
Maison >Périphériques technologiques >IA >L'Université Tsinghua et l'Université du Zhejiang mènent l'explosion des modèles visuels open source, et GPT-4V, LLaVA, CogAgent et d'autres plateformes apportent des changements révolutionnaires
L'Université Tsinghua et l'Université du Zhejiang mènent l'explosion des modèles visuels open source, et GPT-4V, LLaVA, CogAgent et d'autres plateformes apportent des changements révolutionnaires

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-04 08:10:581450parcourir
Actuellement, GPT-4 Vision montre des capacités étonnantes en matière de compréhension du langage et de traitement visuel.
Cependant, pour ceux qui recherchent une alternative rentable sans compromettre les performances, les options open source sont une option au potentiel illimité.
Youssef Hosni est un développeur étranger qui nous propose trois alternatives open source avec une accessibilité absolument garantie pour remplacer GPT-4V.
Les trois modèles de langage visuel open source LLaVa, CogAgent et BakLLaVA ont un grand potentiel dans le domaine du traitement visuel et méritent notre compréhension approfondie. La recherche et le développement de ces modèles peuvent nous fournir des solutions de traitement visuel plus efficaces et plus précises. En utilisant ces modèles, nous pouvons améliorer la précision et l'efficacité de tâches telles que la reconnaissance d'images, la détection de cibles et la génération d'images, apportant
 images
images
LLaVa
LLaVa est une recherche et une application multimodale dans le domaine de traitement visuel Grand modèle, développé par une collaboration entre des chercheurs de l'Université du Wisconsin-Madison, Microsoft Research et l'Université de Columbia. La version initiale est sortie en avril.
Il combine un encodeur visuel et Vicuna (pour une compréhension générale visuelle et linguistique) pour démontrer de très bonnes capacités de chat.
 Photos
Photos
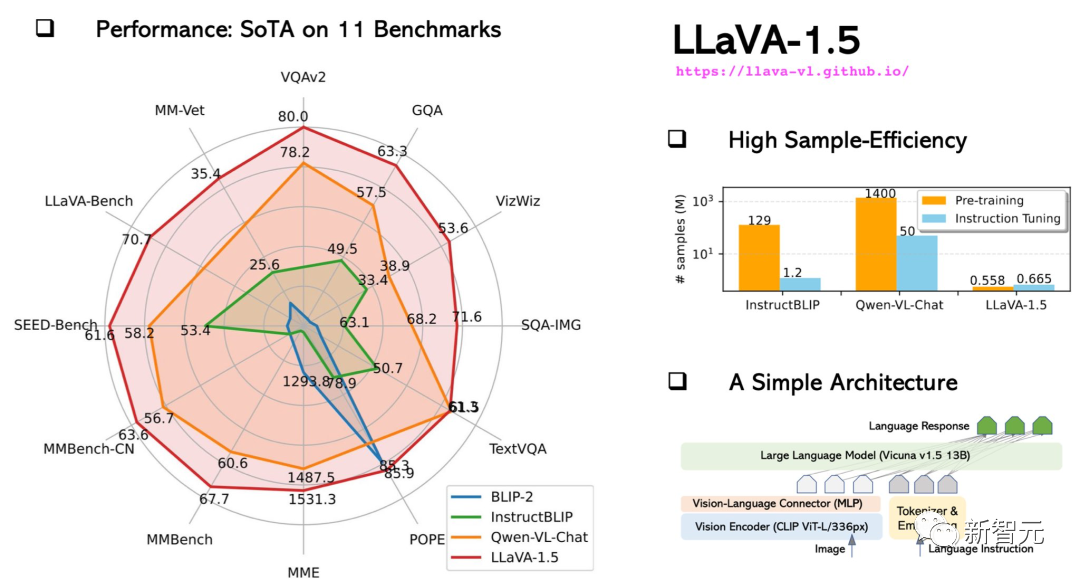
En octobre, le LLaVA-1.5 amélioré était proche du GPT-4 multimodal en termes de performances et a obtenu des résultats de pointe (SOTA) sur l'ensemble de données Science QA.
 Photos
Photos
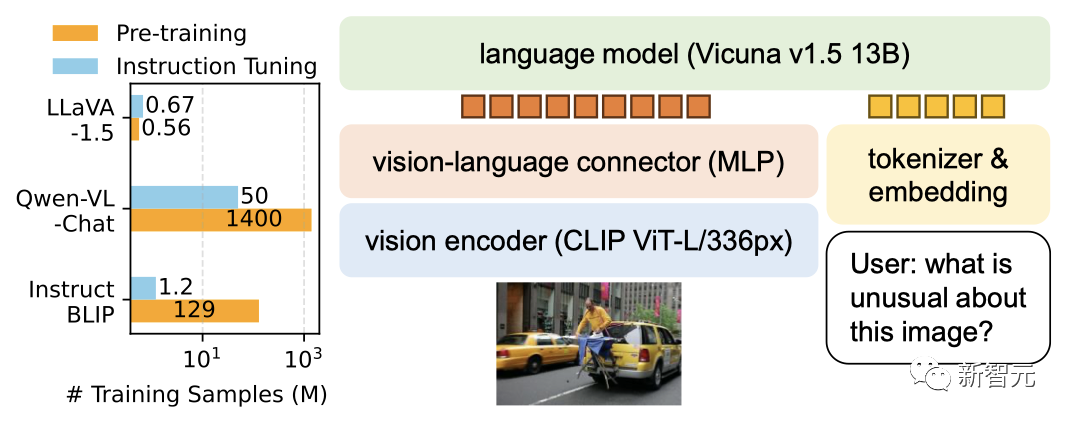
La formation du modèle 13B peut être complétée en 1 journée avec seulement 8 A100.
 Photos
Photos
Comme vous pouvez le voir, LLaVA peut traiter toutes sortes de questions, et les réponses générées sont à la fois complètes et logiques.
LLaVA démontre des capacités multimodales proches du niveau GPT-4, avec un score relatif GPT-4 de 85% en termes de chat visuel.
En termes de questions et réponses de raisonnement, LLaVA a même atteint le nouveau SoTA - 92,53%, battant la chaîne de pensée multimodale.
 Images
Images
En termes de raisonnement visuel, ses performances sont très accrocheuses.
 Photos
Photos
 Photos
Photos
Question : "S'il y a des erreurs factuelles, veuillez les signaler. Sinon, dites-moi, que se passe-t-il dans le désert ?"
LLaVA ne peut pas répondre complètement correctement.
Le LLaVA-1.5 amélioré a donné la réponse parfaite : "Il n'y a pas de désert du tout sur la photo, il y a des palmiers, des plages, des toits de villes et un grand plan d'eau." , LLaVA-1.5 est OK Extrayez les informations du graphique et répondez-y dans le format requis, par exemple en les produisant au format JSON.
 Images
Images
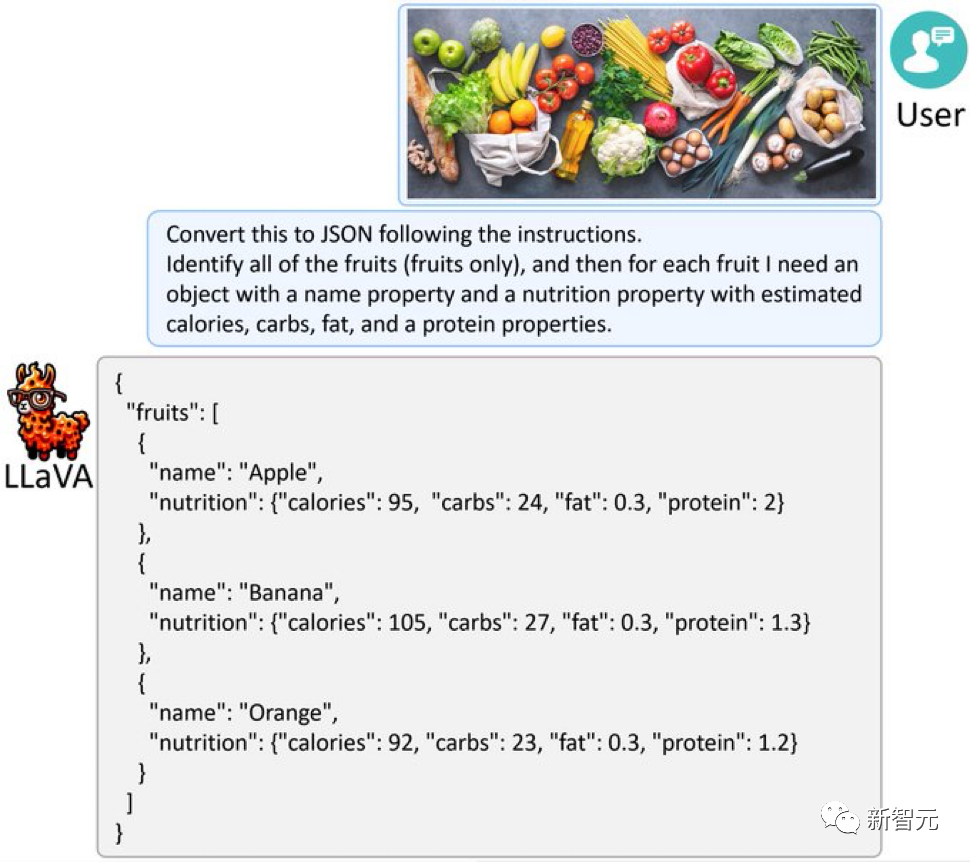
Donnez à LLaVA-1.5 une image pleine de fruits et légumes, et il peut également convertir l'image en JSON comme GPT-4V.
 Photo
Photo
Que signifie l'image ci-dessous ?
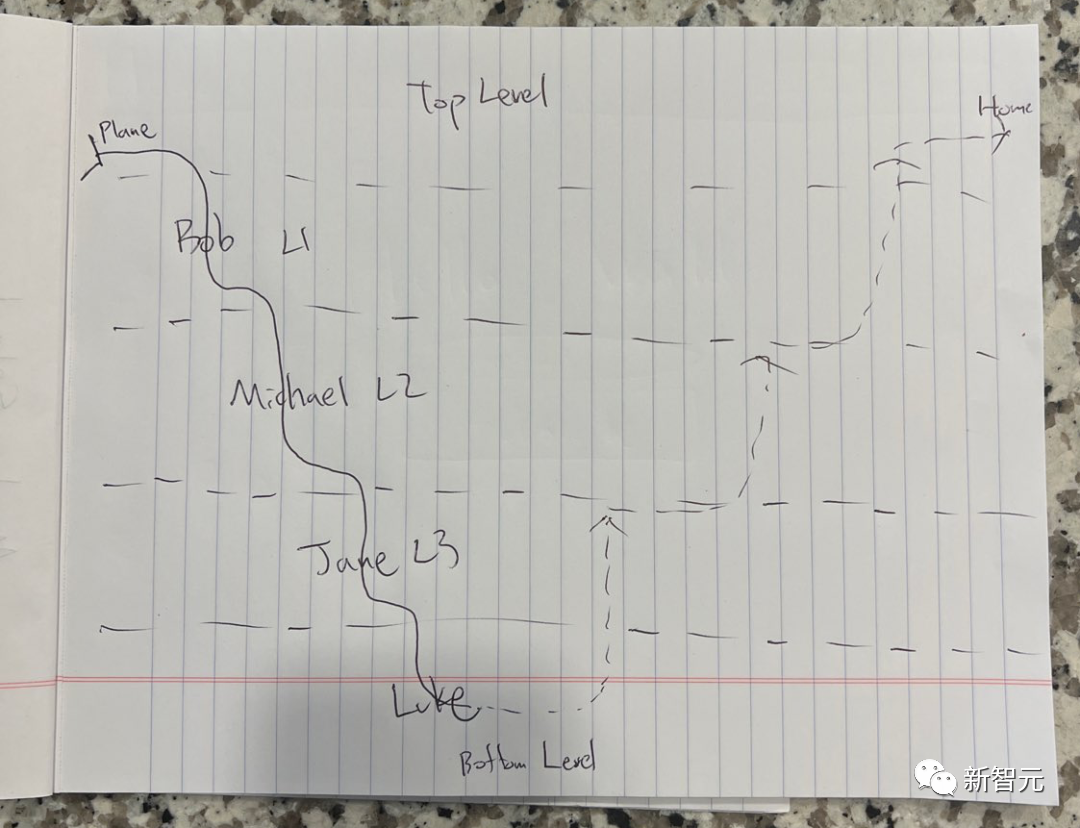 Photo
Photo
Il s'agit d'un croquis simplifié basé sur "Inception" de Nolan Afin d'augmenter la difficulté, le nom du personnage a été changé en pseudonyme.
LLaVA-1.5 a répondu de manière surprenante : "Ceci est une image du film "Inception". Elle montre différents niveaux dans le monde des rêves, et chaque niveau est représenté par une ligne. L'image est écrite sur un morceau de papier, Le papier est placé sur un comptoir. "
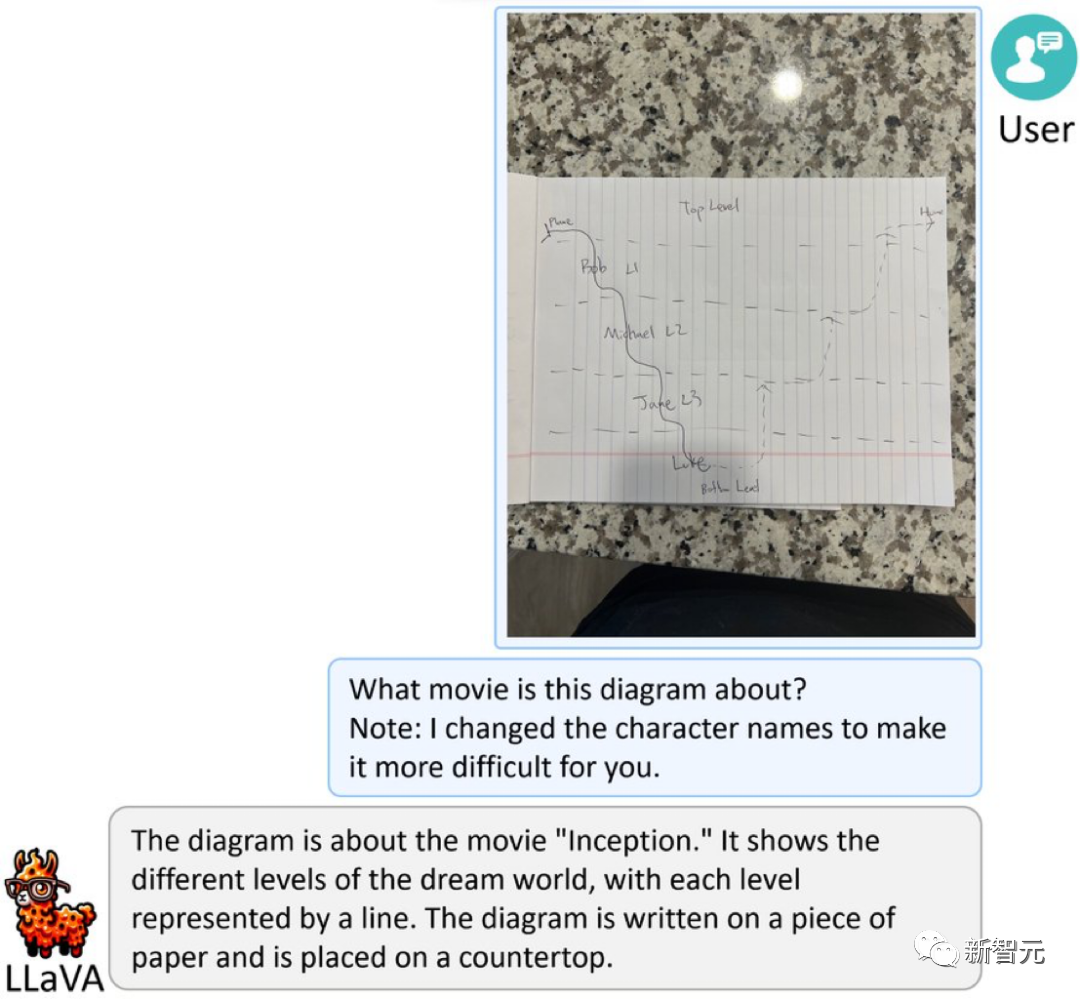 Photos
Photos
Envoyez une photo de nourriture directement à LLaVA-1.5, et il générera rapidement une recette pour vous.
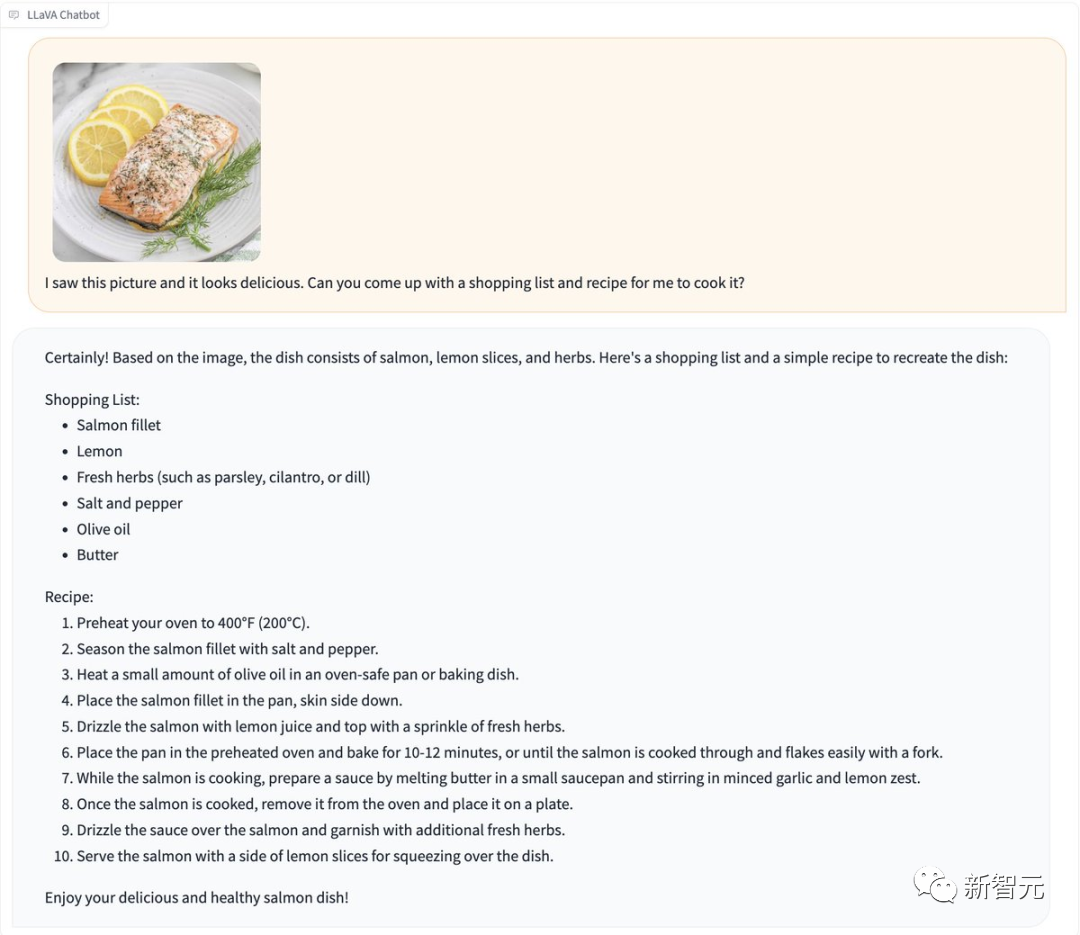 Photos
Photos
De plus, LLaVA-1.5 peut reconnaître les codes de vérification sans « jailbreak ».
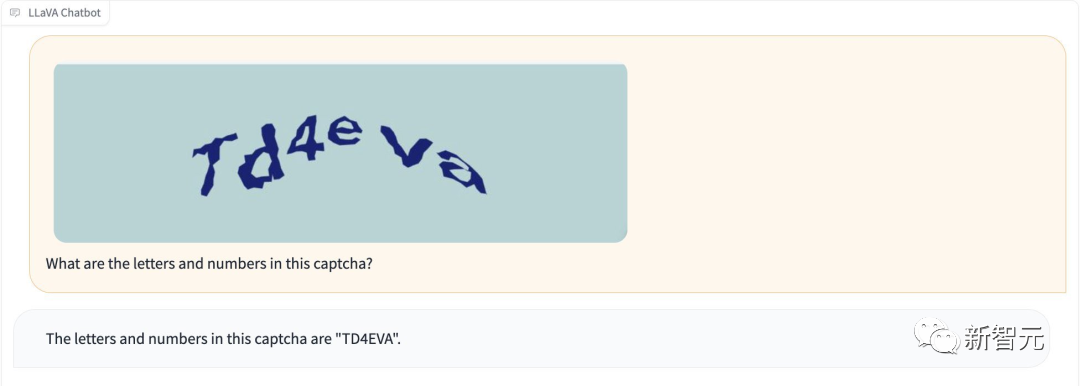 Image
Image
Il peut également détecter quel type de pièce se trouve sur l'image.
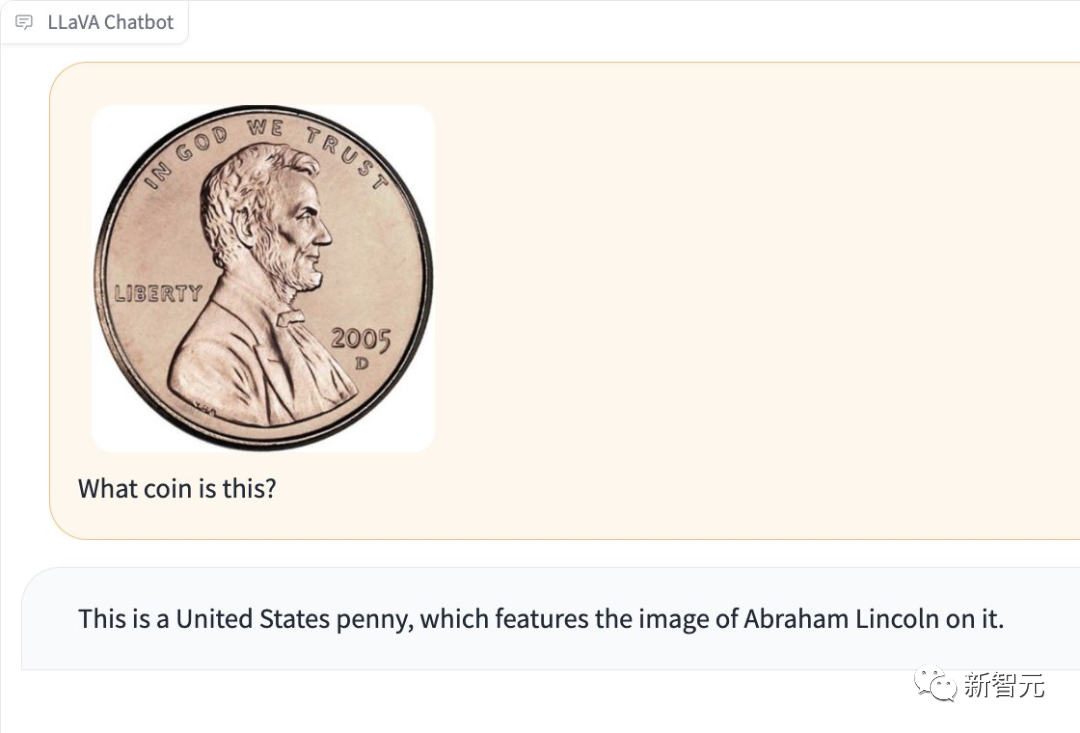 Photos
Photos
Ce qui est particulièrement impressionnant, c'est que LLaVA-1.5 peut également vous indiquer la race du chien sur la photo.
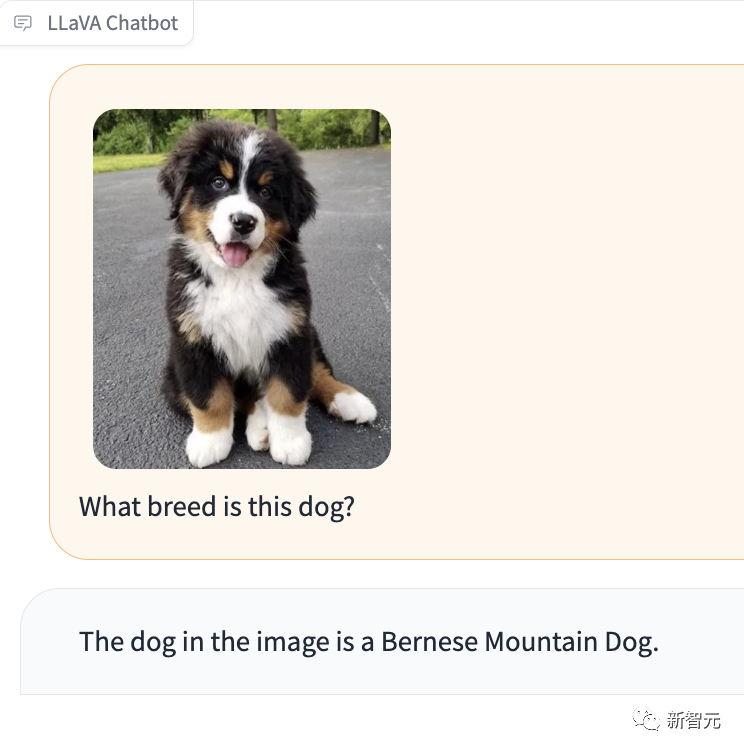 Photo
Photo
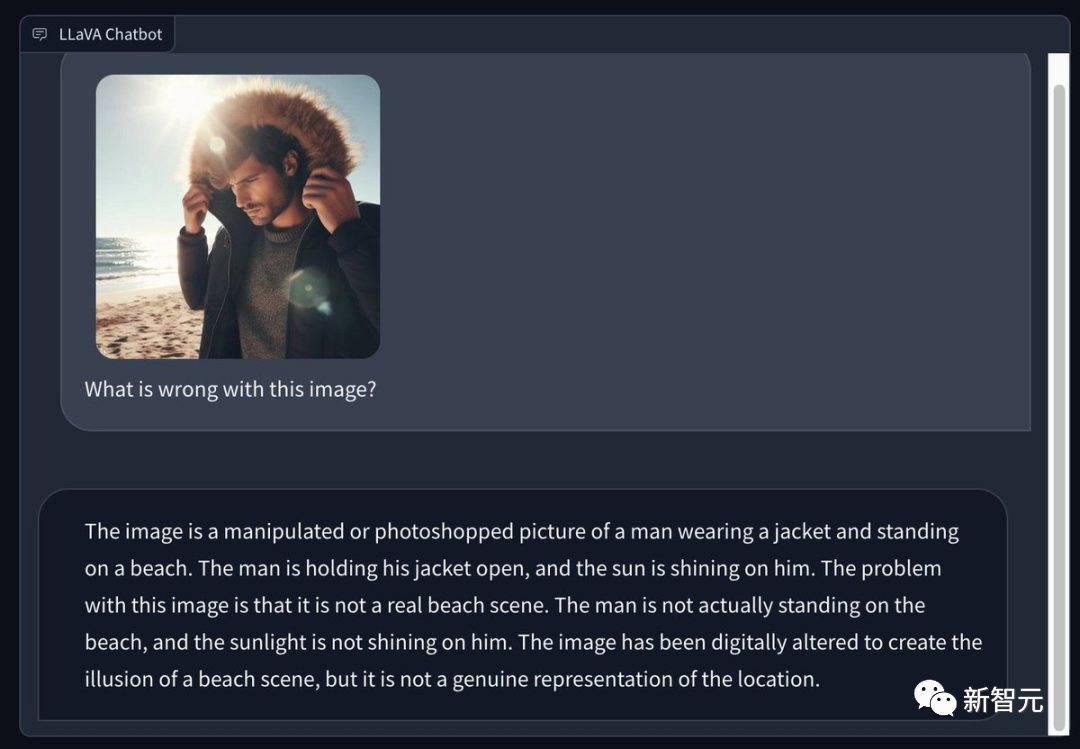
Certains internautes ont utilisé Bing pour générer une photo d'un homme portant un manteau d'hiver sur une plage d'été ensoleillée et ont demandé à LLaVA 1.5 de signaler les problèmes sur la photo. Son œil est très perçant -
Il s'agit d'une photo retouchée ou retouchée, sur laquelle un homme porte une veste et se tient debout sur la plage. L'homme ouvrit son manteau et le soleil brillait sur lui. Le problème avec cette image est qu’il ne s’agit pas d’une véritable scène de plage. L’homme n’était pas réellement debout sur la plage et le soleil ne brillait pas sur lui. Cette image a été retouchée pour créer l'illusion d'une scène de plage, mais elle ne représente pas vraiment la scène.
 Picture
Picture
Reconnaissance OCR, les performances de LLaVA sont également très puissantes.
 Pictures
Pictures
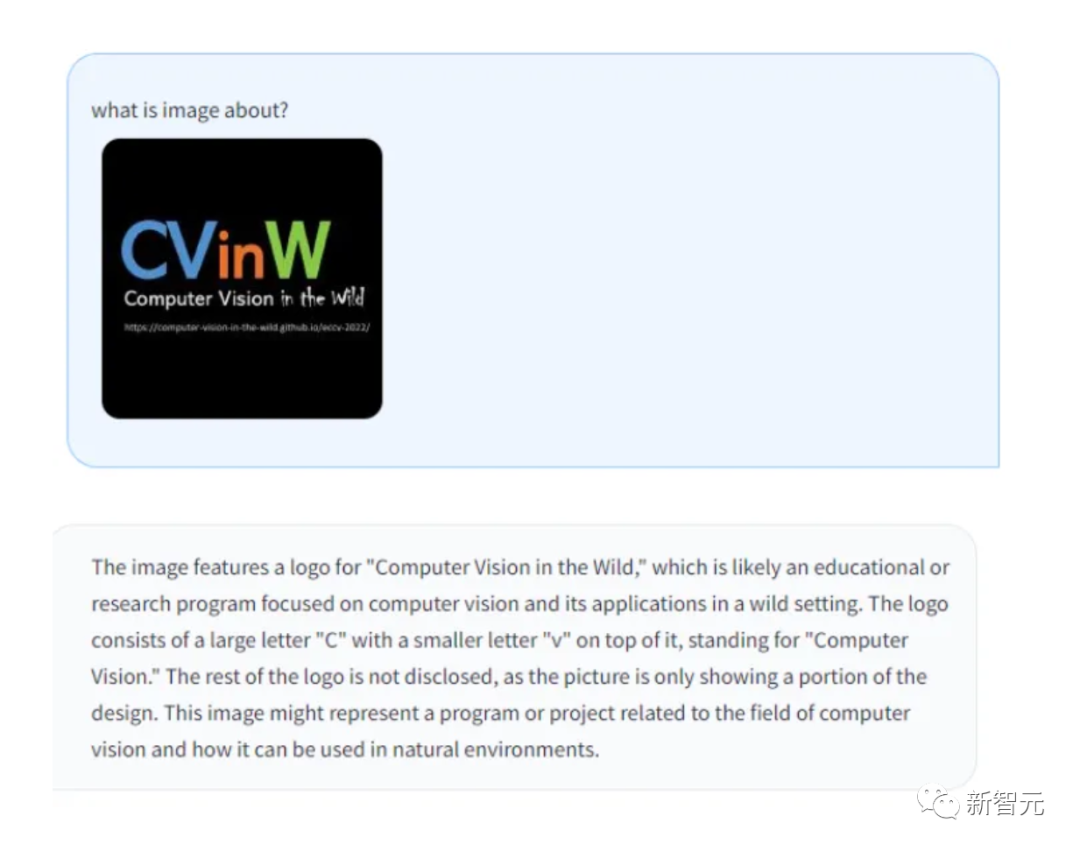 Pictures
Pictures
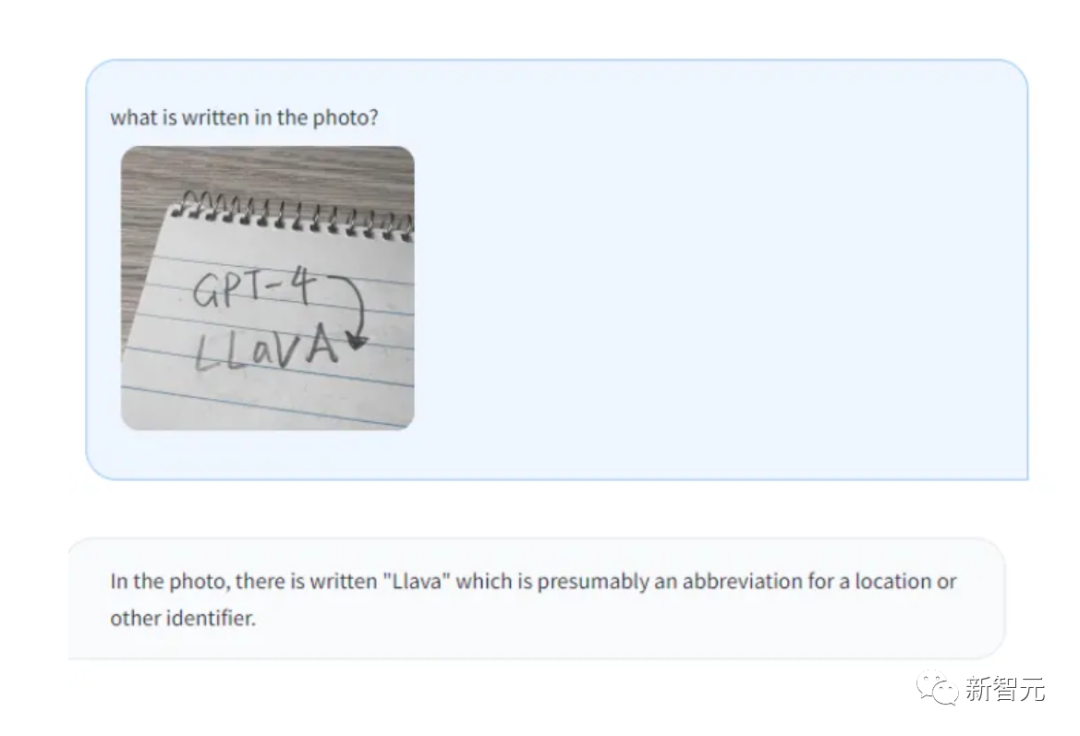 Pictures
Pictures
CogAgent
CogAgent est un modèle de langage visuel open source amélioré sur la base de CogVLM, un chercheur de l'Université Tsinghua.
CogAgent-18B possède 11 milliards de paramètres visuels et 7 milliards de paramètres linguistiques.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2312.08914.pdf
CogAgent-18B atteint des performances générales de pointe sur 9 benchmarks multimodaux classiques (dont VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet et POPE).
Il surpasse considérablement les modèles existants sur les ensembles de données de manipulation d'interface graphique tels que AITW et Mind2Web.
En plus de toutes les fonctions existantes de CogVLM (dialogue multi-tours visualisé, mise à la terre visuelle), CogAgent.NET fournit également plus de fonctions :
1. Prise en charge de la saisie visuelle à plus haute résolution et des réponses aux questions de dialogue. Prend en charge l'entrée d'image ultra haute résolution de 1120 x 1120.
2. Il a la capacité de visualiser les agents et peut renvoyer le plan, la prochaine action et l'opération spécifique avec les coordonnées pour n'importe quelle tâche donnée sur n'importe quelle capture d'écran de l'interface utilisateur graphique.
3. La fonction de réponse aux questions liées à l'interface graphique a été améliorée pour lui permettre de gérer les problèmes liés aux captures d'écran de n'importe quelle interface graphique telle que des pages Web, des applications PC, des applications mobiles, etc.
4. Capacités améliorées pour les tâches liées à l'OCR en améliorant la pré-formation et le réglage fin.
GUI Agent
En utilisant CogAgent, cela peut nous aider à trouver les meilleurs articles du CVPR23 étape par étape.
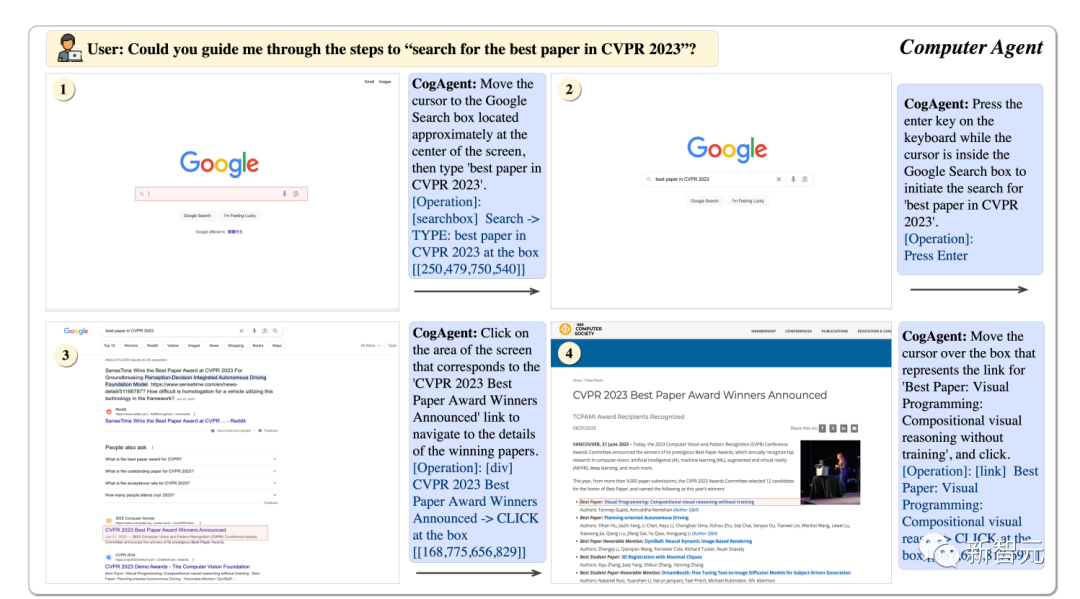 Photos
Photos
peuvent nous aider à transformer l'écran du téléphone en mode lumineux.
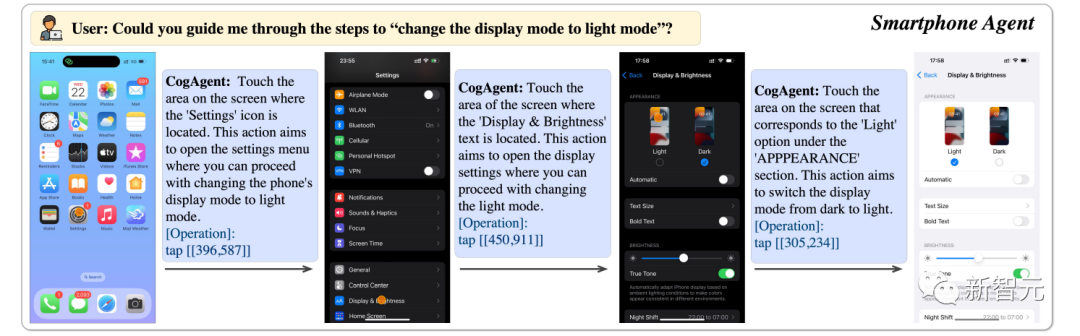 Photos
Photos
Combien de likes et de retweets ce tweet a et pourquoi il est si populaire, CogAgent peut l'analyser, et il peut même répondre par "Brilliant".
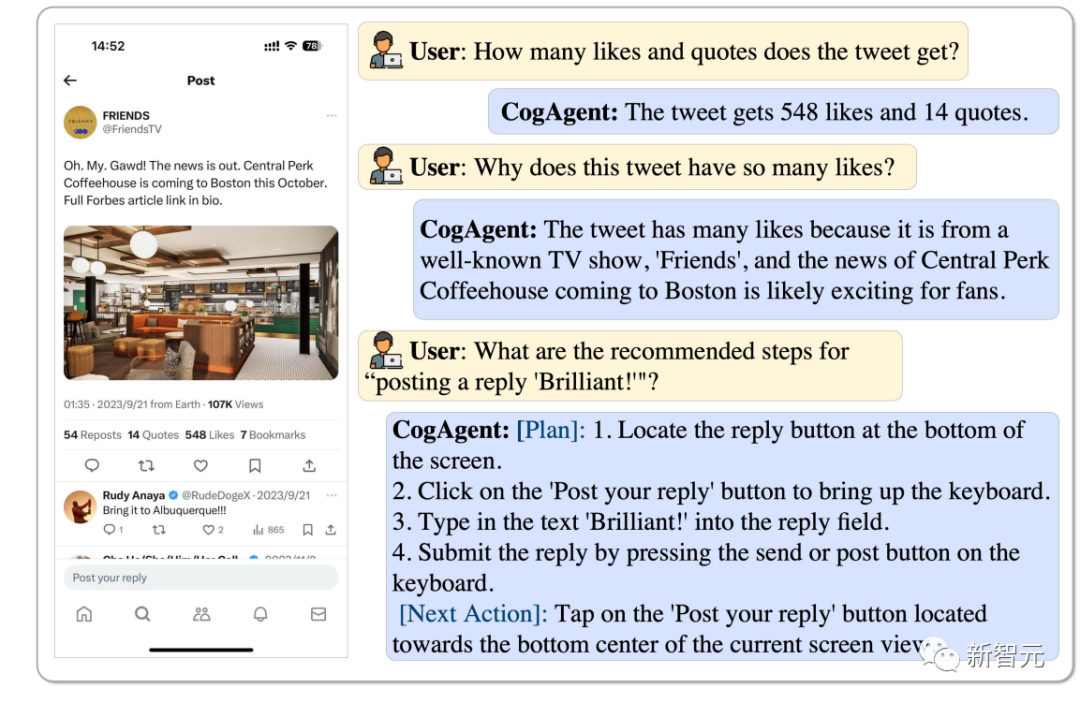 Photos
Photos
Comment choisir l'itinéraire le plus rapide de l'Université de Floride à Hollywood ? Si vous commencez à 8h du matin, comment estimez-vous combien de temps cela prendra ? CogAgent peut répondre à tout.
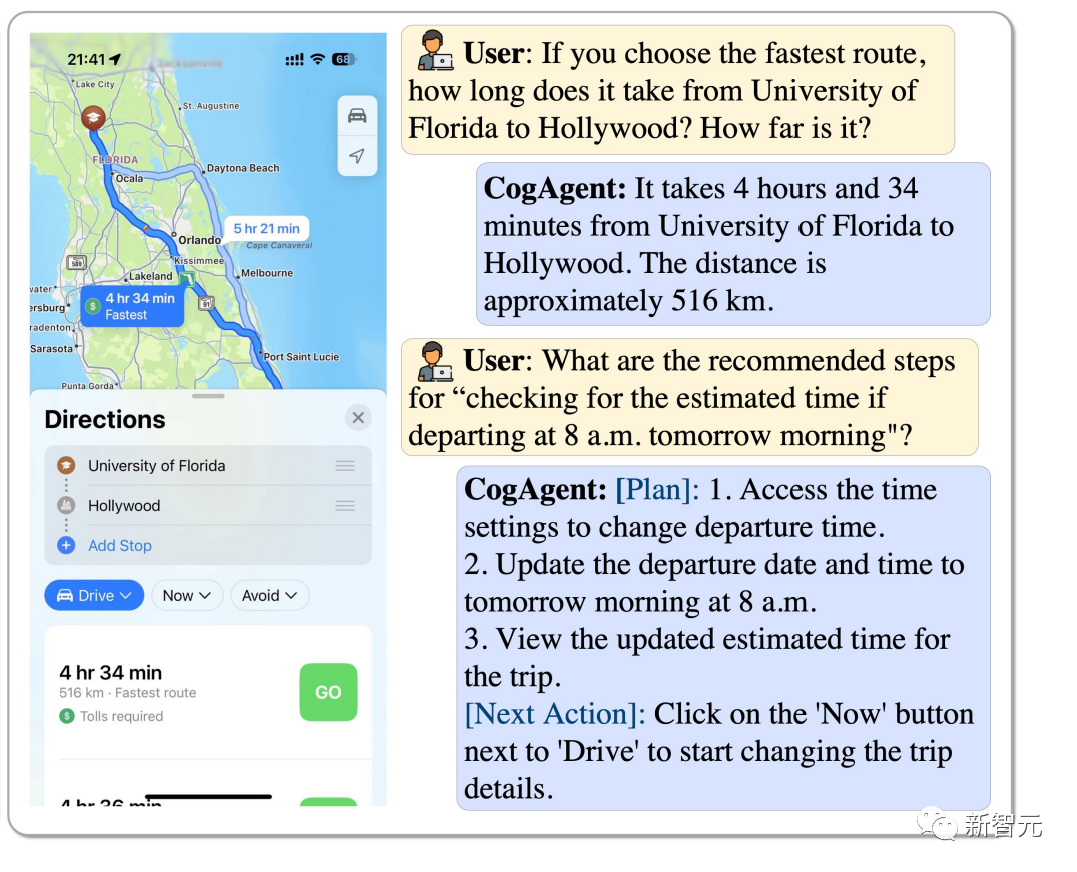 Photos
Photos
Vous pouvez définir un thème spécifique et laisser CogAgent envoyer des e-mails à la boîte aux lettres spécifiée.
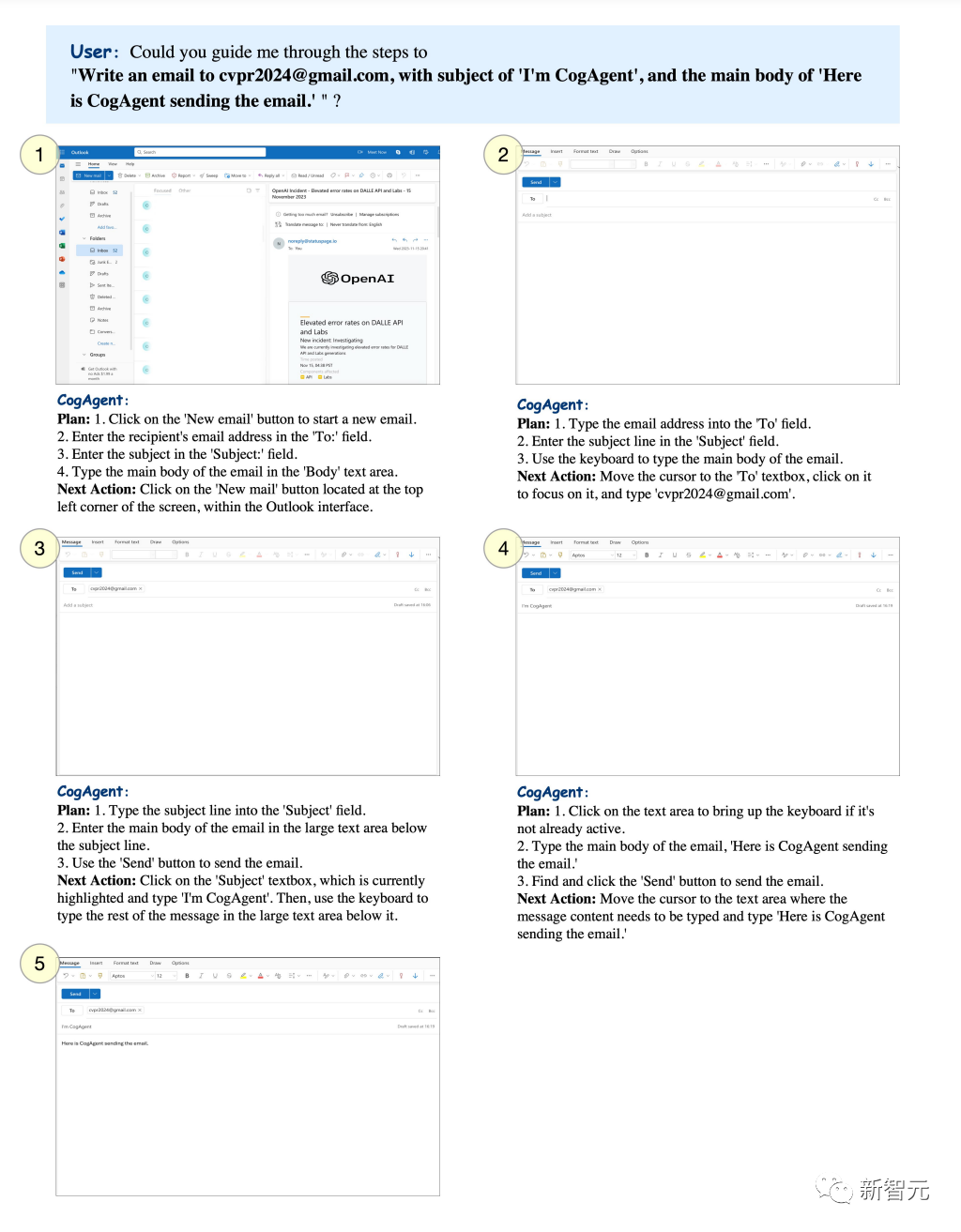 Photos
Photos
Si vous souhaitez écouter la chanson "You raise me up", CogAgent peut lister les étapes étape par étape.
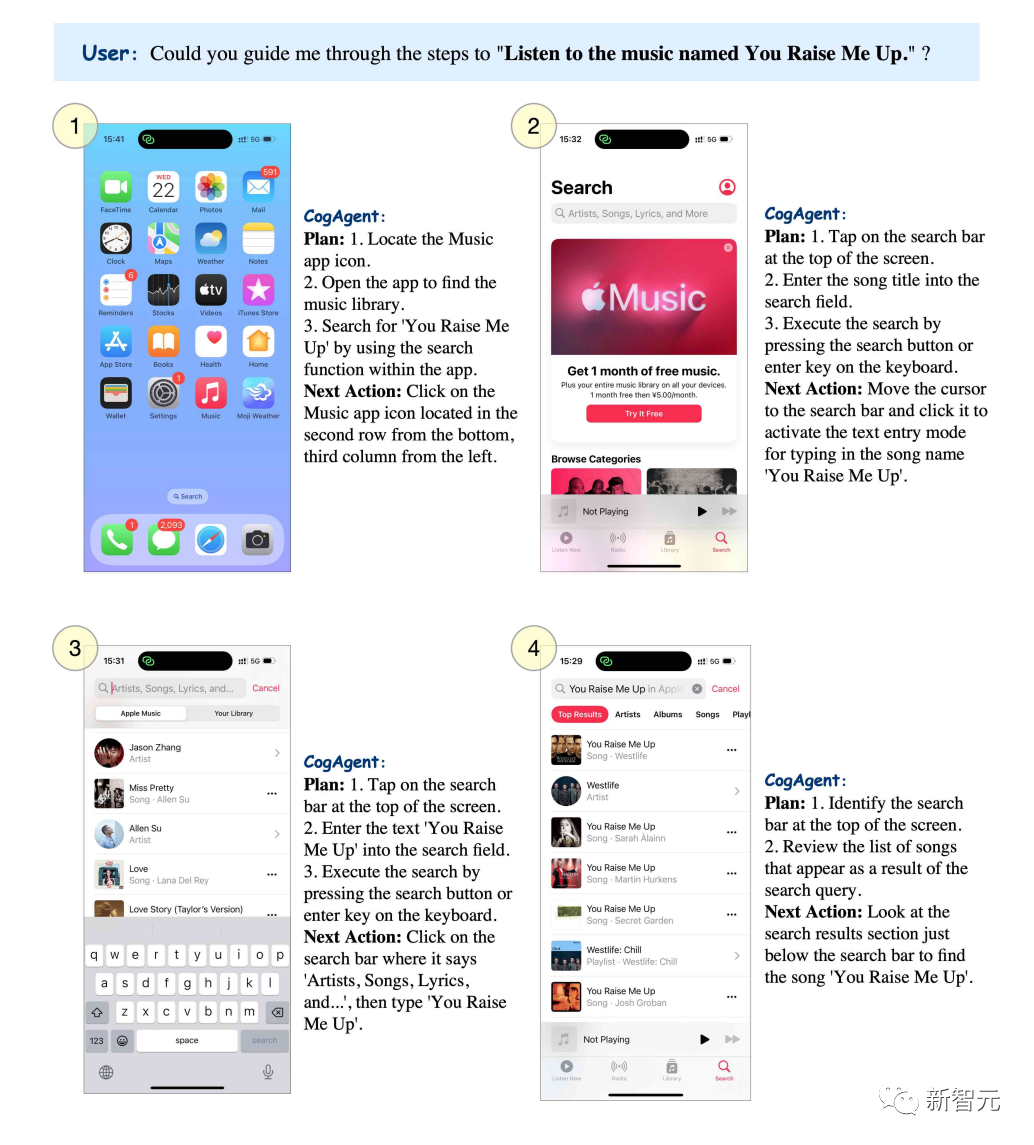 Photos
Photos
CogAgent peut décrire avec précision les scènes de "Genshin Impact" et peut également vous guider sur la façon de vous rendre au point de téléportation.
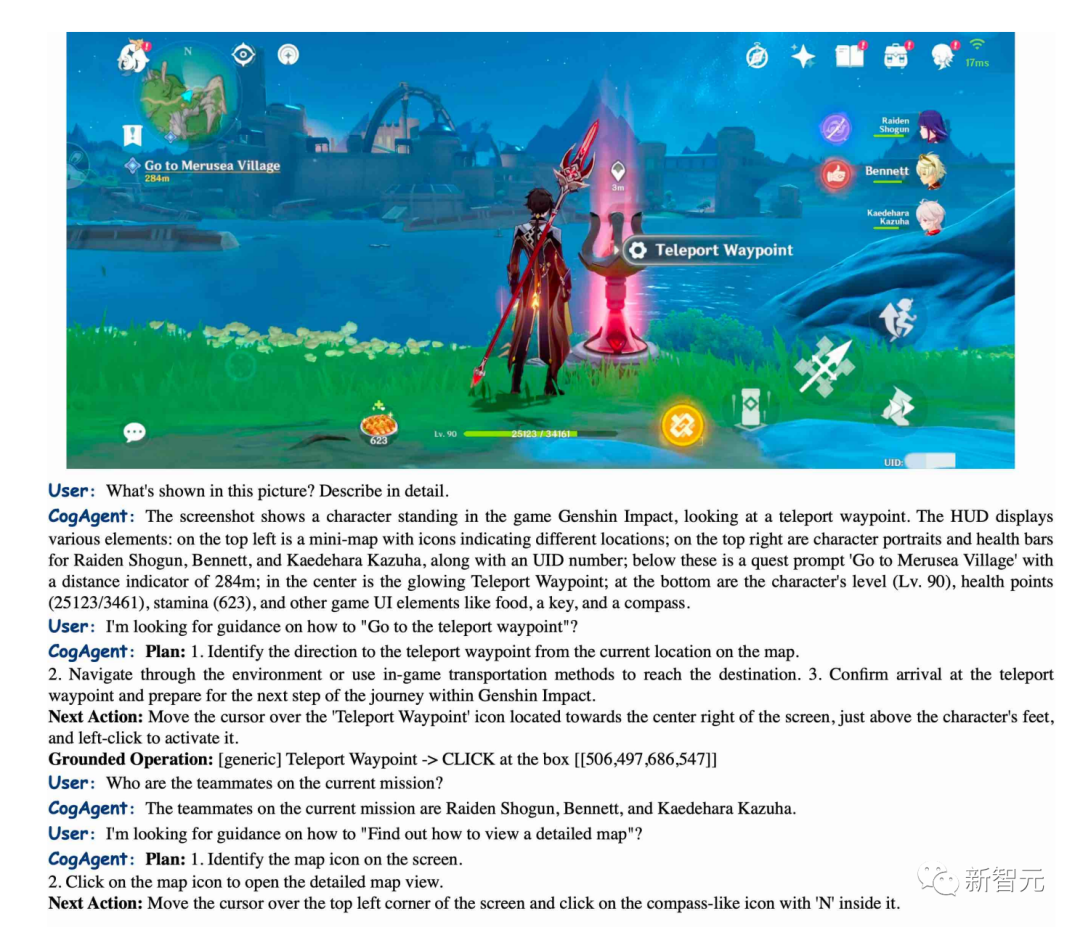 Pictures
Pictures
BakLLaVA
BakLLaVA1 est un modèle de base Mistral 7B amélioré avec l'architecture LLaVA 1.5.
Dans la première version, le modèle de base Mistral 7B a surpassé le Llama 2 13B dans plusieurs benchmarks.
Dans leur dépôt, vous pouvez exécuter BakLLaVA-1. La page est constamment mise à jour pour faciliter la mise au point et le raisonnement. (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1 est entièrement open source, mais a été formé sur certaines données, y compris le corpus de LLaVA, et n'est donc pas autorisé à un usage commercial.
BakLLaVA 2 utilise un ensemble de données plus vaste et une architecture mise à jour pour surpasser la méthode LLaVa actuelle. BakLLaVA élimine les limitations de BakLLaVA-1 et peut être utilisé commercialement.
Référence :
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Java est-il open source ?
- 4 projets ChatGPT étonnants sont open source !
- L'Université du Wisconsin-Madison et d'autres ont publié conjointement un article ! Le dernier grand modèle multimodal LLaVA est sorti et son niveau est proche de GPT-4
- Lava Alpaca LLaVA est là : comme GPT-4, vous pouvez afficher des photos et discuter, aucun code d'invitation n'est requis et vous pouvez jouer en ligne
- Même les gourdes n'arrivent pas à le comprendre, GPT-4V, qui explique League of Legends, fait face à des défis d'hallucination