
Maison >Périphériques technologiques >IA >Lava Alpaca LLaVA est là : comme GPT-4, vous pouvez afficher des photos et discuter, aucun code d'invitation n'est requis et vous pouvez jouer en ligne
Lava Alpaca LLaVA est là : comme GPT-4, vous pouvez afficher des photos et discuter, aucun code d'invitation n'est requis et vous pouvez jouer en ligne

- PHPzavant
- 2023-05-12 14:28:141308parcourir

Quand les capacités de reconnaissance d'images de GPT-4 seront-elles en ligne ? Cette question n'a toujours pas de réponse.
Mais la communauté des chercheurs ne peut plus attendre et s'est lancée dans le bricolage. Le plus populaire est un projet appelé MiniGPT-4. MiniGPT-4 démontre de nombreuses fonctionnalités similaires à GPT-4, telles que la génération de descriptions d'images détaillées et la création de sites Web à partir de brouillons manuscrits. De plus, les auteurs ont observé d'autres capacités émergentes de MiniGPT-4, notamment la création d'histoires et de poèmes basés sur des images données, la fourniture de solutions aux problèmes montrés dans les images, l'enseignement aux utilisateurs sur la façon de cuisiner à partir de photos de plats, etc. Le projet a reçu près de 10 000 étoiles dans les 3 jours suivant son lancement.

Le projet que nous allons présenter aujourd'hui - LLaVA (Large Language and Vision Assistant) est similaire. Il s'agit d'un langage multimodal à grande échelle publié conjointement par des chercheurs de l'Université du Wisconsin-Madison et Microsoft. Recherche et modèle de l'Université de Columbia.

- Lien papier : https://arxiv.org/pdf/2304.08485.pdf
- Lien du projet : https://llava-vl.github.io/
Ce modèle démontre des capacités de compréhension d'images et de textes proches du GPT-4 multimodal : il a obtenu un score relatif de 85,1 % par rapport au GPT-4. Lorsqu'elle est affinée sur Science QA, la synergie de LLaVA et GPT-4 permet d'obtenir un nouveau SoTA avec une précision de 92,53 %.

Voici les résultats des essais du Cœur de la Machine (voir plus de résultats à la fin de l'article) :

Vue d'ensemble papier
Les humains interagissent avec le monde à travers de multiples canaux comme la vision et le langage, car les différents canaux ont leurs propres avantages uniques pour représenter et transmettre certains concepts, et une approche multicanal est propice à une meilleure compréhension du monde. L’une des principales aspirations de l’intelligence artificielle est de développer un assistant universel capable de suivre efficacement des instructions multimodales, telles que des instructions visuelles ou verbales, de satisfaire les intentions humaines et d’accomplir diverses tâches dans des environnements réels.
À cette fin, il y a eu une tendance dans la communauté à développer des modèles visuels basés sur l'amélioration du langage. Ce type de modèle possède de puissantes capacités de compréhension visuelle en monde ouvert, telles que la classification, la détection, la segmentation et les graphiques, ainsi que des capacités de génération visuelle et d'édition visuelle. Chaque tâche est résolue indépendamment par un grand modèle visuel, les besoins de la tâche étant implicitement pris en compte dans la conception du modèle. De plus, le langage est utilisé uniquement pour décrire le contenu de l’image. Bien que cela fasse jouer au langage un rôle important dans la mise en correspondance des signaux visuels avec la sémantique linguistique (un canal commun de communication humaine), cela aboutit à des modèles qui ont souvent des interfaces fixes avec des limitations en termes d'interactivité et d'adaptabilité aux instructions de l'utilisateur.
Les Large Language Models (LLM), en revanche, ont montré que le langage peut jouer un rôle plus large : en tant qu'interface interactive universelle pour des assistants intelligents universels. Dans une interface commune, diverses instructions de tâche peuvent être explicitement exprimées dans un langage et guider l'assistant de réseau neuronal formé de bout en bout pour changer de mode pour accomplir la tâche. Par exemple, le récent succès de ChatGPT et de GPT-4 a démontré la puissance du LLM pour suivre les instructions humaines pour accomplir des tâches et a déclenché une vague de développement du LLM open source. Parmi eux, LLaMA est un LLM open source avec des performances similaires à GPT-3. Alpaca, Vicuna, GPT-4-LLM utilise divers échantillons de traces d'instructions de haute qualité générés par machine pour améliorer les capacités d'alignement du LLM, démontrant des performances impressionnantes par rapport aux LLM propriétaires. Malheureusement, l'entrée dans ces modèles est uniquement du texte.
Dans cet article, les chercheurs proposent une méthode de réglage des instructions visuelles, qui est la première tentative d'étendre le réglage des instructions à un espace multimodal, ouvrant la voie à la construction d'un assistant visuel général.
Plus précisément, cet article apporte les contributions suivantes :
- Données d'instruction multimodale. L’un des principaux défis aujourd’hui est le manque de données sur les commandes visuelles et verbales. Cet article propose une approche de réorganisation des données utilisant ChatGPT/GPT-4 pour convertir les paires image-texte en formats d'instructions appropriés
- grands modèles multimodaux ; Les chercheurs ont développé un grand modèle multimodal (LMM) - LLaVA - en connectant l'encodeur visuel open source et le décodeur de langage LLaMA de CLIP, et ont effectué un réglage fin de bout en bout sur les données d'instructions visuelles-verbales générées. La recherche empirique vérifie l'efficacité de l'utilisation des données générées pour le réglage des instructions LMM et fournit des techniques plus pratiques pour créer des instructions universelles qui suivent les agents visuels. Grâce à GPT-4, nous obtenons des performances de pointe en matière d'assurance qualité scientifique, un ensemble de données d'inférence multimodale.
- Open source. Les chercheurs ont rendu publics les actifs suivants : les données d'instructions multimodales générées, les bibliothèques de codes pour la génération de données et la formation de modèles, les points de contrôle de modèles et les démonstrations de chat visuel.
Architecture LLaVA
L'objectif principal de cet article est d'utiliser efficacement la puissance des modèles LLM et de vision pré-entraînés. L'architecture du réseau est illustrée à la figure 1. Cet article choisit le modèle LLaMA comme LLM fφ(・) car son efficacité a été démontrée dans plusieurs travaux de réglage d'instructions en langage pur open source.

Pour l'image d'entrée X_v, cet article utilise l'encodeur visuel CLIP pré-entraîné ViT-L/14 pour traiter et obtenir la caractéristique visuelle Z_v=g (X_v). Les entités de maillage avant et après la dernière couche de Transformer ont été utilisées dans l'expérience. Cet article utilise une simple couche linéaire pour connecter les caractéristiques de l’image dans l’espace d’incorporation de mots. Plus précisément, après avoir appliqué la matrice de projection entraînable W pour transformer Z_v en jetons d'intégration de langage H_q, qui ont les mêmes dimensions que l'espace d'intégration de mots dans le modèle de langage :
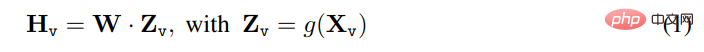
, une séquence de jetons visuels H_v est obtenue. Ce schéma de projection simple est léger, peu coûteux et peut rapidement itérer sur des expériences centrées sur les données. On peut également envisager des schémas plus complexes (mais coûteux) pour concaténer des fonctionnalités d'image et de langage, tels que le mécanisme d'attention croisée gated dans Flamingo et Q-former dans BLIP-2, ou d'autres encodeurs visuels qui fournissent des fonctionnalités au niveau objet, tels que SAM.
Résultats expérimentaux
Chatbot multimodal
Les chercheurs ont développé un exemple de produit de chatbot pour démontrer les capacités de compréhension d'image et de dialogue de LLaVA. Afin d'étudier plus en détail comment LLaVA traite les entrées visuelles et de démontrer sa capacité à traiter les instructions, les chercheurs ont d'abord utilisé des exemples tirés de l'article GPT-4 original, comme le montrent les tableaux 4 et 5. L'invite utilisée doit correspondre au contenu de l'image. À titre de comparaison, cet article cite les invites et les résultats du modèle multimodal GPT-4 tirés de leur article.


Étonnamment, bien que LLaVA ait été formé avec un petit ensemble de données d'instructions multimodales (~ 80 000 images uniques), il démontre sur les deux exemples ci-dessus que les résultats d'inférence sont très similaires à ceux du modèle multimodal. GPT-4. Notez que les deux images sortent du cadre de l'ensemble de données de LLaVA, qui est capable de comprendre la scène et de répondre aux instructions des questions. En revanche, BLIP-2 et OpenFlamingo se concentrent sur la description des images plutôt que sur la réponse appropriée aux instructions de l'utilisateur. D'autres exemples sont présentés dans les figures 3, 4 et 5.



Les résultats de l'évaluation quantitative sont présentés dans le tableau 3.

ScienceQA
ScienceQA contient 21 000 questions multimodales à choix multiples couvrant 3 thèmes, 26 sujets, 127 catégories et 379 compétences, avec une riche diversité de domaines. L'ensemble de données de référence est divisé en parties de formation, de validation et de test avec respectivement 12 726, 4 241 et 4 241 échantillons. Cet article compare deux méthodes représentatives, dont le modèle GPT-3.5 (text-davinci-002) et le modèle GPT-3.5 sans version Chain of Thought (CoT), LLaMA-Adapter et Multimodal Thought Chain (MM-CoT) [57 ], qui est la méthode SoTA actuelle sur cet ensemble de données, et les résultats sont présentés dans le tableau 6.

Commentaires sur l'essai
Sur la page d'utilisation de la visualisation donnée dans le document, Machine Heart a également essayé de saisir quelques images et instructions. La première est une tâche courante à plusieurs personnes dans les questions et réponses. Des tests ont montré que les cibles plus petites sont ignorées lors du comptage des personnes, qu'il existe des erreurs de reconnaissance pour les personnes qui se chevauchent et qu'il existe également des erreurs de reconnaissance pour le sexe.


Ensuite, nous avons essayé quelques tâches génératives, telles que nommer les images ou raconter une histoire basée sur les images. Les résultats produits par le modèle sont toujours biaisés en faveur de la compréhension du contenu de l'image, et les capacités de génération doivent être renforcées.


Sur cette photo, même si les corps humains se chevauchent, le nombre de personnes peut toujours être identifié avec précision. Du point de vue de la description des images et de la capacité de compréhension, il y a encore des points forts dans le travail de cet article, et il y a de la place pour une deuxième création.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI