
Maison >Périphériques technologiques >IA >Les grands modèles multimodaux sont préférés par les jeunes en ligne avec l'open source : exécutez facilement 1080Ti
Les grands modèles multimodaux sont préférés par les jeunes en ligne avec l'open source : exécutez facilement 1080Ti

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-29 09:15:261119parcourir
Un "premier grand modèle multimodal pour les jeunes" baptisé Vary-toy est là !
La taille du modèle est inférieure à 2B, il peut être entraîné sur des cartes graphiques grand public et il peut fonctionner facilement sur les anciennes cartes graphiques GTX1080ti 8G.
Vous souhaitez convertir une image de document au format Markdown ? Dans le passé, plusieurs étapes telles que la reconnaissance de texte, la détection et le tri de la mise en page, le traitement des tableaux de formules et le nettoyage du texte étaient nécessaires.
Maintenant, vous n'avez besoin que d'une seule commande :
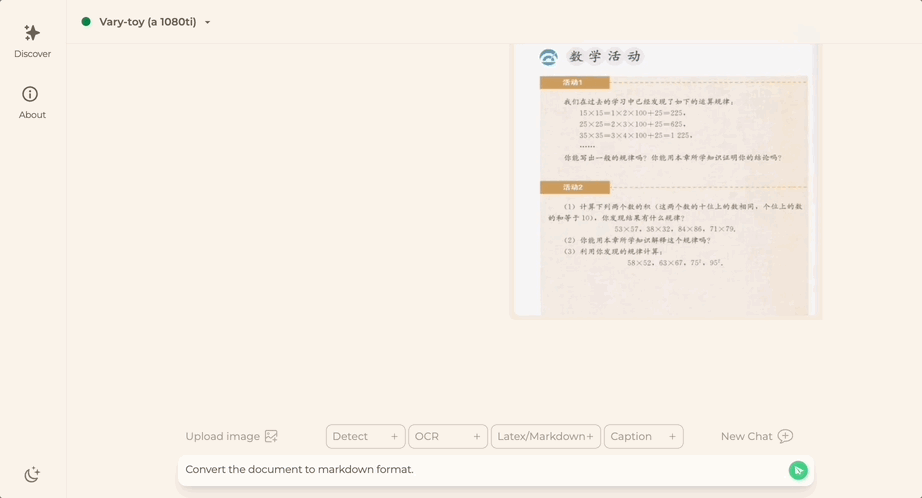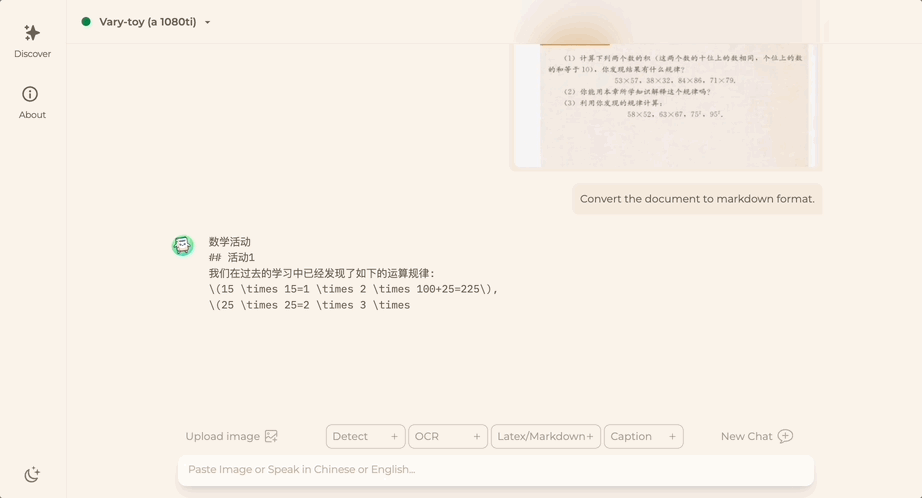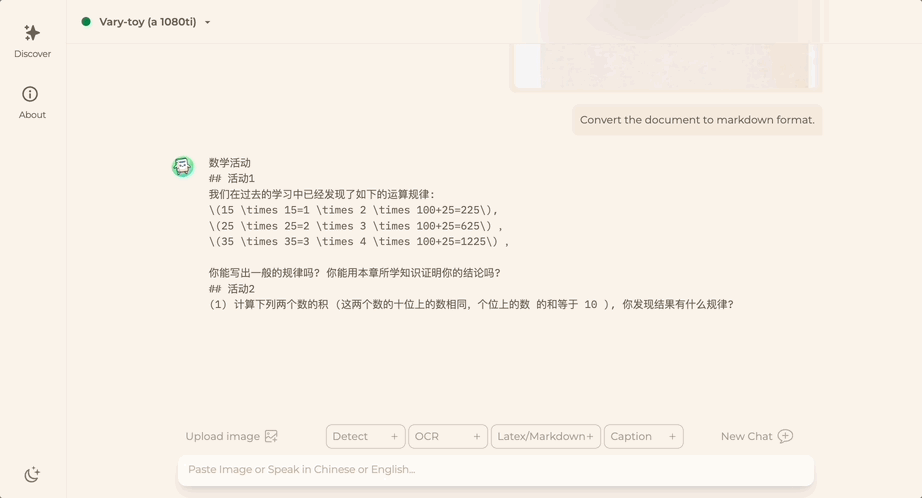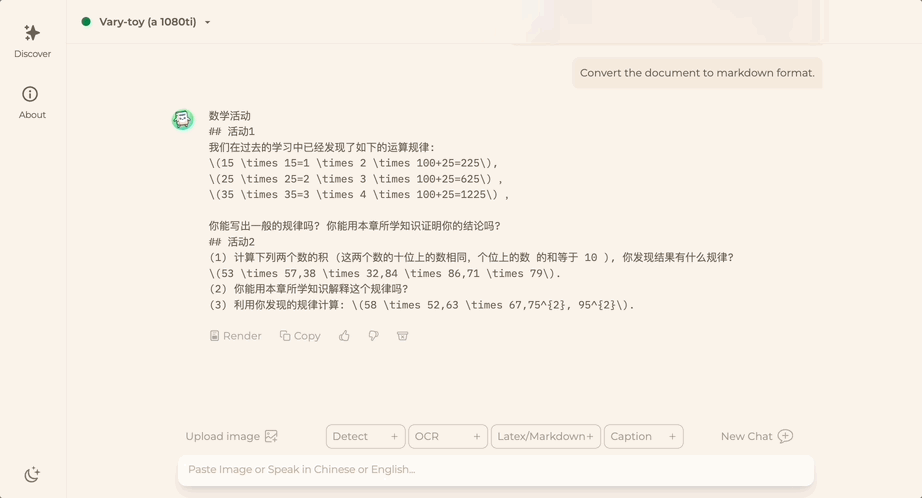
Peu importe Chinois ou Anglais, le texte volumineux dans l'image peut être extrait en quelques minutes :

La détection d'objet sur une image peut toujours donner le type avec des coordonnées :

Cette étude a été proposée conjointement par des chercheurs de Megvii, de l'Université nationale des sciences et technologies et de l'Université de Huazhong.
Selon les rapports, bien que Vary-toy soit petit, il couvre presque toutes les capacités de la recherche actuelle du LVLM(Large Visual Language Model) : reconnaissance OCR de documents(OCR de documents), positionnement visuel(Visual Grounding ) , Légende de l'image, Réponse visuelle aux questions (VQA) .


ancienne·GTX1080, et se sont dit :

, mais de nombreuses personnes ne peuvent pas l'exécuter en raison de ressources limitées.
Considérant qu'il existe relativement peu de « petits » VLM bien open source et offrant d'excellentes performances, l'équipe a récemment lancé Vary-toy, connu comme « le premier grand modèle multimode pour les jeunes ». Par rapport à Vary, Vary-toy est non seulement plus petit, mais entraîne également unvocabulaire visuel plus fort Le nouveau vocabulaire ne limite plus le modèle à l'OCR au niveau du document, mais donne une liste de vocabulaire visuel plus universelle et complète. , qui peut non seulement effectuer une OCR au niveau du document, mais également une détection visuelle générale de cibles. Alors, comment ça se passe ?
La structure du modèle et le processus de formation de Vary-toy sont présentés dans la figure ci-dessous. En général, la formation est divisée en deux étapes.
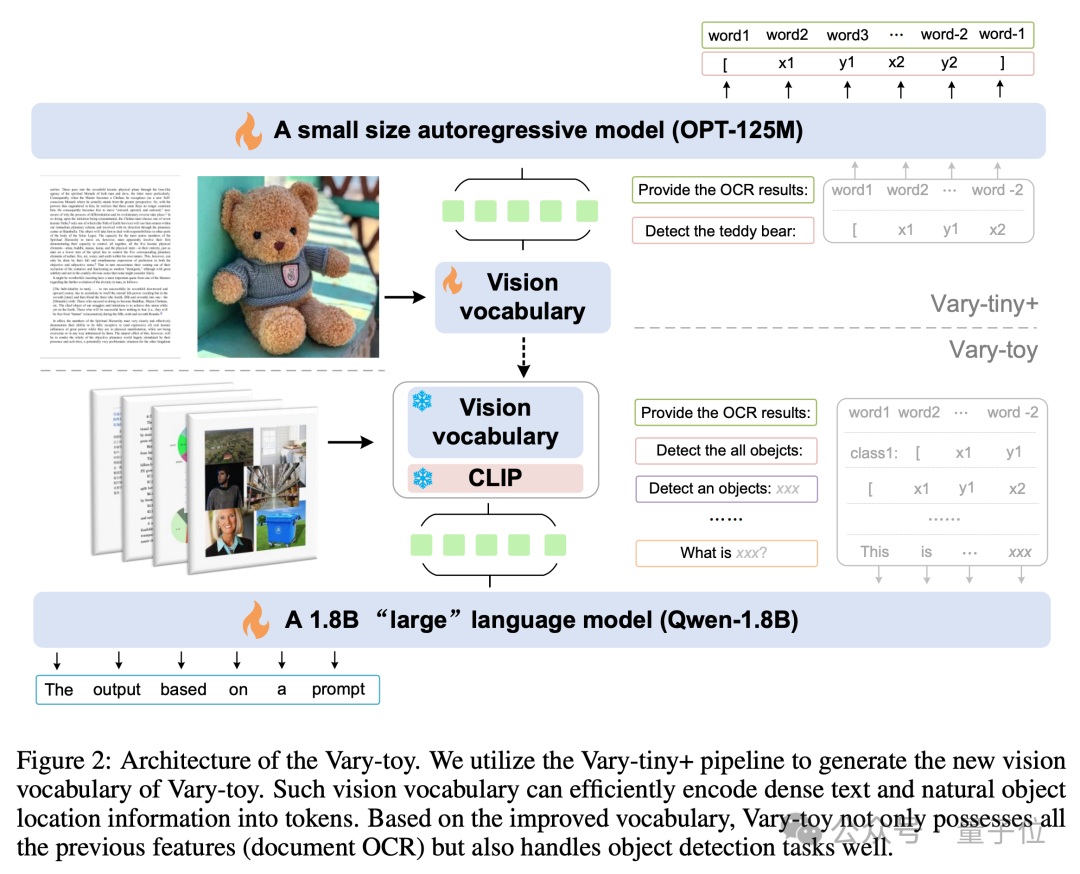 Tout d'abord, dans la première étape, la structure Vary-tiny+ est utilisée pour pré-entraîner un vocabulaire visuel meilleur que le Vary original. Le nouveau vocabulaire visuel résout le problème que le Vary original ne l'utilise que. pour l'OCR au niveau du document Le problème du gaspillage de capacité et le problème de ne pas utiliser pleinement les avantages de la pré-formation SAM.
Tout d'abord, dans la première étape, la structure Vary-tiny+ est utilisée pour pré-entraîner un vocabulaire visuel meilleur que le Vary original. Le nouveau vocabulaire visuel résout le problème que le Vary original ne l'utilise que. pour l'OCR au niveau du document Le problème du gaspillage de capacité et le problème de ne pas utiliser pleinement les avantages de la pré-formation SAM.
Puis dans la deuxième étape, le vocabulaire visuel formé lors de la première étape est fusionné dans la structure finale pour une formation multitâche/SFT.
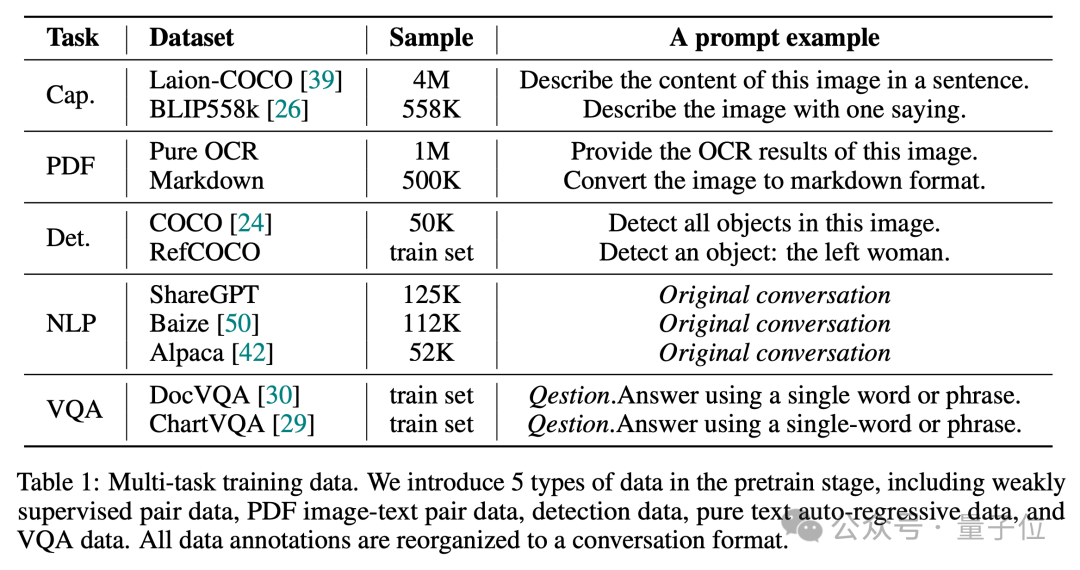
Comme nous le savons tous, un bon ratio de données est crucial pour générer un VLM doté de fonctionnalités complètes.
Ainsi, dans la phase de pré-formation, Vary-toy a utilisé les données de 5 types de tâches pour construire le dialogue. Le rapport de données et les exemples d'invites sont présentés dans la figure ci-dessous :
 Dans la phase SFT, uniquement LLaVA. -80 000 données ont été utilisées. Pour plus de détails techniques, veuillez consulter le rapport technique de Vary-toy.
Dans la phase SFT, uniquement LLaVA. -80 000 données ont été utilisées. Pour plus de détails techniques, veuillez consulter le rapport technique de Vary-toy.
Résultats des tests expérimentaux
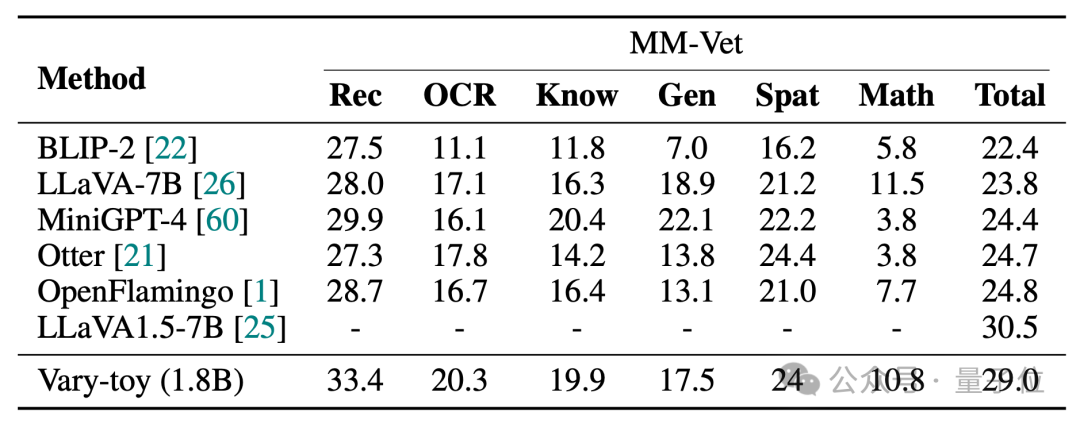
Les scores de Vari-toy dans les quatre tests de référence de DocVQA, ChartQA, RefCOCO et MMVet sont les suivants :
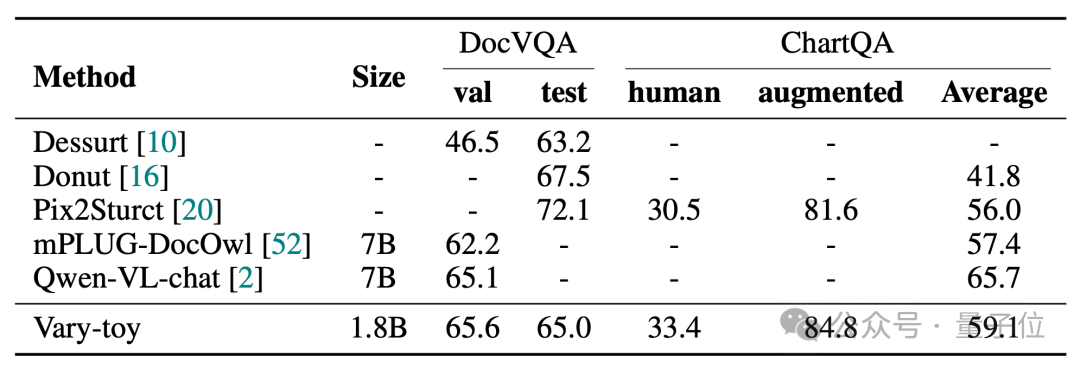
Vary-toy peut atteindre 65,6 % d'ANLS sur DocVQA, 59,1 % de précision sur ChartQA et 88,1 % de précision sur RefCOCO :
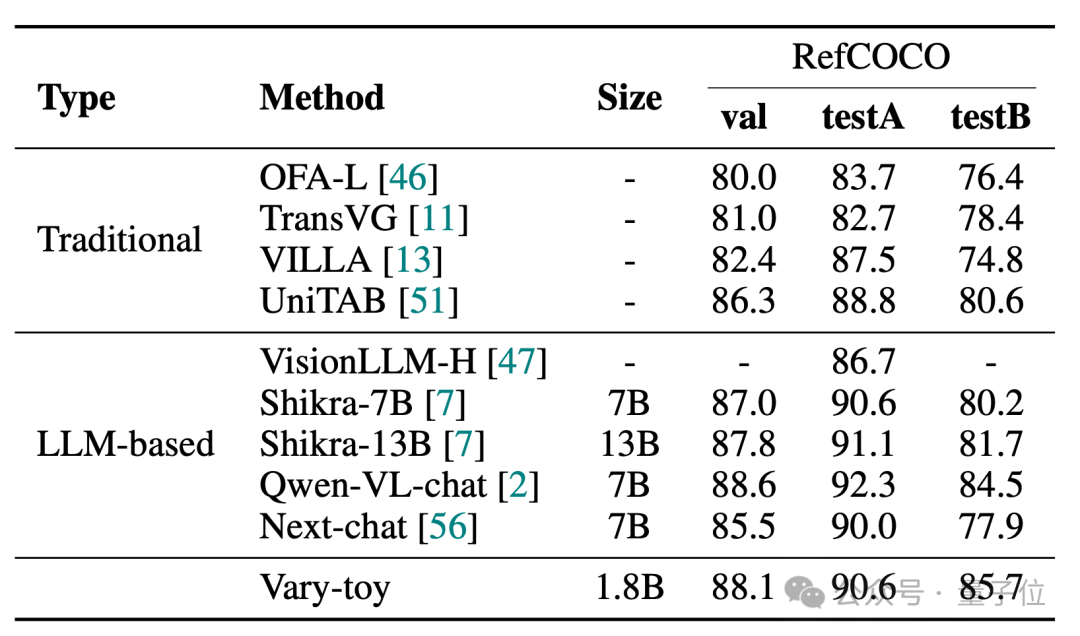
MMVet peut atteindre 29 % de précision, que ce soit en termes de scores de référence ou d'effets de visualisation. , Vary-toy, qui est inférieur à 2B, peut même rivaliser avec les performances de certains modèles 7B populaires.
Lien du projet :
[1]https://arxiv.org/abs/2401.12503
[3]https://varytoy.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment exporter un modèle dans Navicat
- À quel type de modèle de données appartient le serveur SQL ?
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Comment importer la mise en page du modèle CAO
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?