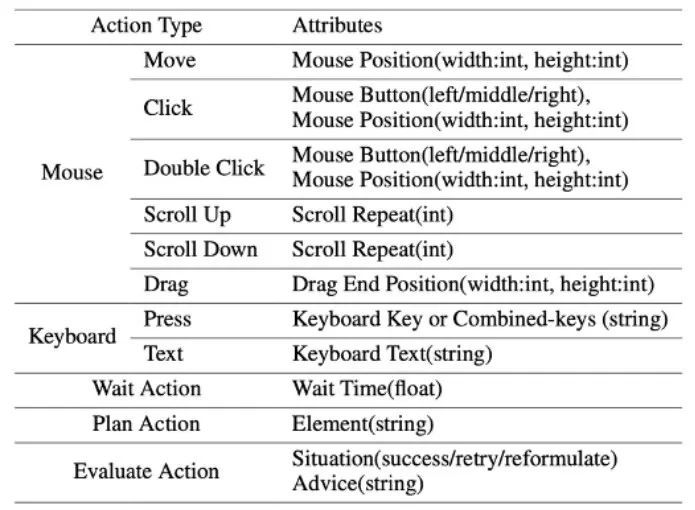
Ensemble de données ScreenAgent
Afin d'entraîner le modèle ScreenAgent, l'article a annoté manuellement l'ensemble de données ScreenAgent avec des informations de positionnement visuel précises. Cet ensemble de données couvre un large éventail de tâches informatiques quotidiennes, notamment les opérations sur les fichiers, la navigation sur le Web, les jeux et d'autres scénarios dans les environnements de bureau Windows et Linux.
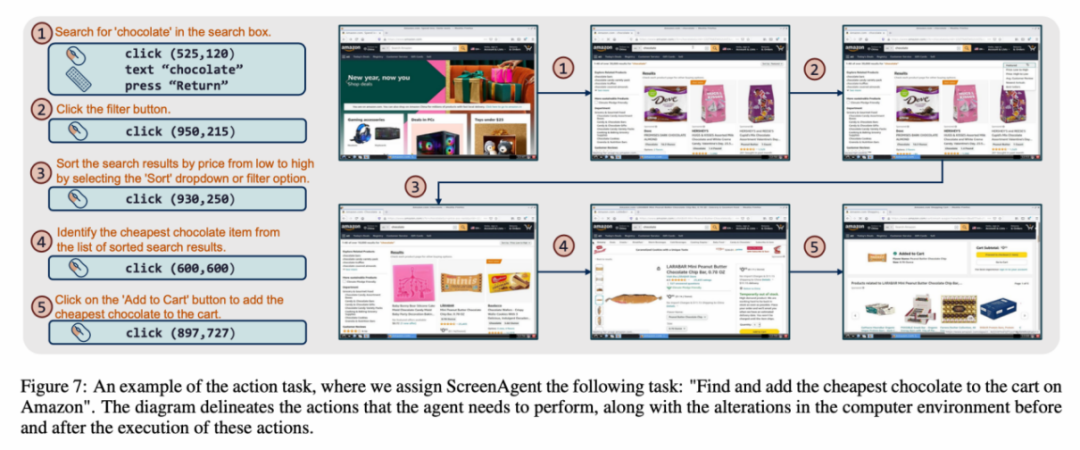
Chaque échantillon de l'ensemble de données est un processus complet pour accomplir une tâche, y compris des descriptions d'actions, des captures d'écran et des actions spécifiques exécutées. Par exemple, dans le cas de « l'ajout du chocolat le moins cher au panier » sur le site Web d'Amazon, vous devez d'abord rechercher des mots-clés dans le champ de recherche, puis utiliser des filtres pour trier les prix, et enfin ajouter les articles les moins chers au panier. Chariot. L'ensemble de données contient 273 enregistrements de tâches complètes.
Résultats expérimentaux
Dans la partie analyse expérimentale, l'auteur a comparé ScreenAgent avec plusieurs modèles VLM existants sous différents angles, comprenant principalement deux niveaux, la capacité de suivi des instructions et la précision du taux de prédiction d'action à granularité fine. La capacité de suivi d'instructions teste principalement si le modèle peut générer correctement la séquence d'action et le type d'action au format JSON. La précision de la prédiction des attributs d'action compare si la valeur d'attribut de chaque action est correctement prédite, comme la position du clic de la souris, les touches du clavier, etc.
Commande à suivre
En termes de suivi des commandes, la première tâche de l'agent est de générer l'appel de fonction d'outil correct en fonction du mot d'invite, c'est-à-dire de générer le format JSON correct. À cet égard, ScreenAgent et GPT-4V peuvent suivre. la commande est très bien et le CogAgent d'origine. En raison du manque de prise en charge des données sous forme d'appels API lors de la formation au réglage visuel, la possibilité de générer du JSON est perdue.
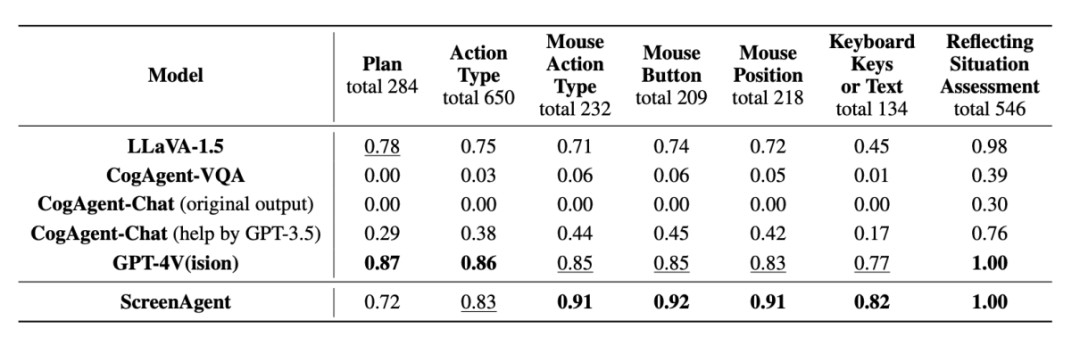
Précision du taux de précision des attributs d'action
Du point de vue du taux de précision des attributs d'action, ScreenAgent a également atteint un niveau comparable à GPT-4V. Notamment, ScreenAgent dépasse de loin les modèles existants en termes de précision des clics de souris. Cela montre que le réglage visuel améliore efficacement la capacité de positionnement précis du modèle. En outre, nous observons également un écart évident entre ScreenAgent et GPT-4V dans la planification de mission, ce qui met en évidence les connaissances de bon sens et les capacités de planification de mission de GPT-4V.
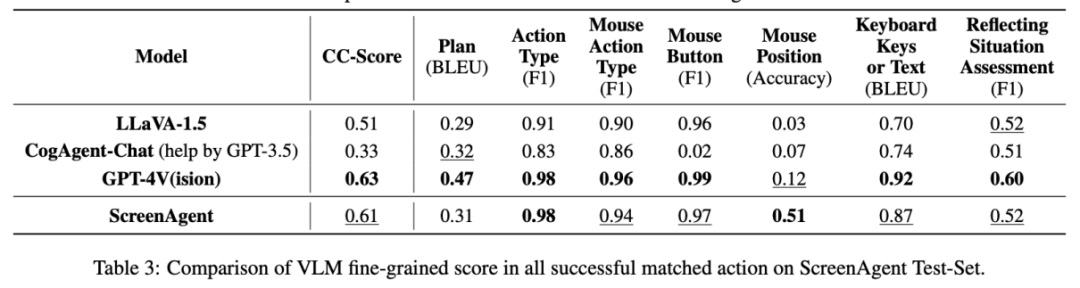
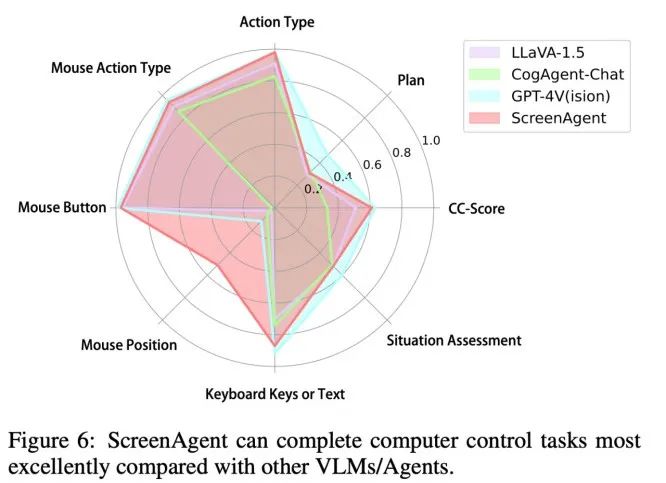
Conclusion
Le ScreenAgent proposé par l'équipe de l'école d'intelligence artificielle de l'université de Jilin peut contrôler les ordinateurs de la même manière que les humains, ne s'appuie pas sur d'autres API ou modèles OCR et peut être Largement utilisé dans divers logiciels d'application et systèmes d'exploitation. ScreenAgent peut accomplir de manière autonome les tâches confiées par l'utilisateur sous le contrôle du processus « plan-exécution-réflexion ». De cette manière, les utilisateurs peuvent voir chaque étape de l'accomplissement d'une tâche et mieux comprendre les pensées comportementales de l'agent.
L'article a open source le logiciel de contrôle, le code de formation du modèle et l'ensemble de données. Sur cette base, vous pouvez explorer des travaux plus avancés en matière d'intelligence artificielle générale, tels que l'apprentissage par renforcement sous rétroaction environnementale, l'exploration active du monde ouvert par les agents, la construction de modèles de monde, les bibliothèques de compétences d'agent, etc.
De plus, les assistants personnels pilotés par des agents IA ont une énorme valeur sociale, comme aider les personnes ayant des membres limités à utiliser des ordinateurs, réduire le travail numérique répétitif pour les humains et populariser l'enseignement informatique. À l'avenir, peut-être que tout le monde ne pourra pas devenir un super-héros comme Iron Man, mais nous pourrions tous avoir un Jarvis exclusif, un partenaire intelligent qui peut nous accompagner, nous aider et nous guider dans notre vie et notre travail, apportant plus de commodité et de possibilités.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment importer des données d'un tableau Excel dans un autre tableau
- Quelle est l'instruction SQL pour créer une base de données ?
- Qu'est-ce qu'un virus spécifiquement conçu pour cibler les logiciels bureautiques largement utilisés ?
- La technologie sous-jacente Python révélée : comment mettre en œuvre la formation et la prédiction de modèles
- Utilisez la vision pour inciter ! Shen Xiangyang a présenté le nouveau modèle de l'Institut de recherche IDEA, qui ne nécessite aucune formation ni réglage précis et peut être utilisé directement.