

 Périphériques technologiquesIAGrimper le long du câble réseau est devenu une réalité, Audio2Photoreal peut générer des expressions et des mouvements réalistes à travers le dialogue
Périphériques technologiquesIAGrimper le long du câble réseau est devenu une réalité, Audio2Photoreal peut générer des expressions et des mouvements réalistes à travers le dialogue
Lorsque vous et vos amis discutez sur l'écran froid du mobile, vous devez deviner le ton de l'autre personne. Lorsqu'il parle, ses expressions et même ses actions peuvent apparaître dans votre esprit. Il serait évidemment préférable que vous puissiez passer un appel vidéo, mais dans les situations réelles, vous ne pouvez pas passer d'appels vidéo à tout moment.
Si vous discutez avec un ami distant, ce n'est pas via un texte sur écran froid ou un avatar manquant d'expressions, mais une personne virtuelle numérique réaliste, dynamique et expressive. Cette personne virtuelle peut non seulement reproduire parfaitement le sourire, les yeux et même les mouvements subtils du corps de votre ami. Vous sentirez-vous plus gentil et chaleureux ? Il incarne vraiment la phrase « Je vais ramper le long du câble réseau pour vous trouver ».
Ce n'est pas un fantasme de science-fiction, mais une technologie qui peut être réalisée dans la réalité.
Les expressions faciales et les mouvements corporels contiennent une grande quantité d'informations, ce qui affectera grandement la signification du contenu. Par exemple, parler en regardant l'autre partie tout le temps donnera aux gens une sensation complètement différente que de parler sans établir de contact visuel, ce qui affectera également la compréhension du contenu de la communication par l'autre partie. Nous avons une capacité extrêmement fine à détecter ces expressions et mouvements subtils pendant la communication et à les utiliser pour développer une compréhension de haut niveau de l'intention, du niveau de confort ou de la compréhension de l'interlocuteur. Par conséquent, développer des avatars conversationnels très réalistes qui capturent ces subtilités est essentiel pour l’interaction.
À cette fin, des chercheurs de Meta et de l'Université de Californie ont proposé une méthode pour générer des humains virtuels réalistes basés sur l'audio vocal d'une conversation entre deux personnes. Il peut synthétiser une variété de gestes à haute fréquence et de mouvements faciaux expressifs étroitement synchronisés avec la parole. Pour le corps et la main, ils exploitent les avantages d’une approche autorégressive basée sur le VQ et d’un modèle de diffusion. Pour les visages, ils utilisent un modèle de diffusion conditionné par l’audio. Les mouvements prédits du visage, du corps et des mains sont ensuite transformés en humains virtuels réalistes. Nous démontrons que l'ajout de conditions de gestes guidés au modèle de diffusion peut générer des gestes conversationnels plus diversifiés et raisonnables que les travaux précédents.

- Adresse papier : https://huggingface.co/papers/2401.01885
- Adresse du projet : https://people.eecs.berkeley.edu/~evonne_ng / projets/audio2photoreal/
Les chercheurs affirment qu'ils sont la première équipe à étudier comment générer des mouvements réalistes du visage, du corps et des mains pour les conversations interpersonnelles. Par rapport aux études précédentes, les chercheurs ont synthétisé des actions plus réalistes et plus diversifiées basées sur des méthodes VQ et de diffusion.
Aperçu de la méthode
Les chercheurs ont extrait des codes d'expression latents à partir de données multi-vues enregistrées pour représenter les visages, et ont utilisé les angles articulaires du squelette cinématique pour représenter les postures du corps. Comme le montre la figure 3, ce système se compose de deux modèles génératifs, qui génèrent des codes d'expression et des séquences de postures corporelles lors de la saisie audio d'une conversation à deux. Le code d'expression et les séquences de poses corporelles peuvent ensuite être rendus image par image à l'aide du Neural Avatar Renderer, qui peut générer un avatar entièrement texturé avec le visage, le corps et les mains à partir d'une vue de caméra donnée.
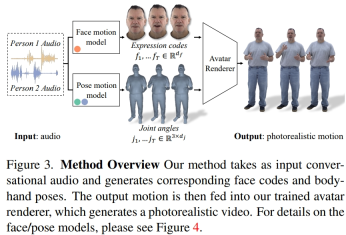
Il est à noter que les dynamiques du corps et du visage sont très différentes. Premièrement, les visages sont fortement corrélés à l’audio d’entrée, en particulier aux mouvements des lèvres, tandis que les corps sont faiblement corrélés à la parole. Cela se traduit par une diversité plus complexe de gestes corporels dans une entrée vocale donnée. Deuxièmement, puisque les visages et les corps sont représentés dans deux espaces différents, ils suivent chacun des dynamiques temporelles différentes. Les chercheurs ont donc utilisé deux modèles de mouvements indépendants pour simuler le visage et le corps. De cette façon, le modèle facial peut « se concentrer » sur les détails du visage qui sont cohérents avec la parole, tandis que le modèle corporel peut se concentrer davantage sur la génération de mouvements corporels diversifiés mais raisonnables.
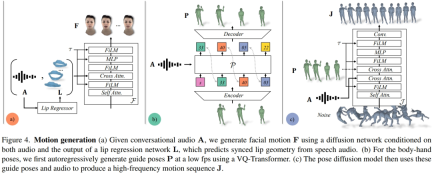
Le modèle de mouvement du visage est un modèle de diffusion conditionné sur l'audio d'entrée et les sommets des lèvres générés par un régresseur de lèvres pré-entraîné (Figure 4a). Pour le modèle de mouvement des membres, les chercheurs ont constaté que le mouvement généré par le modèle de diffusion pure, conditionné uniquement par l'audio, manquait de diversité et n'était pas suffisamment coordonné dans la séquence temporelle. Cependant, la qualité s’est améliorée lorsque les chercheurs ont conditionné différentes postures de guidage. Par conséquent, ils ont divisé le modèle de mouvement corporel en deux parties : d'abord, le conditionneur audio autorégressif prédit des poses de guidage grossières à 1 fp (Fig. 4b), puis le modèle de diffusion utilise ces poses de guidage grossières pour remplir des poses à grain fin et élevé. mouvements de fréquence (Fig. 4c). Consultez l'article original pour plus de détails sur les paramètres de la méthode.
Expériences et résultats
Les chercheurs ont évalué quantitativement la capacité d'Audio2Photoreal à générer efficacement des actions de dialogue réalistes basées sur des données réelles. Des évaluations perceptuelles ont également été menées pour corroborer les résultats quantitatifs et mesurer la pertinence d'Audio2Photoreal à générer des gestes dans un contexte conversationnel donné. Les résultats expérimentaux ont montré que les évaluateurs étaient plus sensibles aux gestes subtils lorsque les gestes étaient présentés sur un avatar réaliste plutôt que sur un maillage 3D.
Les chercheurs ont comparé les résultats générés par cette méthode avec trois méthodes de base : KNN, SHOW et LDA basées sur des séquences de mouvements aléatoires dans l'ensemble d'entraînement. Des expériences d'ablation ont été menées pour tester l'efficacité de chaque composant d'Audio2Photoreal sans audio ni gestes guidés, sans gestes guidés mais basés sur l'audio, et sans audio mais basés sur des gestes guidés.
Résultats quantitatifs
Le tableau 1 montre que par rapport aux études précédentes, notre méthode a le score FD le plus bas lors de la génération de mouvement avec la plus grande diversité. Bien que le hasard ait une bonne diversité qui correspond à GT, les segments aléatoires ne correspondent pas à la dynamique de conversation correspondante, ce qui entraîne un FD_g élevé.

La figure 5 montre la diversité des poses de guidage générées par notre méthode. L'échantillonnage P par transformateur basé sur VQ permet la génération de gestes très différents avec la même entrée audio.

Comme le montre la figure 6, le modèle de diffusion apprendra à générer des actions dynamiques, où les actions correspondront mieux à l'audio de la conversation.

La figure 7 montre que le mouvement généré par LDA manque de vitalité et a moins de mouvement. En revanche, les changements de mouvement synthétisés par cette méthode sont plus cohérents avec la situation réelle.
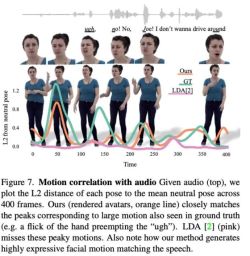
De plus, les chercheurs ont également analysé la précision de cette méthode pour générer des mouvements des lèvres. Comme le montrent les statistiques du tableau 2, Audio2Photoreal surpasse considérablement la méthode de base SHOW, ainsi que les performances après suppression du régresseur labial pré-entraîné dans les expériences d'ablation. Cette conception améliore la synchronisation des formes de la bouche lorsque vous parlez, évite efficacement les mouvements aléatoires d'ouverture et de fermeture de la bouche lorsque vous ne parlez pas, permet au modèle d'obtenir une meilleure reconstruction du mouvement des lèvres et réduit en même temps l'erreur des sommets du maillage facial (grille L2). .

Évaluation qualitative
La cohérence des gestes dans les conversations étant difficile à quantifier, les chercheurs ont utilisé des méthodes d'évaluation qualitatives. Ils ont effectué deux séries de tests A/B sur MTurk. Plus précisément, ils ont demandé aux évaluateurs de regarder les résultats générés par notre méthode et la méthode de base ou la paire vidéo de notre méthode et de la scène réelle, et leur ont demandé d'évaluer quelle vidéo dans laquelle le mouvement semblait le plus raisonnable.
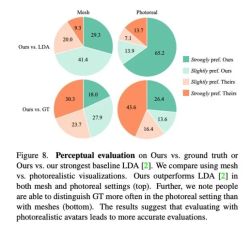
Comme le montre la figure 8, cette méthode est nettement meilleure que la méthode de base précédente LDA, et environ 70 % des évaluateurs préfèrent Audio2Photoreal en termes de grille et de réalisme.
Comme le montre le graphique du haut de la figure 8, par rapport à LDA, l'évaluation de cette méthode par les évaluateurs est passée de « légèrement préfère » à « fortement apprécié ». Par rapport à la situation réelle, la même évaluation est présentée. Pourtant, les évaluateurs ont préféré le produit réel à Audio2Photoreal en termes de réalisme.
Pour plus de détails techniques, veuillez lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AM
Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AMExploiter la puissance de l'IA sur disvise: construire une CLI de chatbot personnelle Dans un passé récent, le concept d'un assistant d'IA personnel semblait être une science-fiction. Imaginez Alex, un passionné de technologie, rêvant d'un compagnon d'IA intelligent et local - celui qui ne dépend pas
 L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AM
L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AMLeur lancement inaugural de l'AI4MH a eu lieu le 15 avril 2025, et le Dr Tom Insel, M.D., célèbre psychiatre et neuroscientifique, a été le conférencier de lancement. Le Dr Insel est réputé pour son travail exceptionnel dans la recherche en santé mentale et la techno
 La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM
La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM"Nous voulons nous assurer que la WNBA reste un espace où tout le monde, les joueurs, les fans et les partenaires d'entreprise, se sentent en sécurité, appréciés et autonomes", a déclaré Engelbert, abordé ce qui est devenu l'un des défis les plus dommageables des sports féminins. L'anno
 Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excelle comme un langage de programmation, en particulier dans la science des données et l'IA générative. La manipulation efficace des données (stockage, gestion et accès) est cruciale lorsqu'il s'agit de grands ensembles de données. Nous avons déjà couvert les nombres et ST
 Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AM
Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AMAvant de plonger, une mise en garde importante: les performances de l'IA sont non déterministes et très usagées. En termes plus simples, votre kilométrage peut varier. Ne prenez pas cet article (ou aucun autre) article comme le dernier mot - au lieu, testez ces modèles sur votre propre scénario
 Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AM
Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AMConstruire un portefeuille AI / ML hors concours: un guide pour les débutants et les professionnels La création d'un portefeuille convaincant est cruciale pour sécuriser les rôles dans l'intelligence artificielle (IA) et l'apprentissage automatique (ML). Ce guide fournit des conseils pour construire un portefeuille
 Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AM
Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AMLe résultat? L'épuisement professionnel, l'inefficacité et un écart d'élargissement entre la détection et l'action. Rien de tout cela ne devrait être un choc pour quiconque travaille en cybersécurité. La promesse d'une IA agentique est devenue un tournant potentiel, cependant. Cette nouvelle classe
 Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AM
Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AMImpact immédiat contre partenariat à long terme? Il y a deux semaines, Openai s'est avancé avec une puissante offre à court terme, accordant aux étudiants des États-Unis et canadiens d'accès gratuit à Chatgpt Plus jusqu'à la fin mai 2025. Cet outil comprend GPT - 4O, un A


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

