
Maison >Périphériques technologiques >IA >Laissez le modèle de langage visuel faire un raisonnement spatial, et Google est à nouveau nouveau
Laissez le modèle de langage visuel faire un raisonnement spatial, et Google est à nouveau nouveau

- PHPzavant
- 2024-02-19 09:27:191229parcourir
Bien que les modèles de langage visuel (VLM) aient fait des progrès significatifs dans de nombreuses tâches, notamment la description d'images, la réponse visuelle à des questions, la planification incarnée et la reconnaissance d'actions, des défis subsistent en matière de raisonnement spatial. De nombreux modèles ont encore des difficultés à comprendre la localisation ou les relations spatiales des cibles dans un espace tridimensionnel. Cela montre que dans le processus de développement ultérieur des modèles de langage visuel, il est nécessaire de se concentrer sur la résolution du problème du raisonnement spatial afin d'améliorer la précision et l'efficacité du modèle dans le traitement de tâches visuelles complexes.
Les chercheurs explorent souvent cette question à travers l’expérience physique humaine et le développement évolutif. Les humains possèdent des capacités inhérentes de raisonnement spatial qui leur permettent de déterminer facilement les relations spatiales, telles que les positions relatives des objets, et d’estimer les distances et les tailles, sans avoir recours à des processus de pensée complexes ou à des calculs mentaux.
Cette maîtrise des tâches de raisonnement spatial direct contraste avec les limites des capacités actuelles des modèles de langage visuel et soulève une question de recherche incontournable : les modèles de langage visuel peuvent-ils être dotés de capacités de raisonnement spatial semblables à celles des humains ?
Récemment, Google a proposé un modèle de langage visuel doté de capacités de raisonnement spatial : SpatialVLM.

- Titre de l'article : SpatialVLM : doter les modèles de vision-langage de capacités de raisonnement spatial
- Adresse de l'article : https://arxiv.org/pdf/ 2 401.12168. pdf
- Page d'accueil du projet : https://spatial-vlm.github.io/
Les chercheurs pensent que les limites du modèle de langage visuel actuel dans les capacités de raisonnement spatial ne peuvent pas provenir de limitations de son architecture, mais des limites de son architecture. Cela est plus probablement dû aux limites des ensembles de données communs utilisés lors de la formation. De nombreux modèles de langage visuel sont formés sur des ensembles de données de paires image-texte à grande échelle contenant des informations spatiales limitées. Obtenir des données incorporées riches en informations spatiales ou effectuer des annotations humaines de haute qualité est une tâche difficile. Pour résoudre ce problème, des techniques automatiques de génération et d’amélioration des données sont proposées. Cependant, les recherches antérieures se concentrent principalement sur la génération d’images photoréalistes avec de véritables annotations sémantiques, tout en ignorant la richesse des objets et des relations 3D. Par conséquent, les recherches futures pourraient explorer comment améliorer la compréhension des informations spatiales par le modèle grâce à des techniques de génération automatique, par exemple en introduisant davantage de données incorporées ou en se concentrant sur la modélisation d'objets et de relations 3D. Cela contribuera à améliorer les performances des modèles de langage visuel dans le raisonnement spatial, les rendant ainsi plus adaptés aux scénarios d'application du monde réel.
En revanche, cette recherche se concentre sur l'extraction directe d'informations spatiales à l'aide de données du monde réel pour montrer la diversité et la complexité du monde 3D réel. Cette méthode s'inspire des dernières technologies de modélisation visuelle et peut générer automatiquement des annotations spatiales 3D à partir d'images 2D.
Une fonction clé du système SpatialVLM est de traiter des données du monde réel à grande échelle et densément annotées à l'aide de technologies telles que la détection d'objets, l'estimation de la profondeur, la segmentation sémantique et les modèles de description du centre d'objets pour améliorer les capacités de raisonnement spatial des modèles de langage visuel. . Le système SpatialVLM atteint les objectifs de génération de données et de formation de modèles de langage visuel en convertissant les données générées par des modèles visuels en un format de données hybride qui peut être utilisé pour la description, le VQA et le raisonnement spatial. Les efforts des chercheurs ont permis à ce système de mieux comprendre et traiter les informations visuelles, améliorant ainsi ses performances dans des tâches complexes de raisonnement spatial. Cette approche permet de former des modèles de langage visuel pour mieux comprendre et traiter la relation entre les images et le texte, améliorant ainsi leur précision et leur efficacité dans diverses tâches visuelles.
La recherche montre que le modèle de langage visuel proposé dans cet article présente des capacités satisfaisantes dans plusieurs domaines. Premièrement, il montre des améliorations significatives dans la gestion des problèmes spatiaux qualitatifs. Deuxièmement, le modèle est capable de produire de manière fiable des estimations quantitatives, même en présence de bruit dans les données d'entraînement. Cette capacité lui confère non seulement des connaissances de bon sens sur la taille de la cible, mais la rend également utile pour gérer les tâches de réarrangement et l'annotation de récompenses à vocabulaire ouvert. Enfin, combiné à un puissant modèle de langage spatial à grande échelle, le modèle de langage spatial visuel peut effectuer des chaînes de raisonnement spatial et résoudre des tâches de raisonnement spatial complexes basées sur des interfaces de langage naturel.
Aperçu de la méthode
Afin de doter le modèle de langage visuel de capacités de raisonnement spatial qualitatif et quantitatif, les chercheurs ont proposé de générer un ensemble de données VQA spatiales à grande échelle pour entraîner le modèle de langage visuel. Plus précisément, il s'agit de concevoir un cadre complet de génération de données qui utilise d'abord des modèles de vision par ordinateur disponibles dans le commerce, notamment la détection de vocabulaire ouvert, l'estimation de la profondeur métrique, la segmentation sémantique et les modèles de description centrés sur la cible, pour extraire des informations de fond centrées sur la cible. Une approche basée sur un modèle est ensuite adoptée pour générer des données VQA spatiales à grande échelle avec une qualité raisonnable. Dans cet article, les chercheurs ont utilisé l'ensemble de données généré pour entraîner SpatialVLM à acquérir des capacités de raisonnement spatial direct, puis l'ont combiné avec le raisonnement de bon sens de haut niveau intégré dans les LLM pour débloquer le raisonnement spatial de la pensée en chaîne. Les chercheurs ont conçu un processus pour générer des données VQA contenant des questions de raisonnement spatial. Le processus spécifique est illustré à la figure 2.

1. Filtrage sémantique : Dans le processus de synthèse des données de cet article, la première étape consiste à utiliser le modèle de classification de vocabulaire ouvert basé sur CLIP pour classer toutes les images et exclure les images inappropriées.
2. Extraction d'images 2D en arrière-plan centré sur la cible : Cette étape obtient des entités centrées sur la cible composées de groupes de pixels et de descriptions de vocabulaire ouvert.3. Informations d'arrière-plan 2D en informations d'arrière-plan 3D : après l'estimation de la profondeur, les pixels 2D d'un seul œil sont mis à niveau vers un nuage de points 3D à l'échelle métrique. Cet article est le premier à convertir des images à l'échelle Internet en nuages de points 3D centrés sur des objets et à les utiliser pour synthétiser des données VQA avec une supervision d'inférence spatiale 3D.
 4. Désambiguïsation : Parfois, il peut y avoir plusieurs objets de catégories similaires dans une image, ce qui entraîne une ambiguïté dans leurs étiquettes de description. Par conséquent, avant de poser des questions sur ces objectifs, vous devez vous assurer que l’expression de référence ne contient pas d’ambiguïté.
4. Désambiguïsation : Parfois, il peut y avoir plusieurs objets de catégories similaires dans une image, ce qui entraîne une ambiguïté dans leurs étiquettes de description. Par conséquent, avant de poser des questions sur ces objectifs, vous devez vous assurer que l’expression de référence ne contient pas d’ambiguïté.
Ensemble de données VQA de raisonnement spatial à grande échelle
Les chercheurs intègrent des capacités de raisonnement spatial « intuitives » dans VLM en utilisant des données synthétiques pour la pré-formation. Par conséquent, la synthèse implique un raisonnement spatial questions-réponses ne comportant pas plus de deux objets (notés A et B) dans l’image. Les deux types de questions suivants sont principalement considérés ici :
1. Questions qualitatives : interroger sur le jugement de certaines relations spatiales. Par exemple : « Étant donné deux objets A et B, lequel est le plus à gauche ? »
2. Questions quantitatives : demandez des réponses plus détaillées, y compris des nombres et des unités. Par exemple, « À quelle distance se trouve l'objet A par rapport à l'objet B ? », « À quelle distance se trouve l'objet A de B ? » Ici, les chercheurs ont spécifié 38 types différents de questions de raisonnement spatial qualitatif et quantitatif, chacune Les questions contiennent environ 20 modèles de questions et 10 modèles de réponses.
La figure 3 montre un exemple des paires question-réponse synthétiques obtenues dans cet article. Les chercheurs ont créé un ensemble de données massif de 10 millions d’images et 2 milliards de paires questions-réponses de raisonnement spatial direct (50 % qualitatif, 50 % quantitatif).
Apprendre le raisonnement spatial
Raisonnement spatial direct : le modèle de langage visuel reçoit une image I et une requête Q sur une tâche spatiale en entrée, et génère une réponse A, et est présenté au format texte, sans avoir besoin d'utiliser des outils externes ou d'interagir avec d'autres grands modèles. Cet article adopte la même architecture et le même processus de formation que PaLM-E, sauf que le squelette de PaLM est remplacé par PaLM 2-S. La formation du modèle a ensuite été réalisée en utilisant un mélange de l'ensemble de données PaLM-E d'origine et de l'ensemble de données des auteurs, avec 5 % des jetons utilisés pour la tâche d'inférence spatiale.
Raisonnement spatial de pensée en chaîne : SpatialVLM fournit une interface en langage naturel qui peut être utilisée pour interroger des questions avec des concepts sous-jacents et, lorsqu'elle est combinée avec le puissant LLM, peut effectuer un raisonnement spatial complexe. 
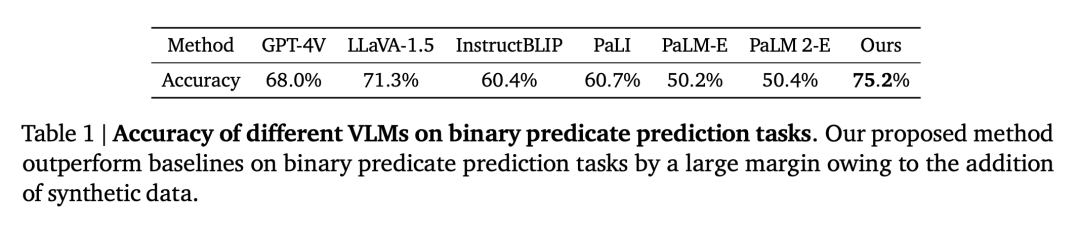
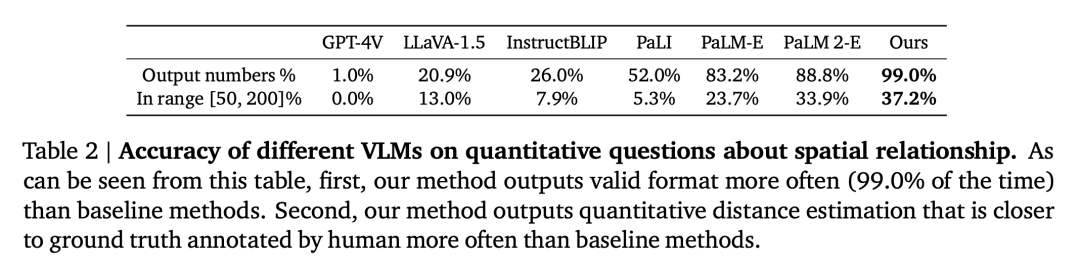
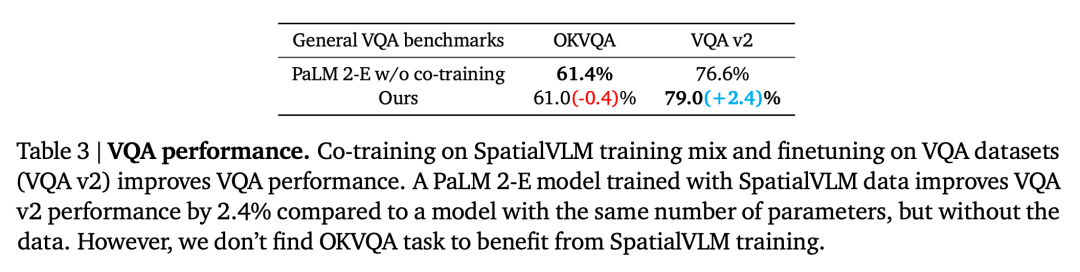
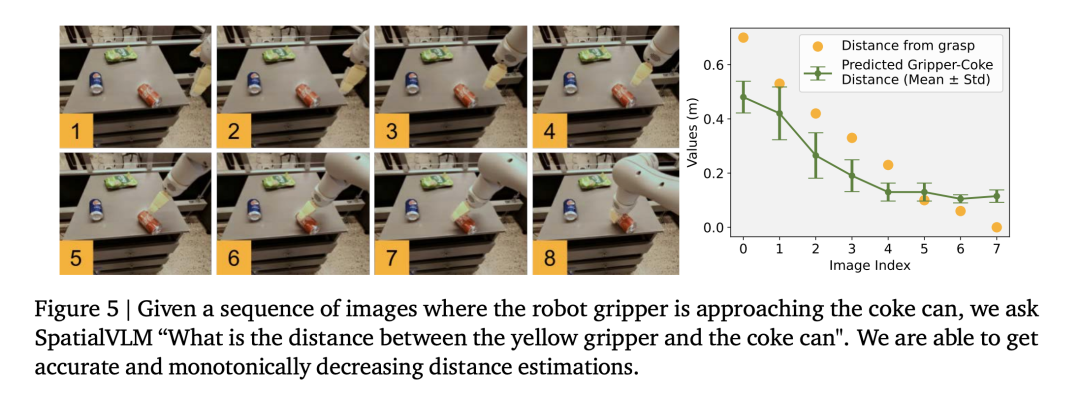
Semblable aux méthodes des modèles socratiques et du coordinateur LLM, cet article utilise LLM (text-davinci-003) pour coordonner la communication avec SpatialVLM afin de résoudre des problèmes complexes dans une invite de réflexion en chaîne, comme le montre la figure 4. Les chercheurs ont prouvé et répondu aux questions suivantes par le biais d'expériences : Question 1 : Le processus de génération et de formation de données spatiales VQA conçu dans cet article améliore-t-il les performances générales de VLM ? Des compétences en raisonnement spatial ? Et comment ça marche ? Question 2 : Quel impact les données VQA spatiales synthétiques pleines de données bruitées et différentes stratégies de formation ont-elles sur les performances d'apprentissage ? Question 3 : Un VLM équipé de capacités de raisonnement spatial « direct » peut-il débloquer de nouvelles capacités telles que le raisonnement en chaîne et la planification incarnée ? Les chercheurs ont entraîné le modèle en utilisant un mélange de l'ensemble d'entraînement PaLM-E et de l'ensemble de données spatiales VQA conçu dans cet article. Pour vérifier si la limitation du VLM dans le raisonnement spatial est un problème de données, ils ont sélectionné le modèle de langage visuel de pointe actuel comme référence. La tâche de description sémantique occupe une proportion considérable dans le processus de formation de ces modèles, plutôt que d'utiliser l'ensemble de données spatiales VQA de cet article pour la formation. Performance VQA spatiale VQA spatiale qualitative. Pour cette question, les réponses annotées par l'homme et la sortie VLM sont en langage naturel de forme libre. Par conséquent, pour évaluer les performances du VLM, nous avons utilisé des évaluateurs humains pour déterminer si les réponses étaient correctes, et les taux de réussite pour chaque VLM sont présentés dans le tableau 1. VQA spatiale quantitative. Comme le montre le tableau 2, notre modèle fonctionne mieux que la référence sur les deux mesures et est loin devant. L'impact des données spatiales VQA sur la VQA générale La deuxième question est de savoir si les performances du VLM sur d'autres tâches seront affectées par un co-entraînement avec une grande quantité de VQA spatiales données. En comparant notre modèle avec le PaLM 2-E de base formé sur le benchmark général VQA sans utiliser de données spatiales VQA, comme résumé dans le tableau 3, notre modèle atteint des performances comparables à celles du PaLM 2-E sur le benchmark OKVQA, qui inclut des performances spatiales limitées. problèmes d'inférence, est légèrement meilleur sur le benchmark test-dev VQA-v2, qui inclut des problèmes d'inférence spatiale. Impact de l'encodeur ViT sur le raisonnement spatial Frozen ViT (entraîné sur des cibles contrastées) code-t-il suffisamment d'informations pour le raisonnement spatial ? Pour explorer cela, les expériences des chercheurs ont commencé à l'étape de formation 110 000 et ont été divisées en deux cycles de formation, l'un Frozen ViT et l'autre Unfrozen ViT. En entraînant les deux modèles pour 70 000 étapes, les résultats de l'évaluation sont présentés dans le tableau 4. L'impact des réponses spatiales quantitatives bruyantes Les chercheurs ont utilisé l'ensemble de données de fonctionnement du robot pour entraîner un modèle de langage visuel et ont découvert que le modèle était capable d'effectuer une estimation fine de la distance dans le domaine opérationnel (Figure 5), prouvant en outre l’exactitude des données. Le Tableau 5 compare l'impact de différents écarts types du bruit gaussien sur les performances globales du VLM dans le VQA spatial quantitatif. 1. Modèle de langage visuel comme annotateur de récompense dense Les modèles de langage visuel ont une application importante dans le domaine de la robotique. Des recherches récentes ont montré que les modèles de langage visuel et les grands modèles de langage peuvent servir d'annotateurs de récompenses à vocabulaire ouvert général et de détecteurs de réussite pour les tâches robotiques, qui peuvent être utilisés pour développer des stratégies de contrôle efficaces. Cependant, les capacités d'étiquetage des récompenses de VLM sont souvent limitées par une conscience spatiale insuffisante. SpatialVLM est particulièrement adapté en tant qu'annotateur de récompense dense en raison de sa capacité à estimer quantitativement les distances ou les dimensions à partir d'images. Les auteurs mènent une expérience robotique réelle, spécifient une tâche en langage naturel et demandent à SpatialVLM d'annoter les récompenses pour chaque image de la trajectoire. Chaque point de la figure 6 représente l'emplacement d'une cible, et leur couleur représente la récompense annotée. À mesure que le robot progresse vers un objectif donné, les récompenses augmentent de façon monotone, démontrant les capacités de SpatialVLM en tant qu'annotateur de récompenses dense. 2. Raisonnement spatial de pensée enchaînée Les chercheurs ont également étudié si SpatialVLM pouvait être utilisé pour effectuer des tâches nécessitant un raisonnement en plusieurs étapes, compte tenu de sa capacité à résoudre des problèmes spatiaux de base. Améliorez vos capacités de réponse. Les auteurs montrent quelques exemples dans les figures 1 et 4. Lorsque le grand modèle de langage (GPT-4) est équipé de SpatialVLM comme sous-module de raisonnement spatial, il peut effectuer des tâches de raisonnement spatial complexes, telles que déterminer si 3 objets dans l'environnement peuvent former un « triangle isocèle ». Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux. 
Expériences et résultats


Le raisonnement spatial inspire de nouvelles applications

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de Three.js utilisant le plug-in de contrôle d'orbite (contrôle d'orbite) pour contrôler l'interaction du modèle
- Comment implémenter une permutation complète et une combinaison de chaînes en PHP ? (Photos, texte + vidéo)
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?
- Utilisez intelligemment les propriétés de filtre et de style de transformation pour créer des effets visuels 3D
- Meitu lance MiracleVision, le premier modèle visuel d'IA « esthétiquement avisé » de Chine