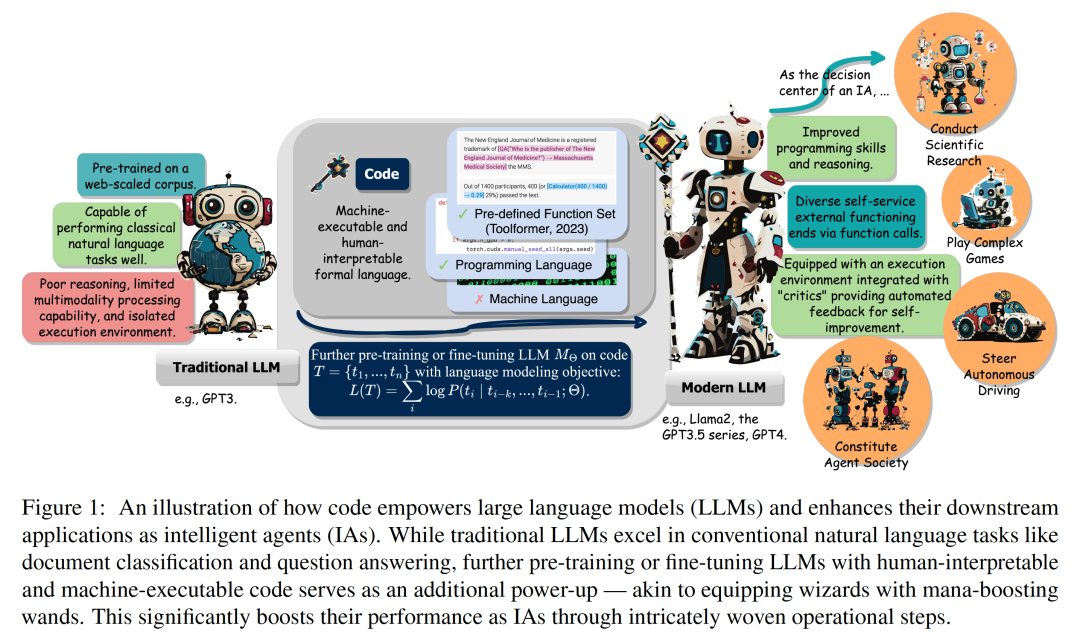
Tout comme la baguette de Rhysford a créé la légende de magiciens extraordinaires de tous âges, tels que Dumbledore, les modèles de langage traditionnels à grande échelle dotés d'un énorme potentiel, après une pré-formation/un réglage fin du corpus de code, ont maîtrisé les connaissances au-delà de la source d'exécution. . Plus précisément, la version avancée du grand modèle a été améliorée en termes d'écriture de code, de raisonnement plus fort, de référence indépendante aux interfaces d'exécution, d'amélioration indépendante, etc., ce qui lui permettra de servir plus facilement d'IA agent et effectuer des tâches en aval dans tous les aspects. Récemment, une équipe de recherche de l'Université de l'Illinois à Urbana-Champaign (UIUC) a publié une revue importante. 
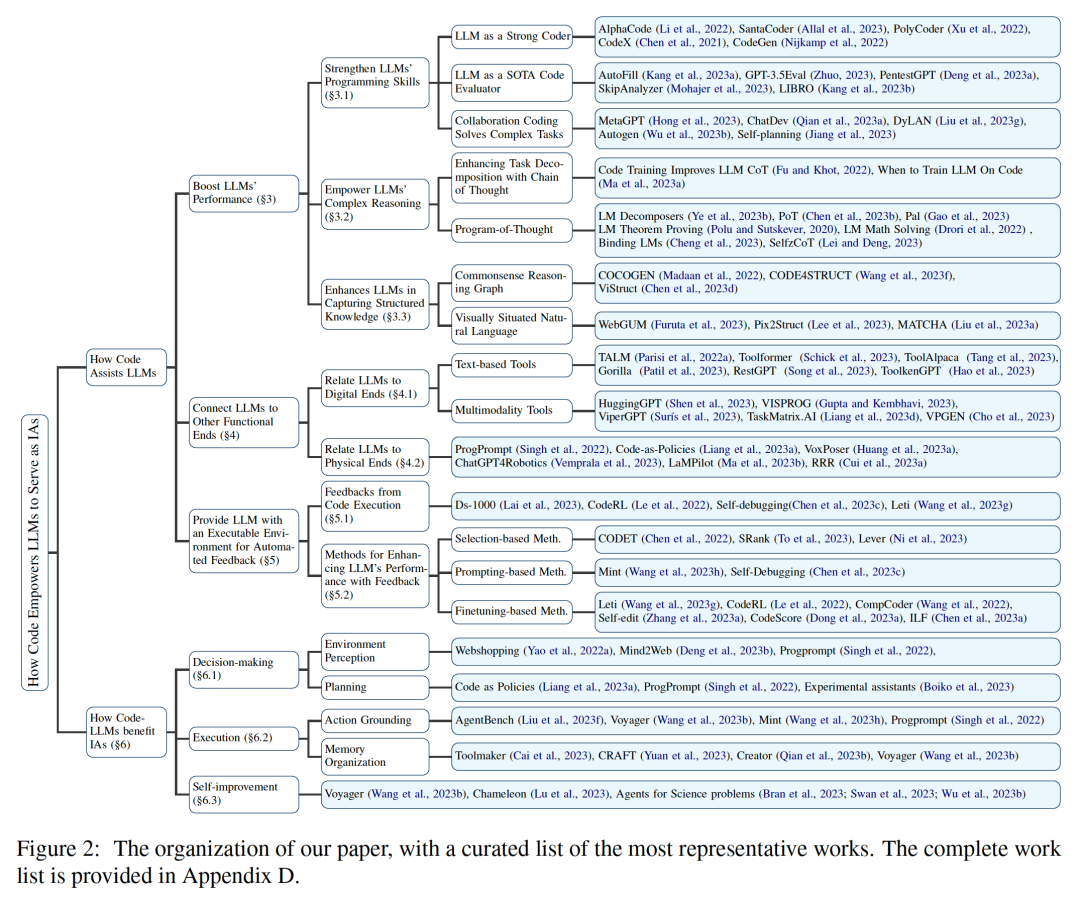
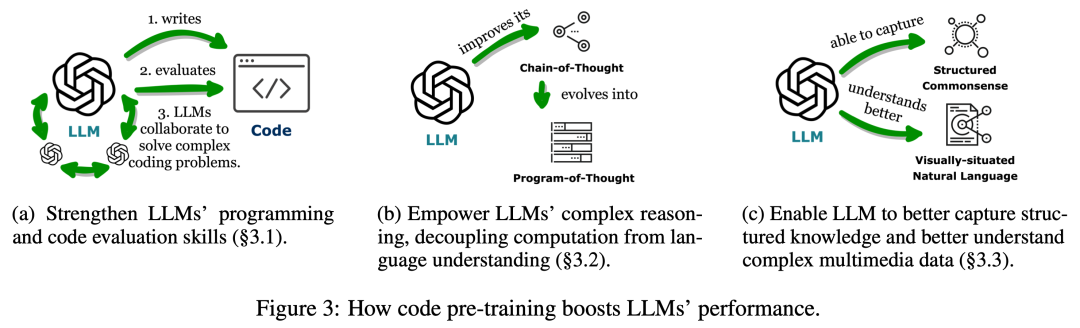
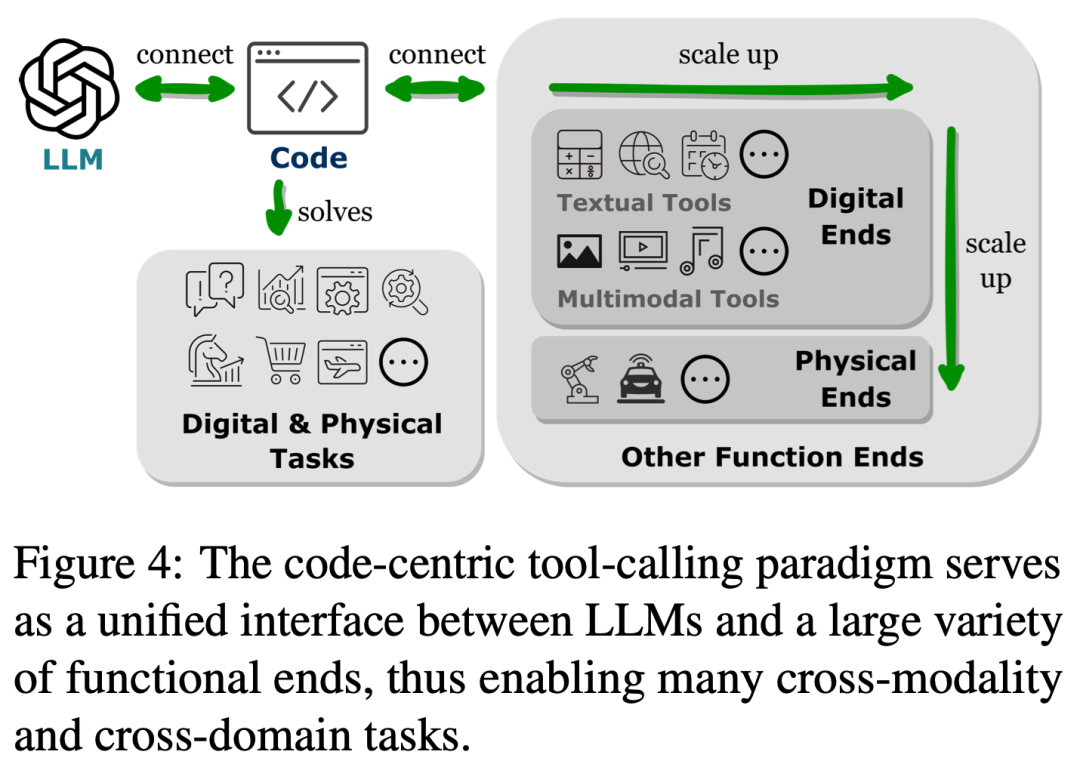
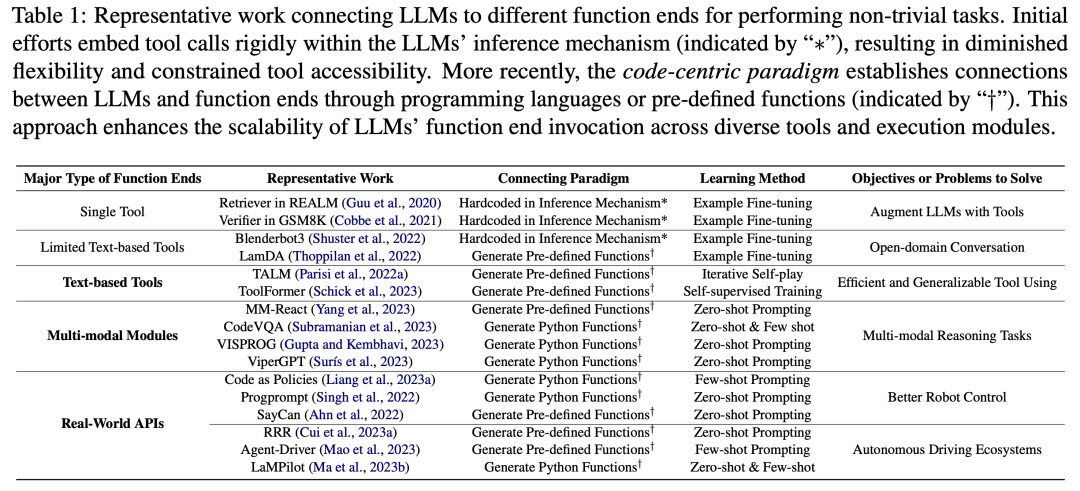
Lien papier : https://arxiv.org/abs/2401.00812Cette revue explore comment le code renforce les grands modèles de langage (LLM) et leurs agents intelligents (Intelligents) basés sur lui) de puissantes capacités . Parmi eux, le code fait spécifiquement référence à un langage formel exécutable par machine et lisible par l'homme, comme un langage de programmation, un ensemble de fonctions prédéfinies, etc. De la même manière que nous guidons les LLM pour comprendre/générer le langage naturel traditionnel, pour rendre les LLM compétents en code, il suffit d'appliquer les mêmes objectifs de formation en modélisation linguistique aux données de code. Différents des modèles de langage traditionnels, les LLM courants d'aujourd'hui, tels que Llama2 et GPT4, ont non seulement considérablement amélioré leur taille, mais ils ont également suivi une formation de corpus de code indépendante du corpus typique du langage naturel. Le code a une syntaxe, une cohérence logique, une abstraction et une modularité standardisées, et peut transformer des objectifs de haut niveau en étapes exécutables, ce qui en fait un moyen idéal pour connecter les humains et les ordinateurs. Comme le montre la figure 2, dans cette revue, les chercheurs ont compilé des travaux pertinents et analysé en détail les différents avantages de l'incorporation de code dans les données de formation LLM. Plus précisément, les chercheurs ont observé que les propriétés uniques du code aident à : 1 Améliorer les capacités d'écriture de code, les capacités de raisonnement et les capacités de traitement de l'information structurée des LLM, leur permettant ainsi de s'appliquer à des processus naturels plus complexes. tâches de langage ; 2. Guider les LLM pour générer des étapes intermédiaires structurées et précises, qui peuvent être connectées à des fins d'exécution externes via des appels de fonction ; 3. Utiliser l'environnement de compilation et d'exécution du code pour fournir une amélioration autonome du modèle et fournir des commentaires divers. De plus, les chercheurs ont également observé en profondeur comment les éléments d'optimisation de ces LLM donnés par le code peuvent les renforcer en tant que centre de prise de décision de l'agent intelligent, comprenant les instructions, décomposant les objectifs, planifiant et exécutant les actions, et Amélioration des capacités de la série. Comme le montre la figure 3, dans la première partie, les chercheurs ont découvert que la pré-formation des LLM sur le code a élargi la portée des tâches des LLM au-delà du langage naturel. Ces modèles peuvent prendre en charge diverses applications, notamment la génération de code pour les théories mathématiques, les tâches de programmation générales et la récupération de données. Le code doit produire une séquence d’étapes logiquement cohérentes et ordonnées, ce qui est essentiel pour une exécution efficace. De plus, l'exécutabilité de chaque étape du code permet une vérification étape par étape de la logique. L'exploitation et l'intégration de ces attributs de code dans la pré-formation améliorent les performances de la chaîne de pensée (CoT) des LLM dans de nombreuses tâches traditionnelles en aval du langage naturel, validant ainsi leur amélioration des compétences de raisonnement complexes. Dans le même temps, en apprenant implicitement le format structuré du code, les codeLLM sont plus performants dans les tâches de raisonnement structuré de bon sens, telles que celles liées aux langages de balisage, au HTML et à la compréhension des diagrammes. Comme le montre la figure 4, la connexion des LLM à d'autres fins fonctionnelles (c'est-à-dire l'extension des capacités des LLM via des outils externes et des modules d'exécution) aide les LLM à effectuer des tâches avec plus de précision et de fiabilité. Dans la deuxième partie, comme le montre le tableau 1, les chercheurs ont observé une tendance générale : les LLM établissent des connexions avec d'autres points de terminaison fonctionnels en générant des langages de programmation ou en exploitant des fonctions prédéfinies. Ce « paradigme centré sur le code » diffère de l’approche rigide des appels d’outils strictement codés en dur dans le mécanisme d’inférence des LLM, qui permet aux LLM de générer dynamiquement des jetons qui appellent des modules d’exécution, avec des paramètres réglables.
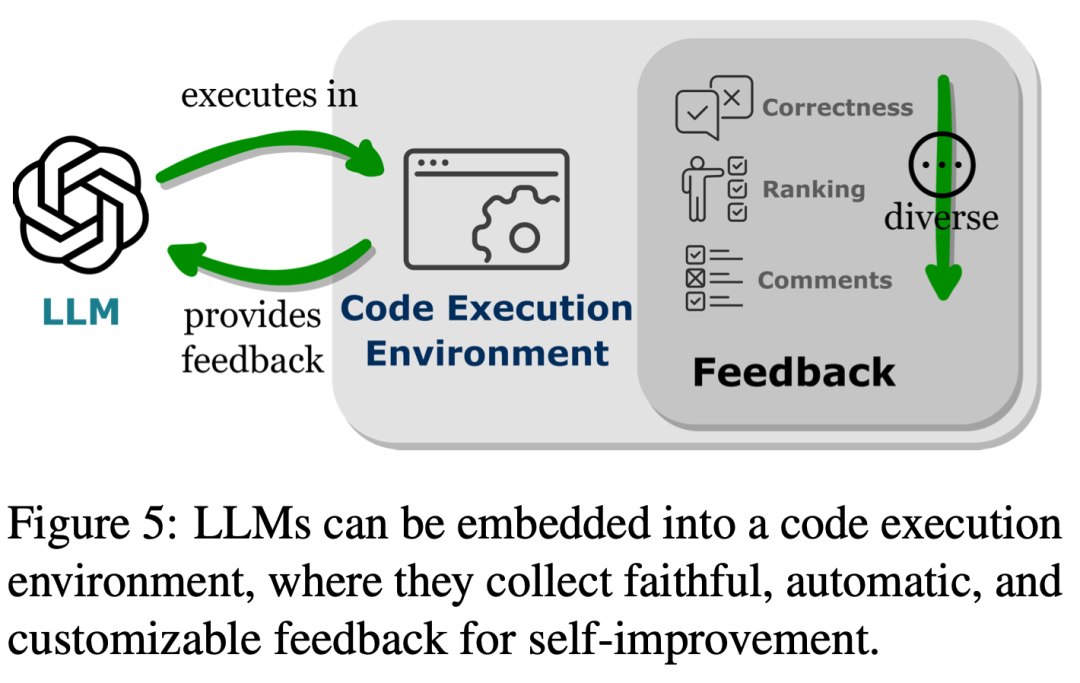
Ce paradigme fournit aux LLM un moyen simple et clair d'interagir avec d'autres fins fonctionnelles, améliorant ainsi la flexibilité et l'évolutivité de leurs applications. Plus important encore, cela permet également aux LLM d'interagir avec de nombreux points finaux fonctionnels couvrant plusieurs modalités et domaines. En augmentant le nombre et la variété de terminaux fonctionnels accessibles aux LLM, les LLM sont capables de gérer des tâches plus complexes. Comme le montre la figure 5, l'intégration de LLM dans l'environnement d'exécution de code peut obtenir un retour automatisé et une amélioration indépendante du modèle. Les LLM fonctionnent au-delà de la plage de leurs paramètres de formation, en partie parce qu'ils sont capables de prendre en compte les commentaires. Cependant, le feedback doit être choisi avec soin, car une entrée de signal bruyante peut entraver les performances des LLM sur les tâches en aval. De plus, les ressources humaines étant coûteuses, les feedbacks doivent être collectés automatiquement tout en préservant leur authenticité. Dans la troisième partie, les chercheurs ont découvert que l’intégration de LLM dans l’environnement d’exécution de code peut générer des retours répondant à tous ces critères.
Tout d'abord, puisque l'exécution du code est déterministe, obtenir un retour sur les résultats de l'exécution du code peut refléter directement et fidèlement les tâches effectuées par LLM. De plus, les interpréteurs de code fournissent aux LLM un moyen d'interroger automatiquement les commentaires internes, éliminant ainsi le besoin d'annotations humaines coûteuses lors de l'utilisation des LLM pour déboguer ou optimiser du code erroné. L'environnement de compilation et d'exécution de code permet également aux LLM d'incorporer des formulaires de rétroaction externes divers et complets, tels qu'une génération simple d'évaluations binaires correctes et d'erreurs, des explications en langage naturel légèrement plus complexes des résultats d'exécution et divers classements avec des méthodes de rétroaction, le tout. rendre les méthodes d'amélioration des performances hautement personnalisables. En analysant les différentes façons dont l'intégration des données de formation du code améliore les capacités des LLM, les chercheurs ont en outre découvert que les avantages des LLM autonomisant le code sont particulièrement évidents dans le domaine d'application clé du LLM qu'est le développement d'agents intelligents. La figure 6 montre le flux de travail standard d'un assistant intelligent. Les chercheurs ont observé que les améliorations apportées par la formation au code dans les LLM affectaient également les étapes réelles qu'ils effectuaient en tant qu'assistants intelligents. Ces étapes comprennent : (1) l'amélioration des capacités de prise de décision de l'IA en matière de sensibilisation et de planification environnementale, (2) l'optimisation de l'exécution de la stratégie en mettant en œuvre des actions dans des primitives d'action modulaires et une mémoire organisationnelle efficace, et (3) optimiser les performances. grâce à des commentaires automatiquement dérivés de l’environnement d’exécution du code. En résumé, dans cette revue, les chercheurs analysent et clarifient comment le code confère aux LLM de puissantes capacités et comment le code aide les LLM à fonctionner en tant que centres de décision des agents intelligents. Grâce à une revue complète de la littérature, les chercheurs ont observé qu'après une formation au code, les LLM ont amélioré leurs compétences en programmation et leurs capacités de raisonnement, ont acquis la capacité de mettre en œuvre des connexions flexibles avec de multiples fins fonctionnelles dans tous les modes et domaines, et ont renforcé leur capacité à interagir avec le module d'évaluation intégré dans l'environnement d'exécution de code et réaliser une auto-amélioration automatique. De plus, les capacités améliorées des LLM apportées par la formation au code contribuent à leurs performances en tant qu'agents intelligents dans les applications en aval, reflétées dans des étapes opérationnelles spécifiques telles que la prise de décision, l'exécution et l'auto-amélioration. En plus d'examiner les recherches antérieures, les chercheurs ont également proposé plusieurs défis dans le domaine comme éléments directeurs pour de potentielles orientations futures. Veuillez vous référer à l'article original pour plus de détails ! Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!