

 Périphériques technologiquesIAAdaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
Périphériques technologiquesIAAdaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
La tâche de génération d'image en vidéo (I2V) est un défi dans le domaine de la vision par ordinateur qui vise à convertir des images statiques en vidéos dynamiques. La difficulté de cette tâche est d'extraire et de générer des informations dynamiques dans la dimension temporelle à partir d'une seule image tout en conservant l'authenticité et la cohérence visuelle du contenu de l'image. Les méthodes I2V existantes nécessitent souvent des architectures de modèles complexes et de grandes quantités de données de formation pour atteindre cet objectif.
Récemment, un nouveau résultat de recherche « I2V-Adapter : A General Image-to-Video Adapter for Video Diffusion Models » dirigé par Kuaishou a été publié. Cette recherche introduit une méthode innovante de conversion image-vidéo et propose un module adaptateur léger, l'I2V-Adapter. Ce module adaptateur est capable de convertir des images statiques en vidéos dynamiques sans modifier la structure d'origine et les paramètres pré-entraînés des modèles de génération texte-vidéo (T2V) existants. Cette méthode a de larges perspectives d'application dans le domaine de la conversion d'image en vidéo et peut apporter davantage de possibilités à la création vidéo, à la communication médiatique et à d'autres domaines. La publication des résultats de la recherche revêt une grande importance pour promouvoir le développement de la technologie de l'image et de la vidéo et constitue un outil et une méthode efficaces pour les chercheurs dans des domaines connexes.

- Adresse papier : https://arxiv.org/pdf/2312.16693.pdf
- Page d'accueil du projet : https://i2v-adapter.github.io/index .html
- Adresse du code : https://github.com/I2V-Adapter/I2V-Adapter-repo
Par rapport aux méthodes existantes, I2V-Adapter a davantage de paramètres entraînables. D'énormes améliorations ont été réalisé, et le nombre de paramètres peut atteindre aussi bas que 22M, ce qui ne représente que 1% de la solution grand public Stable Video Diffusion. Dans le même temps, l'adaptateur est également compatible avec les modèles T2I personnalisés (tels que DreamBooth, Lora) et les outils de contrôle (tels que ControlNet) développés par la communauté Stable Diffusion. Grâce à des expériences, les chercheurs ont prouvé l'efficacité de l'I2V-Adapter pour générer du contenu vidéo de haute qualité, ouvrant ainsi de nouvelles possibilités d'applications créatives dans le domaine I2V.

Introduction à la méthode
Modélisation temporelle avec diffusion stable
Par rapport à la génération d'images, la génération vidéo est confrontée à un défi unique, à savoir modéliser la cohérence temporelle entre les images vidéo et le sexe. La plupart des méthodes actuelles sont basées sur des modèles T2I pré-entraînés, tels que Stable Diffusion et SDXL, en introduisant des modules de synchronisation pour modéliser les informations de synchronisation dans les vidéos. Inspiré d'AnimateDiff, un modèle initialement conçu pour les tâches T2V personnalisées, il modélise les informations de synchronisation en introduisant un module de synchronisation découplé du modèle T2I, et conserve la capacité du modèle T2I d'origine à générer des vidéos fluides. Par conséquent, les chercheurs pensent que le module temporel pré-entraîné peut être considéré comme une représentation temporelle universelle et peut être appliqué à d’autres scénarios de génération vidéo, tels que la génération I2V, sans aucun réglage précis. Par conséquent, les chercheurs ont directement utilisé le module de synchronisation AnimateDiff pré-entraîné et ont maintenu ses paramètres fixes.
Adaptateur pour les couches d'attention
Un autre défi de la tâche I2V est de conserver les informations d'identification de l'image d'entrée. Il existe actuellement deux solutions principales : l'une consiste à utiliser un encodeur d'image pré-entraîné pour coder l'image d'entrée et à injecter les caractéristiques codées dans le modèle via un mécanisme d'attention croisée pour guider le processus de débruitage ; concaténés avec l'entrée bruyante dans la dimension du canal, puis introduits ensemble dans le réseau suivant. Cependant, la première méthode peut entraîner une modification de l'ID vidéo généré car il est difficile pour l'encodeur d'image de capturer les informations sous-jacentes, tandis que la seconde méthode nécessite souvent de modifier la structure et les paramètres du modèle T2I, ce qui entraîne des coûts de formation élevés et médiocres ; compatibilité.
Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé l'adaptateur I2V. Plus précisément, le chercheur entre l'image d'entrée et l'entrée bruitée dans le réseau en parallèle. Dans le bloc spatial du modèle, toutes les trames interrogeront en outre les informations de la première trame, c'est-à-dire que les caractéristiques clés et de valeur proviennent de la première trame sans bruit. , et la sortie Le résultat est ajouté à l'auto-attention du modèle d'origine. La matrice de mappage de sortie de ce module est initialisée avec des zéros et seules la matrice de mappage de sortie et la matrice de mappage de requêtes sont entraînées. Afin d'améliorer encore la compréhension du modèle des informations sémantiques de l'image d'entrée, les chercheurs ont introduit un adaptateur de contenu pré-entraîné (cet article utilise IP-Adapter [8]) pour injecter les caractéristiques sémantiques de l'image.

Frame Similarity Prior
Afin d'améliorer encore la stabilité des résultats générés, les chercheurs ont proposé une similarité inter-images avant de trouver un équilibre entre la stabilité et l'intensité du mouvement de la vidéo générée. L'hypothèse clé est qu'à un niveau de bruit gaussien relativement faible, la première image bruyante et les images suivantes bruyantes sont suffisamment proches, comme le montre la figure ci-dessous :
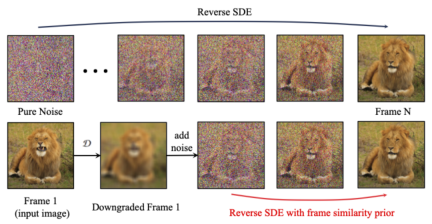
Ainsi, les chercheurs ont supposé que toutes les structures de trame étaient similaires. , et deviennent indiscernables après l'ajout d'une certaine quantité de bruit gaussien, de sorte que l'image d'entrée bruitée peut être utilisée comme entrée a priori pour les images suivantes. Afin d'éliminer le caractère trompeur des informations haute fréquence, les chercheurs ont également utilisé un opérateur de flou gaussien et un mélange de masques aléatoire. Plus précisément, l'opération est donnée par la formule suivante :

Résultats expérimentaux
Résultats quantitatifs
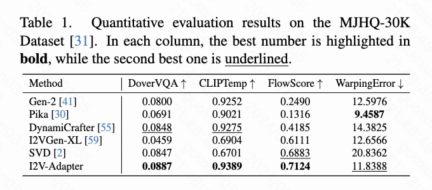
Cet article calcule quatre indicateurs quantitatifs, à savoir DoverVQA (score esthétique), CLIPTemp (premier Frame cohérence), FlowScore (amplitude de mouvement) et WarppingError (erreur de mouvement) sont utilisés pour évaluer la qualité de la vidéo générée. Le tableau 1 montre que l'adaptateur I2V a reçu le score esthétique le plus élevé et a également dépassé tous les schémas de comparaison en termes de cohérence de la première image. De plus, la vidéo générée par I2V-Adapter présente la plus grande amplitude de mouvement et une erreur de mouvement relativement faible, ce qui indique que ce modèle est capable de générer des vidéos plus dynamiques tout en conservant la précision du mouvement temporel.
Résultats qualitatifs
Animation d'image (gauche est l'entrée, droite est la sortie) :




avec T2I personnalisés (sur le Entrée gauche, droite est la sortie) :




w/ ControlNet (gauche est l'entrée, droite est la sortie) :



Résumé
Cet article propose I2V-Adapter, un module léger plug-and-play pour les tâches de génération d'image en vidéo. Cette méthode maintient fixes les structures et les paramètres des blocs spatiaux et des blocs de mouvement du modèle T2V d'origine, entre la première image sans bruit et les images suivantes avec du bruit en parallèle, et permet à toutes les images d'interagir avec la première image sans bruit via le mécanisme d'attention. , produisez ainsi une vidéo temporellement cohérente et cohérente avec la première image. Les chercheurs ont démontré l’efficacité de cette méthode sur des tâches I2V à travers des expérimentations quantitatives et qualitatives. De plus, sa conception découplée permet à la solution d'être directement combinée avec des modules tels que DreamBooth, Lora et ControlNet, prouvant la compatibilité de la solution et favorisant la recherche sur la génération d'image en vidéo personnalisée et contrôlable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AM
Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AMExploiter la puissance de l'IA sur disvise: construire une CLI de chatbot personnelle Dans un passé récent, le concept d'un assistant d'IA personnel semblait être une science-fiction. Imaginez Alex, un passionné de technologie, rêvant d'un compagnon d'IA intelligent et local - celui qui ne dépend pas
 L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AM
L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AMLeur lancement inaugural de l'AI4MH a eu lieu le 15 avril 2025, et le Dr Tom Insel, M.D., célèbre psychiatre et neuroscientifique, a été le conférencier de lancement. Le Dr Insel est réputé pour son travail exceptionnel dans la recherche en santé mentale et la techno
 La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM
La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM"Nous voulons nous assurer que la WNBA reste un espace où tout le monde, les joueurs, les fans et les partenaires d'entreprise, se sentent en sécurité, appréciés et autonomes", a déclaré Engelbert, abordé ce qui est devenu l'un des défis les plus dommageables des sports féminins. L'anno
 Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excelle comme un langage de programmation, en particulier dans la science des données et l'IA générative. La manipulation efficace des données (stockage, gestion et accès) est cruciale lorsqu'il s'agit de grands ensembles de données. Nous avons déjà couvert les nombres et ST
 Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AM
Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AMAvant de plonger, une mise en garde importante: les performances de l'IA sont non déterministes et très usagées. En termes plus simples, votre kilométrage peut varier. Ne prenez pas cet article (ou aucun autre) article comme le dernier mot - au lieu, testez ces modèles sur votre propre scénario
 Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AM
Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AMConstruire un portefeuille AI / ML hors concours: un guide pour les débutants et les professionnels La création d'un portefeuille convaincant est cruciale pour sécuriser les rôles dans l'intelligence artificielle (IA) et l'apprentissage automatique (ML). Ce guide fournit des conseils pour construire un portefeuille
 Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AM
Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AMLe résultat? L'épuisement professionnel, l'inefficacité et un écart d'élargissement entre la détection et l'action. Rien de tout cela ne devrait être un choc pour quiconque travaille en cybersécurité. La promesse d'une IA agentique est devenue un tournant potentiel, cependant. Cette nouvelle classe
 Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AM
Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AMImpact immédiat contre partenariat à long terme? Il y a deux semaines, Openai s'est avancé avec une puissante offre à court terme, accordant aux étudiants des États-Unis et canadiens d'accès gratuit à Chatgpt Plus jusqu'à la fin mai 2025. Cet outil comprend GPT - 4O, un A


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Version Mac de WebStorm
Outils de développement JavaScript utiles

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

