
Maison >Périphériques technologiques >IA >Les journaux anonymes proposent des idées surprenantes ! Cela peut en fait être fait pour améliorer les capacités de texte long des grands modèles.
Les journaux anonymes proposent des idées surprenantes ! Cela peut en fait être fait pour améliorer les capacités de texte long des grands modèles.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-02 18:21:15679parcourir
Quand il s'agit d'améliorer les capacités de texte long des grands modèles, pensez-vous à l'extrapolation de longueur ou à l'expansion de la fenêtre contextuelle ?
Non, ceux-ci consomment trop de ressources matérielles.
Jetons un coup d'œil à une nouvelle solution merveilleuse :
est essentiellement différente du cache KV utilisé par des méthodes telles que l'extrapolation de longueur. Elle utilise les paramètres du modèle pour stocker une grande quantité d'informations contextuelles. .
La méthode spécifique consiste à construire un module Lora temporaire, de sorte qu'il ne "diffuse les mises à jour" que pendant le processus de génération de texte long, c'est-à-dire qu'il utilise en permanence le contenu généré précédemment comme entrée pour servir de données d'entraînement. , garantissant ainsi que les connaissances sont stockées dans les paramètres du modèle.
Puis une fois l'inférence terminée, jetez-la pour vous assurer qu'il n'y a pas d'impact à long terme sur les paramètres du modèle.
Cette méthode nous permet de stocker autant d'informations contextuelles que nous le souhaitons sans agrandir la fenêtre contextuelle Stockez autant que vous le souhaitez.
Des expériences ont prouvé que cette méthode :
- peut améliorer considérablement la qualité des tâches de texte long du modèle, atteignant une réduction de 29,6 % de la perplexité et une amélioration de 53,2 % de la qualité de la traduction de texte long (score BLEU) ;
- peut également être compatible avec la plupart des méthodes de génération de texte long existantes et les améliorer.
- Le plus important est que cela peut réduire considérablement les coûts informatiques.
Tout en assurant une légère amélioration de la qualité de génération (perplexité réduite de 3,8%), les FLOP nécessaires à l'inférence sont réduits de 70,5% et le délai est réduit de 51,5% !
Pour la situation spécifique, ouvrons le papier et jetons un œil.
Créez un module Lora temporaire et jetez-le après utilisation
La méthode s'appelle Temp-Lora Le schéma d'architecture est le suivant :
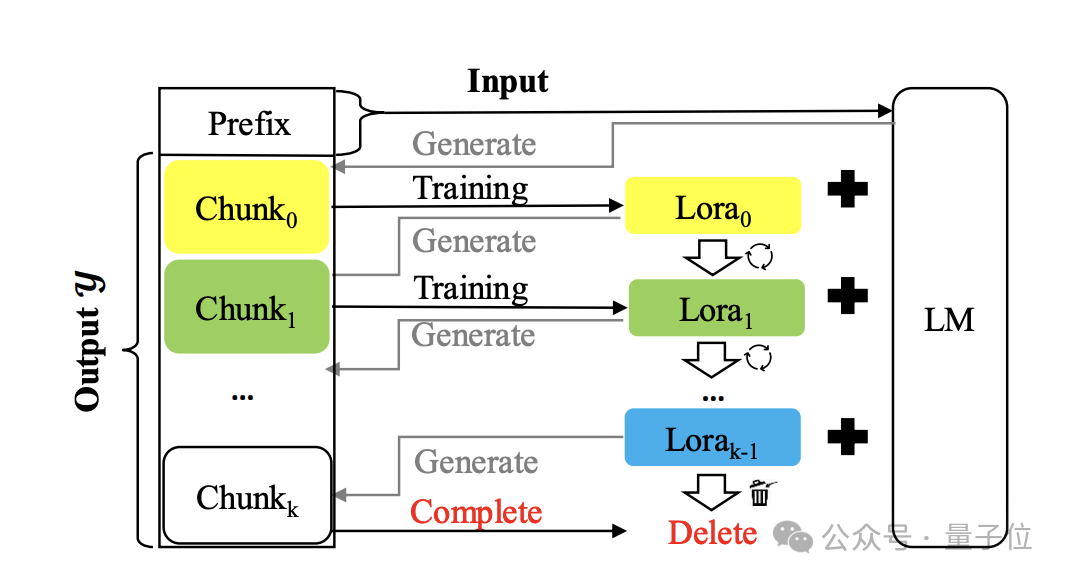
Le noyau est d'utiliser le texte précédemment généré pour progressivement. s'entraîner de manière autorégressive Module Lora temporaire.
Ce module est très adaptable et peut être ajusté en continu, afin de pouvoir avoir une compréhension approfondie des contextes de différentes distances.
L'algorithme spécifique est le suivant :
Pendant le processus de génération, les jetons sont générés bloc par bloc. Chaque fois qu'un bloc est généré, le dernier jeton Lx est utilisé comme entrée X pour générer les jetons suivants.
Une fois que le nombre de jetons générés atteint la taille de bloc prédéfinie Δ, démarrez la formation du module Temp-Lora en utilisant le dernier bloc, puis démarrez la génération de bloc suivante.

Dans l'expérience, l'auteur définit Δ+Lx sur W pour utiliser pleinement la taille de la fenêtre contextuelle du modèle.
Pour la formation du module Temp-Lora, apprendre à générer de nouveaux blocs sans aucune condition peut ne pas constituer un objectif d'entraînement efficace et conduire à de sérieux surapprentissages.
Pour résoudre ce problème, les auteurs intègrent des balises LT devant chaque bloc dans le processus de formation, en les utilisant comme entrée et le bloc comme sortie.
Enfin, l'auteur propose également une stratégie appelée Cache Reuse (Cache Reuse) pour obtenir une inférence plus efficace.
D'une manière générale, après la mise à jour du module Temp-Loramo dans le framework standard, nous devons recalculer l'état KV avec les paramètres mis à jour.
Vous pouvez également réutiliser l'état KV mis en cache existant tout en utilisant le modèle mis à jour pour la génération de texte ultérieure.
Plus précisément, nous utilisons le dernier module Temp-Lora pour recalculer l'état KV uniquement lorsque le modèle génère une longueur maximale (taille de la fenêtre contextuelle W).
Une telle méthode de réutilisation du cache peut accélérer la génération sans affecter de manière significative la qualité de la génération.
C’est toute l’introduction à la méthode Temp-Lora Regardons principalement le test ci-dessous.
Plus le texte est long, meilleur est l'effet
L'auteur a évalué le framework Temp-Lora sur les modèles Llama2-7B-4K, Llama2-13B-4K, Llama2-7B-32K et Yi-Chat-6B et a couvert ces deux les types de tâches de texte long sont la génération et la traduction.
L'ensemble de données de test est un sous-ensemble du benchmark de modélisation de langage de texte long PG19, à partir duquel 40 livres ont été sélectionnés au hasard.
L'autre est un sous-ensemble aléatoire de l'ensemble de données Guofeng du WMT 2023, contenant 20 romans chinois en ligne traduits en anglais par des professionnels.
Regardons d’abord les résultats sur PG19.
Le tableau ci-dessous montre le PPL (perplexité, reflétant l'incertitude du modèle pour une entrée donnée, le plus bas sera le mieux) comparaison de différents modèles sur PG19 avec et sans le module Temp-Lora. Divisez chaque document en segments de 0 à 100 000 à plus de 500 000 jetons.
On peut voir que le PPL de tous les modèles a diminué de manière significative après Temp-Lora, et à mesure que les clips deviennent de plus en plus longs, l'impact de Temp-Lora est plus évident (1-100K n'a diminué que de 3,6%, 500K+ a diminué de 13,2%) .
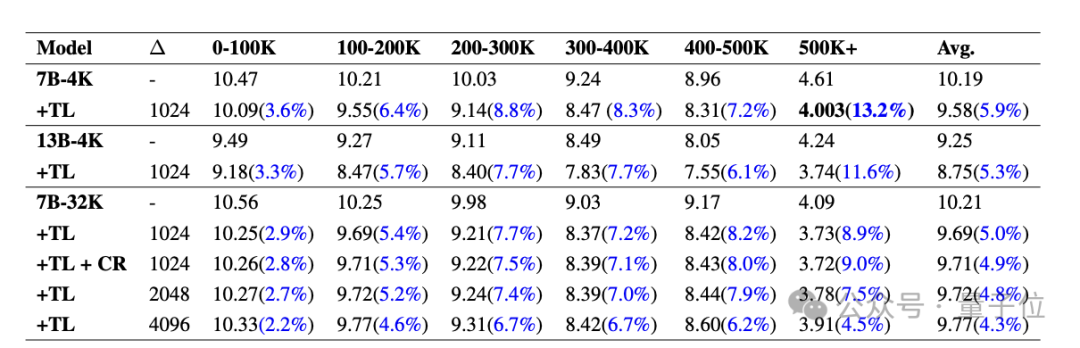
Par conséquent, nous pouvons simplement conclure : Plus il y a de texte, plus la nécessité d'utiliser Temp-Lora est forte.
De plus, nous pouvons constater que l'ajustement de la taille du bloc de 1024 à 2048 et 4096 entraîne une légère augmentation du PPL.
Ce n'est pas surprenant, après tout, le module Temp-Lora est entraîné sur les données du bloc précédent.
Ces données nous indiquent principalement que le choix de la taille des blocs est un compromis clé entre la qualité de la génération et l'efficacité des calculs (une analyse plus approfondie peut être trouvée dans l'article) .
Enfin, nous pouvons également constater que la réutilisation du cache n'entraînera aucune perte de performances. L'auteur a déclaré : C'est une nouvelle très encourageante.Voici les résultats sur l'ensemble de données Guofeng.
On constate que Temp-Lora a également un impact significatif sur les tâches de traduction littéraire de textes longs. Améliorations significatives de toutes les métriques par rapport au modèle de base : -29,6 % de réduction du PPL, +53,2 % d'amélioration du score BLEU(similarité du texte traduit automatiquement avec des traductions de référence de haute qualité), +53,2 % d'amélioration du score COMET (Egalement un indicateur de qualité) amélioré de +8,4%.
 Enfin, il y a l'exploration de l'efficacité et de la qualité informatiques.
Enfin, il y a l'exploration de l'efficacité et de la qualité informatiques.
L'auteur a découvert grâce à des expériences que l'utilisation de la
configuration Temp-Lora la plus "économique" (Δ=2K, W=4K) peut réduire le PPL de 3,8 % tout en économisant 70,5 % des FLOP et 51,5 % du délai. Au contraire, si nous ignorons complètement le coût de calcul et utilisons
la configuration la plus "luxueuse" (Δ=1K et W=24K), nous pouvons également obtenir une réduction de 5,0% du PPL et 17 $ supplémentaires % d'augmentation du FLOP et 19,6 % de latence. Suggestions d'utilisation
Pour résumer les résultats ci-dessus, l'auteur donne également trois suggestions pour l'application pratique de Temp-Lora :
1 Pour les applications qui nécessitent le plus haut niveau de génération de texte long, intégrez Temp sans modifier aucun paramètre. -Lora peut être ajoutée aux modèles existants pour améliorer considérablement les performances à un coût relativement modeste.
2. Pour les applications qui valorisent une latence ou une utilisation de la mémoire minimale, le coût de calcul peut être considérablement réduit en réduisant la longueur d'entrée et les informations contextuelles stockées dans Temp-Lora.
Dans ce paramètre, nous pouvons utiliser une taille de fenêtre courte fixe
(telle que 2K ou 4K)pour gérer un texte presque infiniment long (500K+ dans les expériences de l'auteur) . 3. Enfin, veuillez noter que dans les scénarios qui ne contiennent pas une grande quantité de texte, comme lorsque le contexte en pré-formation est plus petit que la taille de la fenêtre du modèle, Temp-Lora est inutile.
L'auteur appartient à une organisation confidentielle
Il est à noter que pour inventer une méthode aussi simple et innovante, l'auteur n'a pas laissé beaucoup d'informations sur la source :
Le nom de l'organisation est directement signé comme "Secrétaire de l'Organisation", et les noms des trois auteurs ne sont que des noms de famille complets.
 Cependant, à en juger par les informations envoyées par courrier électronique, il peut s'agir d'écoles telles que la City University of Hong Kong et la Hong Kong Chinese Language School.
Cependant, à en juger par les informations envoyées par courrier électronique, il peut s'agir d'écoles telles que la City University of Hong Kong et la Hong Kong Chinese Language School.
Au final, que pensez-vous de cette méthode ?
Papier :Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les modèles de données couramment utilisés ?
- Quels sont les trois types de modèles de données de base de données ?
- Quels sont les quatre modèles courants de développement de logiciels ?
- Une autre révolution dans l'apprentissage par renforcement ! DeepMind propose une « distillation d'algorithmes » : un transformateur d'apprentissage par renforcement pré-entraîné explorable
- Yunshenchen et Shengteng CANN travaillent ensemble pour ouvrir un camp d'entraînement de développement de chiens robots à quatre pattes ROS