
Maison >Périphériques technologiques >IA >Yancore Digital publie un modèle de mécanisme de non-attention à grande échelle qui prend en charge le déploiement hors ligne côté appareil
Yancore Digital publie un modèle de mécanisme de non-attention à grande échelle qui prend en charge le déploiement hors ligne côté appareil

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-26 08:24:061297parcourir
Le 24 janvier, Shanghai Yanxinshuzhi Artificial Intelligence Technology Co., Ltd. a lancé un grand modèle général de langage naturel sans mécanisme d'attention-modèle Yan. Selon la conférence de presse de Yancore Digital Intelligence, le modèle Yan utilise une nouvelle « architecture Yan » auto-développée pour remplacer l'architecture Transformer. Par rapport au Transformer, l'architecture Yan a une capacité de mémoire augmentée de 3 fois et une vitesse augmentée de 7. fois tout en atteignant un débit d’inférence 5 fois supérieur.  Liu Fanping, PDG de Yancore Digital Intelligence, estime que la puissance de calcul élevée et le coût élevé de Transformer, célèbre pour sa grande échelle, dans ses applications pratiques ont découragé de nombreuses petites et moyennes entreprises. La complexité de son architecture interne rend le processus de prise de décision difficile à expliquer ; la difficulté de traiter de longues séquences et le problème des hallucinations incontrôlables limitent également la large application des grands modèles dans certains domaines clés et scénarios particuliers. Avec la popularisation du cloud computing et de l'edge computing, la demande de l'industrie en modèles d'IA à grande échelle offrant des performances élevées et une faible consommation d'énergie augmente.
Liu Fanping, PDG de Yancore Digital Intelligence, estime que la puissance de calcul élevée et le coût élevé de Transformer, célèbre pour sa grande échelle, dans ses applications pratiques ont découragé de nombreuses petites et moyennes entreprises. La complexité de son architecture interne rend le processus de prise de décision difficile à expliquer ; la difficulté de traiter de longues séquences et le problème des hallucinations incontrôlables limitent également la large application des grands modèles dans certains domaines clés et scénarios particuliers. Avec la popularisation du cloud computing et de l'edge computing, la demande de l'industrie en modèles d'IA à grande échelle offrant des performances élevées et une faible consommation d'énergie augmente.
« À l'échelle mondiale, de nombreux chercheurs exceptionnels ont tenté de résoudre fondamentalement la dépendance excessive à l'égard de l'architecture Transformer et de chercher de meilleurs moyens de remplacer Transformer. Même Llion Jones, l'un des auteurs de l'article Transformer, explore également la « Possibilité après Transformer ». tente d'utiliser une méthode intelligente inspirée de la nature et basée sur des principes évolutifs pour créer une redéfinition du cadre de l'IA sous différents angles. "
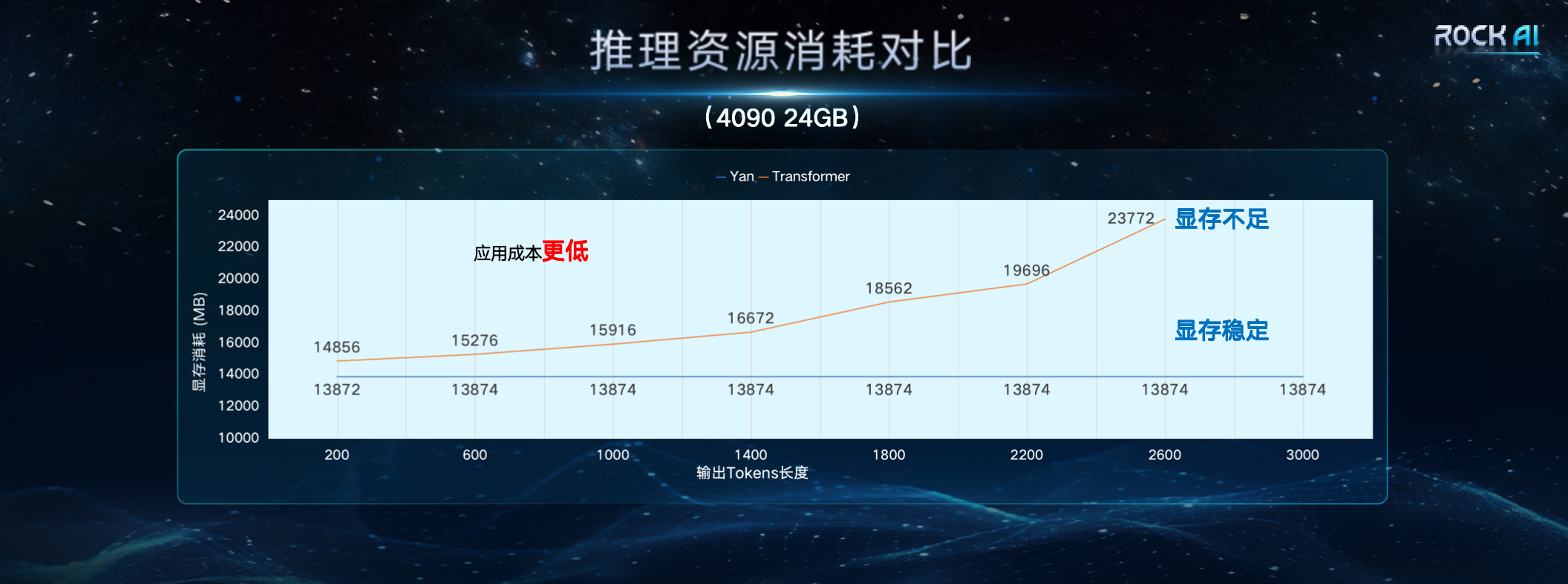
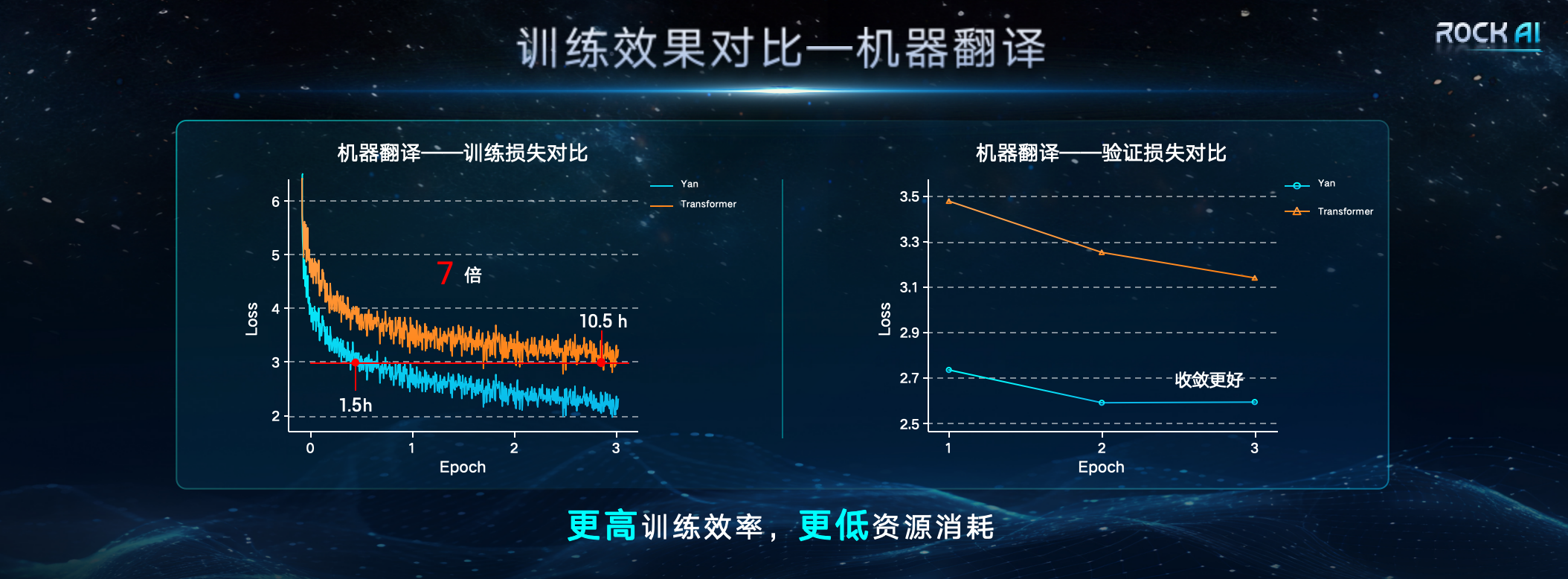
Lors de la conférence de presse, Core Digital a déclaré que dans les mêmes conditions de ressources, l'efficacité de la formation et le débit d'inférence du modèle d'architecture Yan sont respectivement 7 fois et 5 fois supérieures à celles de l'architecture Transformer, et la capacité de mémoire est améliorée de 3 fois. La conception de l'architecture Yan rend la complexité spatiale du modèle Yan constante pendant l'inférence. Par conséquent, le modèle Yan fonctionne également bien face aux problèmes de séquence longue rencontrés par le Transformer. Les données comparatives montrent que sur une seule carte graphique 4090 24G, lorsque la longueur du jeton de sortie du modèle dépasse 2600, le modèle Transformer souffrira d'une mémoire vidéo insuffisante, tandis que l'utilisation de la mémoire vidéo du modèle Yan est toujours stable à environ 14G, ce qui permet théoriquement une inférence de longueur infinie.
Liu Fanping a déclaré que le modèle Yan prend en charge à 100 % les applications de déploiement privatisées et peut fonctionner sans perte sur des appareils finaux tels que les processeurs grand public grand public sans écrêtage ni compression, obtenant le même effet que d'autres modèles fonctionnant sur des GPU. Lors de la conférence de presse, Yan a montré des clips en temps réel exécutés sur un ordinateur portable après avoir été hors ligne. Liu Fanping a déclaré que le déploiement final hors ligne deviendrait une direction commerciale importante de Core Intelligence à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Le PHP est-il difficile à apprendre ? Combien de temps faut-il pour apprendre PHP, de l'entrée à la maîtrise ?
- Résumé des connaissances de base de PHP (nécessaire aux débutants pour débuter)
- Quels livres dois-je lire pour apprendre Java à partir de zéro ? Livres Java avancés recommandés
- 5 livres classiques d'introduction à la programmation recommandés en 2018
- Tutoriel d'introduction à l'utilisation du système Linux