
Maison > Article > Périphériques technologiques > Apple utilise des modèles de langage autorégressifs pour pré-entraîner les modèles d'image
Apple utilise des modèles de langage autorégressifs pour pré-entraîner les modèles d'image

- 王林avant
- 2024-01-29 09:18:27967parcourir
1.Contexte
Après l'émergence de grands modèles tels que GPT, la méthode de modélisation autorégressive Transformer + du modèle de langage, qui est la tâche de pré-entraînement consistant à prédire le prochain jeton, a remporté un grand succès. Alors, cette méthode de modélisation autorégressive peut-elle obtenir de meilleurs résultats dans les modèles visuels ? L'article présenté aujourd'hui est un article récemment publié par Apple sur la formation d'un modèle visuel basé sur la pré-formation Transformer + autorégressive. Laissez-moi vous présenter ce travail.
 Pictures
Pictures
Titre de l'article : Pré-formation évolutive de grands modèles d'images autorégressives
Adresse de téléchargement : https://arxiv.org/pdf/2401.08541v1.pdf
Code source ouvert : https://github .com/apple/ml-aim
2. Structure du modèle
La structure du modèle est basée sur Transformer et utilise la prédiction du prochain jeton dans le modèle de langage comme objectif d'optimisation. Les principales modifications portent sur trois aspects. Tout d'abord, contrairement à ViT, cet article utilise l'attention unidirectionnelle de GPT, c'est-à-dire que l'élément à chaque position ne calcule l'attention qu'avec l'élément précédent. Deuxièmement, nous introduisons davantage d'informations contextuelles pour améliorer les capacités de compréhension du langage du modèle. Enfin, nous avons optimisé les paramètres du modèle pour améliorer encore les performances. Grâce à ces améliorations, notre modèle réalise des gains de performances significatifs sur les tâches linguistiques.
 Picture
Picture
Dans le modèle Transformer, un nouveau mécanisme est introduit, c'est-à-dire que plusieurs jetons de préfixe sont ajoutés devant la séquence d'entrée. Ces jetons utilisent un mécanisme d'attention bidirectionnel. L'objectif principal de ce changement est d'améliorer la cohérence entre les applications de pré-formation et en aval. Dans les tâches en aval, des méthodes d'attention bidirectionnelles similaires à ViT sont largement utilisées. En introduisant une attention bidirectionnelle préfixe dans le processus de pré-formation, le modèle peut mieux s'adapter aux besoins des diverses tâches en aval. De telles améliorations peuvent améliorer les performances et les capacités de généralisation du modèle.
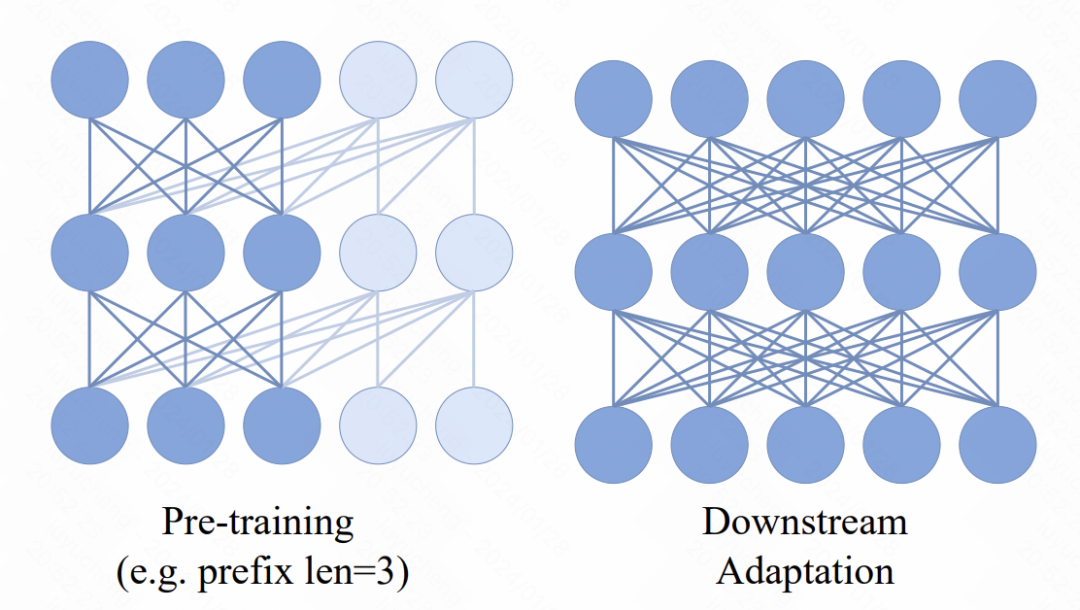 Picture
Picture
En termes d'optimisation de la couche MLP de sortie finale du modèle, la méthode de pré-entraînement d'origine supprime généralement la couche MLP et utilise un tout nouveau MLP dans les tâches en aval. Il s'agit d'éviter que le MLP pré-entraîné ne soit trop orienté vers la tâche de pré-formation, ce qui entraînerait une diminution de l'efficacité des tâches en aval. Cependant, dans cet article, les auteurs proposent une nouvelle approche. Ils utilisent un MLP indépendant pour chaque patch, et utilisent également la fusion de la représentation et de l'attention de chaque patch pour remplacer l'opération de pooling traditionnelle. De cette manière, la convivialité du responsable MLP pré-entraîné dans les tâches en aval est améliorée. Grâce à cette méthode, les auteurs peuvent mieux conserver les informations de l'image globale et éviter le problème d'une dépendance excessive aux tâches de pré-formation. Ceci est très utile pour améliorer la capacité de généralisation et l’adaptabilité du modèle.
Concernant l'objectif d'optimisation, l'article a essayé deux méthodes. La première consiste à ajuster directement les pixels du patch et à utiliser MSE pour la prédiction. La seconde consiste à tokeniser le patch d'image à l'avance, à le convertir en tâche de classification et à utiliser la perte d'entropie croisée. Cependant, dans les expériences d'ablation ultérieures de l'article, il a été constaté que bien que la deuxième méthode puisse également permettre au modèle d'être entraîné normalement, l'effet n'est pas aussi bon que celui basé sur la granularité des pixels MSE.
3. Résultats expérimentaux
La partie expérimentale de l'article analyse en détail l'effet de ce modèle d'image basé sur l'autorégression et l'impact de chaque partie sur l'effet.
Tout d'abord, à mesure que la formation progresse, la tâche de classification d'images en aval s'améliore de plus en plus, indiquant que cette méthode de pré-formation peut effectivement apprendre de bonnes informations sur la représentation d'image.
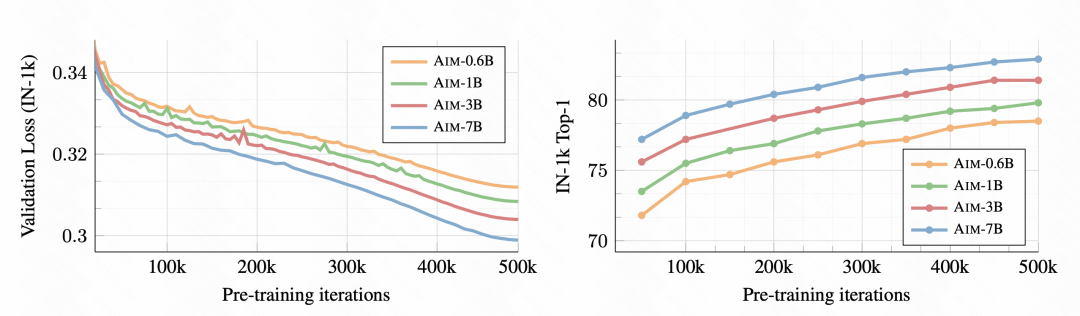 Photo
Photo
Sur les données d'entraînement, l'entraînement avec un petit ensemble de données entraînera un surapprentissage. Cependant, en utilisant DFN-2B, bien que la perte de l'ensemble de vérification initiale soit plus importante, il n'y a pas de problème de surapprentissage évident.
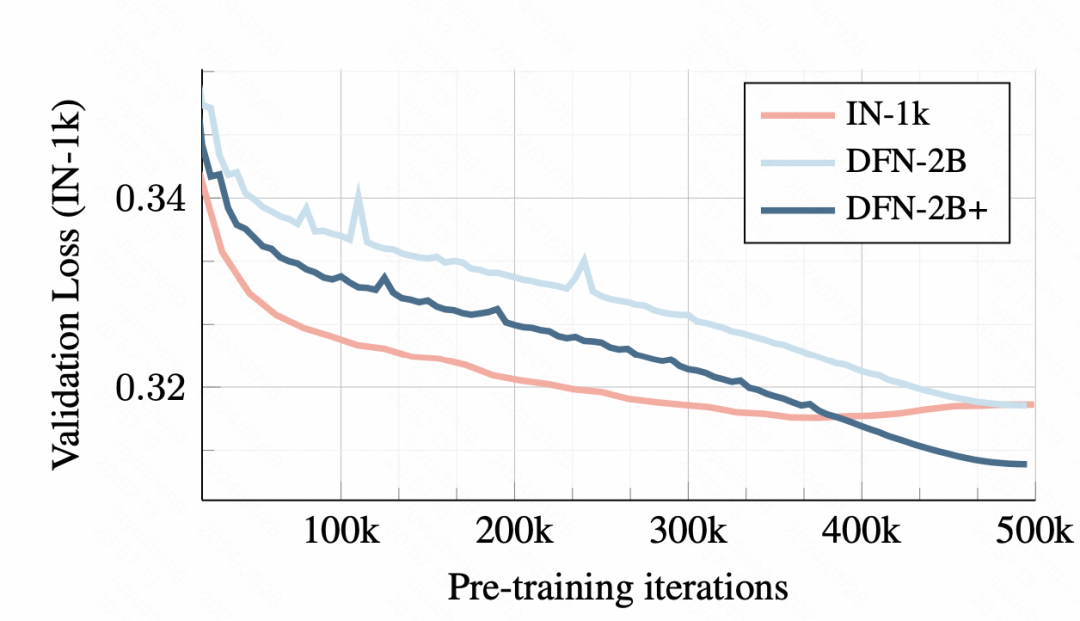 Photos
Photos
Pour la conception de chaque module du modèle, l'article effectue également une analyse détaillée de l'expérience d'ablation.
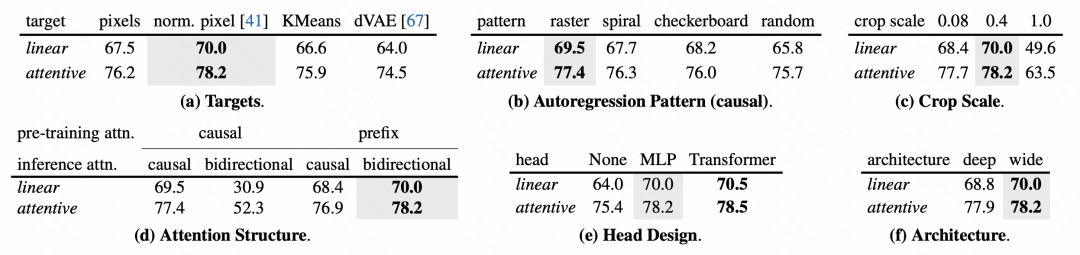 Photos
Photos
Dans la comparaison finale des effets, AIM a obtenu de très bons résultats, ce qui vérifie également que cette méthode de pré-entraînement autorégressive est également disponible sur les images, et peut devenir une méthode de pré-entraînement de grand modèle pour les images suivantes . L'un des principaux moyens de formation.
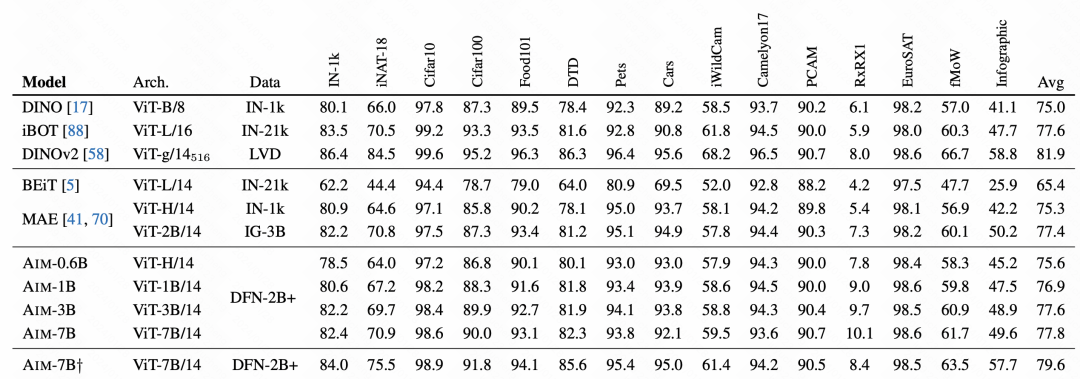 Photos
Photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment ajouter du texte sur une image en utilisant HTML et CSS ? (exemple de code)
- Quelle norme de codage de compression d’image est JPEG ?
- Quels sont les modèles de données pris en charge par le système de gestion de base de données Access2010 ?
- Ce que vous pouvez faire avec l'outil Dodge lors de l'édition d'une image
- Comment effacer l’historique des images récentes de l’arrière-plan du bureau dans Windows 11