
Maison >Périphériques technologiques >IA >Google l'a fait aussi ? Bard a été exposé à l'utilisation des données ChatGPT pour la formation. Le grand modèle prend vraiment du retard, étape par étape.
Google l'a fait aussi ? Bard a été exposé à l'utilisation des données ChatGPT pour la formation. Le grand modèle prend vraiment du retard, étape par étape.

- PHPzavant
- 2023-04-04 12:30:021719parcourir
Selon The Information, Jacob Devlin, ancien chercheur en intelligence artificielle de Google, a récemment quitté l'entreprise pour rejoindre OpenAI, mais avant cela, il a révélé qu'il avait averti Sundar Pichai, PDG de la société mère de Google, Alphabet, à propos du chat de Google. Le bot Bard obtient des données de ChatGPT de manière indirecte.

Vous souvenez-vous encore que Baidu Wenxinyiyan a été interrogé dans le cadre d'un incident « obus » ? Récemment, des médias étrangers ont annoncé que Google semblait avoir fait de même.
Selon The Information, Jacob Devlin, ancien chercheur en intelligence artificielle de Google, a récemment quitté l'entreprise pour rejoindre OpenAI, mais avant cela, il a révélé qu'il avait averti Sundar Pichai, PDG de la société mère de Google Alphabet, que le chatbot Bard de Google obtenait des données. de ChatGPT de manière indirecte.
Selon la description de Devlin, l'équipe de développement de Bard a visité un site Web appelé ShareGPT, qui partageait et publiait un grand nombre de contenus de discussion obtenus par les utilisateurs via ChatGPT. Cela signifie que Bard a utilisé les données prêtes à l’emploi de ChatGPT pour s’« armer », ce qui équivaut à voler les premiers résultats de ChatGPT.

En réponse, le porte-parole de Google, Chris Pappas, a rapidement publié une déclaration aux médias, déclarant fermement et clairement : "Bard n'est formé sur aucune donnée de ShareGPT ou ChatGPT.")"
Lorsque les médias lui ont demandé. " Si Google Bard avait déjà utilisé les données ChatGPT auparavant, Pappas a refusé de répondre, insistant sur le fait que tout ce qu'il pouvait dire était le contenu de la déclaration ci-dessus.
Cet incident ne peut que rappeler aux gens les doutes similaires auxquels Baidu Wenxin Yiyan a récemment été confronté.
Fin mars, certains internautes ont publié un article remettant en question Yiyan Painting de Baidu Wenxin, qui signifie essentiellement « traduire automatiquement des phrases chinoises en mots anglais, en utilisant l'intelligence artificielle Stable Diffusion qui vient d'être open source à l'étranger pour générer des images, puis revenir Les exemples donnés par les internautes à l'époque incluent la saisie d'instructions dans Wen Xinyiyan et lui demandant de dessiner « une souris et un bus ». L'image faite par Wenxinyiyan était « une souris et un bus » parce que « "souris" et "bus" sont "souris" et "bus" en anglais.
Baidu a également répondu de toute urgence. Le 23 mars, Baidu a publié une déclaration indiquant que Wenxin Yiyan est entièrement un grand modèle de langage développé par Baidu et que la capacité de graphe Wenxin provient du grand modèle multimodal Wenxin ERNIE-ViLG. Dans la formation de grands modèles, Baidu utilise des données publiques mondiales sur Internet, ce qui est conforme aux pratiques de l'industrie. Dans le même temps, il a déclaré que Wen Xinyiyan apprend et grandit constamment au cours du processus d'utilisation et espère que tout le monde aura une certaine confiance dans la technologie et les produits auto-développés.
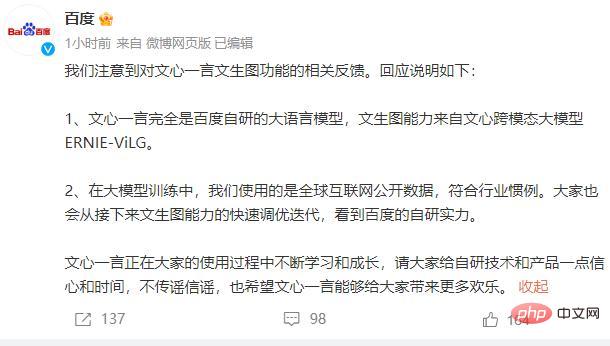 Par la suite, Baidu a corrigé des problèmes similaires et les utilisateurs ont rapidement découvert que les problèmes associés n'existaient plus, indiquant que des situations similaires étaient en cours de correction sur la base des commentaires des utilisateurs.
Par la suite, Baidu a corrigé des problèmes similaires et les utilisateurs ont rapidement découvert que les problèmes associés n'existaient plus, indiquant que des situations similaires étaient en cours de correction sur la base des commentaires des utilisateurs.
En ce qui concerne la question de Baidu Wen Xinyiyan, les experts du secteur ont également déclaré que l'utilisation des données publiques en ligne est une opération de base de l'industrie. Il existe un certain nombre de fournisseurs de services intermédiaires dans ce secteur spécialisés dans la formation de données pour les applications d'IA. Les ensembles de données d'IA qu'ils entraînent sur la base d'annotations de données publiques sont en effet utilisés par plusieurs applications d'IA en même temps.
Cependant, les opérations de base du secteur peuvent ne pas recevoir la même compréhension et la même reconnaissance au niveau du consommateur. Cette fois, Google Bard a été exposé à l'utilisation des données ChatGPT à des fins de formation, ce qui a également provoqué un tollé à l'étranger. les résultats d’OpenAI.
Les données publiques sur Internet, y compris les informations sur les sites Web, sont facilement capturées par des moyens techniques, ce qui est encore plus facile pour Google, qui est un moteur de recherche. De plus, de telles révélations émanent d'employés de Google qui viennent de démissionner, et la crédibilité s'en est naturellement grandement améliorée.
Cependant, certains internautes ont souligné que Devlin a rejoint le concurrent OpenAI après avoir quitté l'équipe Google AI. Ses révélations impliquent inévitablement des intérêts commerciaux, et l'authenticité doit être confirmée davantage.
Cependant, de l'avis de Geek.com, aussi vrai qu'un tel incident soit, il démontre pleinement une « règle de fer » : le domaine des grands modèles d'IA est vraiment à la traîne, et les retardataires veulent rattraper leur retard. avec les premiers arrivés, ce n'est pas facile.
Il existe de nombreux facteurs d'influence derrière cela, notamment les algorithmes, la puissance de calcul et la qualité des données d'entraînement. Ce qui est plus important, c'est qu'une fois que le premier grand modèle d'IA aura trouvé le chemin du succès, il continuera à se former et à évoluer, et ne s'arrêtera pas et n'attendra pas ses poursuivants.
Pour cette raison, l'ère GPT d'OpenAI a été rapidement mise à niveau de l'ère GPT-3 à l'ère GPT-4. Cela a également incité un certain nombre de célébrités, dont Musk, à publier conjointement une lettre ouverte appelant les grandes entreprises à suspendre le développement de grands modèles. . , pour éviter de menacer les humains.
Robin Li a également déclaré dans une précédente interview avec les médias que même s'il est plus performant dans certains domaines, il existe globalement encore un écart d'un ou deux mois entre le niveau de Baidu Wenxinyiyan et celui d'OpenAI ChatGPT. Il a également souligné que lorsque ChatGPT a été lancé dès les premiers stades, les retours externes étaient encore pires que ceux de Wen Xinyiyan.
Il y a aussi de mauvaises nouvelles pour Google Bard. Selon la rumeur, l'équipe d'intelligence artificielle Brain de Google travaillerait avec DeepMind, une autre société d'intelligence artificielle affiliée à Alphabet, pour mener conjointement un nouveau projet nommé Gemini. Des produits pouvant rivaliser avec le GPT d'OpenAI. Cela semble impliquer que Google n'a pas confiance en Bard et espère développer un grand modèle d'IA plus avancé et créer un robot de chat IA plus avancé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI