
Maison >Périphériques technologiques >IA >L'effet est explosif ! Lancement du premier modèle de génération vidéo d'OpenAI, fluide et haute définition en 1 minute, internautes : toute l'industrie est RIP
L'effet est explosif ! Lancement du premier modèle de génération vidéo d'OpenAI, fluide et haute définition en 1 minute, internautes : toute l'industrie est RIP

- PHPzavant
- 2024-02-19 09:30:091108parcourir
Tout à l'heure, Ultraman a publié le premier modèle de génération vidéo d'OpenAI Sora.
Hérite parfaitement de la qualité d'image et des capacités de suivi de commandes du DALL·E 3, et peut générer des vidéos haute définition d'une durée maximale d'une minute.
La Fête du Printemps de l'Année du Dragon imaginée par AI, avec des drapeaux rouges agités et une foule immense.
De nombreux enfants ont regardé l'équipe de danse du dragon avec curiosité, et certaines personnes ont sorti leur téléphone portable pour enregistrer les différents comportements des gens.

Les rues de Tokyo après la pluie, le sol mouillé RéflexionL'effet d'ombre au néon est comparable à RTX ON.

La vitre du train en marche est parfois bloquée, et le reflet des personnes dans la voiture apparaît brièvement, ce qui est très étonnant.

Vous pouvez également regarder une bande-annonce de film avec la qualité d'un blockbuster hollywoodien :

Du point de vue très rapproché de l'écran vertical, ce lézard regorge de détails :

Les internautes disent que le jeu est terminé, le travail est trop perdu :

Certaines personnes ont même commencé à "pleurer" toute une industrie :
L'IA comprend le monde physique en mouvement
OpenAI a déclaré que c'est apprendre à l'IA à comprendre et à simuler le monde physique en mouvement , l'objectif est de former des modèles pour aider les gens à résoudre des problèmes qui nécessitent une interaction dans le monde réel
Générer des vidéos basées sur des invites textuelles n'est qu'une étape de l'ensemble du plan.

Actuellement, Sora peut générer des scènes complexes avec plusieurs personnages et mouvements spécifiques Il peut non seulement comprendre les exigences formulées par les utilisateurs dans les invites, mais également comprendre comment ces objets existent dans le monde physique.
Sora peut également créer plusieurs plans dans une seule vidéo et s'appuyer sur sa compréhension approfondie du langage pour interpréter avec précision les mots indicateurs, tout en préservant le caractère et le style visuel.
La belle Tokyo enneigée regorge de monde. La caméra se déplace dans les rues animées de la ville, suivant plusieurs personnes profitant d'une belle journée enneigée et faisant leurs achats dans les stands à proximité. Les magnifiques pétales de fleurs de cerisier flottent au vent avec les flocons de neige.
OpenAI n'hésite pas à parler des faiblesses actuelles de Sora, soulignant qu'il peut être difficile de simuler avec précision les principes physiques de scènes complexes, et qu'il peut ne pas être capable de comprendre les relations de cause à effet .
Par exemple, "Cinq louveteaux gris jouaient et se poursuivaient sur une route de gravier isolée." Le nombre de loups changera et certains apparaîtront ou disparaîtront de nulle part.

Le modèle peut également obscurcir les détails spatiaux des signaux , comme confondre gauche et droite, et peut avoir des difficultés à décrire avec précision les événements au fil du temps , comme suivre une trajectoire de caméra spécifique.
Par exemple, dans le mot d'invite « Le ballon de basket passe à travers le panier et explose », le ballon de basket n'est pas correctement bloqué par le panier.

En termes de technologie, OpenAI n'a pas divulgué grand-chose pour le moment. Une brève introduction est la suivante :
Sora est un modèle de diffusion, à partir du bruit, il peut générer la vidéo entière en une seule fois ou prolonger la durée de la vidéo. La
clé est que génère des prédictions pour plusieurs images à la fois, garantissant ainsi. que le sujet de l'image peut être détecté même s'il quitte temporairement le champ de vision. Peut rester inchangé.
Semblable au modèle GPT, Sora utilise l'architecture Transformer, qui est hautement évolutive.
En termes de données, OpenAI représente les vidéos et les images sous forme de correctifs, similaires aux jetons dans GPT.
Avec cette représentation unifiée des données, les modèles peuvent être formés sur une gamme de données visuelles plus large qu'auparavant, couvrant différentes durées, résolutions et rapports d'aspect.
Sora s'appuie sur des recherches antérieures sur les modèles DALL·E et GPT. Il utilise la technologie de reformulation de mots d'invite de DALL·E 3 pour générer des annotations hautement descriptives pour les données d'entraînement visuel, afin de pouvoir suivre plus fidèlement les instructions textuelles de l'utilisateur.
En plus de pouvoir générer des vidéos basées uniquement sur des instructions textuelles, le modèle est également capable de prendre des images statiques existantes et de générer des vidéos à partir d'elles, en animant avec précision le contenu de l'image et en prêtant attention aux petits détails.
Le modèle peut également prendre une vidéo existante et l'étendre ou remplir les images manquantes, voir le document technique pour plus d'informations (à paraître ultérieurement) .
Sora est la base de modèles capables de comprendre et de simuler le monde réel. OpenAI estime que cette fonctionnalité deviendra une étape importante dans la réalisation de l'AGI.
Ultraman prend les commandes en ligne
Un certain nombre d'artistes visuels, de designers et de cinéastes (ainsi que des employés d'OpenAI) ont déjà eu accès à Sora.
Ils ont commencé à publier de nouvelles œuvres en continu et Ultraman a également commencé à prendre des commandes en ligne.
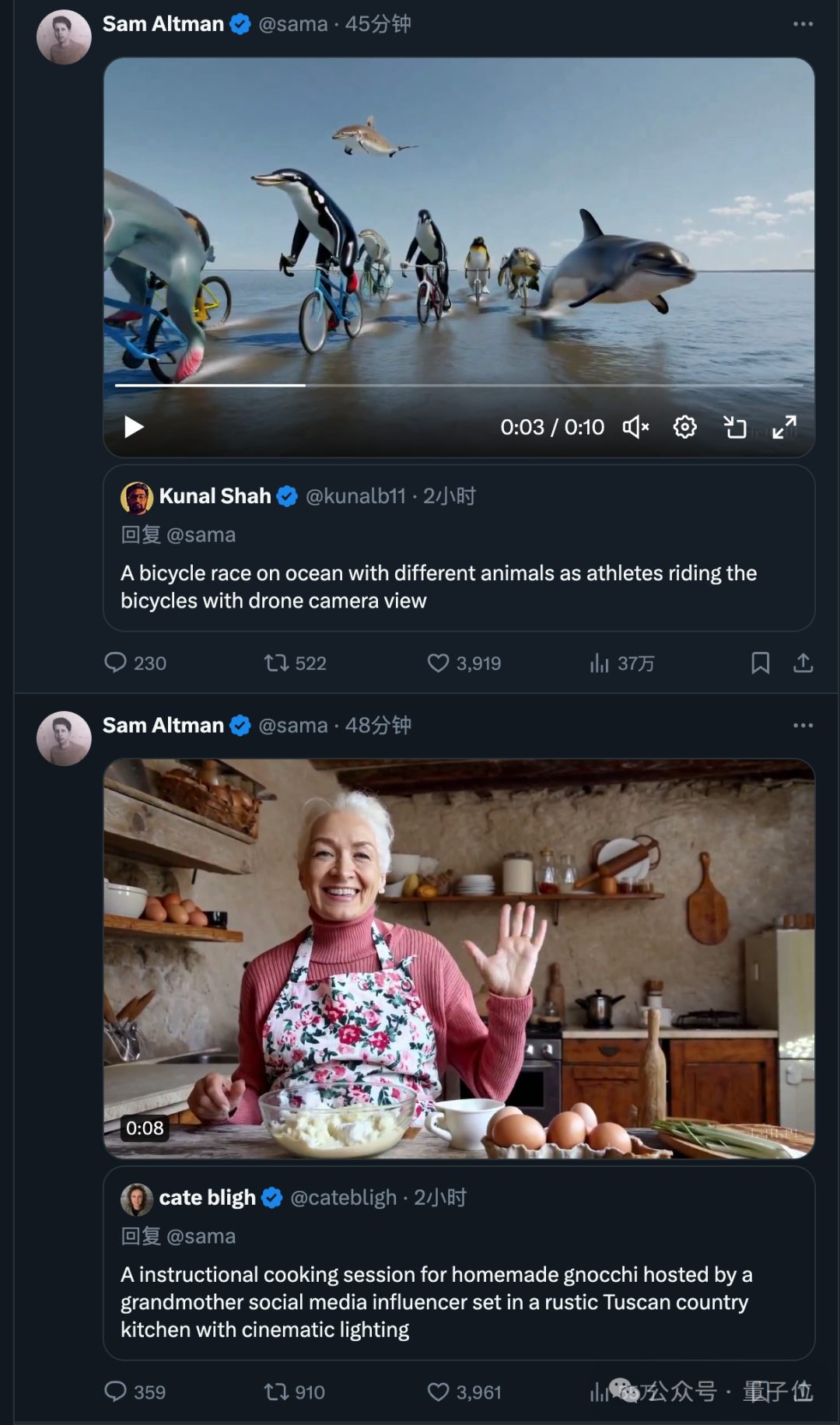
Insérez votre mot d'invite @sama et vous recevrez peut-être une réponse vidéo générée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les trois modèles de données de base de données courants ?
- Quelles propriétés possède le modèle de boîte CSS ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- Quel est le processus de conversion d'un diagramme e-r en un modèle de données relationnel ?
- Comment utiliser PyTorch pour la formation aux réseaux neuronaux