
Maison >Périphériques technologiques >IA >LeCun a accusé avec colère Sora de ne pas être capable de comprendre le monde physique ! Première vidéo IA de Meta 'World Model' V-JEPA
LeCun a accusé avec colère Sora de ne pas être capable de comprendre le monde physique ! Première vidéo IA de Meta 'World Model' V-JEPA

- 王林avant
- 2024-02-19 09:27:07869parcourir
Sora est instantanément devenue une tendance phare dès sa sortie, et la popularité du sujet n'a fait qu'augmenter.
La puissante capacité à générer des vidéos réalistes a fait s'exclamer de nombreuses personnes "la réalité n'existe plus".
Même le rapport technique d'OpenAI a révélé que Sora peut comprendre en profondeur le monde physique en mouvement et peut être qualifié de véritable « modèle du monde ».

Et le géant de Turing LeCun, qui s'est toujours concentré sur le « modèle mondial » comme axe de recherche, a également été impliqué dans ce débat.
La raison en est que les internautes ont déterré les opinions exprimées par LeCun lors du sommet WGS il y a quelques jours : "En termes de vidéo IA, nous ne savons pas quoi faire."
Il estime que générer des vidéos réalistes basées uniquement sur des invites textuelles n'équivaut pas au modèle comprenant le monde physique. L’approche de génération de vidéo est très différente des modèles du monde basés sur des prédictions causales.

Ensuite, LeCun a expliqué plus en détail :
Bien qu'il existe de nombreux types de vidéos imaginables, le système de génération vidéo n'a besoin que de créer « un » échantillon raisonnable pour réussir.
Pour une vraie vidéo, il existe relativement peu de voies de développement ultérieures raisonnables. Il est beaucoup plus difficile de générer des parties représentatives de ces possibilités, notamment dans des conditions d'action spécifiques.
De plus, générer du contenu de suivi pour ces vidéos est non seulement coûteux, mais en réalité inutile.
Une approche plus idéale consiste à générer une « représentation abstraite » de ces contenus ultérieurs, en supprimant les détails de la scène qui ne sont pas pertinents pour les actions que nous pouvons entreprendre.
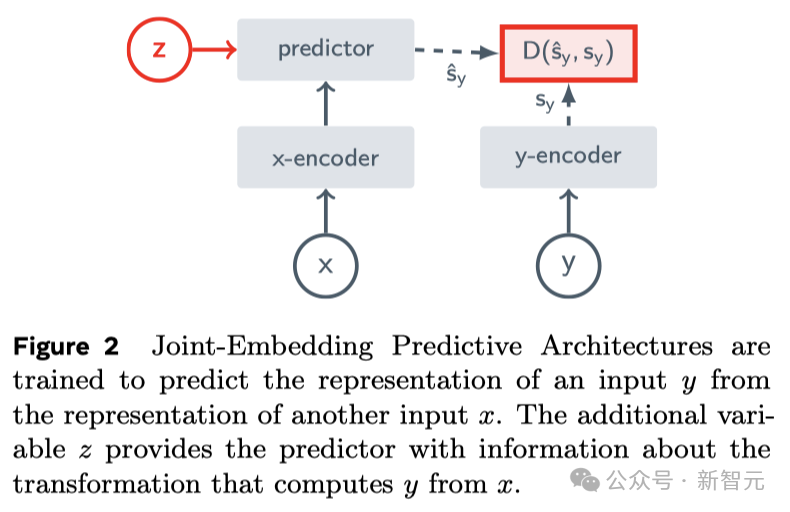
C'est l'idée centrale de JEPA (Joint Embedding Prediction Architecture). Elle n'est pas générative, mais prédit dans l'espace de représentation.
Ensuite, il a utilisé ses propres recherches sur VICReg, I-JEPA, V-JEPA et les travaux d'autres pour prouver :
et l'architecture générative de reconstruction de pixels, telle que l'auto-encodeur variationnel (Variational AE), masque Par rapport à l'AE masqué, à l'AE débruitant, etc., « l'architecture d'intégration conjointe » peut produire une meilleure expression d'entrée visuelle.
Lors de l'utilisation de la représentation apprise comme entrée de la tête supervisée dans les tâches en aval (sans affiner le squelette), l'architecture d'intégration conjointe surpasse l'architecture générative.
Le jour de la sortie du modèle Sora, Meta a lancé un nouveau "modèle de prédiction vidéo" non supervisé - V-JEPA.
Depuis que LeCun a mentionné JEPA pour la première fois en 2022, I-JEPA et V-JEPA disposent de fortes capacités de prédiction basées respectivement sur des images et des vidéos.
Il prétend être capable de voir le monde d'une « manière humaine de comprendre » et de générer des parties occluses grâce à une prédiction abstraite et efficace.

Adresse papier : https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
V-JEPA Quand en ce qui concerne l'action dans la vidéo ci-dessous, elle dit "Déchirez le papier en deux".

Pour un autre exemple, si une partie de la vidéo que vous regardez est bloquée, V-JEPA peut faire différentes prédictions sur le contenu du carnet.

Il convient de mentionner que c'est le super pouvoir que V-JEPA a acquis après avoir visionné 2 millions de vidéos.
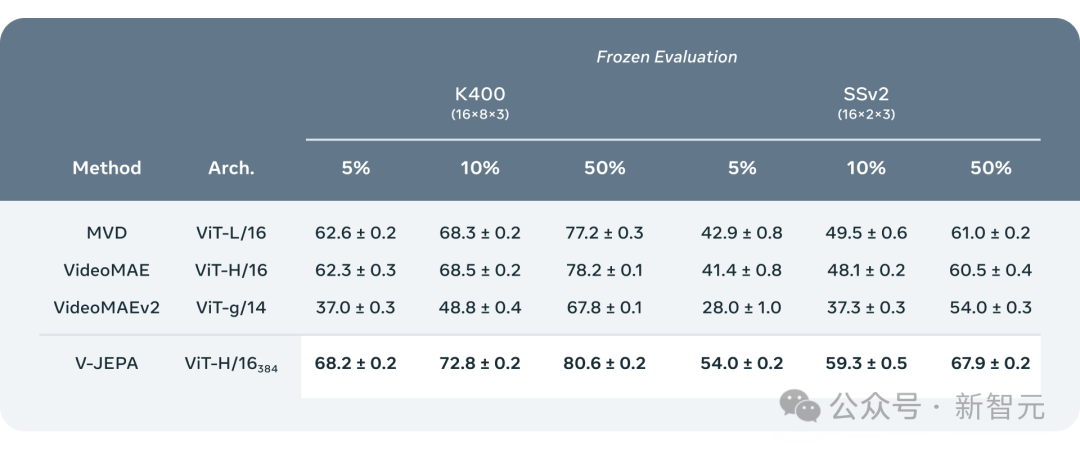
Les résultats expérimentaux montrent que seul grâce à l'apprentissage de la prédiction des fonctionnalités vidéo, une « représentation visuelle efficace » peut être obtenue, largement applicable à diverses tâches basées sur l'action et le jugement d'apparence, et ne nécessite aucun ajustement des paramètres du modèle.
ViT-H/16 basé sur la formation V-JEPA a obtenu des scores élevés de 81,9 %, 72,2 % et 77,9 % respectivement sur les benchmarks Kinetics-400, SSv2 et ImageNet1K.
Après avoir regardé 2 millions de vidéos, V-JEPA comprend le monde
La compréhension que les humains ont du monde qui les entoure, en particulier dans les premiers stades de la vie, s'obtient en grande partie par « l'observation ».
Prenons l'exemple de la « troisième loi du mouvement » de Newton. Même un bébé ou un chat peut naturellement comprendre après avoir poussé les objets de la table plusieurs fois et observé les résultats. Tout objet finira par tomber.
Cette compréhension ne nécessite pas d'orientation à long terme ni la lecture d'un grand nombre de livres.
On peut voir que votre modèle du monde intérieur - une compréhension situationnelle basée sur la compréhension mentale du monde - peut prédire ces résultats et être extrêmement efficace.
Yann LeCun a déclaré que le V-JEPA est une étape clé vers une compréhension plus profonde du monde, visant à permettre aux machines de raisonner et de planifier plus largement.

En 2022, il a proposé pour la première fois la Joint Embedding Prediction Architecture (JEPA).
Notre objectif est de créer une intelligence artificielle (AMI) avancée capable d'apprendre comme le font les humains, en apprenant, en s'adaptant et en planifiant efficacement pour résoudre des tâches complexes en créant des modèles internes du monde qui les entoure.

V-JEPA : Modèle non génératif
Complètement différent du modèle d'IA génératif Sora, le V-JEPA est un "modèle non génératif".
Il apprend en prédisant les parties cachées ou manquantes de la vidéo dans une représentation spatiale abstraite.
Ceci est similaire à l'architecture de prédiction d'intégration conjointe d'images (I-JEPA), qui apprend en comparant des représentations abstraites d'images plutôt qu'en comparant directement des "pixels".
Contrairement aux méthodes génératives qui tentent de reconstruire chaque pixel manquant, V-JEPA est capable d'éliminer les informations difficiles à prédire. Cette approche permet d'améliorer de 1,5 à 6 fois l'efficacité de la formation et des échantillons.
V-JEPA adopte une méthode d'apprentissage auto-supervisé et s'appuie entièrement sur des données non étiquetées pour la pré-formation.
Seulement après la pré-formation, il peut affiner le modèle en fonction de la tâche spécifique en étiquetant les données.
En conséquence, cette architecture est plus efficace que les modèles précédents, à la fois en termes de nombre d'échantillons étiquetés requis et d'investissement dans l'apprentissage à partir de données non étiquetées.
Lors de l'utilisation de V-JEPA, les chercheurs ont bloqué la plupart du contenu vidéo et n'ont montré qu'une très petite partie du « contexte ».
Ensuite, il est demandé au prédicteur de remplir le contenu manquant - non pas via des pixels spécifiques, mais sous la forme d'une description plus abstraite pour remplir le contenu dans cet espace de représentation.
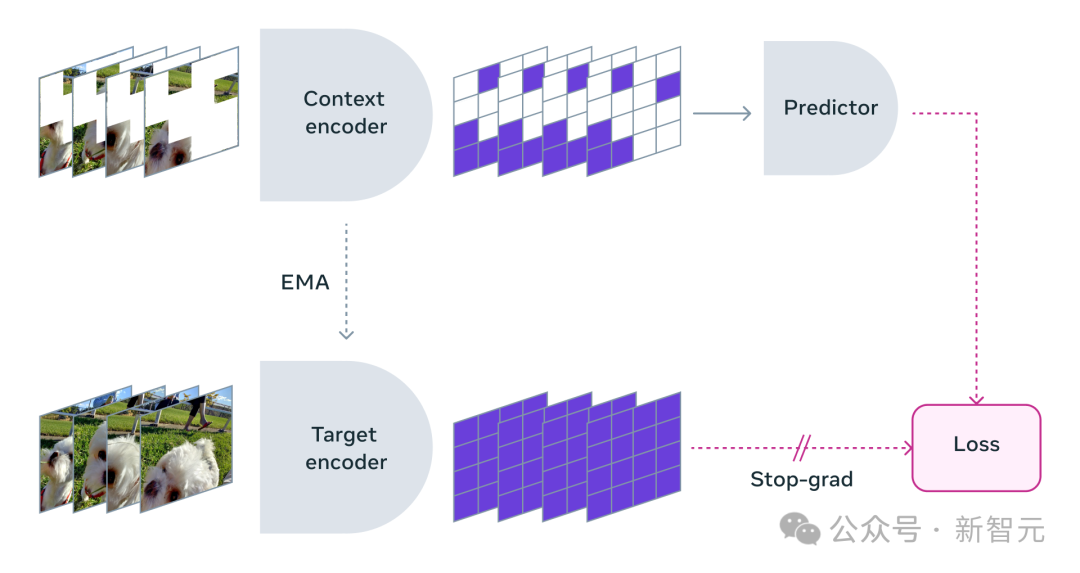
V-JEPA entraîne l'encodeur visuel en prédisant les régions spatio-temporelles cachées dans l'espace latent appris
Méthode du masque
V-JEPA n'est pas conçu pour comprendre des types spécifiques d'actions de.
Au lieu de cela, il a beaucoup appris sur le fonctionnement du monde en appliquant l'apprentissage auto-supervisé sur diverses vidéos.
Les méta-chercheurs ont également soigneusement conçu une stratégie de masquage :
Si vous ne bloquez pas la plupart des zones de la vidéo, mais sélectionnez simplement quelques petits fragments au hasard, cela rendra la tâche d'apprentissage trop simple, empêchant le modèle d'apprendre des informations complexes sur le monde.
Encore une fois, il est important de noter que dans la plupart des vidéos, les choses évoluent avec le temps.
Si vous masquez seulement une petite partie de la vidéo sur une courte période afin que le modèle puisse voir ce qui s'est passé avant et après, cela réduira également la difficulté d'apprentissage et rendra difficile pour le modèle d'apprendre un contenu intéressant. .
Par conséquent, les chercheurs ont adopté l'approche consistant à masquer des parties de la vidéo à la fois spatialement et temporellement, forçant le modèle à apprendre et à comprendre la scène.
Prédiction efficace sans réglage fin
La prédiction dans un espace de représentation abstrait est essentielle car elle permet au modèle de se concentrer sur les concepts de haut niveau du contenu vidéo sans avoir à se soucier des détails qui ne sont généralement pas importants à accomplir la tâche.
Après tout, si une vidéo montrait un arbre, vous ne vous soucieriez probablement pas des minuscules mouvements de chaque feuille.
Ce qui passionne vraiment les chercheurs de Meta, c'est que V-JEPA est le premier modèle vidéo à bien fonctionner en « évaluation gelée ».
Le gel signifie qu'une fois tous les pré-entraînements auto-supervisés terminés sur l'encodeur et le prédicteur, ils ne seront plus modifiés.
Lorsque nous avons besoin du modèle pour acquérir de nouvelles compétences, nous ajoutons simplement une petite couche ou un réseau spécialisé par-dessus, ce qui est efficace et rapide.
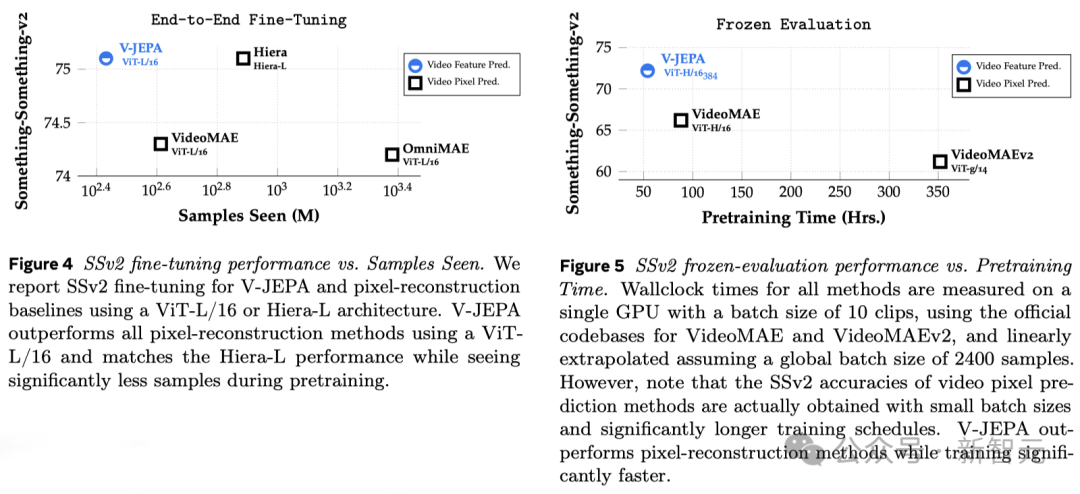
Les recherches précédentes nécessitaient également un réglage fin complet, c'est-à-dire après un pré-entraînement du modèle, afin que le modèle fonctionne bien sur des tâches telles que la reconnaissance fine d'actions, tous les paramètres ou poids du Le modèle doit être affiné.
Pour parler franchement, le modèle affiné ne peut se concentrer que sur une certaine tâche et ne peut pas s'adapter à d'autres tâches.
Si vous souhaitez que le modèle apprenne différentes tâches, vous devez modifier les données et apporter des ajustements spécialisés à l'ensemble du modèle.
Les recherches du V-JEPA montrent qu'il est possible de pré-entraîner le modèle en une seule fois sans s'appuyer sur des données étiquetées, puis d'utiliser le modèle pour plusieurs tâches différentes, telles que la classification des actions, la reconnaissance fine des interactions entre objets. et la localisation des activités, ouvrant de nouvelles possibilités.

- Évaluation gelée en quelques plans
Les chercheurs ont comparé V-JEPA avec d'autres modèles de traitement vidéo, en accordant une attention particulière aux performances lorsque les annotations de données sont moindres.
Ils ont sélectionné deux ensembles de données, Kinetics-400 et Something-Something-v2, et ont observé les performances du modèle lors du traitement des vidéos en ajustant la proportion d'échantillons étiquetés utilisés pour l'entraînement (respectivement 5 %, 10 % et 50 % ). efficacité.
Pour garantir la fiabilité des résultats, 3 tests indépendants ont été réalisés pour chaque ratio, et la moyenne et l'écart type ont été calculés.
Les résultats montrent que V-JEPA est meilleur que les autres modèles en termes d'efficacité d'utilisation des annotations. Surtout lorsque les échantillons d'annotations disponibles pour chaque catégorie sont réduits, l'écart de performances entre V-JEPA et les autres modèles devient plus évident.

Nouvelle direction pour les recherches futures : prédiction visuelle + audio
Bien que le « V » de V-JEPA signifie vidéo, jusqu'à présent, il s'est principalement concentré sur l'analyse des « éléments visuels » des vidéos .
Évidemment, la prochaine direction de recherche de Meta est de lancer une méthode multimodale capable de traiter simultanément « les informations visuelles et audio » dans les vidéos.
En tant que modèle de validation de principe, V-JEPA fonctionne bien pour identifier les interactions subtiles entre objets dans les vidéos.
Par exemple, être capable de distinguer si quelqu'un pose le stylo, ramasse le stylo ou fait semblant de poser le stylo mais ne le pose pas réellement.
Cependant, cette reconnaissance de mouvement de haut niveau fonctionne bien pour les clips vidéo courts (de quelques secondes à 10 secondes).
Par conséquent, un autre objectif de la prochaine étape de la recherche est de savoir comment élaborer un plan de modèle et prédire sur une période de temps plus longue.
« World Model » va encore plus loin
Jusqu'à présent, les méta-chercheurs utilisant V-JEPA se sont principalement concentrés sur la « perception » : comprendre la situation en temps réel du monde environnant en analysant les flux vidéo.
Dans cette architecture de prédiction intégrée conjointe, le prédicteur agit comme un « modèle physique du monde » préliminaire qui peut nous dire de manière générale ce qui se passe dans la vidéo.
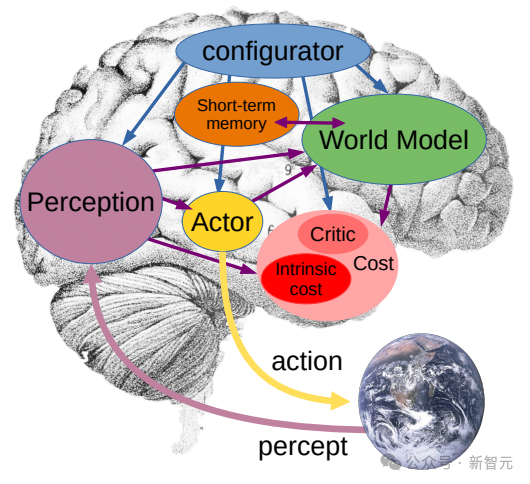
Le prochain objectif de Meta est de montrer comment ce prédicteur ou modèle mondial peut être utilisé pour la planification et la prise de décision continue.
Nous savons déjà que le modèle JEPA peut être formé en observant des vidéos, un peu comme un bébé observant le monde, et peut apprendre beaucoup sans une forte supervision.
De cette façon, le modèle peut rapidement apprendre de nouvelles tâches et reconnaître différentes actions avec seulement une petite quantité de données étiquetées.
À long terme, la solide compréhension de la situation de V-JEPA sera d’une grande importance pour le développement de la technologie de l’IA incarnée et des futures lunettes de réalité augmentée (AR) dans les applications futures.
Maintenant, réfléchissez-y, si Apple Vision Pro peut être béni par le « Modèle Mondial », il sera encore plus invincible.
Discussion entre internautes
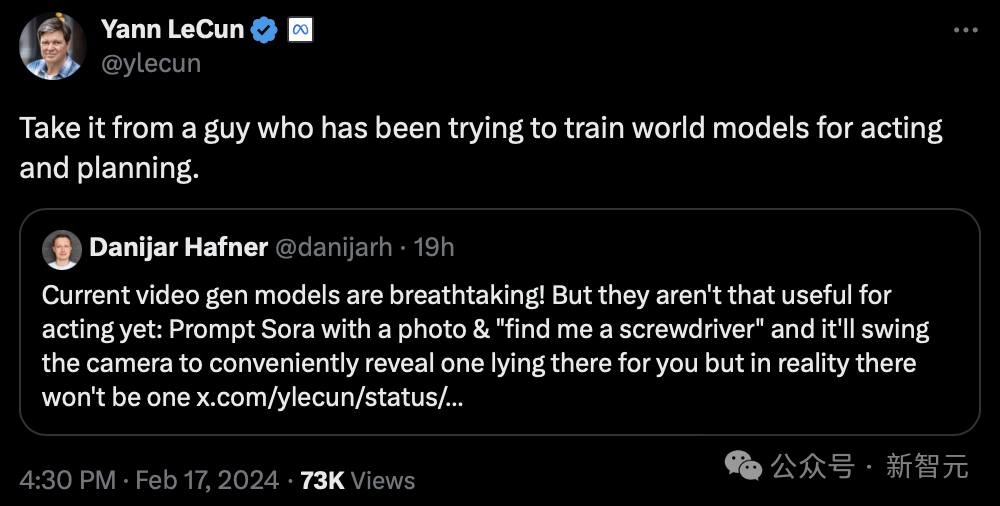
De toute évidence, LeCun n'est pas optimiste quant à l'IA générative.

"Écoutez les conseils de quelqu'un qui a essayé de former un "modèle mondial" pour la présentation et la planification."
Le PDG de Perplexity AI a déclaré :
Sora, bien qu'incroyable, n'est pas prêt à modéliser avec précision la physique. Et l'auteur de Sora a été très intelligent et l'a mentionné dans la section rapport technique du blog, comme le verre brisé ne peut pas être bien modélisé.
Il est évident qu’à court terme, un raisonnement basé sur une simulation d’un monde aussi complexe ne peut pas être exécuté immédiatement sur un robot domestique.
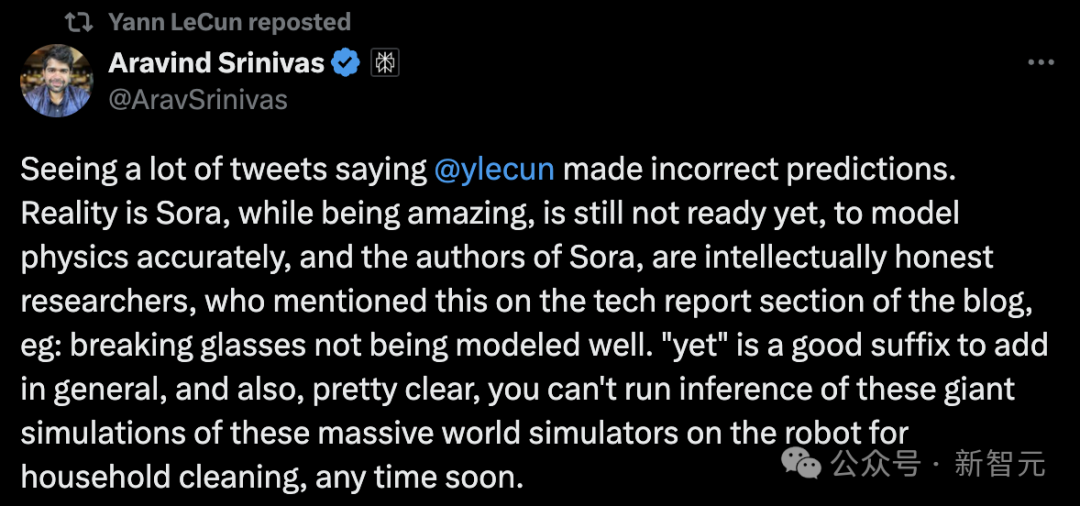
En fait, une nuance très importante que beaucoup de gens ne comprennent pas est la suivante :
Générer un contenu apparemment intéressant dans un texte ou une vidéo ne signifie pas (ni n'exige) qu'il comprenne" le contenu vous générez. Un modèle d’agent capable de raisonner sur la base de la compréhension doit certainement être en dehors des grands modèles ou des modèles de diffusion.

Mais certains internautes ont déclaré : "Ce n'est pas ainsi que les humains apprennent."
"Nous ne nous souvenons que de quelque chose d'unique à propos de nos expériences passées, perdant tous les détails. Nous pouvons également modéliser (créer des représentations) l'environnement à tout moment et n'importe où parce que nous le percevons. La partie la plus importante de l'intelligence est le changement de généralisation".

D'autres prétendent qu'il s'agit toujours d'une intégration de l'espace latent interpolé, et jusqu'à présent, vous ne pouvez pas construire un "modèle mondial" de cette manière.

Sora et V-JEPA peuvent-ils vraiment comprendre le monde ? Qu'en penses-tu?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comprendre le modèle de boîte CSS : Comprendre ce qu'est le modèle de boîte CSS en 5 minutes ?
- Les fichiers ai peuvent-ils être ouverts avec ps ?
- Que dois-je faire si Win10 ne trouve pas les Airpods ?
- À quel type de modèle de données appartient le serveur SQL ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?