
Maison >Périphériques technologiques >IA >La nouvelle méthode ASPIRE de Google : offre des capacités d'auto-évaluation du LLM, résout efficacement le problème de 'l'illusion' et dépasse 10 fois le modèle de volume
La nouvelle méthode ASPIRE de Google : offre des capacités d'auto-évaluation du LLM, résout efficacement le problème de 'l'illusion' et dépasse 10 fois le modèle de volume

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-23 17:21:13831parcourir
Le problème de « l’illusion » des grands modèles sera bientôt résolu ?
Des chercheurs de l'Université du Wisconsin-Madison et de Google ont récemment lancé le système ASPIRE, qui permet aux grands modèles d'auto-évaluer leur production.
Si l'utilisateur constate que le résultat généré par le modèle a un score faible, il se rendra compte que la réponse peut être une illusion.
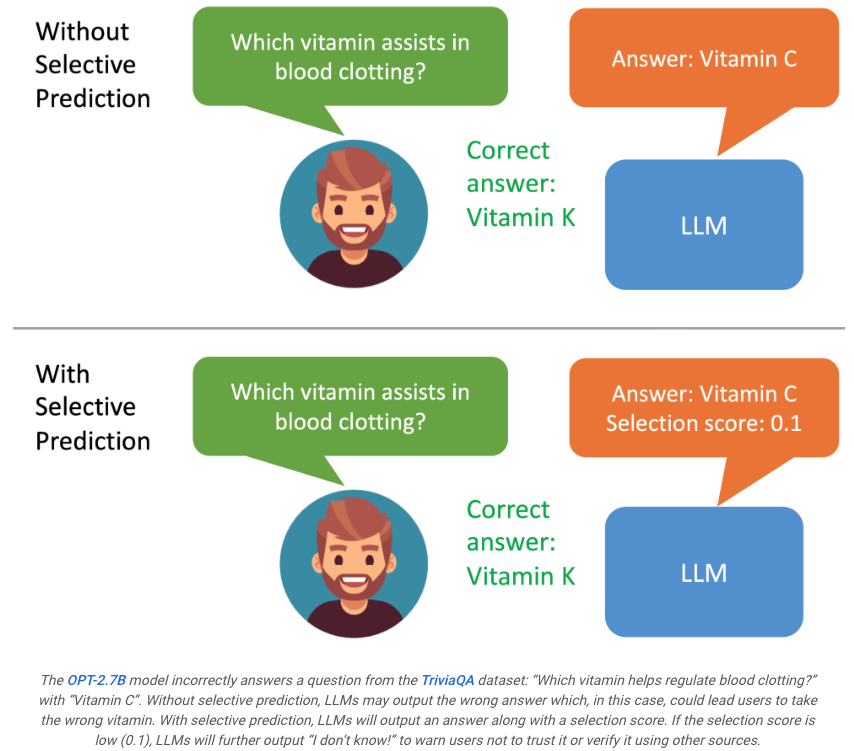
Si le système peut filtrer davantage le contenu de sortie en fonction des résultats de la note, par exemple lorsque la note est faible, un grand modèle peut générer des déclarations telles que "Je ne peux pas répondre à cette question", ce qui peut maximiser la amélioration du problème des hallucinations.

Adresse papier : https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE permet à LLM d'afficher la réponse et le score de confiance de la réponse.
Les résultats expérimentaux des chercheurs montrent qu'ASPIRE surpasse considérablement les méthodes de prédiction sélective traditionnelles sur divers ensembles de données d'assurance qualité (tels que le benchmark CoQA).
Laissez LLM non seulement répondre aux questions, mais également évaluer ces réponses.
Dans le test de référence de prédiction sélective, les chercheurs ont obtenu des résultats plus de 10 fois supérieurs à l'échelle du modèle grâce au système ASPIRE.
C'est comme demander aux élèves de vérifier leurs propres réponses à la fin du manuel. Même si cela semble un peu peu fiable, si vous y réfléchissez bien, tout le monde sera effectivement satisfait de la réponse après avoir répondu à une question. Il y aura une note.
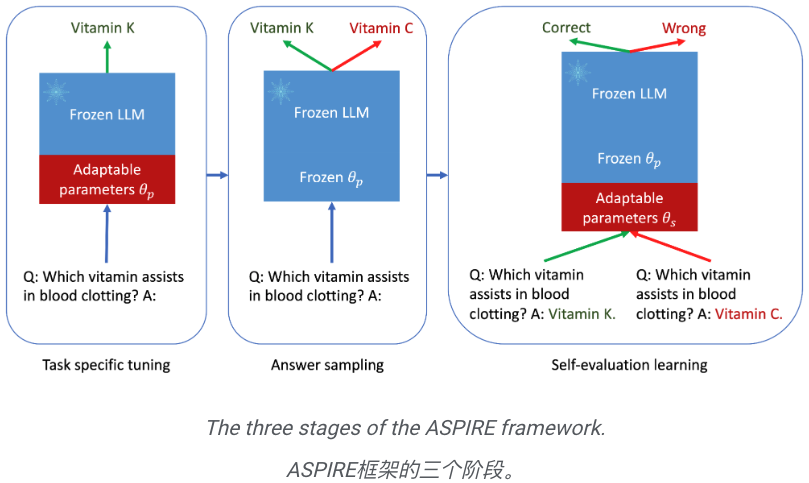
C'est l'essence d'ASPIRE, qui comprend trois phases :
(1) Optimisation pour une tâche spécifique,
(2) Échantillonnage de réponses,
( 3 ) Auto-évaluation de l’apprentissage.
Aux yeux des chercheurs, ASPIRE n'est pas simplement un autre framework, il représente un avenir radieux qui améliore considérablement la fiabilité du LLM et réduit les illusions.
Si LLM peut être un partenaire de confiance dans le processus de prise de décision.
Tant que nous continuons à optimiser la capacité de prédiction sélective, les humains sont sur le point de réaliser pleinement le potentiel des grands modèles.
Les chercheurs espèrent utiliser ASPIRE pour lancer l'évolution de la prochaine génération de LLM, créant ainsi une intelligence artificielle plus fiable et plus consciente d'elle-même.
Le mécanisme d'ASPIRE
Réglage précis spécifique à la tâche
ASPIRE effectue un réglage précis spécifique à la tâche pour entraîner les paramètres adaptatifs 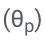 tout en gelant le LLM.
tout en gelant le LLM.
Étant donné un ensemble de données d'entraînement pour la tâche de génération, il affine le LLM pré-entraîné pour améliorer ses performances de prédiction.
À cette fin, des techniques de réglage fin efficaces en termes de paramètres (par exemple, réglage fin des mots de repère logiciel et LoRA) peuvent être utilisées pour affiner les LLM pré-entraînés sur la tâche, car elles peuvent efficacement obtenir une forte généralisation. avec un petit nombre de données cibles.
Plus précisément, les paramètres LLM (θ) sont figés et des paramètres adaptatifs 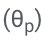 sont ajoutés pour un réglage fin.
sont ajoutés pour un réglage fin.
Mettez à jour uniquement θ (p) pour minimiser la perte de formation LLM standard (par exemple, entropie croisée).
Ce type de réglage fin peut améliorer les performances de prédiction sélective car il améliore non seulement la précision de la prédiction, mais augmente également la probabilité de produire correctement la séquence.
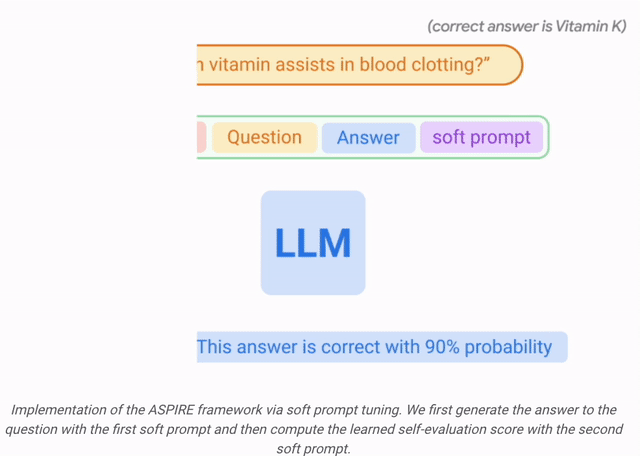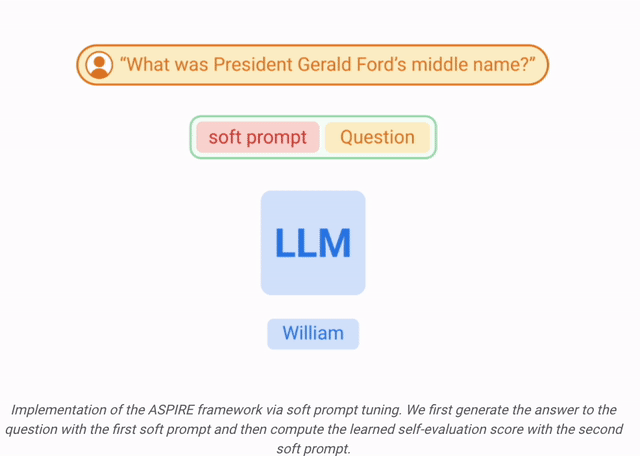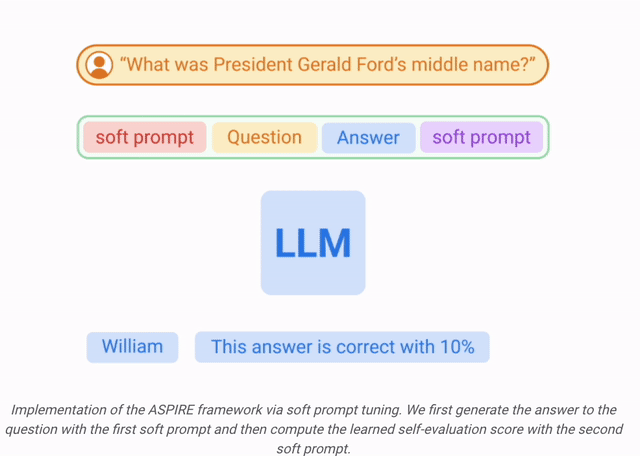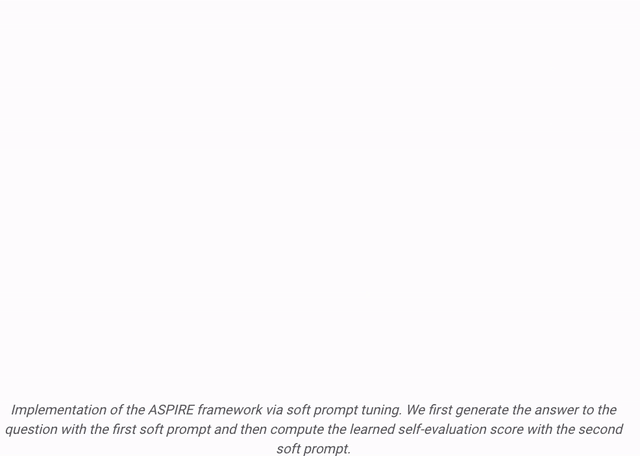
Answer Sampling
Après avoir été configuré pour une tâche spécifique, ASPIRE utilise LLM et a appris 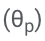 à générer des réponses différentes pour chaque question de formation et à créer un ensemble de données pour l'apprentissage de l'auto-évaluation.
à générer des réponses différentes pour chaque question de formation et à créer un ensemble de données pour l'apprentissage de l'auto-évaluation.
L’objectif du chercheur est de générer des séquences de sortie avec une forte probabilité. Ils ont utilisé Beam Search comme algorithme de décodage pour générer des séquences de sortie à haute probabilité et ont utilisé la métrique Rouge-L pour déterminer si les séquences de sortie générées étaient correctes.
Apprentissage par auto-évaluation
Après avoir échantillonné le résultat à haute probabilité de chaque requête, ASPIRE ajoute des paramètres adaptatifs 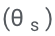 et affine uniquement
et affine uniquement 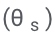 pour apprendre l'auto-évaluation.
pour apprendre l'auto-évaluation.
Étant donné que la génération de la séquence de sortie ne dépend que de θ et 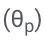 , geler θ et l'apprenant
, geler θ et l'apprenant 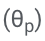 peut éviter de modifier le comportement de prédiction du LLM lors de l'apprentissage de l'auto-évaluation.
peut éviter de modifier le comportement de prédiction du LLM lors de l'apprentissage de l'auto-évaluation.
Les chercheurs ont optimisé 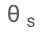 pour que le LLM adapté puisse distinguer par lui-même les réponses correctes et incorrectes.
pour que le LLM adapté puisse distinguer par lui-même les réponses correctes et incorrectes.
Dans ce cadre, toute méthode de réglage fin efficace en termes de paramètres peut être utilisée pour entraîner 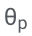 et
et 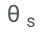 .
.
Dans ce travail, les chercheurs utilisent le réglage fin des repères logiciels, un mécanisme simple mais efficace pour apprendre des « repères logiciels » afin d'ajuster les modèles de langage figés afin qu'ils soient plus efficaces que les repères textuels discrets traditionnels pour effectuer des tâches spécifiques en aval.
Le cœur de cette approche est la reconnaissance du fait que si des signaux qui stimulent efficacement l'auto-évaluation peuvent être développés, alors ces signaux devraient être détectables grâce à un réglage fin des signaux souples combinés à des objectifs d'entraînement ciblés.
Après les formations 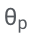 et
et 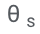 , les chercheurs ont obtenu la prédiction de la requête grâce au décodage par recherche de faisceau.
, les chercheurs ont obtenu la prédiction de la requête grâce au décodage par recherche de faisceau.
Les chercheurs définissent ensuite un score de choix qui combine la probabilité de générer une réponse avec le score d'auto-évaluation appris (c'est-à-dire la probabilité que la prédiction soit correcte pour la requête) pour faire des prédictions sélectives.
Résultats
Pour démontrer l'efficacité d'ASPIRE, les chercheurs ont utilisé divers modèles ouverts de transformateurs pré-entraînés (OPT) pour les évaluer sur trois ensembles de données de réponse aux questions (CoQA, TriviaQA et SQuAD).
En ajustant l'entraînement à l'aide de signaux souples Les chercheurs ont observé une augmentation substantielle de la précision du LLM.
Les chercheurs ont observé une augmentation substantielle de la précision du LLM.
Par exemple, le modèle OPT-2.7B avec ASPIRE a montré de meilleures performances par rapport au plus grand modèle OPT-30B pré-entraîné utilisant les ensembles de données CoQA et SQuAD.
Ces résultats suggèrent qu'avec un réglage approprié, les LLM plus petits peuvent avoir la capacité d'égaler, voire de dépasser, la précision des modèles plus grands dans certains cas.
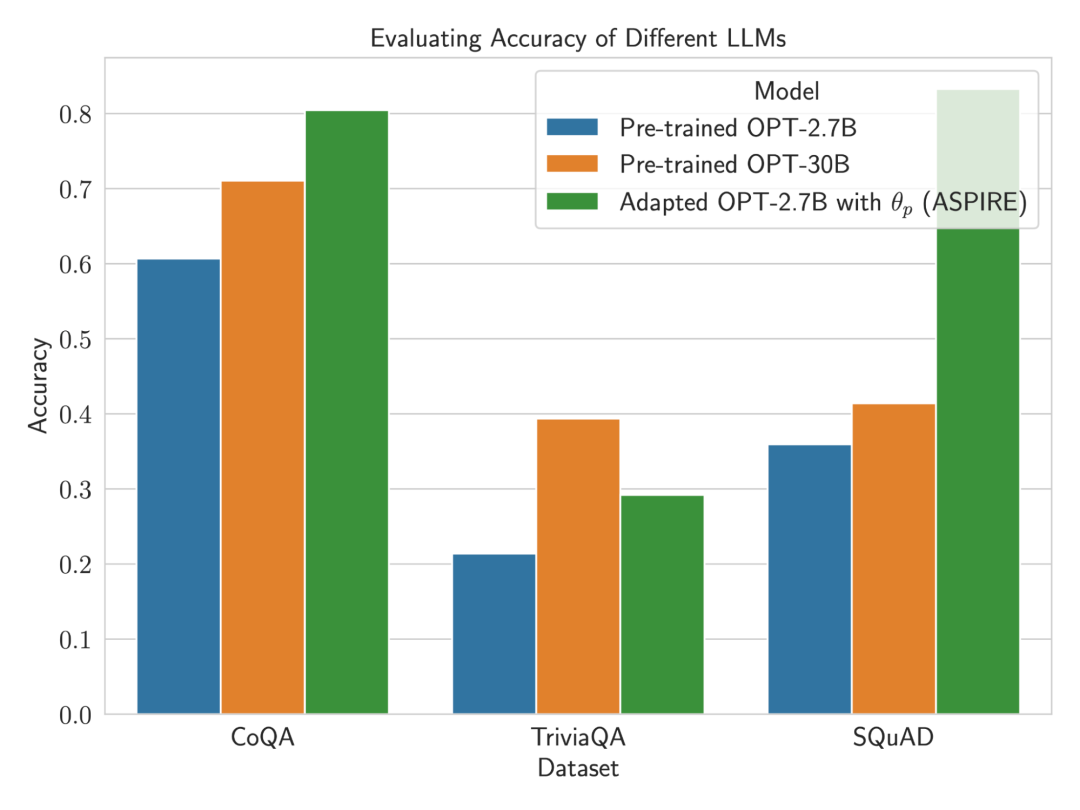
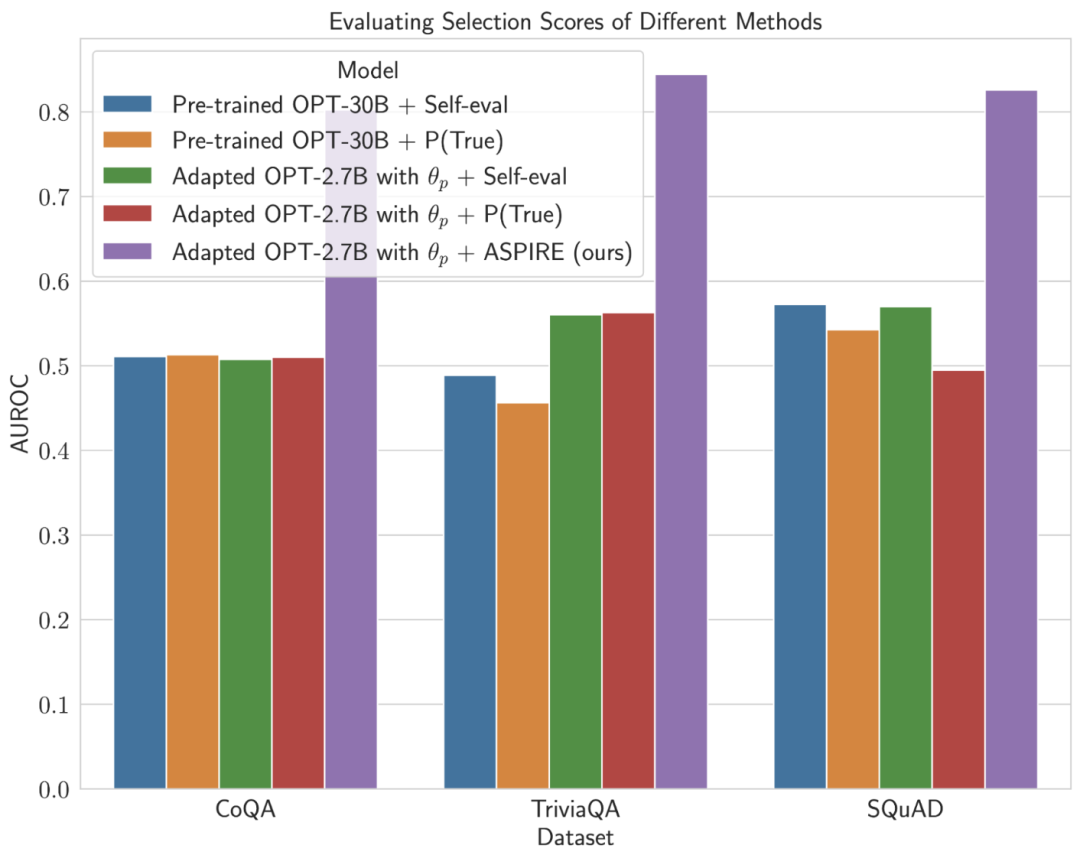
En approfondissant le calcul des scores de sélection pour les prédictions de modèles fixes, ASPIRE a obtenu des scores AUROC plus élevés que les méthodes de base pour tous les ensembles de données (les séquences de sortie correctes sélectionnées au hasard ont des valeurs plus élevées que les séquences de sortie incorrectes sélectionnées au hasard) probabilité d'obtenir un score de sélection plus élevé).
Par exemple, sur le benchmark CoQA, ASPIRE améliore AUROC de 51,3% à 80,3% par rapport à la référence.
Un modèle intéressant a émergé de l'évaluation de l'ensemble de données TriviaQA.
Bien que le modèle OPT-30B pré-entraîné présente une précision de base plus élevée, ses performances de prédiction sélective ne s'améliorent pas de manière significative lorsque les méthodes d'auto-évaluation traditionnelles (auto-évaluation et P (vrai)) sont appliquées.
En revanche, le modèle OPT-2.7B, beaucoup plus petit, surpasse les autres modèles à cet égard après avoir été amélioré avec ASPIRE.
Cette différence incarne un problème important : les LLM plus grands utilisant des techniques d'auto-évaluation traditionnelles peuvent ne pas être aussi efficaces en matière de prédiction sélective que les modèles plus petits améliorés par ASPIRE.
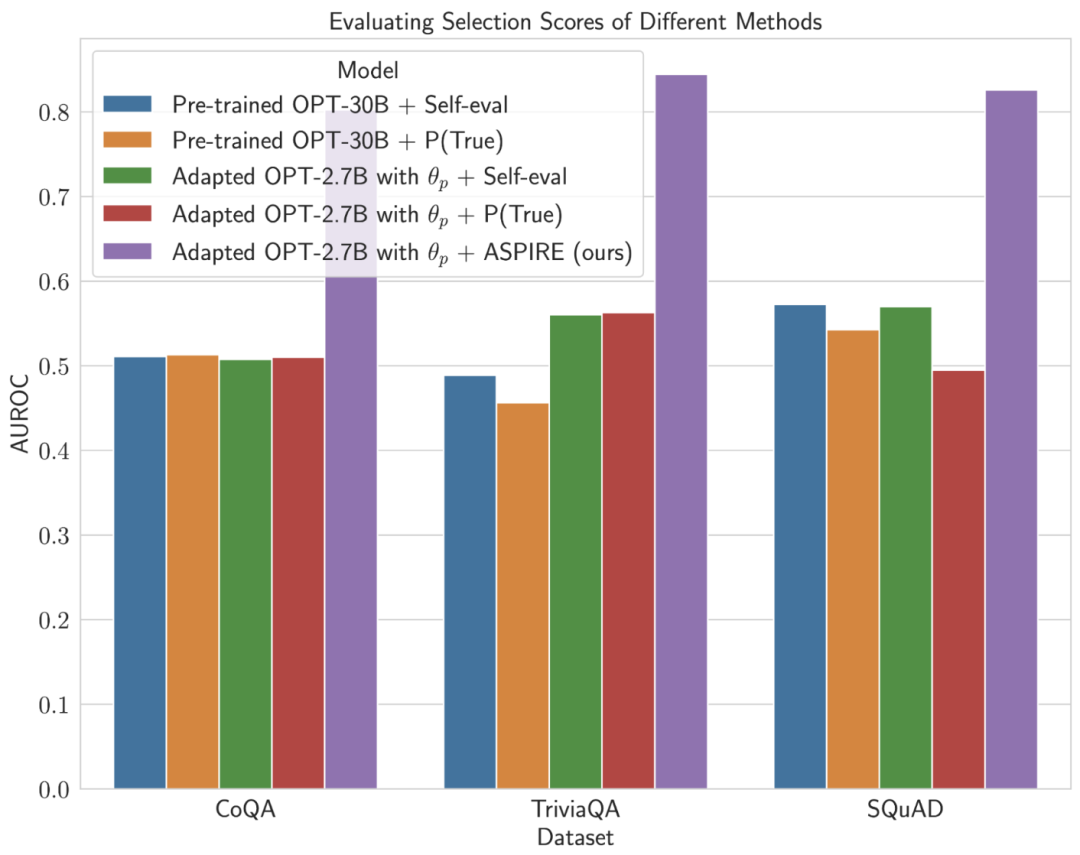
Le parcours expérimental des chercheurs avec ASPIRE met en évidence un changement clé dans le paysage LLM : la capacité d'un modèle de langage n'est pas la clé de sa performance.
En revanche, l'efficacité du modèle peut être considérablement améliorée grâce à des ajustements politiques, permettant des prédictions plus précises et plus fiables, même dans des modèles plus petits.
Ainsi, ASPIRE démontre le potentiel de LLM pour déterminer judicieusement la certitude de ses propres réponses et surpasser significativement d'autres modèles de 10 fois la taille dans les tâches de prédiction sélective.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment TensorFlow met en œuvre l'entraînement aléatoire et l'entraînement par lots
- Quels sont les types de données Java ?
- Comment importer des données d'un tableau Excel dans un autre tableau
- Comment sélectionner rapidement une colonne de données
- Google l'a fait aussi ? Bard a été exposé à l'utilisation des données ChatGPT pour la formation. Le grand modèle prend vraiment du retard, étape par étape.