
Maison >Périphériques technologiques >IA >Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-26 11:18:281744parcourir
0. Écrit devant et& compréhension personnelle
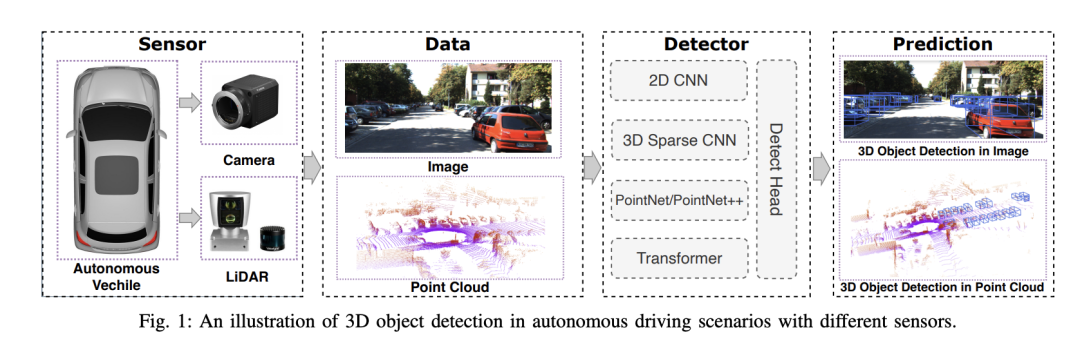
Le système de conduite autonome s'appuie sur une technologie avancée de perception, de prise de décision et de contrôle pour percevoir l'environnement grâce à l'utilisation de divers capteurs (tels que des caméras, un lidar, un radar, etc. .), et utiliser des algorithmes et des modèles pour l’analyse et la prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite des algorithmes de détection d'objets 3D dans les systèmes de conduite autonome, capables de percevoir et de décrire avec précision les objets dans l'environnement, y compris leur emplacement, leur forme, leur taille et leur catégorie. Cette conscience environnementale globale aide les systèmes de conduite autonome à mieux comprendre l’environnement de conduite et à prendre des décisions plus précises.
Nous avons mené une évaluation complète des algorithmes de détection d'objets 3D dans la conduite autonome, en considérant principalement la robustesse. Trois facteurs clés ont été identifiés lors de l'évaluation : la variabilité environnementale, le bruit des capteurs et le désalignement. Ces facteurs sont importants pour les performances des algorithmes de détection dans des conditions changeantes du monde réel.
- Variabilité environnementale : L'article souligne que l'algorithme de détection doit s'adapter à différentes conditions environnementales, telles que les changements d'éclairage, la météo et les saisons.
- Bruit du capteur : L'algorithme doit gérer efficacement le bruit du capteur, qui peut inclure des problèmes tels que le flou de mouvement de la caméra.
- Désalignement : Pour un désalignement causé par des erreurs d'étalonnage ou d'autres facteurs, l'algorithme doit prendre en compte ces facteurs, qu'ils soient externes (comme des surfaces routières inégales) ou internes (comme un désalignement de l'horloge système).
Plonge également dans trois domaines clés de l'évaluation des performances : la précision, la latence et la robustesse.
- Précision : Bien que les études se concentrent souvent sur la précision en tant que mesure de performance clé, les performances dans des conditions complexes et extrêmes nécessitent une compréhension plus approfondie pour garantir une fiabilité réelle.
- Latence : Les capacités en temps réel en matière de conduite autonome sont cruciales. Les retards dans les méthodes de détection ont un impact sur la capacité du système à prendre des décisions en temps opportun, notamment dans les situations d'urgence.
- Robustesse : appelle à une évaluation plus complète de la stabilité du système dans différentes conditions, car de nombreuses évaluations actuelles ne tiennent peut-être pas pleinement compte de la diversité des scénarios du monde réel.
L'article souligne les avantages significatifs des méthodes de détection 3D multimodales dans la perception de la sécurité. En fusionnant les données de différents capteurs, il offre des capacités de perception plus riches et diversifiées, améliorant ainsi la sécurité des systèmes de conduite autonome.
1. Ensemble de données
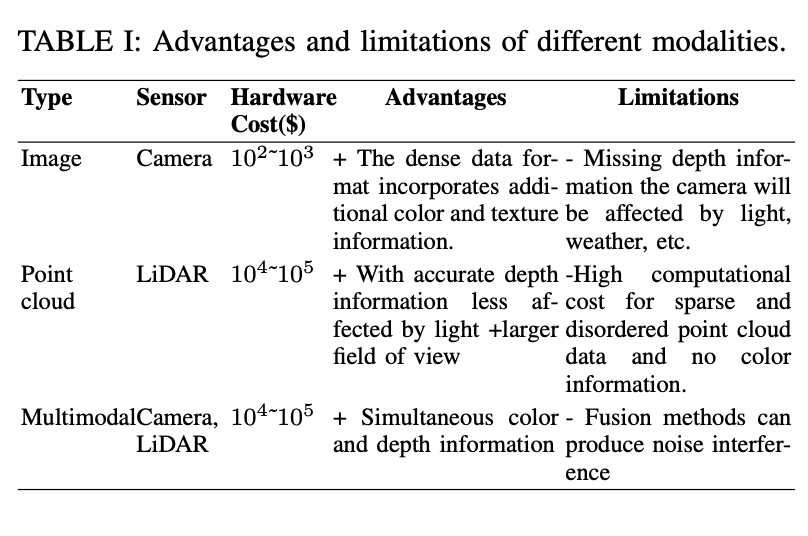
Ce qui précède présente brièvement l'ensemble de données de détection d'objets 3D utilisé dans les systèmes de conduite autonome, en se concentrant principalement sur l'évaluation des avantages et des limites des différents modes de capteur, ainsi que sur les caractéristiques des ensembles de données publics. .
Tout d'abord, le tableau présente trois types de capteurs : caméra, nuage de points et multimodal (caméra et lidar). Pour chaque type, leurs coûts matériels, leurs avantages et leurs limites sont répertoriés. L’avantage des données de caméra est qu’elles fournissent des informations riches sur les couleurs et les textures, mais leurs limites résident dans le manque d’informations sur la profondeur et dans leur sensibilité aux effets de la lumière et des conditions météorologiques. Le LiDAR peut fournir des informations précises sur la profondeur, mais il est coûteux et ne contient aucune information sur la couleur.
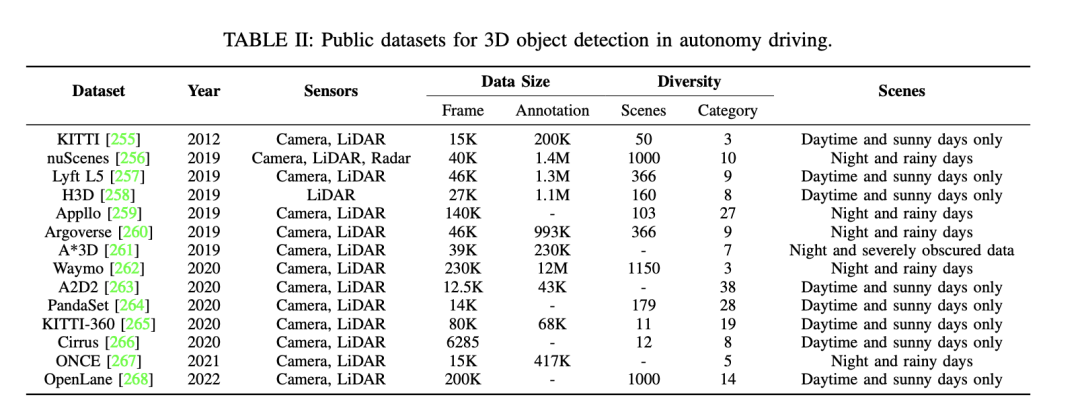
Ensuite, il existe d'autres ensembles de données publics disponibles pour la détection d'objets 3D dans la conduite autonome. Ces ensembles de données incluent KITTI, nuScenes, Waymo, etc. Les détails de ces ensembles de données sont les suivants : - L'ensemble de données KITTI contient des données publiées sur plusieurs années, utilisant différents types de capteurs. Il fournit un grand nombre d'images et d'annotations, ainsi qu'une variété de scènes, y compris des numéros et des catégories de scènes, et différents types de scènes tels que jour, ensoleillé, nuit, pluvieux, etc. - L'ensemble de données nuScenes est également un ensemble de données important, qui contient également des données publiées sur plusieurs années. Cet ensemble de données utilise une variété de capteurs et fournit un grand nombre d'images et d'annotations. Il couvre une variété de scénarios, y compris différents numéros et catégories de scènes, ainsi que divers types de scènes. - L'ensemble de données Waymo est un autre ensemble de données pour la conduite autonome qui contient également des données sur plusieurs années. Cet ensemble de données utilise différents types de capteurs et fournit un grand nombre d'images et d'annotations. Il couvre divers domaines
De plus, la recherche sur les ensembles de données de conduite autonome « propre » est mentionnée et l'importance d'évaluer la robustesse du modèle dans des scénarios bruyants est soulignée. Certaines études se concentrent sur les méthodes monomodales des caméras dans des conditions difficiles, tandis que d'autres ensembles de données multimodales se concentrent sur les problèmes de bruit. Par exemple, l'ensemble de données GROUNDED se concentre sur le positionnement du radar pénétrant dans le sol dans différentes conditions météorologiques, tandis que l'ensemble de données ouvert ApolloScape comprend des données lidar, caméra et GPS, couvrant une variété de conditions météorologiques et d'éclairage.
En raison du coût prohibitif de la collecte de données bruitées à grande échelle dans le monde réel, de nombreuses études se tournent vers l'utilisation d'ensembles de données synthétiques. Par exemple, ImageNet-C est une étude de référence dans la lutte contre les perturbations courantes dans les modèles de classification d'images. Cette direction de recherche a ensuite été étendue à des ensembles de données robustes adaptés à la détection d'objets 3D dans la conduite autonome.
2. Détection d'objets 3D basée sur la vision
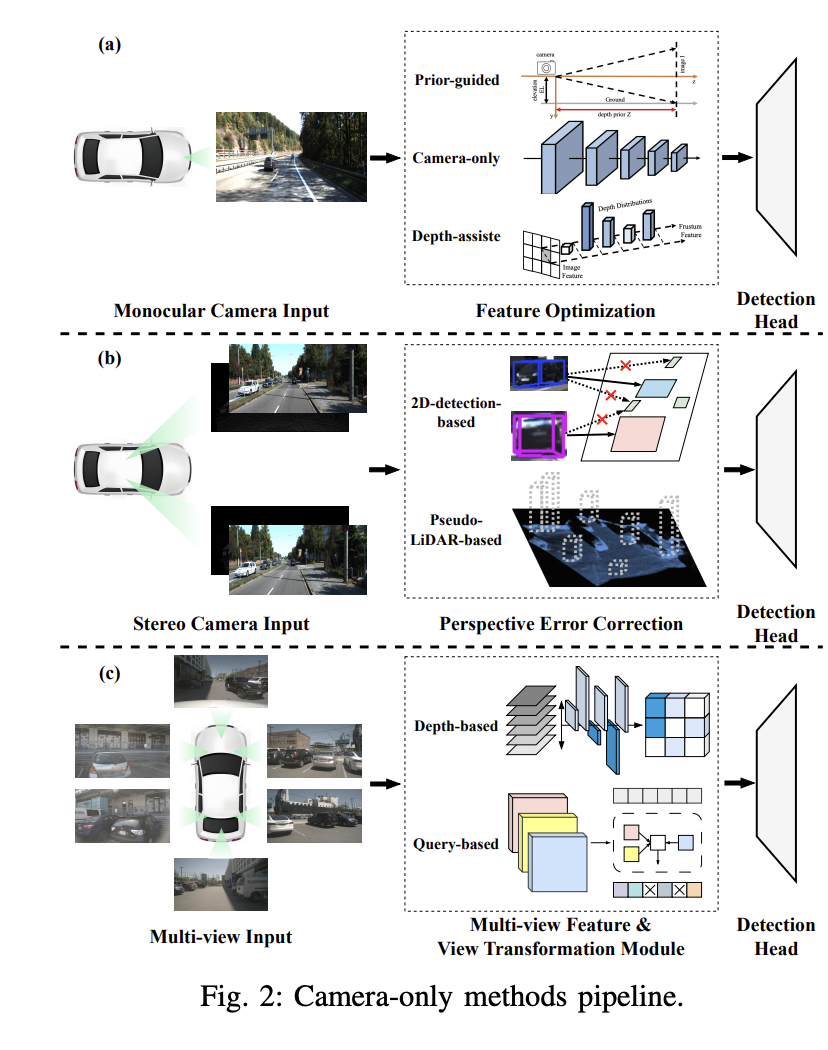
2.1 Détection d'objets 3D monoculaires
Dans cette partie, le concept de détection d'objets 3D monoculaires et trois méthodes principales sont abordés : basé sur le premier monoculaire expérimenté. Détection d'objets 3D, détection d'objets 3D monoculaires par caméra uniquement et détection d'objets 3D monoculaires assistée en profondeur.
Détection d'objets 3D monoculaires à guidage préalable
Cette méthode utilise une connaissance préalable des formes d'objets et de la géométrie de la scène cachée dans les images pour résoudre le défi de la détection d'objets 3D monoculaires. En introduisant des sous-réseaux pré-entraînés ou des tâches auxiliaires, les connaissances préalables peuvent fournir des informations ou des contraintes supplémentaires pour aider à localiser avec précision les objets 3D et améliorer la précision et la robustesse de la détection. Les connaissances antérieures communes incluent la forme de l'objet, la cohérence géométrique, les contraintes temporelles et les informations de segmentation. Par exemple, l'algorithme Mono3D suppose d'abord que l'objet 3D est situé sur un plan de sol fixe, puis utilise la forme 3D antérieure de l'objet pour reconstruire le cadre de délimitation dans l'espace 3D.

Détection d'objets 3D monoculaires par caméra uniquement
Cette méthode utilise uniquement des images capturées par une seule caméra pour détecter et localiser des objets 3D. Il utilise un réseau neuronal convolutif (CNN) pour régresser directement les paramètres du cadre de délimitation 3D à partir d'images afin d'estimer la taille et la pose des objets dans un espace tridimensionnel. Cette méthode de régression directe peut être entraînée de bout en bout, favorisant ainsi l'apprentissage et l'inférence globale d'objets 3D. Par exemple, l'algorithme Smoke abandonne la régression des boîtes englobantes 2D et prédit la boîte 3D de chaque objet détecté en combinant l'estimation de points clés individuels et la régression des variables 3D.
Détection d'objets 3D monoculaires assistée en profondeur
L'estimation de la profondeur joue un rôle clé dans la détection d'objets 3D monoculaires assistée en profondeur. Pour obtenir des résultats de détection monoculaire plus précis, de nombreuses études utilisent des réseaux d’estimation de profondeur auxiliaires pré-entraînés. Le processus commence par convertir l'image monoculaire en image de profondeur à l'aide d'un estimateur de profondeur pré-entraîné tel que MonoDepth. Ensuite, deux méthodes principales sont adoptées pour traiter les images de profondeur et les images monoculaires. Par exemple, le détecteur pseudo-LiDAR utilise un réseau d'estimation de profondeur pré-entraîné pour générer des représentations pseudo-LiDAR, mais il existe un énorme écart de performances entre les détecteurs pseudo-LiDAR et basés sur LiDAR en raison d'erreurs dans la génération d'image vers LiDAR.
Grâce à l'exploration et à l'application de ces méthodes, la détection d'objets 3D monoculaires a fait des progrès significatifs dans les domaines de la vision par ordinateur et des systèmes intelligents, apportant des percées et des opportunités dans ces domaines.
2.2 Détection d'objets 3D basée sur la stéréo
Dans cette partie, la technologie de détection d'objets 3D basée sur la vision stéréo est abordée. La détection d'objets 3D en vision stéréoscopique utilise une paire d'images stéréoscopiques pour identifier et localiser les objets 3D. En exploitant les doubles vues capturées par les caméras stéréo, ces méthodes excellent dans l’obtention d’informations de profondeur de haute précision grâce à la correspondance stéréo et à l’étalonnage, caractéristique qui les différencie des configurations de caméras monoculaires. Malgré ces avantages, les méthodes de vision stéréo souffrent encore d’un écart de performances considérable par rapport aux méthodes basées sur le lidar. De plus, le domaine de la détection d’objets 3D à partir d’images stéréoscopiques est relativement peu exploré, avec seulement des efforts de recherche limités consacrés à ce domaine.
- Méthodes basées sur la détection 2D : Le cadre traditionnel de détection d'objets 2D peut être modifié pour résoudre le problème de détection stéréo. Par exemple, Stereo R-CNN utilise un détecteur 2D basé sur l'image pour prédire les propositions 2D, générant des régions d'intérêt (RoI) gauche et droite pour les images gauche et droite correspondantes. Ensuite, dans un deuxième temps, il estime directement les paramètres de l’objet 3D sur la base des RoI générés précédemment. Ce paradigme a été largement adopté dans les travaux ultérieurs.
- Méthodes basées sur le pseudo-LiDAR : La carte de disparité prédite à partir de l'image stéréo peut être convertie en une carte de profondeur et ensuite convertie en pseudo points LiDAR. Par conséquent, à l’instar des méthodes de détection monoculaires, la représentation pseudo-lidar peut également être utilisée dans les méthodes de détection d’objets 3D basées sur la vision stéréo. Ces méthodes visent à améliorer l’estimation de la disparité dans l’appariement stéréo afin d’obtenir une prédiction de profondeur plus précise. Par exemple, Wang et al. ont été pionniers dans l’introduction de la représentation pseudo-lidar. Cette représentation est générée à partir d'une image avec une carte de profondeur, ce qui nécessite que le modèle effectue des tâches d'estimation de profondeur pour faciliter la détection. Les travaux ultérieurs ont suivi ce paradigme et l'ont affiné en introduisant des informations de couleur supplémentaires pour améliorer les nuages de pseudo-points, les tâches auxiliaires (telles que la segmentation d'instance, la segmentation de premier plan et d'arrière-plan, l'adaptation de domaine) et les schémas de transformation de coordonnées. Il convient de noter que PatchNet proposé par Ma et al. remet en question le concept traditionnel d'utilisation de la représentation pseudo-lidar pour la détection d'objets 3D monoculaires. En codant les coordonnées 3D pour chaque pixel, PatchNet peut obtenir des résultats de détection monoculaire comparables sans représentation pseudo-lidar. Cette observation suggère que la puissance de la représentation pseudo-lidar vient de la transformation des coordonnées plutôt que de la représentation du nuage de points elle-même.
2.3 Détection d'objets 3D multi-vues
Récemment, la détection d'objets 3D multi-vues a montré une supériorité en termes de précision et de robustesse par rapport aux méthodes de détection d'objets 3D à vision monoculaire et stéréo susmentionnées. Contrairement à la détection d'objets 3D basée sur LiDAR, la dernière méthode panoramique Bird's Eye View (BEV) élimine le besoin de cartes de haute précision et élève la détection de la 2D à la 3D. Ces progrès ont conduit à des développements significatifs dans la détection d’objets 3D multi-vues. Dans la détection d'objets 3D multi-caméras, le principal défi consiste à identifier le même objet dans différentes images et à regrouper les caractéristiques du corps à partir de plusieurs angles de vue. Les méthodes actuelles impliquent de mapper uniformément plusieurs vues dans l'espace Bird's Eye View (BEV), ce qui est une pratique courante.
Méthodes multi-vues basées sur la profondeur :
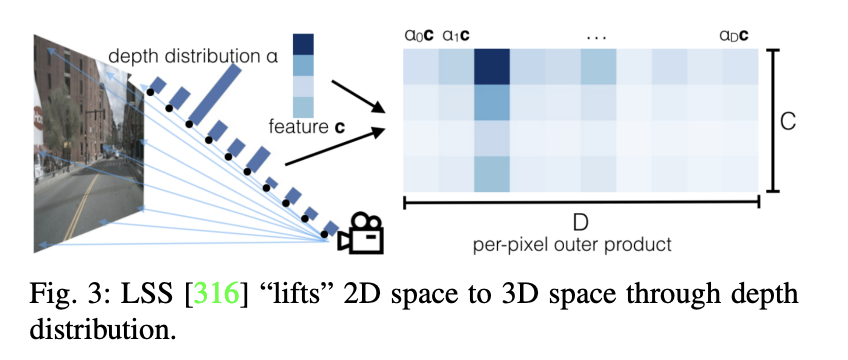
La conversion directe de l'espace 2D vers l'espace BEV pose un défi important. LSS est le premier à proposer une méthode basée sur la profondeur, qui utilise l'espace 3D comme intermédiaire. Cette méthode prédit d'abord la distribution de la profondeur de grille des entités 2D, puis élève ces entités dans l'espace voxel. Cette approche laisse espérer une transformation plus efficace de l’espace 2D vers l’espace BEV. Suite au LSS, CaDDN adopte une méthode de représentation profonde similaire. En compressant les caractéristiques de l'espace voxel dans l'espace BEV, il effectue la détection 3D finale. Il convient de noter que CaDDN ne fait pas partie de la détection d'objets 3D multi-vues, mais de la détection d'objets 3D à vue unique, ce qui a eu un impact sur les recherches approfondies ultérieures. La principale différence entre LSS et CaDDN est que CaDDN utilise les valeurs réelles de profondeur de la vérité terrain pour superviser la prédiction de sa distribution de profondeur de classification, créant ainsi un réseau profond supérieur capable d'extraire plus précisément les informations 3D de l'espace 2D.
Méthodes multi-vues basées sur des requêtes
Sous l'influence de la technologie Transformer, les méthodes multi-vues basées sur des requêtes récupèrent les caractéristiques de l'espace 2D à partir de l'espace 3D. DETR3D introduit la requête d'objets 3D pour résoudre le problème d'agrégation des fonctionnalités multi-vues. Il obtient des caractéristiques d'image dans l'espace Bird's Eye View (BEV) en découpant les caractéristiques d'image de différents points de vue et en les projetant dans un espace 2D à l'aide de points de référence 3D appris. Différente de la méthode multi-vues basée sur la profondeur, la méthode multi-vues basée sur des requêtes obtient des fonctionnalités BEV clairsemées en utilisant la technologie de requête inversée, ce qui affecte fondamentalement le développement ultérieur basé sur des requêtes. Cependant, en raison d'inexactitudes potentielles associées aux points de référence 3D explicites, PETR a adopté une méthode de codage de position implicite pour construire l'espace BEV, affectant les travaux ultérieurs.
2.4 Analyse : Précision, Latence, Robustesse
Actuellement, les solutions de détection d'objets 3D basées sur la perception Bird's Eye View (BEV) se développent rapidement. Malgré l’existence de nombreux articles de synthèse, une revue exhaustive de ce domaine reste encore insuffisante. Le Shanghai AI Lab et le SenseTime Research Institute proposent un examen approfondi de la feuille de route technologique des solutions BEV. Cependant, contrairement aux études existantes, nous prenons en compte des aspects clés tels que la perception de la sécurité de la conduite autonome. Après avoir analysé la feuille de route technologique et l'état actuel du développement des solutions basées sur des caméras, nous avons l'intention de discuter sur la base des principes de base de « Précision, latence, robustesse ». Nous intégrerons la perspective de la sensibilisation à la sécurité pour guider la mise en œuvre pratique de la sensibilisation à la sécurité dans la conduite autonome.
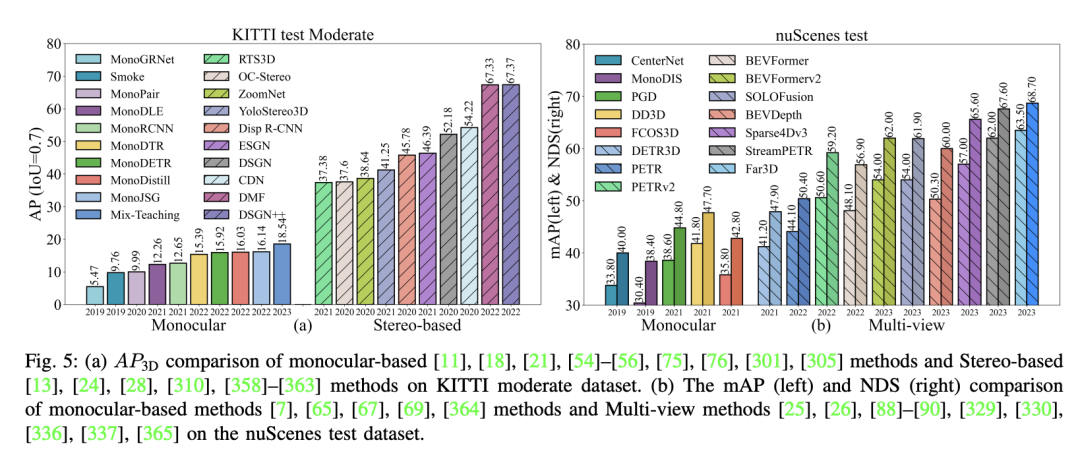
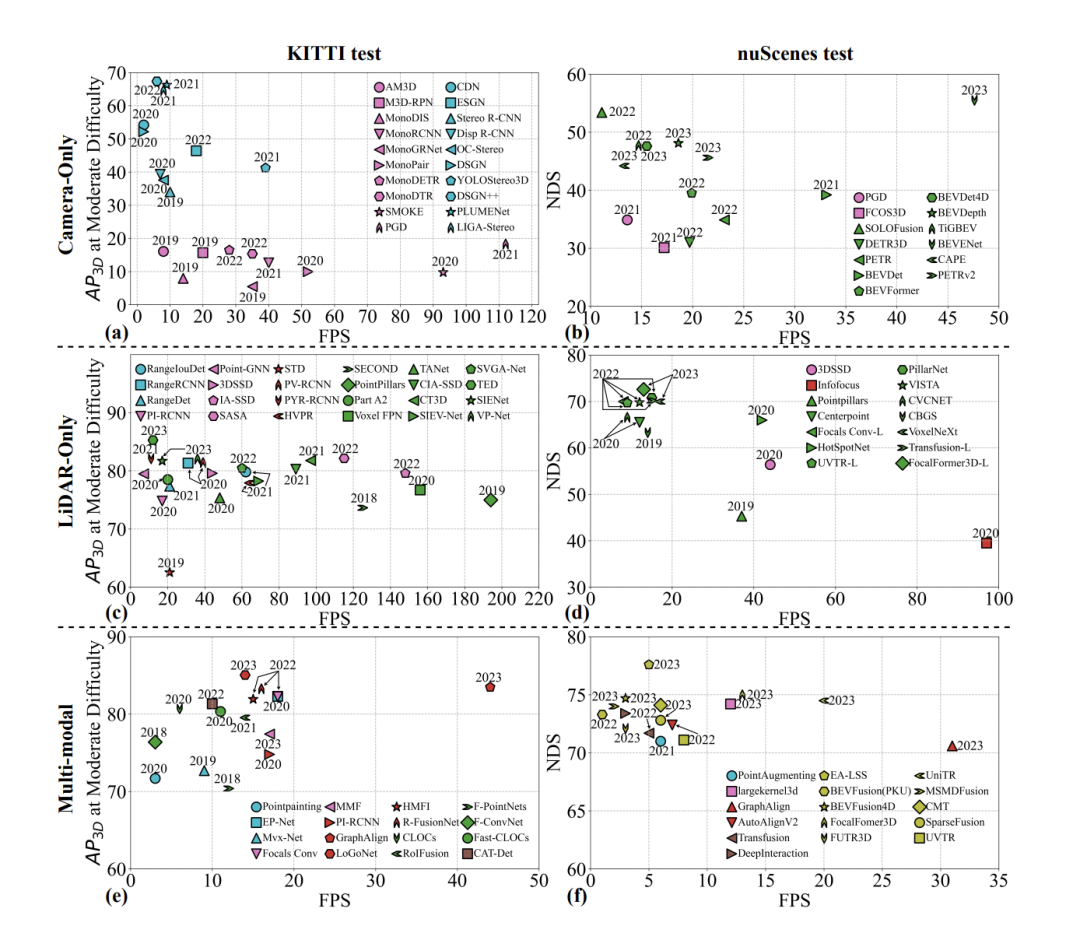
- Précision : la plupart des articles de recherche et des revues mettent beaucoup l'accent sur l'exactitude, et c'est vraiment important. Bien que l’exactitude puisse être reflétée par l’AP (précision moyenne), la prise en compte de l’AP seule peut ne pas fournir une perspective globale, car différentes méthodes peuvent présenter des différences significatives en raison de différents paradigmes. Comme le montre la figure, nous avons sélectionné 10 méthodes représentatives à des fins de comparaison, et les résultats montrent qu'il existe des différences métriques significatives entre la détection d'objets 3D monoculaires et la détection d'objets 3D stéréoscopiques. La situation actuelle montre que la précision de la détection d’objets 3D monoculaires est bien inférieure à celle de la détection d’objets 3D stéréoscopiques. La détection d'objets 3D en vision stéréo utilise des images capturées sous deux perspectives différentes de la même scène pour obtenir des informations sur la profondeur. Plus la ligne de base entre les caméras est grande, plus la gamme d'informations de profondeur capturées est large. Au fil du temps, la détection d'objets 3D multi-vues (perception à vol d'oiseau) a progressivement remplacé les méthodes monoculaires, améliorant considérablement le mAP. L’augmentation du nombre de capteurs a un impact significatif sur mAP.
- Latence : Dans le domaine de la conduite autonome, la latence est cruciale. Il fait référence au temps nécessaire à un système pour réagir à un signal d'entrée, y compris l'ensemble du processus, depuis la collecte des données des capteurs jusqu'à la prise de décision du système et l'exécution des actions. En conduite autonome, les exigences en matière de latence sont très strictes, car toute forme de latence peut entraîner de graves conséquences. L'importance de la latence dans la conduite autonome se reflète dans les aspects suivants : réactivité en temps réel, sécurité, expérience utilisateur, interactivité et réponse d'urgence. Dans le domaine de la détection d’objets 3D, la latence (images par seconde, FPS) et la précision sont des indicateurs clés pour évaluer les performances des algorithmes. Comme le montre la figure, le graphique de détection d'objets 3D en vision monoculaire et stéréo montre la précision moyenne (AP) par rapport au FPS pour des niveaux de difficulté égaux dans l'ensemble de données KITTI. Pour la mise en œuvre de la conduite autonome, les algorithmes de détection d’objets 3D doivent trouver un équilibre entre latence et précision. Si la détection monoculaire est rapide, elle manque de précision, à l'inverse, les méthodes stéréo et multi-vues sont précises mais plus lentes ; Les recherches futures devraient non seulement maintenir une précision élevée, mais également accorder davantage d'attention à l'amélioration des FPS et à la réduction de la latence afin de répondre aux doubles exigences de réactivité en temps réel et de sécurité dans la conduite autonome.
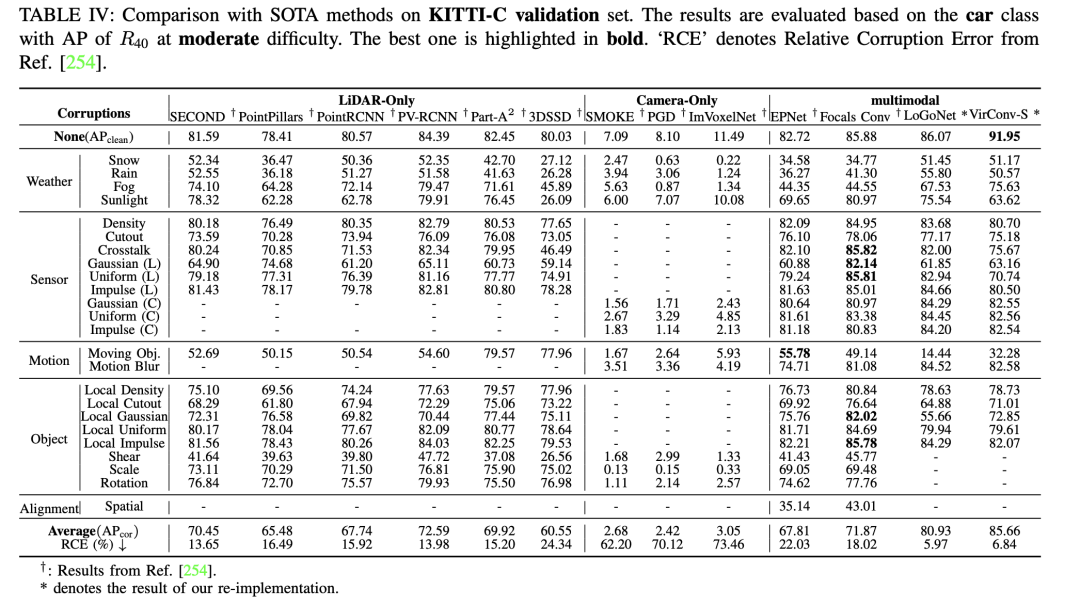
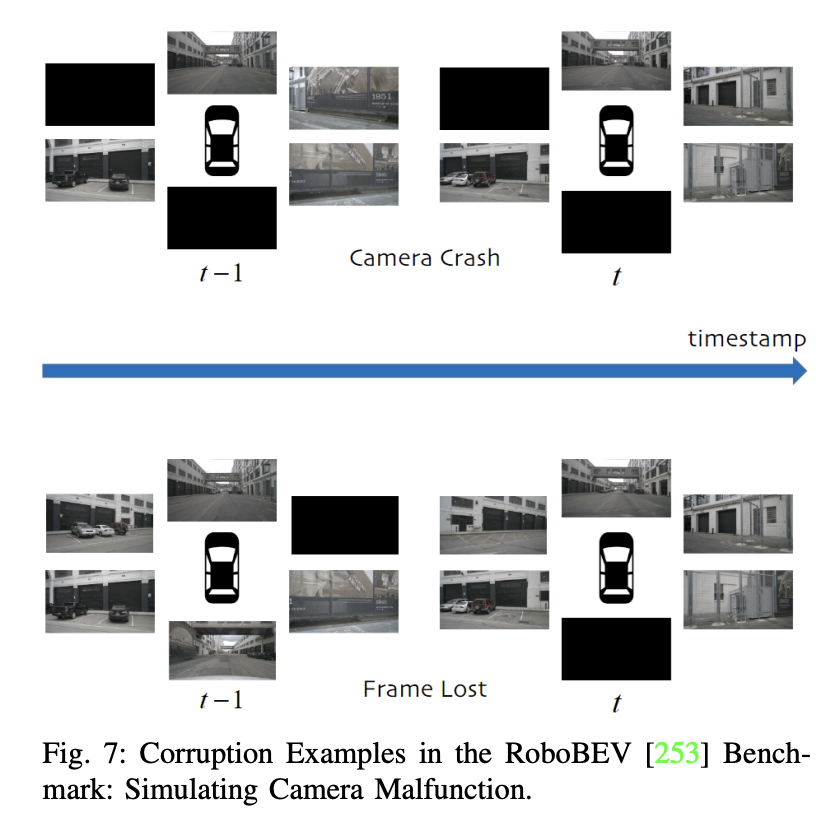
- Robustesse : La robustesse est un facteur clé dans la perception de la sécurité de la conduite autonome et représente un sujet important qui a été auparavant négligé dans les études approfondies. Cet aspect n'est souvent pas abordé dans les ensembles de données et les benchmarks propres et bien conçus, tels que KITTI, nuScenes et Waymo. Actuellement, des travaux de recherche tels que RoboBEV et Robo3D intègrent des considérations de robustesse dans la détection d'objets 3D, telles que la perte du capteur et d'autres facteurs. Ils emploient une méthodologie qui consiste à introduire des perturbations dans des ensembles de données liés à la détection d'objets 3D pour évaluer la robustesse. Cela inclut l'introduction de divers types de bruit, tels que les changements de conditions météorologiques, les pannes de capteurs, les perturbations de mouvement et les perturbations liées aux objets, dans le but de révéler les différents effets des différentes sources de bruit sur le modèle. En règle générale, la plupart des articles étudiant la robustesse sont évalués en introduisant du bruit dans l'ensemble de validation d'ensembles de données propres (tels que KITTI, nuScenes et Waymo). De plus, nous soulignons les résultats de la réf., qui mettent en évidence KITTI-C et nuScenes-C comme exemples de méthodes de détection d'objets 3D utilisant uniquement une caméra. Le tableau fournit une comparaison globale montrant que, dans l’ensemble, l’approche caméra uniquement est moins robuste que les approches de fusion lidar uniquement et multimodèle. Ils sont très sensibles à différents types de bruit. Dans KITTI-C, trois travaux représentatifs (SMOKE, PGD et ImVoxelNet) montrent des performances globales systématiquement inférieures et une robustesse réduite au bruit. Dans nuScenes-C, des méthodes remarquables telles que DETR3D et BEVFormer montrent une plus grande robustesse que FCOS3D et PGD, indiquant que la robustesse globale augmente à mesure que le nombre de capteurs augmente. En conclusion, les futures approches basées uniquement sur des caméras doivent prendre en compte non seulement les facteurs de coût et les mesures de précision (mAP, NDS, etc.), mais également les facteurs liés à la perception de la sécurité et à la robustesse. Notre analyse vise à fournir des informations précieuses sur la sécurité des futurs systèmes de conduite autonome.
3. Détection d'objets 3D basée sur Lidar
La méthode de détection d'objets 3D basée sur les voxels propose de segmenter et de distribuer des nuages de points clairsemés en voxels réguliers pour former une représentation de données dense. Ce processus est appelé voxélisation. Par rapport aux méthodes basées sur la vue, les méthodes basées sur le voxel utilisent la convolution spatiale pour percevoir efficacement les informations spatiales 3D et obtenir une précision de détection plus élevée, ce qui est crucial pour la perception de la sécurité dans la conduite autonome. Cependant, ces méthodes sont toujours confrontées aux défis suivants :
- Haute complexité informatique : Par rapport aux méthodes basées sur une caméra, les méthodes basées sur les voxels nécessitent une mémoire et des ressources de calcul importantes en raison du grand nombre de voxels utilisés pour représenter l'espace 3D.
- Perte d'informations spatiales : en raison des caractéristiques de discrétisation des voxels, les détails et les informations de forme peuvent être perdus ou flous pendant le processus de voxélisation, tandis que la résolution limitée des voxels rend difficile la détection précise des petits objets.
- Incohérence d'échelle et de densité : les méthodes basées sur les voxels nécessitent généralement une détection sur des grilles de voxels de différentes échelles et densités, mais comme l'échelle et la densité des cibles varient considérablement selon les scènes, il est important de choisir l'échelle et la densité appropriées pour s'adapter à différents objectifs devient un défi.
Afin de surmonter ces défis, il est nécessaire de résoudre les limites de la représentation des données, d'améliorer les capacités des fonctionnalités du réseau et la précision du positionnement des cibles, et de renforcer la compréhension de l'algorithme des scènes complexes. Bien que les stratégies d'optimisation varient, elles visent généralement à optimiser à la fois la représentation des données et la structure du modèle.
3.1 Détection d'objets 3D basée sur Voxel
Grâce à la prospérité du PC dans le deep learning, la détection d'objets 3D basée sur des points hérite de plusieurs de ses frameworks et propose de partir directement des points d'origine sans prétraitement Détecter les objets 3D. Comparé aux méthodes basées sur les voxels, le nuage de points d'origine conserve la quantité maximale d'informations d'origine, ce qui est bénéfique pour l'acquisition fine de caractéristiques et permet d'obtenir une grande précision. Dans le même temps, une série de travaux sur PointNet fournit naturellement une base solide pour les méthodes basées sur des points. Les détecteurs d'objets 3D basés sur des points comportent deux composants de base : l'échantillonnage de nuages de points et l'apprentissage de caractéristiques. À l'heure actuelle, les performances des méthodes basées sur des points sont toujours affectées par deux facteurs : le nombre de points de contexte et le rayon de contexte adopté dans l'apprentissage de caractéristiques. . Par exemple, l'augmentation du nombre de points de contexte peut obtenir des informations 3D plus détaillées, mais augmentera considérablement le temps d'inférence du modèle. De même, réduire le rayon du contexte peut avoir le même effet. Par conséquent, le choix de valeurs appropriées pour ces deux facteurs peut permettre au modèle d'atteindre un équilibre entre précision et vitesse. De plus, étant donné que chaque point du nuage de points doit être calculé, le processus d’échantillonnage du nuage de points est le principal facteur limitant le fonctionnement en temps réel des méthodes basées sur les points. Plus précisément, pour résoudre les problèmes ci-dessus, la plupart des méthodes existantes sont optimisées autour des deux composants de base des détecteurs d'objets 3D basés sur des points : 1) Échantillonnage de points 2) Apprentissage de fonctionnalités
3.2 Détection d'objets 3D basée sur des points
Les méthodes de détection d'objets 3D basées sur des points héritent de nombreux frameworks d'apprentissage profond et proposent de détecter des objets 3D directement à partir de nuages de points bruts sans prétraitement. Comparé aux méthodes basées sur les voxels, le nuage de points d'origine conserve au maximum les informations d'origine, ce qui favorise l'acquisition de caractéristiques à granularité fine, permettant ainsi d'obtenir une grande précision. Dans le même temps, la série de travaux PointNet fournit une base solide pour les méthodes basées sur des points. Cependant, jusqu'à présent, les performances des méthodes basées sur les points sont toujours affectées par deux facteurs : le nombre de points de contexte et le rayon de contexte utilisé dans l'apprentissage des fonctionnalités. Par exemple, augmenter le nombre de points de contexte peut obtenir des informations 3D plus détaillées, mais augmentera considérablement le temps d'inférence du modèle. De même, la réduction du rayon du contexte produit le même effet. Par conséquent, le choix de valeurs appropriées pour ces deux facteurs permet au modèle d'atteindre un équilibre entre précision et vitesse. De plus, le processus d'échantillonnage du nuage de points est le principal facteur limitant le fonctionnement en temps réel des méthodes basées sur des points en raison de la nécessité d'effectuer des calculs pour chaque point du nuage de points. Pour résoudre ces problèmes, les méthodes existantes s'optimisent principalement autour de deux composants de base des détecteurs d'objets 3D basés sur des points : 1) l'échantillonnage de nuages de points ; 2) l'apprentissage de caractéristiques.
Farth Point Sampling (FPS) est dérivé de PointNet++ et est une méthode d'échantillonnage de nuages de points largement utilisée dans les méthodes basées sur des points. Son objectif est de sélectionner un ensemble représentatif de points du nuage de points d'origine afin de maximiser la distance entre eux afin de couvrir au mieux la distribution spatiale de l'ensemble du nuage de points. PointRCNN est un détecteur révolutionnaire à deux étages utilisant des méthodes basées sur des points, utilisant PointNet++ comme réseau fédérateur. Dans un premier temps, il génère des propositions 3D à partir de nuages de points de manière ascendante. Dans un deuxième temps, les propositions sont affinées en combinant des caractéristiques sémantiques et des caractéristiques spatiales locales. Cependant, les méthodes existantes basées sur FPS sont encore confrontées à certains problèmes : 1) Les points non liés à la détection participent également au processus d'échantillonnage, ce qui entraîne une charge de calcul supplémentaire ; 2) Les points sont inégalement répartis dans différentes parties de l'objet, ce qui entraîne des stratégies d'échantillonnage sous-optimales. Pour résoudre ces problèmes, les travaux ultérieurs ont adopté un paradigme de conception de type FPS et apporté des améliorations, telles que le filtrage des points d'arrière-plan guidé par la segmentation, l'échantillonnage aléatoire, l'échantillonnage de l'espace des caractéristiques, l'échantillonnage basé sur les voxels et l'échantillonnage basé sur le regroupement de rayons.
L'étape d'apprentissage des caractéristiques des méthodes de détection d'objets 3D basées sur des points vise à extraire des représentations de caractéristiques discriminantes à partir de données de nuages de points clairsemées. Le réseau neuronal utilisé lors de la phase d'apprentissage des fonctionnalités doit avoir les caractéristiques suivantes : 1) Invariance, le réseau fédérateur du nuage de points doit être insensible à l'ordre du nuage de points d'entrée. 2) Il a des capacités de perception locale et peut détecter et modéliser les zones locales ; et extraire des fonctionnalités locales ; 3) La capacité d'intégrer des informations contextuelles et d'extraire des fonctionnalités à partir d'informations contextuelles globales et locales. Sur la base des caractéristiques ci-dessus, un grand nombre de détecteurs sont conçus pour traiter des nuages de points bruts. La plupart des méthodes peuvent être divisées en fonction des opérateurs de base utilisés : 1) méthodes basées sur PointNet ; 2) méthodes basées sur des réseaux neuronaux graphiques ; 3) méthodes basées sur des transformateurs ;
Méthodes basées sur PointNet
Les méthodes basées sur PointNet s'appuient principalement sur l'abstraction d'ensemble pour sous-échantillonner les points d'origine, agréger les informations locales et intégrer les informations contextuelles tout en conservant l'invariance de symétrie des points d'origine. Point-RCNN est le premier travail en deux étapes parmi les méthodes basées sur des points et atteint d'excellentes performances, mais reste confronté au problème du coût de calcul élevé. Des travaux ultérieurs ont résolu ce problème en introduisant une tâche de segmentation sémantique supplémentaire dans le processus de détection afin de filtrer les points d'arrière-plan qui contribuent de manière minimale à la détection.
Méthodes basées sur les réseaux de neurones graphiques
Les réseaux de neurones graphiques (GNN) ont des structures adaptatives, des voisinages dynamiques, la capacité de construire des relations de contexte locales et globales et une robustesse face à un échantillonnage irrégulier. Point-GNN est un travail pionnier qui conçoit un réseau neuronal graphique en une seule étape pour prédire la catégorie et la forme des objets grâce à un mécanisme d'enregistrement automatique, des opérations de fusion et de notation, démontrant l'utilisation des réseaux neuronaux graphiques comme nouvelle méthode de détection d'objets 3D. potentiel.
Méthodes basées sur les transformateurs
Ces dernières années, les transformateurs (Transformateurs) ont été explorés dans l'analyse des nuages de points et ont bien fonctionné dans de nombreuses tâches. Par exemple, Pointformer introduit des modules d'attention locaux et globaux pour traiter les nuages de points 3D, le module Transformer local est utilisé pour modéliser les interactions entre les points dans les régions locales et le Transformer global vise à apprendre des représentations contextuelles au niveau de la scène. Group-free utilise directement tous les points du nuage de points pour calculer les caractéristiques de chaque objet candidat, où la contribution de chaque point est déterminée par un module d'attention appris automatiquement. Ces méthodes démontrent le potentiel des méthodes basées sur Transformer dans le traitement des nuages de points bruts non structurés et non ordonnés.
3.3 Détection d'objets 3D basée sur Point-Voxel
Les méthodes de détection d'objets 3D basées sur des nuages de points offrent une haute résolution et préservent la structure spatiale des données d'origine, mais elles sont confrontées à une complexité de calcul élevée et à une faible efficacité lors du traitement de données clairsemées. En revanche, les méthodes basées sur les voxels fournissent une représentation structurée des données, améliorent l’efficacité des calculs et facilitent l’application de la technologie traditionnelle des réseaux neuronaux convolutifs. Cependant, ils perdent souvent des détails spatiaux fins en raison du processus de discrétisation. Pour résoudre ces problèmes, des méthodes basées sur le point-voxel (PV) ont été développées. Les méthodes point-voxel visent à exploiter les capacités de capture d’informations fines des méthodes basées sur des points et l’efficacité de calcul des méthodes basées sur le voxel. En intégrant ces méthodes, les méthodes basées sur les points et les voxels peuvent traiter les données des nuages de points plus en détail, capturant la structure globale et les détails microgéométriques. Ceci est crucial pour la perception de la sécurité dans la conduite autonome, car la précision décisionnelle du système de conduite autonome dépend de résultats de détection de haute précision.
L'objectif principal de la méthode point-voxel est d'obtenir une interaction de caractéristiques entre les voxels et les points via une conversion point à voxel ou voxel à point. De nombreux travaux ont exploré l'idée d'utiliser la fusion de fonctionnalités point-voxel dans les réseaux fédérateurs. Ces méthodes peuvent être divisées en deux catégories : 1) fusion précoce 2) fusion tardive ;
a) Fusion précoce : Certaines méthodes ont exploré l'utilisation de nouveaux opérateurs de convolution pour fusionner des voxels et des caractéristiques ponctuelles, et PVCNN pourrait être le premier travail dans cette direction. Dans cette approche, la branche basée sur les voxels convertit d'abord les points en une grille de voxels basse résolution et agrège les caractéristiques des voxels voisins par convolution. Ensuite, grâce à un processus appelé dévoxélisation, les caractéristiques au niveau voxel sont reconverties en caractéristiques au niveau point et fusionnées avec les caractéristiques obtenues par la branche basée sur les points. La branche basée sur les points extrait les caractéristiques de chaque point individuel. Puisqu’elle ne regroupe pas les informations sur les voisins, cette méthode peut fonctionner à des vitesses plus élevées. Ensuite, SPVCNN a été étendu au domaine de la détection d’objets basée sur PVCNN. D'autres méthodes tentent de s'améliorer sous différents angles, comme les tâches auxiliaires ou la fusion de fonctionnalités multi-échelles.
b) Post-fusion : Cette série de méthodes utilise principalement un cadre de détection en deux étapes. Premièrement, des propositions d'objets préliminaires sont générées à l'aide d'une approche basée sur les voxels. Ensuite, des caractéristiques au niveau du point sont utilisées pour diviser avec précision le cadre de détection. Le PV-RCNN proposé par Shi et al. constitue une étape importante dans les méthodes basées sur les points et les voxels. Il utilise SECOND comme détecteur de premier étage et propose une étape de raffinement de deuxième étage avec un regroupement de grilles RoI pour la fusion des caractéristiques des points clés. Les travaux ultérieurs suivent principalement le paradigme ci-dessus et se concentrent sur les progrès de la détection de deuxième étape. Les développements notables incluent des mécanismes d'attention, un regroupement sensible à l'échelle et des modules de raffinement sensibles à la densité de points.
Les méthodes basées sur des points et des voxels ont à la fois l'efficacité de calcul des méthodes basées sur des voxels et la capacité des méthodes basées sur des points à capturer des informations à granularité fine. Cependant, la construction de relations point à voxel ou voxel à point, ainsi que la fusion de caractéristiques de voxels et de points, entraîneront une surcharge de calcul supplémentaire. Par conséquent, les méthodes basées sur des points et des voxels peuvent obtenir une meilleure précision de détection par rapport aux méthodes basées sur des voxels, mais au prix d’un temps d’inférence accru.
4. Détection d'objets 3D multimodale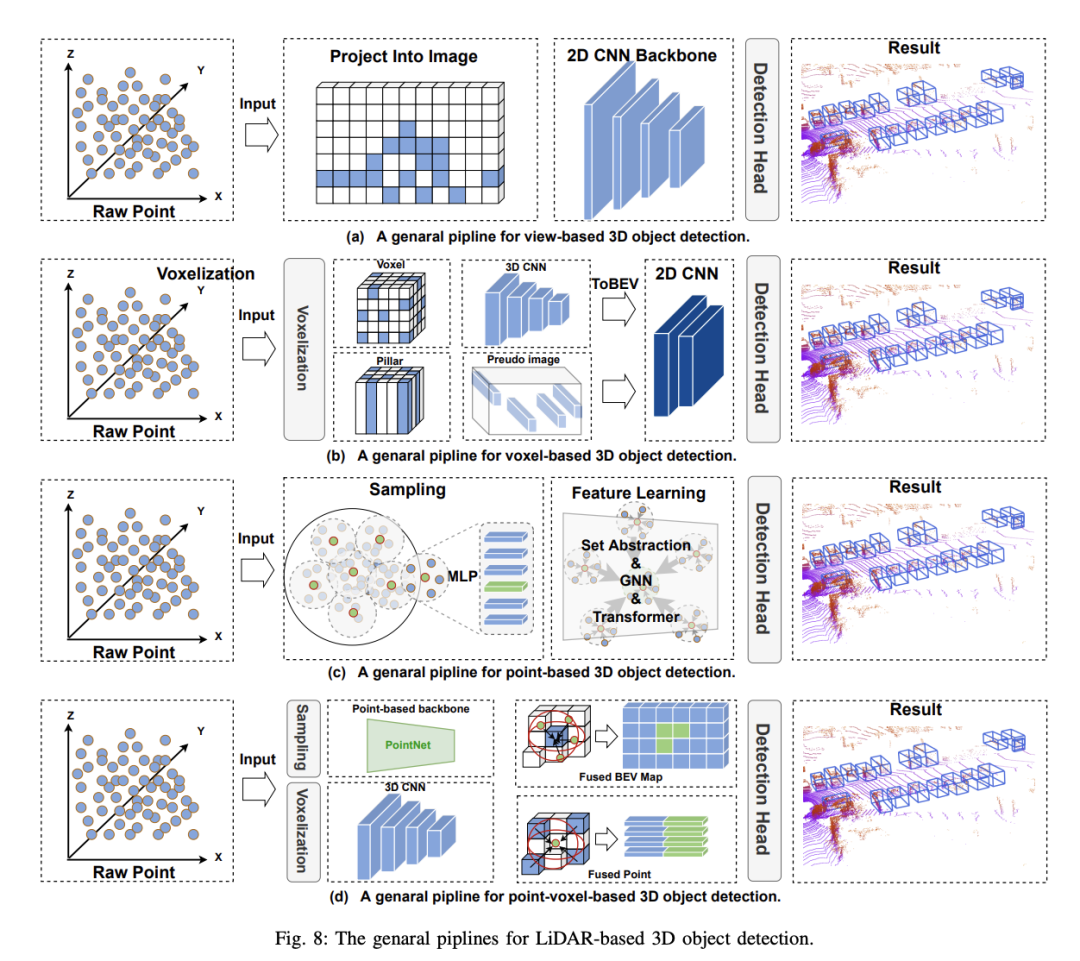
La méthode de détection d'objets 3D basée sur la projection utilise la matrice de projection dans l'étape de fusion de caractéristiques pour réaliser le nuage de points. et fonctionnalités d'image. La clé ici est de se concentrer sur la projection lors de la fusion de fonctionnalités, plutôt que sur d'autres processus de projection au cours de l'étape de fusion, tels que l'augmentation des données, etc. Selon les différents types de projections utilisés lors de l'étape de fusion, les méthodes de détection d'objets 3D basées sur la projection peuvent être subdivisées dans les catégories suivantes :
- Détection d'objets 3D basée sur la projection ponctuelle
- : Ce type de méthode fonctionne en projetant une image. Les fonctionnalités sur le nuage de points d'origine sont utilisées pour améliorer la capacité de représentation des données du nuage de points d'origine. La première étape de ces méthodes consiste à utiliser une matrice d’étalonnage pour établir de fortes corrélations entre les points lidar et les pixels de l’image. Ensuite, les fonctionnalités du nuage de points sont améliorées en ajoutant des données supplémentaires. Cette amélioration se présente sous deux formes : l'une en fusionnant les scores de segmentation (comme PointPainting) et l'autre en utilisant les fonctionnalités CNN des pixels pertinents (comme MVP). PointPainting améliore les points lidar en ajoutant des scores de segmentation, mais présente des limites dans la capture efficace des détails de couleur et de texture dans les images. Pour résoudre ces problèmes, des méthodes plus sophistiquées telles que FusionPainting ont été développées. Détection d'objets 3D basée sur la projection de caractéristiques
- : Différent des méthodes basées sur la projection de points, ce type de méthode se concentre principalement sur la fusion des caractéristiques du nuage de points avec les caractéristiques de l'image lors de l'étape d'extraction des caractéristiques du nuage de points. Dans ce processus, les modalités du nuage de points et de l'image sont efficacement fusionnées en appliquant une matrice d'étalonnage pour transformer le système de coordonnées 3D des voxels en système de coordonnées de pixels de l'image. Par exemple, ContFuse fusionne des cartes de caractéristiques convolutives à plusieurs échelles par convolution continue. Détection automatique d'objets 3D basée sur la projection
- : de nombreuses études effectuent une fusion par projection directe, mais ne résolvent pas le problème de l'erreur de projection. Certains travaux (comme AutoAlignV2) atténuent ces erreurs en apprenant les décalages et les projections de quartier, etc. Par exemple, HMFI, GraphAlign et GraphAlign++ utilisent une connaissance préalable de la matrice d'étalonnage de projection pour la projection d'images et la modélisation de graphiques locaux. Détection d'objets 3D basée sur une projection décisionnelle
- : ce type de méthode utilise une matrice de projection pour aligner les caractéristiques dans une région d'intérêt (RoI) ou un résultat spécifique. Par exemple, Graph-RCNN projette des nœuds graphiques vers des positions dans une image de caméra et collecte des vecteurs de caractéristiques pour ce pixel dans l'image de caméra par interpolation bilinéaire. F-PointNet détermine la catégorie et le positionnement des objets grâce à la détection d'images 2D et obtient des nuages de points dans l'espace 3D correspondant grâce à des paramètres de capteur calibrés et des matrices de transformation dans l'espace 3D. Ces méthodes montrent comment utiliser la technologie de projection pour réaliser la fusion de caractéristiques dans la détection d'objets 3D multimodaux, mais elles présentent encore certaines limites dans la gestion de l'interaction entre les différentes modalités et la précision.
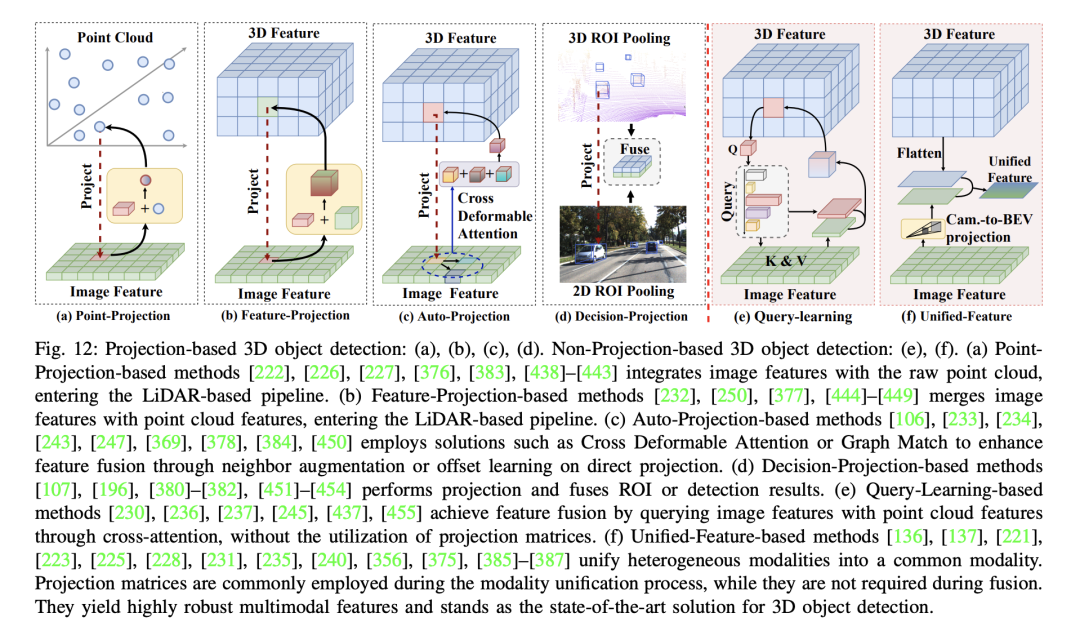 La méthode de détection d'objets 3D sans projection réalise la fusion en ne s'appuyant pas sur l'alignement des caractéristiques, ce qui donne une représentation robuste des caractéristiques. Ils contournent les limites de la projection caméra-lidar, qui réduit souvent la densité sémantique des fonctionnalités de la caméra et affecte l'efficacité de techniques telles que Focals Conv et PointPainting. Les méthodes non projectives adoptent généralement un mécanisme d’attention croisée ou construisent un espace unifié pour résoudre le problème de désalignement inhérent à la projection directe de caractéristiques. Ces méthodes sont principalement divisées en deux catégories : (1) les méthodes basées sur l'apprentissage des requêtes et (2) les méthodes unifiées basées sur les fonctionnalités. Les méthodes basées sur l'apprentissage des requêtes évitent complètement le besoin d'alignement pendant le processus de fusion. En revanche, les méthodes unifiées basées sur les fonctionnalités, bien que construisant un espace de fonctionnalités unifié, n'évitent pas complètement la projection, elle se produit généralement dans un contexte à modalité unique ; Par exemple, BEVFusion utilise LSS pour la projection caméra vers BEV. Ce processus se produit avant la fusion et montre une robustesse considérable dans les scénarios où les fonctionnalités sont mal alignées.
La méthode de détection d'objets 3D sans projection réalise la fusion en ne s'appuyant pas sur l'alignement des caractéristiques, ce qui donne une représentation robuste des caractéristiques. Ils contournent les limites de la projection caméra-lidar, qui réduit souvent la densité sémantique des fonctionnalités de la caméra et affecte l'efficacité de techniques telles que Focals Conv et PointPainting. Les méthodes non projectives adoptent généralement un mécanisme d’attention croisée ou construisent un espace unifié pour résoudre le problème de désalignement inhérent à la projection directe de caractéristiques. Ces méthodes sont principalement divisées en deux catégories : (1) les méthodes basées sur l'apprentissage des requêtes et (2) les méthodes unifiées basées sur les fonctionnalités. Les méthodes basées sur l'apprentissage des requêtes évitent complètement le besoin d'alignement pendant le processus de fusion. En revanche, les méthodes unifiées basées sur les fonctionnalités, bien que construisant un espace de fonctionnalités unifié, n'évitent pas complètement la projection, elle se produit généralement dans un contexte à modalité unique ; Par exemple, BEVFusion utilise LSS pour la projection caméra vers BEV. Ce processus se produit avant la fusion et montre une robustesse considérable dans les scénarios où les fonctionnalités sont mal alignées.
- Détection d'objets tridimensionnels basée sur l'apprentissage de requêtes : Les méthodes de détection d'objets tridimensionnels basées sur l'apprentissage de requêtes, telles que Transfusion, DeepFusion, DeepInteraction, autoalign, CAT-Det, MixedFusion, etc., évitent le besoin de projection dans le processus de fusion de fonctionnalités. Au lieu de cela, ils réalisent l’alignement des fonctionnalités avant d’effectuer la fusion des fonctionnalités via un mécanisme d’attention croisée. Les fonctionnalités de nuage de points sont généralement utilisées comme requêtes, et les fonctionnalités d'image sont utilisées comme clés et valeurs. Des fonctionnalités multimodales très robustes sont obtenues grâce à des requêtes de fonctionnalités globales. De plus, DeepInteraction introduit une interaction multimodale, dans laquelle les caractéristiques des nuages de points et des images sont utilisées comme différentes requêtes pour obtenir une interaction plus poussée entre les fonctionnalités. L'intégration complète des fonctionnalités d'image conduit à l'acquisition de fonctionnalités multimodales plus robustes par rapport à l'utilisation uniquement de fonctionnalités de nuage de points comme requêtes. En général, la méthode de détection d'objets tridimensionnels basée sur l'apprentissage de requêtes utilise une structure basée sur un transformateur pour effectuer une requête de fonctionnalités afin d'obtenir un alignement de fonctionnalités. Finalement, des fonctionnalités multimodales ont été intégrées dans des processus basés sur lidar tels que CenterPoint.
- Détection d'objets tridimensionnels basée sur des fonctionnalités unifiées : méthodes de détection d'objets tridimensionnels basées sur des fonctionnalités unifiées, telles que EA-BEV, BEVFusion, cai2023bevfusion4d, FocalFormer3D, FUTR3D, UniTR, Uni3D, virconv, MSMDFusion, sfd, cmt , UVTR, sparsefusion, etc. , l'unification pré-fusion de modalités hétérogènes est généralement réalisée par projection avant la fusion des caractéristiques. Dans la série de fusion BEV, LSS est utilisé pour l'estimation de la profondeur, les caractéristiques de la vue de face sont converties en caractéristiques BEV, puis l'image BEV et les caractéristiques du nuage de points BEV sont fusionnées. D'autre part, CMT et UniTR utilisent Transformer pour la tokenisation des nuages de points et des images, et construisent un espace unifié implicite grâce au codage Transformer. CMT utilise la projection dans le processus de codage de position mais évite complètement de s'appuyer sur les relations de projection au niveau de l'apprentissage des fonctionnalités. FocalFormer3D, FUTR3D et UVTR utilisent la requête de Transformer pour implémenter une solution similaire à DETR3D et créer un espace de fonctionnalités BEV clairsemé unifié via une requête, atténuant ainsi l'instabilité causée par la projection directe.
VirConv, MSMDFusion et SFD construisent un espace unifié à travers des pseudo-nuages de points, et la projection a lieu avant l'apprentissage des fonctionnalités. Les problèmes introduits par la projection directe sont résolus grâce à un apprentissage ultérieur des fonctionnalités. En résumé, les méthodes unifiées de détection d’objets 3D basées sur les fonctionnalités représentent actuellement des solutions très précises et robustes. Bien qu'ils contiennent une matrice de projection, cette projection ne se produit pas entre les fusions multimodales et est donc considérée comme une méthode de détection d'objets 3D non projective. Différentes des méthodes de détection automatique d'objets 3D par projection, elles ne résolvent pas directement le problème de l'erreur de projection, mais choisissent de construire un espace unifié et considèrent plusieurs dimensions de détection d'objets 3D multimodales pour obtenir des fonctionnalités multimodales très robustes.
5. Conclusion
La détection d'objets 3D joue un rôle crucial dans la perception de la conduite autonome. Ces dernières années, ce domaine s'est développé rapidement et a donné lieu à un grand nombre d'articles de recherche. Basées sur les diverses formes de données générées par les capteurs, ces méthodes sont principalement divisées en trois types : basées sur des images, basées sur des nuages de points et multimodales. Les principales mesures d’évaluation de ces méthodes sont une grande précision et une faible latence. De nombreuses revues résument ces approches, en se concentrant principalement sur les principes fondamentaux de « haute précision et faible latence », décrivant leurs trajectoires techniques.
Cependant, dans le processus de transition de la technologie de conduite autonome des avancées vers les applications pratiques, les études existantes ne prennent pas la perception de la sécurité comme objectif principal et ne parviennent pas à couvrir les voies techniques actuelles liées à la perception de la sécurité. Par exemple, la robustesse des méthodes récentes de fusion multimodale est souvent testée pendant la phase expérimentale, un aspect qui n’a pas été pleinement pris en compte dans la présente revue.
Par conséquent, réexaminez l'algorithme de détection d'objets 3D, en vous concentrant sur « la précision, la latence et la robustesse » comme aspects clés. Nous reclassons les avis précédents en mettant un accent particulier sur la reclassification du point de vue de la perception de la sécurité. On espère que ces travaux fourniront de nouvelles perspectives sur les recherches futures sur la détection d’objets 3D, allant au-delà de la simple exploration des limites de la haute précision.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Éditeur de modèles WebGL3D personnalisé basé sur Babylonjs
- Python dessine des graphiques 3D
- Huawei Cloud et un certain nombre d'entreprises ont lancé une initiative d'action : construire conjointement un écosystème industriel ouvert pour la conduite autonome
- Cet article vous donnera une compréhension facile à comprendre de la conduite autonome
- Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation