
Maison >Périphériques technologiques >IA >RoboFusion pour une détection 3D multimodale fiable à l'aide de SAM
RoboFusion pour une détection 3D multimodale fiable à l'aide de SAM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-16 14:03:211316parcourir
Lien papier : https://arxiv.org/pdf/2401.03907.pdf
Le détecteur 3D multimodal est conçu pour étudier les systèmes de perception de conduite autonome sûrs et fiables. Bien qu’ils atteignent des performances de pointe sur des ensembles de données de référence propres, la complexité et les conditions difficiles des environnements réels sont souvent ignorées. Dans le même temps, avec l’émergence du Vision Foundation Model (VFM), l’amélioration de la robustesse et des capacités de généralisation de la détection 3D multimodale se heurte à des opportunités et à des défis en matière de conduite autonome. Par conséquent, les auteurs proposent le cadre RoboFusion, qui exploite le VFM comme SAM pour traiter les scénarios de bruit hors distribution (OOD).
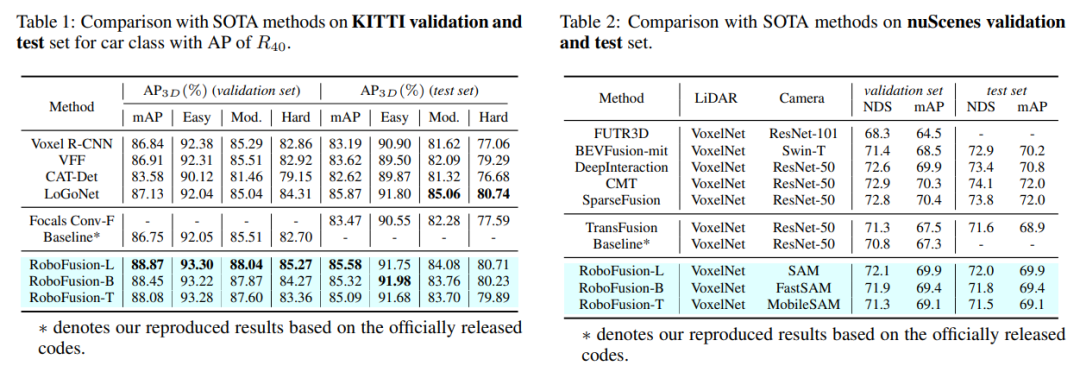
Tout d'abord, nous appliquons le SAM original à un scénario de conduite autonome appelé SAM-AD. Pour aligner SAM ou SAMAD avec des méthodes multimodales, nous introduisons AD-FPN pour suréchantillonner les caractéristiques de l'image extraites par SAM. Pour réduire davantage le bruit et les interférences météorologiques, nous utilisons la décomposition en ondelettes pour débruiter les images guidées en profondeur. Enfin, nous utilisons un mécanisme d’auto-attention pour repondérer de manière adaptative les fonctionnalités fusionnées afin d’améliorer les fonctionnalités informatives tout en supprimant l’excès de bruit. RoboFusion améliore la résilience de la détection d'objets 3D multimodale en tirant parti de la généralisation et de la robustesse de VFM pour réduire progressivement le bruit. En conséquence, RoboFusion atteint des performances de pointe dans les scènes bruyantes, selon les résultats des tests KITTIC et nuScenes-C.
L'article propose un cadre robuste appelé RoboFusion, qui utilise VFM comme SAM pour adapter les détecteurs d'objets multimodaux 3D des scènes propres aux scènes bruyantes OOD. Parmi eux, la stratégie d'adaptation de SAM est la clé.
1) Utilisez les fonctionnalités extraites de SAM au lieu de déduire les résultats de segmentation.
2) SAM-AD est proposé, qui est un SAM pré-entraîné pour les scénarios AD.
3) Un nouvel AD-FPN est introduit pour résoudre le problème de suréchantillonnage des fonctionnalités pour l'alignement du VFM avec des détecteurs 3D multimodaux.
Afin de réduire les interférences sonores et de conserver les caractéristiques du signal, le module Deep Guided Wavelet Attention (DGWA) est introduit pour atténuer efficacement le bruit haute et basse fréquence.
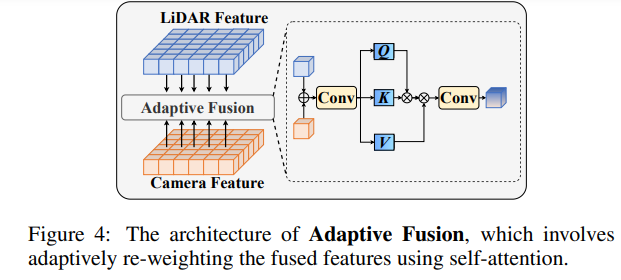
Après avoir fusionné les fonctionnalités de nuage de points et les fonctionnalités d'image, repondérez les fonctionnalités grâce à une fusion adaptative pour améliorer la robustesse et la résistance au bruit des fonctionnalités.
Structure du réseau RoboFusion
Le framework RoboFusion est présenté ci-dessous et sa branche lidar suit la ligne de base [Chen et al., 2022] pour générer des fonctionnalités lidar. Dans le secteur des caméras, l'algorithme SAM-AD hautement optimisé est d'abord utilisé pour extraire des caractéristiques d'image robustes, puis combiné avec AD-FPN pour obtenir des fonctionnalités multi-échelles. Ensuite, les points d'origine sont utilisés pour générer une carte de profondeur clairsemée S, qui est entrée dans le codeur de profondeur pour obtenir des caractéristiques de profondeur, et est fusionnée avec des caractéristiques d'image multi-échelles pour obtenir des caractéristiques d'image guidées en profondeur. Ensuite, le bruit de mutation est supprimé grâce au mécanisme d’attention fluctuant. Enfin, la fusion adaptative est obtenue grâce à un mécanisme d'auto-attention permettant de combiner des fonctionnalités de nuage de points avec des fonctionnalités d'image robustes avec des informations de profondeur.
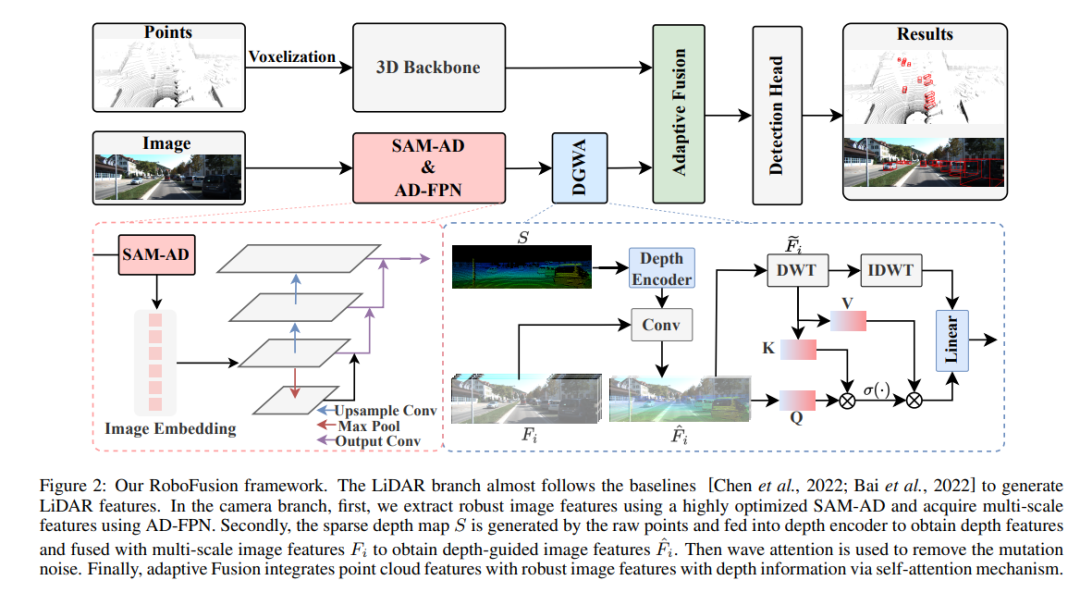
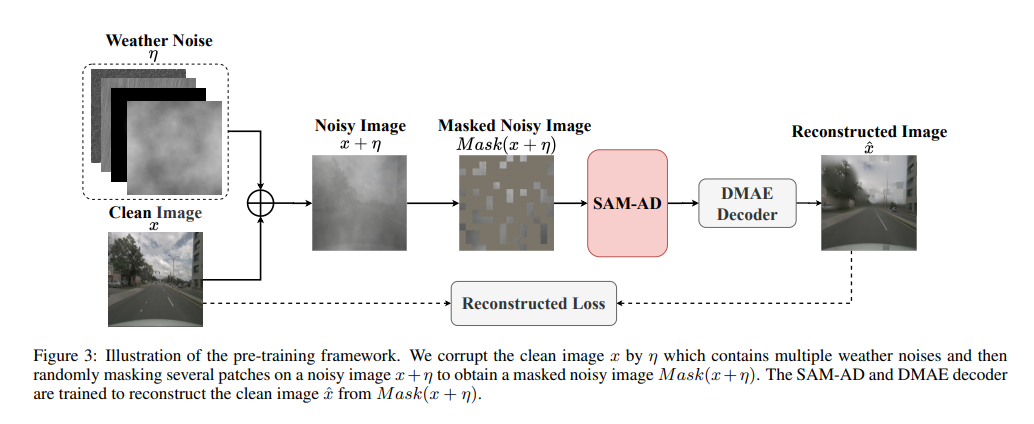
SAM-AD : Afin d'adapter davantage le SAM aux scénarios AD (conduite autonome), SAM est pré-entraîné pour obtenir le SAM-AD. Plus précisément, nous collectons un grand nombre d'échantillons d'images à partir d'ensembles de données matures (c'est-à-dire KITTI et nuScenes) pour former l'ensemble de données AD de base. Après DMAE, SAM est pré-entraîné pour obtenir SAM-AD dans les scénarios AD, comme le montre la figure 3. Désignons x comme l'image propre de l'ensemble de données AD (c'est-à-dire KITTI et nuScenes) et eta comme l'image bruyante générée en fonction de x. Le type et la gravité du bruit ont été sélectionnés au hasard parmi quatre conditions météorologiques (pluie, neige, brouillard et soleil) et cinq niveaux de gravité allant de 1 à 5, respectivement. En utilisant SAM, l'encodeur d'image de MobileSAM comme encodeur, tandis que les pertes du décodeur et de la reconstruction sont les mêmes que celles du DMAE.
AD-FPN. En tant que modèle de segmentation cuable, SAM se compose de trois parties : un encodeur d'image, un encodeur de repère et un décodeur de masque. De manière générale, il faut généraliser l'encodeur d'image pour entraîner le VFM puis entraîner le décodeur. En d’autres termes, l’encodeur d’image peut fournir des intégrations d’images de haute qualité et très robustes aux modèles en aval, tandis que le décodeur de masque est uniquement conçu pour fournir des services de décodage pour la segmentation sémantique. De plus, nous avons besoin de fonctionnalités d’image robustes plutôt que du traitement des informations de repère par l’encodeur de repère. Par conséquent, nous utilisons l’encodeur d’image de SAM pour extraire des caractéristiques d’image robustes. Cependant, SAM utilise la série ViT comme encodeur d'image, ce qui exclut les fonctionnalités multi-échelles et ne fournit que des fonctionnalités basse résolution de haute dimension. Afin de générer les fonctionnalités multi-échelles nécessaires à la détection de cibles, inspiré de [Li et al., 2022a], un AD-FPN est conçu, qui fournit des fonctionnalités multi-échelles basées sur ViT !
Malgré la capacité de SAM-AD ou SAM à extraire des caractéristiques d'image robustes, l'écart entre le domaine 2D et le domaine 3D existe toujours, et les caméras manquant d'informations géométriques dans des environnements endommagés amplifient souvent le bruit et provoquent des problèmes de transfert négatif. Pour atténuer ce problème, nous proposons le module Deep Guided Wavelet Attention (DGWA), qui peut être divisé en deux étapes suivantes. 1) Un réseau de guidage en profondeur est conçu pour ajouter de la géométrie avant les caractéristiques de l'image en combinant les caractéristiques de l'image et les caractéristiques de profondeur des nuages de points. 2) Utilisez la transformation en ondelettes de Haar pour décomposer les caractéristiques de l'image en quatre sous-bandes, puis le mécanisme d'attention permet de débruiter les caractéristiques d'information dans les sous-bandes !
Comparaison expérimentale
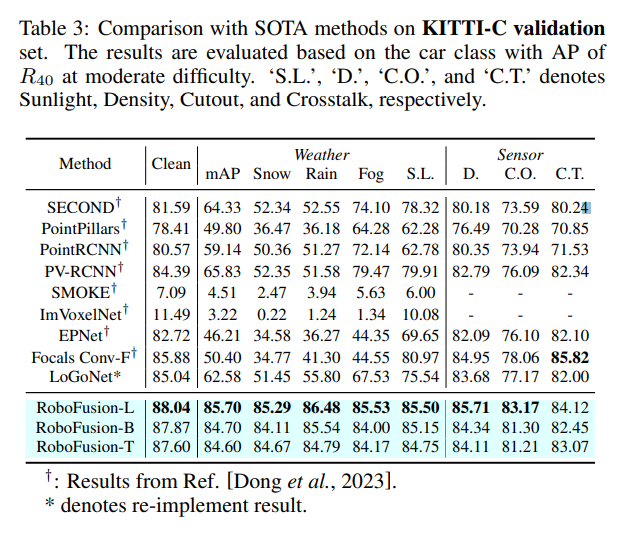
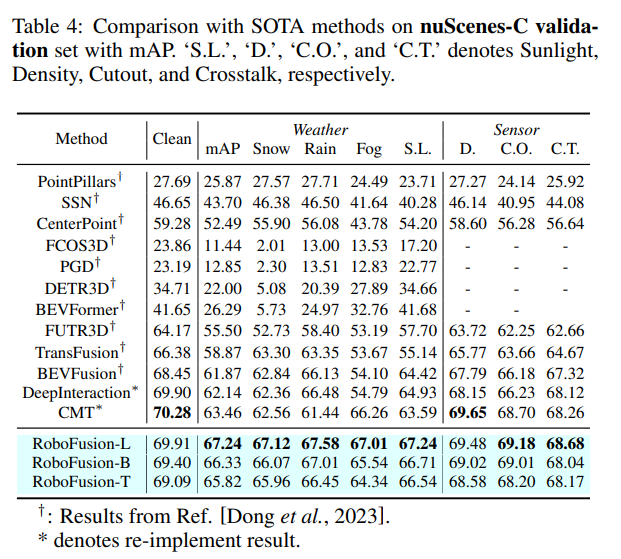
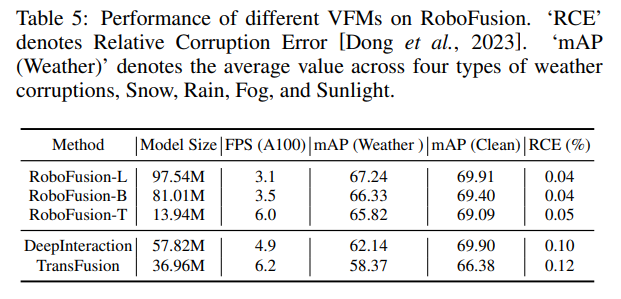

 Lien original : https://mp.weixin.qq.com/s/78y 1 KyipHeUSh5sLQZy-ng
Lien original : https://mp.weixin.qq.com/s/78y 1 KyipHeUSh5sLQZy-ng
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!