
Maison >Périphériques technologiques >IA >L'Université du Wisconsin-Madison et d'autres ont publié conjointement un article ! Le dernier grand modèle multimodal LLaVA est sorti et son niveau est proche de GPT-4
L'Université du Wisconsin-Madison et d'autres ont publié conjointement un article ! Le dernier grand modèle multimodal LLaVA est sorti et son niveau est proche de GPT-4

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-30 22:49:051840parcourir
Le réglage fin des commandes visuelles est populaire.
Cet article s'appelle Visual Instruction Tuning et est produit conjointement par l'Université du Wisconsin-Madison, Microsoft Research et l'Université de Columbia.
Les auteurs incluent Haotian Liu, Chunyuan Li, Qingyang Wu et Yong Jae Lee.

Dans le même temps, les chercheurs ont également ouvert leur code, leurs modèles et leurs ensembles de données sur GitHub. Le document est également publié sur Arxiv.
Explication
Alors quelle est exactement la fonction de LLaVA ? Si vous vous plongez dans le journal, cela peut paraître un peu étrange à ceux qui ne le connaissent pas.
Voyons d'abord ce que dit LLaVA.
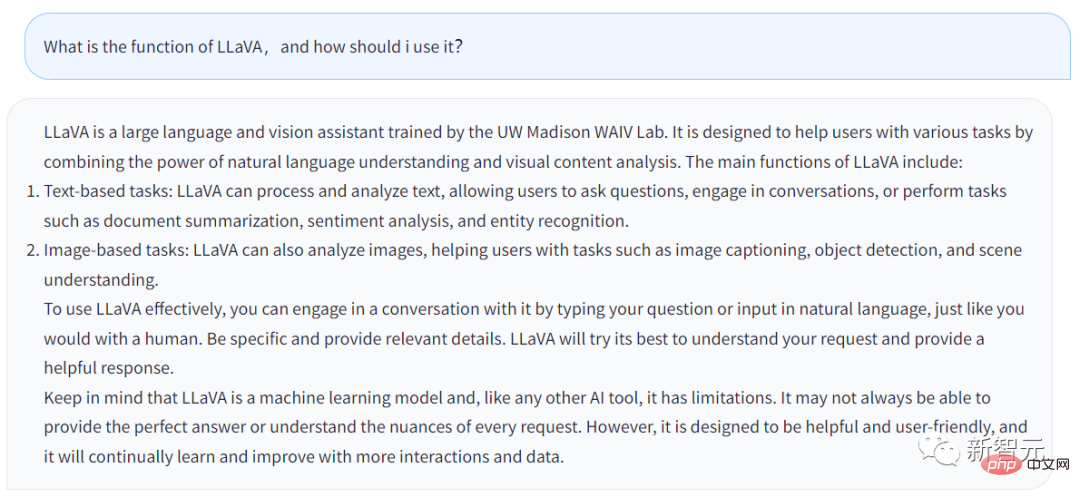
La réponse ci-dessus est générée à partir du chatbot de LLaVA. La question que j'ai posée est la suivante : quelle est la fonction de LLaVA et comment les utilisateurs peuvent-ils en profiter ?
La réponse est la suivante :
LLaVA est une grande assistante linguistique et visuelle formée au laboratoire UW Madison WAIV. LLaVA est conçu pour aider les utilisateurs à gérer diverses tâches en tirant parti de ses capacités de compréhension du langage naturel et de ses capacités d'analyse de contenu visuel.
Les principales fonctionnalités de LLaVA incluent :
· Tâches basées sur du texte : LLaVA peut traiter et analyser du texte, permettant aux utilisateurs de poser des questions, LLaVA peut parler aux utilisateurs ou effectuer des tâches saisies par les utilisateurs, telles que Talk. sur l'affinement des résumés de documents, l'analyse des sentiments, la reconnaissance des entités, etc.
· Tâches basées sur l'image : LLaVA peut analyser des images, décrire des images, effectuer une reconnaissance d'objets, ainsi qu'analyser et comprendre des scènes.
Si les utilisateurs souhaitent mieux utiliser LLaVA, ils peuvent parler directement à LLaVA, tout comme parler aux humains. Fournissez autant de détails que possible et LLaVA générera une réponse plus complète.
En même temps, vous devez vous rappeler qu'après tout, LLaVA est un modèle d'apprentissage automatique et un outil d'IA. Tant qu’il s’agit d’un outil, il a ses limites. LLaVA peut ne pas être en mesure de répondre parfaitement aux questions saisies par les utilisateurs à chaque fois.
Bien sûr, LLaVA apprend et s'améliore également constamment, et ses fonctions deviendront de plus en plus puissantes.
De manière générale, il ressort de la réponse de LLaVA que les fonctions du Chatbot ne sont pas très différentes de celles du GPT. Mais LLaVA peut gérer certaines tâches liées aux images.
Exhibiting Color
Les chercheurs ont détaillé les détails techniques de LLaVA dans un article sur Arxiv.
Il est important de savoir que l'utilisation d'instructions générées par la machine pour suivre les données afin d'affiner les instructions des grands modèles de langage (LLM) améliore les capacités du point zéro pour les nouvelles tâches, mais cette idée a été moins explorée dans le multi- champ modal.
Dans cet article, les chercheurs ont d'abord tenté d'utiliser GPT-4 uniquement en langage pour générer des données de suivi de commande pour des images en langage multimodal.
En conditionnant les instructions sur ces données générées, les chercheurs introduisent LLaVA : un assistant de langage et de vision à grande échelle, un modèle multimodal à grande échelle formé de bout en bout qui connecte des encodeurs visuels et des LLM pour la vision générale et compréhension du langage.
Les premières expériences montrent que LLaVA démontre des capacités de chat multimodales impressionnantes, produisant parfois des performances GPT-4 multimodales sur des images/instructions invisibles et suivant des instructions multimodales synthétiques. Par rapport à GPT-4 sur l'ensemble de données, il a atteint un score relatif de 85,1%.
Une fois affinée pour le magazine Science, la synergie de LLaVA et GPT-4 a atteint une nouvelle précision de pointe de 92,53 %.
Les chercheurs ont divulgué les données, les modèles et la base de code pour les ajustements de commandes visuelles générés par GPT-4.
Modèle multimodal
Clarifiez d’abord la définition.
Le modèle multimodal à grande échelle fait référence à un modèle basé sur la technologie d'apprentissage automatique qui peut traiter et analyser plusieurs types d'entrée, tels que du texte et des images.
Ces modèles sont conçus pour gérer un plus large éventail de tâches et sont capables de comprendre différentes formes de données. En prenant du texte et des images en entrée, ces modèles améliorent leur capacité à comprendre et à compiler des explications pour générer des réponses plus précises et pertinentes.
Les humains interagissent avec le monde à travers de multiples canaux tels que la vision et le langage, car chaque canal individuel présente des avantages uniques pour représenter et transmettre certains concepts du monde, propices ainsi à une meilleure compréhension du monde.
L'une des principales aspirations de l'intelligence artificielle est de développer un assistant universel capable de suivre efficacement des instructions visuelles et linguistiques multimodales, cohérentes avec les intentions humaines, et d'effectuer une variété de tâches du monde réel.
En conséquence, la communauté des développeurs constate un regain d'intérêt pour le développement de modèles de vision fondamentaux améliorés par le langage et dotés de puissantes capacités de compréhension visuelle en monde ouvert, telles que la classification, la détection, la segmentation, la description, ainsi que la génération et l'édition de vision.
Dans ces fonctionnalités, chaque tâche est résolue indépendamment par un seul grand modèle visuel, avec des instructions de tâche implicitement prises en compte dans la conception du modèle.
De plus, le langage n'est utilisé que pour décrire le contenu de l'image. Cela permet au langage de jouer un rôle important dans la cartographie des signaux visuels avec la sémantique linguistique – un canal commun pour la communication humaine. Mais cela aboutit à des modèles qui ont souvent des interfaces fixes avec une interactivité et une adaptabilité limitées aux instructions de l'utilisateur.
Et les grands modèles de langage (LLM) montrent que le langage peut jouer un rôle plus large : une interface commune pour un assistant universel, diverses instructions de tâches peuvent être explicitement exprimées dans le langage et guider de bout en bout le changement d'assistant neuronal formé. Go à la tâche qui vous intéresse et la résoudre.
Par exemple, le récent succès de ChatGPT et GPT-4 a prouvé la capacité de ce LLM à suivre les instructions humaines et a stimulé un énorme intérêt pour le développement de LLM open source.
LLaMA est un LLM open source dont les performances sont équivalentes à GPT-3. Les travaux en cours exploitent diverses instructions de haute qualité générées par la machine à la suite d'échantillons pour améliorer les capacités d'alignement du LLM, rapportant des performances impressionnantes par rapport aux LLM propriétaires. Il est important de noter que cette ligne de travail est uniquement composée de texte.
Dans cet article, les chercheurs proposent le réglage des commandes visuelles, qui est la première tentative d'étendre le réglage des commandes dans un espace multimodal et ouvre la voie à la création d'un assistant visuel universel. Plus précisément, le contenu principal de l'article comprend :
Instruction multimodale suivant les données. Un défi majeur est le manque d’instructions visuelles pour suivre les données. Nous présentons une perspective et un pipeline de réforme des données qui utilisent ChatGPT/GPT-4 pour convertir les paires image-texte en formats de suivi de commande appropriés.
Grand modèle multimodal. Les chercheurs ont développé un grand modèle multimodal (LMM) en connectant l'encodeur visuel ouvert de CLIP et le décodeur de langage LaMA, et les ont peaufinés de bout en bout sur les données pédagogiques visuelles-verbales générées. Des études empiriques vérifient l'efficacité du réglage des instructions LMM à l'aide des données générées et fournissent des suggestions pratiques pour créer un agent visuel général suivant les instructions. Avec GPT 4, l’équipe de recherche a atteint des performances de pointe sur l’ensemble de données d’inférence multimodale Science QA.
Open source. L'équipe de recherche a rendu public les éléments suivants : les données d'instructions multimodales générées, une bibliothèque de codes pour la génération de données et la formation de modèles, des points de contrôle de modèles et une démonstration de chat visuel.
Affichage des résultats

On peut voir que LLaVA peut gérer toutes sortes de problèmes, et les réponses générées sont à la fois complètes et logiques.
LLaVA présente des capacités multimodales proches du niveau du GPT-4, avec un score relatif GPT-4 de 85% en termes de chat visuel.
En termes de questions et réponses de raisonnement, LLaVA a même atteint le nouveau SoTA-92,53%, battant la chaîne de pensée multimodale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI