
Maison >Périphériques technologiques >IA >De ODS à ADS, une explication détaillée de la stratification des entrepôts de données !
De ODS à ADS, une explication détaillée de la stratification des entrepôts de données !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-30 20:22:042170parcourir
1. Pourquoi devrions-nous superposer l'entrepôt de données
Ce n'est qu'une fois que le modèle de données a organisé et stocké les données de manière ordonnée que le Big Data peut être utilisé avec des performances élevées, un faible coût, une efficacité élevée et une qualité élevée.
01 Signification de la superposition
1) Structure de données claire : Chaque couche de données a sa portée, afin que nous puissions la localiser et la comprendre plus facilement lors de l'utilisation de tableaux.
Structuralisation des relations de données : il existe des relations de données complexes entre les systèmes sources. Par exemple, les informations sur les clients existent en même temps dans le système de base, le système de crédit, le système de gestion financière et le système de capital. décision lors de la récupération des données ? L'entrepôt de données effectuera une modélisation unifiée des données sur le même thème et triera les relations de données complexes en modèles de données clairs, ce qui pourra éviter les problèmes ci-dessus lors de son utilisation.
2) Suivi de la lignée des données : En termes simples, cela peut être compris ainsi. Ce que nous donnons en fin de compte à l'intégrité commerciale, c'est un tableau commercial qui peut être utilisé directement, mais il provient de nombreuses sources. il y a une source Il y a un problème avec la montre, et nous voulons être en mesure de localiser rapidement et précisément le problème et de comprendre l'ampleur du dommage.
3) Réutilisation des données pour réduire le développement répété : Standardisez la superposition de données et développez des données de couche intermédiaire communes, ce qui peut réduire d'énormes calculs répétés. Basée sur le principe de traitement des données couche par couche, la couche inférieure contient toutes les données nécessaires au traitement des données de la couche supérieure. Cette méthode de traitement évite à chaque développeur de données de réextraire les données du système source pour les traiter. Grâce à l'introduction de la couche récapitulative, les calculs répétés de la logique des utilisateurs en aval sont évités, ce qui permet aux utilisateurs de gagner du temps et de l'énergie en matière de développement, ainsi que de réaliser des économies de calcul et de stockage. Il réduit considérablement la redondance inutile des données, permet la réutilisation des résultats de calcul et réduit considérablement les coûts de stockage et de calcul.
4) Simplifiez les problèmes complexes. Décomposez une tâche complexe en plusieurs étapes à réaliser. Chaque couche ne gère qu'une seule étape, qui est relativement simple et facile à comprendre. Il est également facile de maintenir l'exactitude des données. En cas de problème avec les données, vous n'avez pas besoin de réparer toutes les données. Il vous suffit de commencer à les réparer à partir de l'étape problématique.
5) Protégez (l'influence) des données d'origine et protégez l'impact sur l'entreprise. Lorsque l'entreprise ou le système change, il n'est pas nécessaire de changer d'entreprise une fois puis de reconnecter les données. Améliorez la stabilité et la continuité des données.
Protégez la complexité du système métier source : le système source peut être extrêmement compliqué, et la dénomination des tables, la dénomination des champs, les significations des champs, etc. peuvent être diverses. La couche DW est utilisée pour standardiser et protéger tout cela. complexités pour garantir l’utilisation des données par les utilisateurs en aval. Commodité et normalisation des données. Si l'activité du système source change, les modifications pertinentes seront traitées par la couche DW, qui est transparente pour les utilisateurs en aval sans modifier le code et la logique des utilisateurs en aval.
Maintenabilité de l'entrepôt de données : la conception en couches permet de résoudre les problèmes sur une certaine couche uniquement au niveau de cette couche, sans modifier le code et la logique de la couche suivante.
Les systèmes Big Data nécessitent des méthodes de modélisation de données pour aider à mieux organiser et stocker les données afin d'atteindre le meilleur équilibre entre performances, coûts, efficacité et qualité !
02 Les quatre opérations de l'entrepôt de données (ETL)
ETL (extraction transformation chargement) est responsable de l'extraction des données de sources de données dispersées et hétérogènes vers la couche intermédiaire temporaire pour le nettoyage, la transformation, l'intégration et enfin le chargement . dans un entrepôt de données ou un datamart. ETL est le cœur et l'âme de la mise en œuvre d'un entrepôt de données. La conception et la mise en œuvre des règles ETL représentent environ 60 à 80 % de la charge de travail totale de construction d'un entrepôt de données.
1) L'extraction de données comprend le chargement initial des données et l'actualisation des données : le chargement initial des données se concentre principalement sur la façon d'établir des tables de dimensions et des tables de faits, et de placer les données correspondantes dans ces tables de données, et l'actualisation des données se concentre sur la manière de ; ajouter et mettre à jour les données correspondantes dans l'entrepôt de données lorsque les données sources changent (par exemple, vous pouvez créer des tâches planifiées ou effectuer une actualisation des données planifiée sous forme de déclencheurs).
2) Le nettoyage des données consiste principalement à effectuer un traitement unifié des données présentant des problèmes tels que l'ambiguïté, la duplication, l'incomplétude, la violation des règles métier ou logiques, etc. qui apparaissent dans la base de données source. C’est-à-dire nettoyer les données qui ne correspondent pas à l’entreprise ou qui sont inutiles. Par exemple, vous pouvez écrire hive ou MR pour nettoyer les données dont la longueur ne répond pas aux exigences.
3) La transformation des données (transformation) consiste principalement à convertir les données nettoyées en données requises par l'entrepôt de données : dictionnaires de données ou formats de données du même champ de données provenant de différents systèmes sources. Cela peut être différent (par exemple, on l'appelle id dans le tableau A et ids dans le tableau B). Dans l'entrepôt de données, il est nécessaire de leur fournir un dictionnaire et un format de données unifiés pour normaliser le contenu des données ; besoins de l'entrepôt Le contenu de certains champs peut ne pas être disponible dans le système source, mais doit être déterminé en fonction du contenu de plusieurs champs du système source.
4) Le chargement des données consiste à importer les dernières données traitées dans l'espace de stockage correspondant (hbase, mysql, etc.) pour faciliter la mise à disposition du data mart pour la visualisation.
En général, les grandes entreprises disposent de leur propre plate-forme de données encapsulée et de leur propre plate-forme de planification de tâches pour la sécurité des données et la commodité de fonctionnement. La couche inférieure encapsule les clusters Big Data tels que le cluster Hadoop, le cluster Spark, Squoop, Hive, Zookeeper, hbase, etc. Fournissez une interface Web et accordez différentes autorisations à différents employés, puis effectuez différentes opérations et appels sur le cluster. En prenant l'entrepôt de données comme exemple, l'entrepôt de données est divisé en plusieurs niveaux logiques. De cette manière, pour différents niveaux d'opérations sur les données, différents niveaux de tâches peuvent être créés et exécutés dans différents niveaux de flux de tâches (un cluster dans une grande entreprise a généralement des milliers, voire des dizaines de milliers, de tâches planifiées en attente d'exécution). chaque jour, les divisions sont donc différentes. Flux de tâches hiérarchique, les tâches à différents niveaux sont exécutées dans des flux de tâches correspondants, ce qui rendra la gestion et la maintenance plus pratiques).
03 Malentendus sur la superposition
La division interne de la couche d'entrepôt de données n'est pas une superposition pour le plaisir de la superposition. La superposition vise à résoudre l'organisation des tâches et des flux de travail ETL, le flux de données et le contrôle de. autorisations de lecture et d'écriture. Divers problèmes tels que la satisfaction de différents besoins.
Une pratique courante dans l'industrie consiste à diviser l'ensemble de la couche d'entrepôt de données en plusieurs couches telles que DWD, DWT, DWS, DIM, DM, etc. Cependant, nous n'avons jamais été en mesure de déterminer quelles sont les limites claires entre ces couches, ni de les expliquer clairement. Cependant, les scénarios commerciaux complexes nous empêchent de les mettre en œuvre réellement.
De manière générale, trois couches sont les plus basiques en matière de stratification des données. Quant à la manière de segmenter la couche DW, elle est définie en fonction des besoins spécifiques de l'entreprise et des scénarios de l'entreprise.
2. Architecture technique de l'entrepôt de données
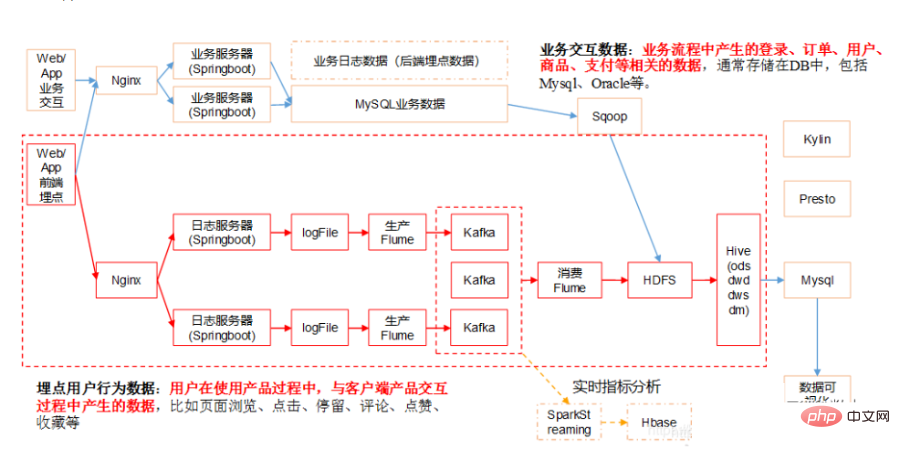
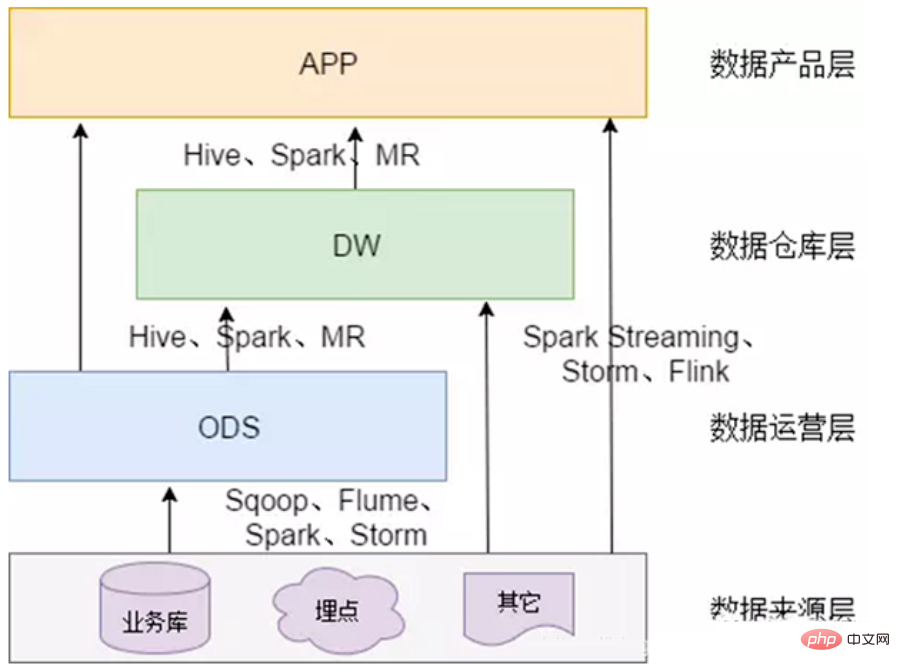
Le data center contient beaucoup de contenu S'il correspond à des travaux précis, il peut inclure le contenu suivant :
- Architecture système : Une architecture système centrée sur Hadoop, Spark et autres composants
- Architecture des données : Conception de niveau supérieur, division par domaine, conception hiérarchique, ODS-DW-ADS#🎜 🎜 #
- Modélisation des données : Modélisation dimensionnelle, processus métier - déterminer la granularité - la dimension - la table de faits #🎜🎜 #
- Gestion des données : Gestion des actifs, gestion des métadonnées, gestion de la qualité, gestion des données de référence, normes de données, gestion de la sécurité des données#🎜 🎜# Systèmes auxiliaires :
- Système de planification, système ETL, système de surveillance# 🎜🎜 #Service de données :
- Portail de données, exploration de données d'apprentissage automatique, requête de données, analyse, système de rapports, système de visualisation, téléchargement de partage d'échange de données# 🎜🎜 #3. Architecture en couches de l'entrepôt de données
Normes de l'entrepôt de données peut être divisé en quatre couches. Cependant, veuillez noter que cette division et cette dénomination ne sont pas uniques. Généralement, les entrepôts de données comportent quatre niveaux, mais différentes sociétés peuvent avoir des noms différents. Mais les concepts de base proviennent tous du modèle de données à quatre couches. 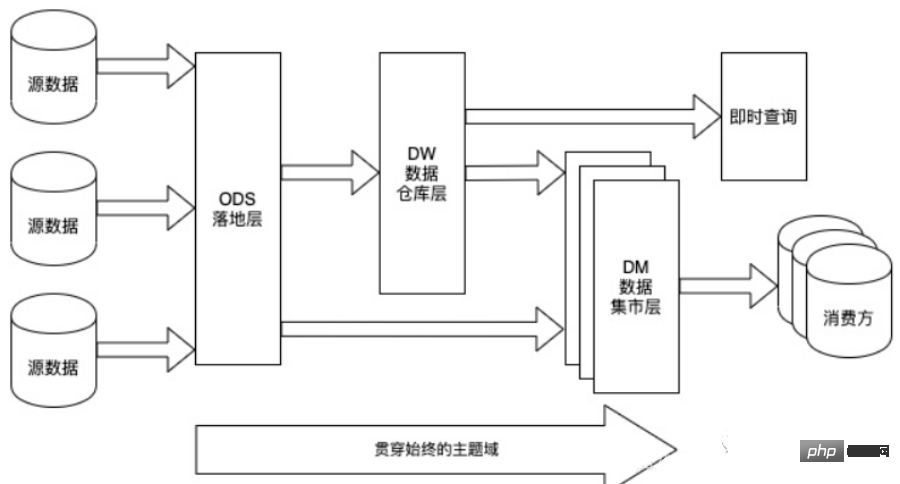

# 🎜 🎜# 01 Couche post-source (ODS, Operational Data Store)
01 Couche post-source (ODS, Operational Data Store)
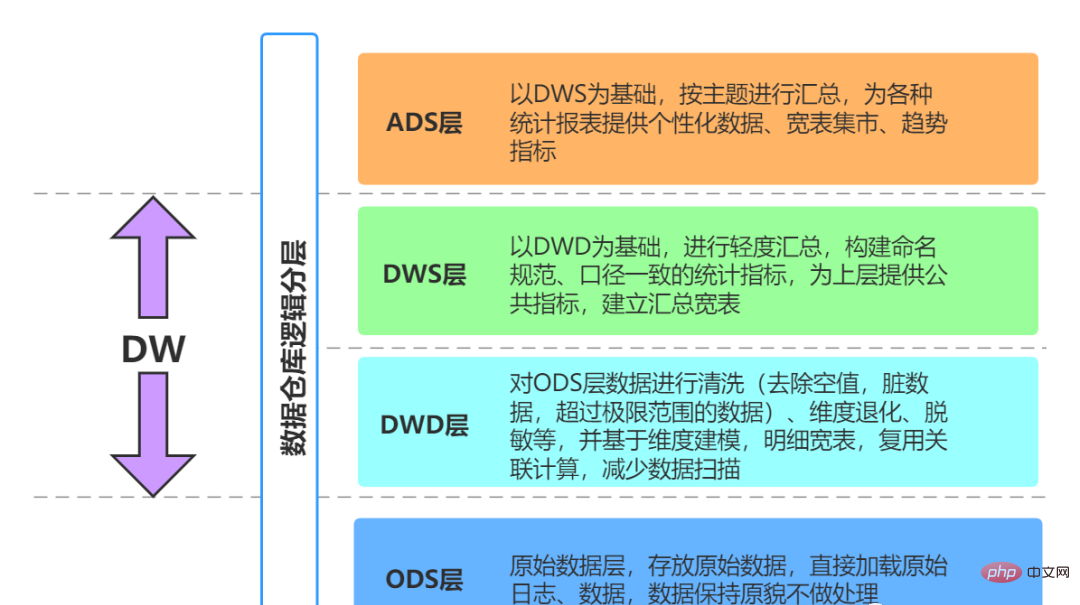
data Couche d'introduction (ODS, Operational Data Store, également appelée couche de base de données) : les données originales sont stockées dans le système d'entrepôt de données sans presque aucun traitement. La structure est fondamentalement cohérente avec le système source. l'entrepôt de données. La principale responsabilité de cette couche est de synchroniser et de stocker les données de base.
De manière générale, les données de la couche ODS et les données du système source sont isomorphes, et l'objectif principal est de simplifier traitement ultérieur des données. En termes de granularité des données, la granularité des données de la couche ODS est bonne. Les tables de la couche ODS comprennent généralement deux types, l'une utilisée pour stocker les données actuelles qui doivent être chargées et l'autre utilisée pour stocker les données historiques après traitement. Les données historiques sont généralement stockées pendant 3 à 6 mois, puis doivent être effacées pour économiser de l'espace. Cependant, différents projets doivent être traités différemment. Si la quantité de données dans le système source n'est pas importante, elles peuvent être conservées pendant une période plus longue ou même enregistrées dans leur intégralité.
Remarque : À cette couche, il ne doit pas s'agir d'un simple accès aux données, mais certains nettoyages de données, comme les champs anormaux, doivent être pris en compte le traitement, la standardisation de la dénomination des champs, l'unification des champs temporels, etc. Généralement, ceux-ci sont facilement ignorés, mais ils sont cruciaux. Cela sera très utile surtout lorsque nous ferons ultérieurement une génération automatique de diverses fonctionnalités.
Remarque : La couche ODS de certaines entreprises ne filtrera pas trop les données et sera placée dans la couche DWD pour traitement. Certaines entreprises effectuent dès le début un filtrage relativement raffiné des données au niveau de la couche ODS. Cela n'est pas clairement défini et dépend des idées et des spécifications techniques de chaque entreprise.
Le développement général de l'entreprise effectuera un traitement de base lorsque les données d'origine sont stockées dans ODS.
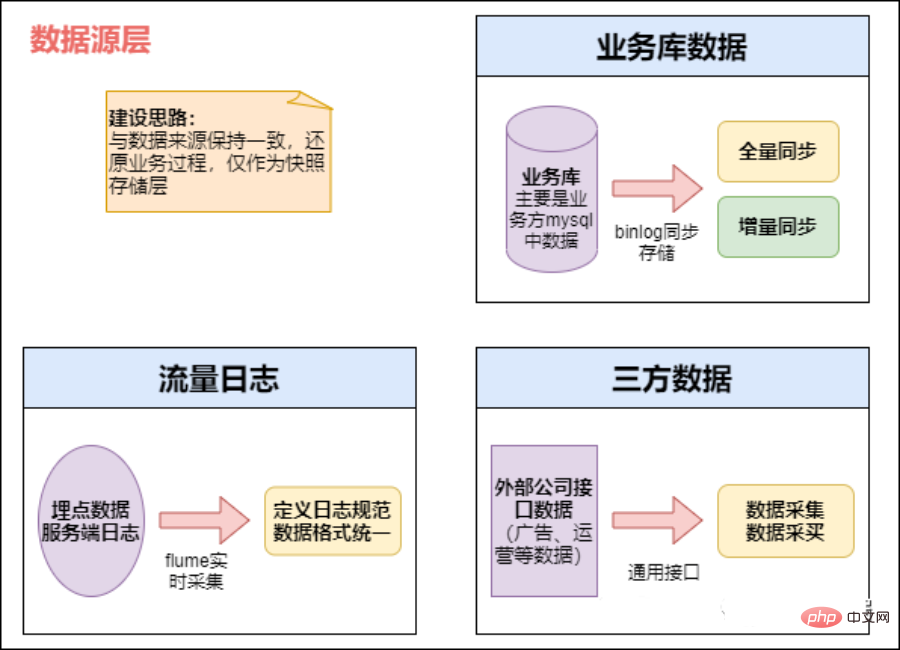
Distinction des sources de données
#🎜🎜 #Les données sont stockées selon des partitions temporelles, généralement en jours. Certaines entreprises utilisent également des partitions à trois niveaux d'année, de mois et de jour pour le stockage.
Effectuer le traitement des données le plus élémentaire, tel que l'élimination des erreurs de format, le filtrage de la perte d'informations clés, etc.
Données en temps réel hors ligne
- Aspects hors ligne : tâches planifiées quotidiennes : exécution de tâches par lots, bibliothèques métier, telles que nos tâches informatiques quotidiennes typiques, où Sqoop est souvent utilisé pour extraire, comme la nôtre Draw régulièrement chaque jour. Calculez les données de la veille chaque petit matin et lisez le rapport le matin. Ce type de tâche est souvent calculé à l'aide de Hive et Spark, et les résultats finaux sont écrits dans Hive, Hbase, Mysql, Es ou Redis.
- Données temps réel : journal des données de points enfouis ou bibliothèque métier, cette partie est principalement utilisée par divers systèmes temps réel, tels car nos recommandations en temps réel et nos portraits d'utilisateurs en temps réel sont généralement calculés à l'aide de Spark Streaming et Flink, et finiront par tomber dans Es, Hbase ou Redis. La source de données est une base de données commerciale. Vous pouvez envisager d'utiliser Canal pour surveiller le Binlog de Mysql et y accéder en temps réel. Ensuite, elles sont également collectées dans la file d'attente des messages et finalement transférées vers HDFS par Camus.
1) Principale source de données :
#🎜🎜 #- La source de données est une base de données d'entreprise, et les données générées par tous les systèmes de l'entreprise
- est En enterrant les rapports sur le client, nous collectons des journaux de comportement des utilisateurs et certaines sources de données de type journal des journaux back-end. Pour les journaux de comportement enfouis, cela passe généralement par un processus comme celui-ci. Tout d'abord, les données sont signalées à Nginx puis collectées par Flume. Ensuite, elles sont stockées dans une file d'attente de messages telle que Kafka, puis extraites en temps réel. ou des tâches d'extraction hors ligne. Obtenez notre entrepôt de données hors ligne HDFS
- données externes (y compris les données coopératives et les données obtenues par les robots d'exploration) et convertissez-les. les données collectées Rassemblez le tout
2) Stratégie de stockage des données (incrémental, complet)# 🎜🎜#
Dans les applications réelles, vous pouvez choisir d'utiliser un stockage incrémentiel, complet ou un stockage à glissière.
- stockage incrémental#🎜🎜 #
Par exemple :
#🎜🎜 #Le 1er janvier, l'utilisateur A a visité la boutique de commerce électronique B de l'entreprise A et le journal de commerce électronique de l'entreprise A a généré un enregistrement t1. Le 2 janvier, l'utilisateur A a visité la boutique de commerce électronique C de l'entreprise A et le journal de commerce électronique de l'entreprise A. généré Un enregistrement t2.
Grâce au stockage incrémentiel, t1 sera stocké dans la partition le 1er janvier et t2 sera stocké le 2 janvier dans cette partition .
Le 1er janvier, l'utilisateur A a acheté le produit B sur le site e-commerce de l'entreprise A, et un enregistrement t1 sera généré dans le journal des transactions. Le 2 janvier, l'utilisateur A renvoie à nouveau le produit B et le journal des transactions mettra à jour l'enregistrement t1.
Grâce au stockage incrémentiel, l'enregistrement t1 initial acheté sera stocké dans la partition le 1er janvier et le t1 mis à jour sera stocké dans cette partition le 2 janvier.
Les tables ODS avec une forte nature de transaction, telles que les transactions et les journaux, conviennent au stockage incrémentiel. Ce type de table contient une grande quantité de données et le coût de stockage lié à l'utilisation du stockage complet est élevé. De plus, les applications en aval de ces tables nécessitent moins d’accès complet aux données historiques (ces demandes peuvent être obtenues grâce à une agrégation ultérieure par l’entrepôt de données). Par exemple, une table de journal ODS n'a pas de processus métier de mise à jour des données, donc toutes les partitions incrémentielles UNION ensemble pour former un ensemble complet de données. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Stockage complet # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #
Stockage complet en jours, avec la date ouvrable comme partition, et chaque partition stocke l'intégralité des données professionnelles jusqu'à la date ouvrable.
- Par exemple, le 1er janvier, le vendeur A a lancé deux produits, B et C, sur le site de commerce électronique de l'entreprise A. La table générera deux enregistrements t1 et t2. Le 2 janvier, le vendeur A a retiré le produit B des étagères et a publié le produit D en même temps. La table de produits frontale mettra à jour l'enregistrement t1 et générera un nouvel enregistrement t3. En utilisant la méthode de stockage complet, deux enregistrements de t1 et t2 sont stockés dans la partition le 1er janvier et les enregistrements t1, t2 et t3 mis à jour sont stockés dans la partition le 2 janvier.
Pour des données dimensionnelles à évolution lente avec une petite quantité de données, telles que les catégories de produits, un stockage complet peut être utilisé directement. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # zipper Storage # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # Le stockage Zip enregistre toutes les données modifiées avec une granularité quotidienne en ajoutant deux nouveaux champs d'horodatage (start_dt et end_dt). Habituellement, les champs de partition sont également ces deux champs d'horodatage.
- scheme
notion : Également appelée couche d'interface (étape), utilisée pour stocker les données incrémentielles quotidiennes et les données modifiées
Méthode de génération de données : directe Pour recevoir données source de Kafka, la table métier doit générer des données de mise à jour, de suppression et d'insertion chaque jour. Seule la table métier pour l'insertion des données est générée et les données sont directement saisies dans la couche de détail.
Plan de discussion : ne placez le journal du canal que directement dans la couche tampon. S'il y a d'autres entreprises avec des données de fermeture éclair, mettez-le également. dans la couche tampon.
Méthode de stockage des journaux : utilisation de l'apparence impala et du format de fichier parquet pour faciliter la lecture des données nécessitant un traitement MR.
Méthode de suppression du journal : stockage longue durée, seules les données des derniers jours peuvent être stockées. Plan de discussion : stockage direct longue durée.
Schéma de table : les partitions sont généralement créées par jour et les partitions par sont généralement stockées par jour.
Bibliothèque et dénomination des tables. Nom de la bibliothèque : ods, nom de la table : Le format de considération initial est le nom de la table métier ods date, à déterminer.
hive la table externe correspond à la table métier.
hive external table, le fichier stockant les données peut ne pas se trouver à l'emplacement par défaut du hdfs de la ruche, et lorsque la table correspondante de la ruche est supprimé, Les fichiers de données correspondants ne seront pas supprimés.De cette façon, pour le développement de l'entreprise, cela peut empêcher la suppression de données précieuses de la table d'affaires Hive en raison des opérations de suppression de table. Au contraire, les fichiers de données sont stockés par défaut. emplacement correspondant à la table de la ruche. Une fois supprimés, les fichiers correspondants seront également supprimés.
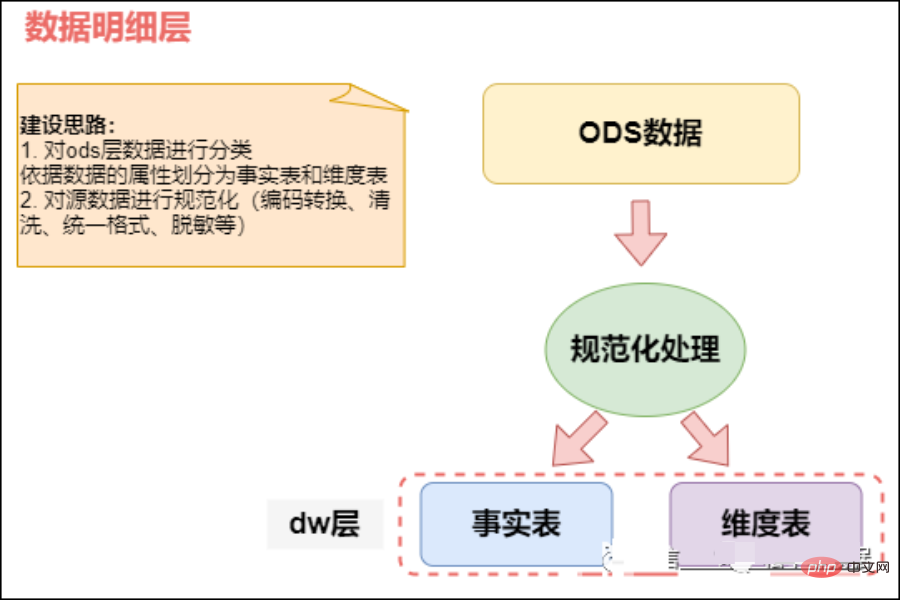
02 Entrepôt de données (DW)
Couche d'entrepôt de données ( Couche DW) : La couche d'entrepôt de données est la couche de conception de base lorsque nous construisons un entrepôt de données. Cette couche construira divers modèles de données basés sur des thèmes à partir des données obtenues à partir de la couche ODS. Chaque thème correspond à une macro dans la zone d'analyse. la couche d'entrepôt de données exclut les données qui ne sont pas utiles à la prise de décision et fournit une vue concise d'un sujet spécifique. Toutes les données historiques du système BI seront enregistrées au niveau de la couche DW, par exemple 10 années de données.
DW stocke des données de faits détaillées, des données de tableaux de dimensions et des données récapitulatives d'indicateurs publics. Parmi eux, des données factuelles détaillées et des données de table de dimension sont généralement générées sur la base du traitement des données de la couche ODS. Les données récapitulatives des indicateurs publics sont généralement générées sur la base des données des tableaux de dimensions et des données factuelles détaillées.
La couche DW est subdivisée en couche de dimension (DIM), couche de données détaillées (DWD) et couche de données récapitulatives (DWS) .En utilisant la méthode du modèle dimensionnel comme base théorique, nous pouvons définir la relation entre la clé primaire du modèle dimensionnel et la clé étrangère dans le modèle de faits, réduire la redondance des données et améliorer la convivialité du tableau de données détaillé. Dans la couche de données récapitulatives, des dimensions de la granularité statistique réutilisée peuvent également être associées, et des méthodes de tableaux plus larges peuvent être utilisées pour construire la couche de données d'indicateurs publics afin d'améliorer la réutilisabilité des indicateurs publics et de réduire les traitements répétés.
Couche de dimension (DIM, Dimension) : utiliser les dimensions comme pilote de modélisation, en fonction de la signification commerciale de chaque dimension, en ajoutant dimensions Définir la logique de calcul des attributs, les dimensions associées, etc., compléter le processus de définition des attributs et établir des tables de dimensions cohérentes pour l'analyse des données. Afin d'éviter les attributs de dimension associés de manière redondante dans le modèle dimensionnel, une table de dimensions est construite sur la base du modèle en flocon de neige.
Couche de données détaillées (DWD, Data Warehouse Detail) : Utilisation des processus métier comme moteurs de modélisation, en fonction des fonctionnalités spécifiques de chaque processus métier, créer le tableau de faits détaillé le plus fin. Certains champs d'attributs importants peuvent être rendus redondants de manière appropriée, c'est-à-dire le traitement de tables étendues.
Data Warehouse Summary (DWS) : en utilisant l'objet analysé comme pilote de modélisation, il crée un tableau d'indicateurs récapitulatif granulaire public basé sur les exigences en matière d'indicateurs des applications et des produits de couche supérieure. Utilisez des méthodes de tableaux larges pour physicaliser le modèle, créez des indicateurs statistiques avec des normes de dénomination et des calibres cohérents, fournissez des indicateurs publics pour la couche supérieure et établissez des tableaux récapitulatifs généraux et des tableaux de faits détaillés.
Domaine thématique : une collection abstraite d'événements d'activité commerciale, orientée vers les processus métier, tels que la passation de commande, le paiement et le remboursement, sont tous des processus métier. Partitionnement de thèmes pour le niveau de détail commun (DWD).
Domaine de données : pour l'analyse commerciale, il s'agit d'un ensemble abstrait de processus ou de dimensions métier. Partitionnement du domaine de données pour la couche de résumé commune (DWS).
La couche DWD est pilotée par les processus métier.
La couche DWS, la couche DWT et la couche ADS sont toutes axées sur la demande.
DWD : couche de détail des données de l'entrepôt de données. Effectuer principalement certaines opérations de nettoyage et de normalisation des données sur la couche de données ODS.
Nettoyage des données : supprimez les valeurs nulles, les données sales, la conversion des valeurs d'énumération et celles qui dépassent la plage limite.
DWB : couche de base de données de base d'entrepôt de données, qui stocke les données objectives. Elle est généralement utilisée comme couche intermédiaire et peut être considérée comme une couche de données pour un grand nombre d'indicateurs.
DWS : couche de service de données de service d'entrepôt de données, basée sur les données de base sur DWB, intégrées et résumées dans une couche de données de service pour analyser un certain domaine, généralement un large tableau. Utilisé pour fournir des requêtes commerciales ultérieures, une analyse OLAP, une distribution de données, etc.
Comportement de l'utilisateur, agrégation légère
Faites principalement un résumé léger des données de la couche ODS/DWD.
1) Couche de dimension publique (DIM, Dimension)
DIM : Vous pouvez la comprendre en donnant un exemple, comme le code du pays et le nom du pays, l'emplacement géographique, Le nom chinois et le drapeau national. Les informations telles que les images sont stockées dans la couche DIM.
Basé sur le concept de modélisation dimensionnelle, établir des dimensions cohérentes pour l'ensemble de l'entreprise. Réduisez le risque de calibres et d’algorithmes de calcul de données incohérents.
La couche récapitulative des dimensions publiques (DIM) est principalement composée de tables de dimensions (tableaux de dimensions). La dimension est un concept logique, une perspective à partir de laquelle mesurer et observer les affaires. Les tables de dimensions sont des tables qui physicalisent des tables construites sur la plateforme de données en fonction des dimensions et de leurs attributs, et adoptent le principe de conception de tables larges. Par conséquent, la création d’une couche récapitulative des dimensions communes (DIM) nécessite d’abord de définir les dimensions.
Données dimensionnelles à haute cardinalité : généralement des tableaux de données similaires aux tableaux de données utilisateur et aux tableaux de données produits. La quantité de données peut atteindre des dizaines ou des centaines de millions.
Données dimensionnelles de faible cardinalité : généralement un tableau de configuration, comme la signification chinoise correspondant à la valeur d'énumération, ou le tableau des dimensions de date. La quantité de données peut être composée d'un seul chiffre ou de dizaines de milliers.
Tableau des dimensions de conception :
Après avoir terminé la définition des dimensions, vous pouvez compléter les dimensions et générer le tableau des dimensions. La conception des tableaux de dimensions nécessite une attention particulière :
Il est recommandé que les informations du tableau des dimensions ne dépassent pas 10 millions de pièces.
Lorsque vous joignez une table de dimensions avec d'autres tables, il est recommandé d'utiliser Map Join
pour éviter de mettre à jour les données de la table de dimensions trop fréquemment. Dimensions qui changent lentement : table Zipper
Spécification de la table de dimensions de la couche de résumé des dimensions publiques (DIM)
Spécification de dénomination de la table de dimensions de la couche de résumé des dimensions publiques (DIM) : dim_{Nom du segment d'activité/pub} _{Définition de la dimension}[_{Balise de nom personnalisée}], ce qu'on appelle la pub est une dimension qui n'a rien à voir avec le secteur d'activité spécifique ou qui est commune à tous les secteurs d'activité, comme la dimension temporelle.
Par exemple : table de dimension de zone publique dim_pub_area table de dimension de produit dim_asale_itm
Table de faits Le degré de détail métier exprimé par un enregistrement est appelé granularité. Généralement, la granularité peut être exprimée de deux manières : l'une est le niveau de détail représenté par la combinaison d'attributs de dimension, et l'autre est la signification métier spécifique représentée. Transparent! Méthodes de modélisation courantes et exemples pratiques dans le domaine des entrepôts de données.
Méthodes et principes de modélisation
# 🎜 🎜#Il est nécessaire de construire un modèle dimensionnel, généralement à l'aide d'un modèle en étoile, et l'état présenté est généralement un modèle de constellation (composé de plusieurs tables de faits, la table de dimensions est publique et peut être partagée par plusieurs tables de faits) ; 🎜##🎜 🎜#
Afin de prendre en charge la réexécution des données, un champ de date professionnelle supplémentaire peut être ajouté et les tableaux peuvent être divisés par jour, en utilisant Données de couche ODS incrémentielles et tables liées au DWD de la veille Effectuer un traitement de fusion ?La granularité est une ligne d'informations représentant un comportement, comme passer une commande.
Étapes de modélisation dimensionnelle
#🎜 🎜 #Sélectionner le processus de gestion : dans le système de gestion, sélectionnez le secteur d'activité qui vous intéresse, tel que l'activité de commande, l'activité de paiement, l'activité de remboursement, l'activité de logistique. Un secteur d'activité correspond à une table de faits. S'il s'agit d'une petite ou moyenne entreprise, essayez de sélectionner tous les processus métier. Si DWD est une grande entreprise (plus de 1 000 tables), choisissez le métier en rapport avec les besoins.
Granularité des déclarations : la granularité des données fait référence au niveau de raffinement ou d'exhaustivité des données stockées dans l'entrepôt de données. Déclarer la granularité signifie définir précisément ce que représente une ligne de données dans la table de faits. Vous devez choisir la plus petite granularité possible pour répondre à une variété de besoins. Une déclaration de granularité typique est la suivante : chaque élément de la commande est traité comme une ligne dans la table des faits de la commande, et la granularité est à chaque fois. Le nombre de commandes par semaine est donné sous forme de ligne, la granularité étant hebdomadaire. Le nombre de commandes par mois est présenté sous forme de ligne, la granularité étant mensuelle. Si la granularité au niveau de la couche DWD est hebdomadaire ou mensuelle, il n'y aura aucun moyen de compter les indicateurs à granularité fine plus tard. Il est donc recommandé d’utiliser la plus petite granularité.
Déterminer les dimensions : le rôle principal des dimensions est de décrire les faits commerciaux et de représenter principalement "qui, où, quand" et d'autres information. Le principe pour déterminer les dimensions est le suivant : si les indicateurs des dimensions pertinentes doivent être analysés dans les exigences ultérieures. Par exemple, des statistiques sont nécessaires pour déterminer quand davantage de commandes ont été passées, quelle région a passé le plus de commandes et quel utilisateur a passé le plus de commandes. Les dimensions qui doivent être déterminées comprennent : la dimension temporelle, la dimension régionale et la dimension utilisateur. Tableau des dimensions : la dégradation des dimensions doit être effectuée selon le principe du schéma en étoile dans la modélisation dimensionnelle.
Déterminer les faits : Le mot « fait » fait ici référence à la valeur de mesure (nombre de fois, nombre, nombre de pièces et le montant peut être accumulé), comme le montant de la commande, le nombre de commandes passées, etc. Dans la couche DWD, le processus métier est utilisé comme pilote de modélisation, et la table de faits de la couche de détail la plus fine est construite en fonction des caractéristiques de chaque processus métier spécifique. La table de faits peut être élargie de manière appropriée.
Remarque : La couche DWD est pilotée par les processus métier. Les couches DWS, DWT et ADS sont toutes basées sur la demande et n'ont rien à voir avec la modélisation dimensionnelle. DWS et DWT créent tous deux des tableaux larges et créent des tableaux en fonction de thèmes. Le thème équivaut à la perspective sous laquelle le problème est envisagé. Correspond au tableau des dimensions.
A propos du sujet :
#🎜 🎜 #Les données de l'entrepôt de données sont organisées par thème. Le thème est un concept abstrait qui synthétise, catégorise, analyse et utilise les données du système d'information de l'entreprise à un niveau supérieur. Chaque thème correspond essentiellement à un champ d'analyse macro. Par exemple, l'analyse financière est un domaine d'analyse, le thème de cette application d'entrepôt de données est donc « analyse financière ».
À propos du domaine sujet :
# 🎜 🎜#Un domaine thématique est généralement un ensemble de sujets de données étroitement liés. Ces sujets de données peuvent être divisés en différents domaines en fonction des préoccupations commerciales (c'est-à-dire les limites des sujets déterminées après analyse d'un sujet)
#🎜 🎜#À propos de la répartition des domaines :
La détermination du domaine sujet doit être complétée conjointement par l'utilisateur final (entreprise) et le concepteur de l'entrepôt de données. Lors de la division du domaine sujet, les différents points d'entrée de chacun peuvent provoquer des débats, des refactorisations, etc., considérez que les points peuvent. être certains des aspects suivants :
- Divisé selon l'entreprise ou le processus commercial : par exemple, un site Web portail qui repose sur la vente de postes publicitaires peut avoir un domaine publicitaire, un domaine client, etc., et la publicité le domaine peut être Il y aura un inventaire publicitaire, une analyse des ventes, une analyse de la livraison interne et d'autres sujets
- Divisé en fonction du côté de la demande : par exemple, si le côté de la demande est le service financier, le domaine financier correspondant peut être défini, et le domaine financier peut inclure Il y aura des sujets tels que l'analyse des salaires des employés, l'analyse du taux de retour sur investissement, etc.
- divisés selon les fonctions ou les applications : comme le champ de données du cercle d'amis, champ de données de discussion de groupe, etc. dans WeChat, et le champ de données du cercle d'amis peut avoir des utilisateurs Thèmes d'information dynamiques, thèmes publicitaires, etc.
- Divisé selon les départements : par exemple, il peut y avoir des domaines opérationnels, domaines techniques, etc. Dans le domaine opérationnel, il peut y avoir des sujets tels que l'analyse des dépenses salariales, l'analyse des effets de promotion d'événements, etc.
En bref, si la logique de départ est différente, il peut y avoir des logiques de division. Une approche itérative peut être adoptée pendant le processus de construction. Au lieu de vous concentrer sur l'abstraction de tous les sujets en même temps, vous pouvez commencer par des sujets clairement définis, puis les résumer progressivement dans un modèle standard pour votre propre secteur.
Thèmes : parties, marketing, finance, accord contractuel, organisation, adresse, canal, produit,
Quels sont les sujets liés aux affaires financières : peuvent être divisés en quatre sujets :
- Thème de l'utilisateur (âge de l'utilisateur, sexe, adresse de livraison, numéro de téléphone, province, etc.)
- Thème de la transaction (données de commande, données de facture, etc.)
- Thème de contrôle des risques (données de l'utilisateur niveau de contrôle des risques, données de crédit tiers)
- Sujets marketing (liste des activités marketing, informations de configuration des activités, etc.)
2) Couche de détail des données DWD (détail de l'entrepôt de données), granulaire couche de faits

DWD est la couche d'isolation entre la couche métier et l'entrepôt de données. Cette couche résout principalement certains problèmes de qualité des données et d'intégrité des données.
La table détaillée est utilisée pour stocker les données détaillées converties à partir de la table originale de la couche ODS. Les données de la couche DWD doivent être cohérentes, précises et propres, c'est-à-dire la couche ODS des données du système source. les données doivent être nettoyées (supprimer les données vides, les données sales, les données dépassant la plage limite, changer le stockage de lignes en stockage de colonnes, changer le format de compression), la normalisation, la dégradation des dimensions, la désensibilisation et d'autres opérations. Par exemple, les informations sur les données utilisateur proviennent de nombreuses tables différentes, et des problèmes tels qu'une perte de données retardée surviennent souvent. Afin de permettre à chaque utilisateur de mieux utiliser les données, nous pouvons créer un bouclier au niveau de cette couche. Cette couche contient également des données dimensionnelles unifiées.
Couche de faits détaillés (DWD) : en prenant le processus métier comme moteur de modélisation, en fonction des caractéristiques de chaque processus métier spécifique, la table de faits de couche détaillée la plus fine est construite. En combinant les caractéristiques d'utilisation des données de l'entreprise, certains champs d'attributs de dimension importants de la table de faits détaillés peuvent être rendus redondants de manière appropriée, c'est-à-dire le traitement de tables étendues. Les tableaux au niveau des faits à granularité fine sont souvent également appelés tableaux de faits logiques.
Responsable des données les plus granulaires des données, basées sur la couche DWD, légèrement résumées, combinées avec des dimensions communes (heure, lieu, niveau organisationnel, utilisateurs, produits, etc.)
Cette couche Généralement, la même granularité des données que la couche ODS est conservée et une certaine garantie de qualité des données est fournie. Les données sont traitées sur la base de l'ODS pour fournir des données plus propres. Dans le même temps, afin d'améliorer la convivialité de la couche de détail des données, cette couche adoptera certaines techniques de dégradation des dimensions. Lorsqu'une dimension ne dispose d'aucune donnée requise par l'entrepôt de données, la dimension peut être dégradée et la dimension peut être dégradée. dégradé en table de faits, réduisant ainsi le nombre de tables de faits et d'associations de tables de dimensions.
Par exemple :
Identifiant de commande, une dimension si grande, il n'est pas nécessaire d'utiliser une table de dimensions pour le stocker, et l'identifiant de commande est généralement très important lorsque nous effectuons une analyse de données, nous le L'ID de commande est redondant dans la table de faits. Cette dimension est une dimension dégénérée.
Les données à ce niveau suivent généralement la troisième forme normale ou modélisation dimensionnelle de la base de données, et sa granularité des données est généralement la même que celle de l'ODS. Toutes les données historiques du système BI seront enregistrées au niveau de la couche PDW, par exemple, 10 ans de données seront enregistrées.
Les travaux suivants doivent être effectués avant que les données ne soient chargées dans cette couche : débruitage, déduplication, suppression de la saleté, extraction d'entreprise, unification des unités, découpe de champ et identification d'entreprise.
Types de données nettoyées :
- Données incomplètes
- Données d'erreur
- Données en double
La tâche de nettoyage des données est Filtrer les données qui ne répondent pas aux exigences, et soumettre les résultats filtrés au service métier pour confirmer s'ils sont filtrés ou corrigés par la business unit avant extraction.
Que fait la couche DWD ?
①Nettoyage et filtrage des données
Supprimer les champs abandonnés, supprimer les informations mal formatées
Supprimer les informations qui ont perdu des champs clés
Le champ principal du filtre est constitué de données dénuées de sens, par exemple, l'identifiant de commande dans le tableau de commande est nul et l'identifiant de paiement dans le tableau de paiement est vide
Désensibiliser les données sensibles telles que les numéros de téléphone portable et les numéros d'identification
Supprimer les données qui le font ne contiennent pas d'informations temporelles (Cela dépend de l'activité spécifique de l'entreprise, mais généralement les données seront horodatées, afin de faciliter le traitement ultérieur, l'analyse de l'information, le traitement et l'extraction dans la dimension temporelle)
Certaines entreprises imprimeront également les données à cette couche sont plates, mais cela dépend des besoins de l'entreprise. En effet, kylin est adapté au traitement des données aplaties, mais ne convient pas au traitement des informations de données de tableaux imbriqués
Certaines entreprises réduiront également la session de données, il s'agit généralement d'une application. Les données du journal peuvent ne pas convenir à d'autres scénarios commerciaux. En effet, l'application passe en mode arrière-plan. Par exemple, l'utilisateur ouvre l'application pendant 10 minutes le matin, puis l'application passe en arrière-plan et l'ouvre. encore une fois la nuit. À ce moment-là, la session en est toujours une, et en fait, elle devrait être coupée. (Il existe également des entreprises qui enregistrent les enregistrements de l'application entrant en arrière-plan et entrant à nouveau à la réception, pour le faire. coupure de session)
②Cartographie et conversion des données
Convertissez la longitude et la latitude GPS en adresse détaillée de la province et de la ville. Les requêtes rapides GPS courantes dans l'industrie cartographient généralement la base de connaissances de localisation géographique à l'aide de geohash, puis convertissent le GPS à comparer en geohash, puis comparent le geohash dans la base de connaissances pour découvrir les informations de localisation géographique. les entreprises qui utilisent une API ouverte, comme Amap, l'API de Baidu Map cartographie les informations GPS et de localisation géographique, mais cela coûte de l'argent pour atteindre un certain nombre de fois, donc tout le monde sait que l'adresse IP sera également convertie en adresses détaillées des provinces et villes. Il existe de nombreuses bibliothèques de recherche rapide, mais le principe de base est la recherche binaire, car l'adresse IP peut être convertie en un entier long. Un exemple typique est la bibliothèque ip2region
qui convertit le temps en année, mois, jour ou. même la semaine, informations sur les dimensions du trimestre
Standardisation des données, car les données traitées par le big data peuvent provenir de différents départements de l'entreprise ressource, de différents projets et de différents clients. À l'heure actuelle, les mêmes champs de données commerciales, les mêmes données. Les types, les valeurs nulles, etc. peuvent être différents. À ce stade, il est nécessaire de lisser le calque DWD, sinon cela causera beaucoup de problèmes lors du traitement ultérieur. Par exemple, les booléens sont marqués de 0 à 1. avec vrai et faux. Par exemple, la chaîne est vide. La valeur peut être "" ou nulle, utilisez-la simplement comme null
.Comme le format de date, il est plus différent et doit être déterminé en fonction des données commerciales réelles, mais il est généralement formaté dans des formats standard tels que AAAA-MM-jj HH:mm:ss
dimensions Dégradation : effectuez une dégradation des dimensions et une réduction de la dimensionnalité sur les tables transférées à partir des données métier. (Produit niveau un, niveau deux, niveau trois, province, ville, comté, année, mois, jour) L'ID de commande est redondant dans la table de faits
Quelle quantité de données est raisonnable à nettoyer : 1 donnée est nettoyé sur 10 000.
Nombre raisonnable de tables : dix mille tables deviennent trois mille tables, trois mille tables deviennent mille tables
Principes détaillés de conception de tables de faits granulaires :
- Une table de faits granulaires est associé à une seule dimension.
- Incluez autant de faits que possible liés au processus commercial.
- Choisissez uniquement les faits pertinents pour le processus métier.
- Décomposez les faits non additifs en composants additifs.
- La granularité doit être déclarée avant de sélectionner les dimensions et les faits.
- Vous ne pouvez pas avoir plusieurs faits de granularités différentes dans la même table de faits.
- Les unités de faits doivent être cohérentes. Granularité
- Manipulez les valeurs Null avec prudence.
- Utilisez des dimensions dégénérées pour améliorer la convivialité des tableaux de faits.
Plan
Plan de discussion : La méthode de synthèse des données est :
Montant total : Chaque jour, le montant total des données d'avant-hier et les nouvelles données d'hier sont synthétisés dans une nouvelle table de données au niveau de la couche de détail. Écrasez l'ancienne table. En même temps, utilisez la mise en miroir historique pour stocker un miroir historique dans un nouveau tableau par semaine/mois/année.
Méthode de stockage des journaux : les données directes utilisent l'apparence impala et le format de fichier parquet. Il est recommandé d'utiliser des tables internes. Les couches suivantes sont toutes des données générées à partir d'impala. .
Schéma de table : créez généralement des partitions par jour et sélectionnez les champs de partition en fonction d'une activité spécifique sans la notion de temps. partitionné par est généralement stocké en fonction des jours.
Nom de la bibliothèque et des tables. Nom de la bibliothèque : dwd, nom de la table : Le format de considération initial est le nom de la table métier dwd date, à déterminer.
Ancienne méthode de mise à jour des données : couverture directe } _{Abréviation du processus métier}[_{Abréviation de l'étiquette de dénomination de table personnalisée}] _{Identification complète incrémentielle de partition unique}, pub signifie que les données incluent des données provenant de plusieurs secteurs d'activité. L'identifiant du montant total incrémentiel d'une seule partition est généralement : i signifie incrément, f signifie montant total.
Par exemple : dwd_asale_trd_ordcrt_trip_di (tableau de faits sur les commandes de billets d'avion d'une société de commerce électronique, incrément d'actualisation quotidien) dwd_asale_itm_item_df (tableau de faits sur les instantanés de produits de commerce électronique, montant total d'actualisation quotidienne).
Dans ce tutoriel, la couche DWD est principalement composée de trois tables :
Table de faits sur les informations sur les produits de trading : dwd_asale_trd_itm_di.
Tableau d'informations sur les membres commerçants : ods_asale_trd_mbr_di.
- Tableau d'informations sur les commandes de transaction : dwd_asale_trd_ord_di.
-
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di ( item_id BIGINT COMMENT '商品ID', item_title STRING COMMENT '商品名称', item_price DOUBLE COMMENT '商品价格', item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手', item_prov STRING COMMENT '商品省份', item_city STRING COMMENT '商品城市', cate_id BIGINT COMMENT '商品类目ID', cate_name STRING COMMENT '商品类目名称', commodity_id BIGINT COMMENT '品类ID', commodity_name STRING COMMENT '品类名称', buyer_id BIGINT COMMENT '买家ID', ) COMMENT '交易商品信息事实表' PARTITIONED BY (ds STRING COMMENT '日期') LIFECYCLE 400;
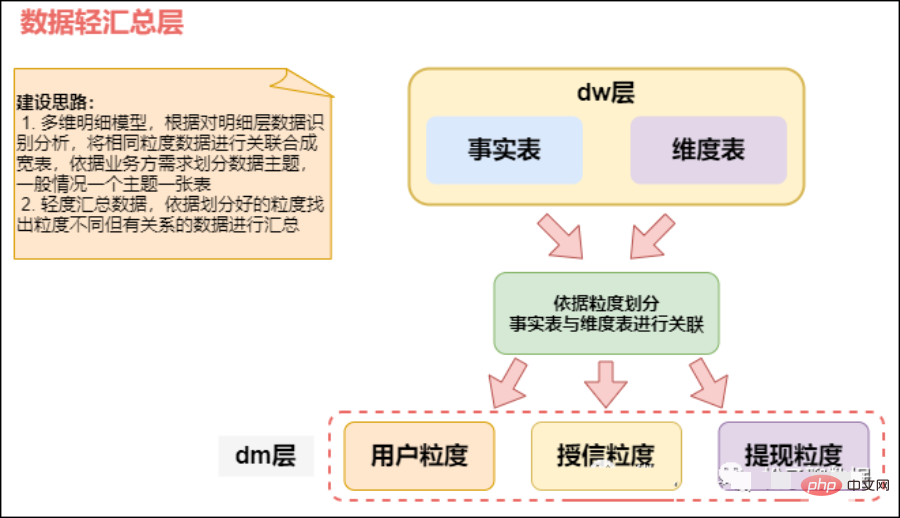
3) Couche de service de données DWS (service d'entrepôt de données), tableau à l'échelle de la couche récapitulative
Sur la base de la couche de données détaillée DWD, nous organiserons nos données en fonction de certains scénarios d'analyse, entités d'analyse, etc. La couche de données récapitulatives DWS est organisée en quelques sous-thèmes.
Granlarité détaillée ==> Granularité récapitulative
Tableau large de la couche DWS (couche de résumé des données), résumé orienté sujet, relativement peu de dimensions, DWS est basé sur les données de base de la couche DWD. Dimension ID effectue une agrégation récapitulative grossière, telle que l'agrégation par source de transaction et par type de transaction. Intégrez et résumez les données de service pour l’analyse d’un certain domaine, généralement dans un large tableau.
Basé sur DWD, résumé léger par jour. Statistiques du comportement quotidien de chaque objet sujet (par exemple, comportement d'achat, statistiques du taux de rachat de produits).
Il y aura relativement peu de tables de données dans cette couche, et la plupart d'entre elles sont des tables larges (une table couvrira plus de contenu métier et il y aura plus de champs dans la table). Selon les sujets, tels que les commandes, les utilisateurs, etc., un large tableau avec de nombreux champs est généré pour fournir des requêtes commerciales ultérieures, une analyse OLAP, une distribution de données, etc.
Intégrez plusieurs données de couche intermédiaire et formez des tables de faits basées sur des sujets, tels que des tables de faits sur les utilisateurs, des tables de faits sur les canaux, des tables de faits sur les terminaux, des tables de faits sur les actifs, etc. Les tables de faits sont généralement des tables larges et sont implémentées sur ce couche de cohérence des données à l’échelle de l’entreprise.
Divisez d'abord le sujet commercial en domaine de vente, domaine d'inventaire, domaine client, domaine d'achat, etc., puis déterminez la table de faits et la table de dimensions de chaque domaine de sujet. Généralement basé sur les besoins de l'entreprise, il est divisé en trafic, commandes, utilisateurs, etc., et un large tableau avec de nombreux champs est généré pour fournir des requêtes commerciales ultérieures, une analyse OLAP, une distribution de données, etc.
Les ventes totales d'une certaine catégorie (par exemple : ustensiles de cuisine) dans chaque province au cours du dernier jour, les noms des 10 produits les plus vendus dans la catégorie et la répartition du pouvoir d'achat des utilisateurs dans chaque province. Par conséquent, nous pouvons résumer les données du dernier jour du point de vue de la transaction finale réussie de biens, catégories, acheteurs, etc.
Par exemple, le nombre de produits achetés par les utilisateurs à différentes adresses IP de connexion au cours de chaque période, etc. Une légère agrégation ici rendra le calcul plus efficace, sur cette base, il sera beaucoup plus rapide si le comportement de seulement 7 jours, 30 jours et 90 jours est calculé. Nous espérons que 80 % des activités pourront être calculées via notre couche DWS au lieu d'ODS.
Que fait la couche DWS ?
dws résume les données de la couche dwd par sujet et les place dans un tableau en fonction du sujet
Par exemple, sous le sujet utilisateur, les informations d'enregistrement de l'utilisateur, l'adresse de livraison de l'utilisateur, et le rapport de crédit de l'utilisateur sera Les données sont placées dans le même tableau, et celles-ci correspondent à plusieurs tableaux de la couche dwd. Selon la division commerciale, comme le trafic, les commandes, les utilisateurs, etc., un large tableau avec plus de champs est disponible. généré
modélisation thématique autour d'un certain Effectuer une modélisation des données sur des sujets métiers et extraire les données pertinentes
Par exemple :
- Agréger les sessions de trafic par jour et par mois .
- Agrégation d'utilisateurs actifs quotidiens advance. Pratique pour les requêtes ultérieures
- Par exemple, si les données de dimension opérationnelle sont agrégées ① La couche DWS sera agrégée. 1 à 3 tableaux larges par sujet (traitement de 100 à plus de 70 % de la demande pour 200 indicateurs)
Noms de tables larges spécifiques : table large du comportement de l'utilisateur, table large du comportement des détails du produit d'achat de l'utilisateur, table large du produit, table large de la logistique, après-vente, etc.
②Quelle largeur de table est la plus large ? Il y a combien de champs environ ?
Le plus large est le tableau du comportement des utilisateurs. Il y a environ 60 à 200 champs
③Nom du champ de table large du comportement spécifique de l'utilisateur#🎜🎜 #
Commenter, récompenser, collecter, suivre - produits, suivre - personnes, liker, partager, news bon prix, sortie d'article, actif, se connecter, re-signer la carte, Lucky house, cadeaux, pièces d'or, clics e-commerce, gmv
④Indicateurs analysés# 🎜🎜## 🎜🎜#
Actif quotidien, actif mensuel, actif hebdomadaire, rétention, taux de rétention, nouveaux ajouts (jour, semaine, année), taux de conversion, désabonnement, retour, 3 jours consécutifs dans les sept jours Connexion ( like, favori, commentaire, achat, achat complémentaire, commande, activité), connexion 3 semaines consécutives (mois), GMV (montant de la transaction, commande), taux de rachat, classement des taux de rachat, likes, commentaires, collection, nombre de personnes recevant remises, utilisation des remises, silence, vaut-il la peine d'acheter, nombre de remboursements, taux de remboursement topn Produits populaires actif- Actif quotidien : 1 million ; actif mensuel : 2-3 fois actif quotidien 3 millions #🎜🎜 #
- Combien y a-t-il d'utilisateurs enregistrés au total ? Entre 10 millions et 30 millions
GMV, quel produit se vend le mieux ? Combien de commandes sont passées chaque jour ?
GMV : 100 000 commandes par jour (50 – 100 yuans) 5 à 10 millions
- # 🎜🎜#
- Avec une activité quotidienne de 1 million, il y a environ 100 000 achats chaque jour, avec une consommation moyenne de 100 yuans par personne et un GMV quotidien de 10 millions#🎜 🎜#
10%-20% 1 million-2 millions#🎜 🎜#
#🎜 🎜#Taux de rachat
Rachat d'un produit du quotidien ; (papier toilette, masque facial, dentifrice) 10%-20%
- Ordinateurs, moniteurs, montres 1%# 🎜🎜##🎜 🎜# Taux de conversion
#🎜🎜 ## 🎜🎜#Détails du produit =》 Ajouter à la boutique Car=》Commande=》Payer
5%-10% 60-70% 90%-95%
- Taux de rétention
1/2/3, rétention hebdomadaire, rétention mensuelle
Activité : 10-20%
- Régime :
Concept : également connu sous le nom de Data mart ou table large. Selon les divisions commerciales, telles que le trafic, les commandes, les utilisateurs, etc., un large tableau avec de nombreux champs est généré pour fournir des requêtes commerciales ultérieures, une analyse OLAP, une distribution de données, etc.
Méthode de génération de données : générée par une couche récapitulative légère et un calcul de données de couche détaillé.
Méthode de stockage des journaux : utilisation de la table interne impala, format de fichier parquet.
Schéma de table : Créez généralement des partitions par jour et sélectionnez les champs de partition en fonction d'une activité spécifique sans la notion de temps.
Bibliothèque et dénomination des tables. Nom de la bibliothèque : dws, nom de la table : Le format de considération initial est : dws date business nom de la table, à déterminer.
Ancienne méthode de mise à jour des données : écrasement direct #🎜🎜 #
Spécification du tableau de faits récapitulatif public公共汇总事实表命名规范:dws_{业务板块缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}。关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表。如果出现_nd的表字段过多需要拆分时,只允许以一个统计周期单元作为原子拆分。即一个统计周期拆分一个表,例如最近7天(_1w)拆分一个表。不允许拆分出来的一个表存储多个统计周期。
对于小时表(无论是天刷新还是小时刷新),都用_hh来表示。对于分钟表(无论是天刷新还是小时刷新),都用_mm来表示。
举例如下:
dws_asale_trd_byr_subpay_1d(买家粒度交易分阶段付款一日汇总事实表)
dws_asale_trd_byr_subpay_td(买家粒度分阶段付款截至当日汇总表)
dws_asale_trd_byr_cod_nd(买家粒度货到付款交易汇总事实表)
dws_asale_itm_slr_td(卖家粒度商品截至当日存量汇总表)
dws_asale_itm_slr_hh(卖家粒度商品小时汇总表)---维度为小时
dws_asale_itm_slr_mm(卖家粒度商品分钟汇总表)---维度为分钟
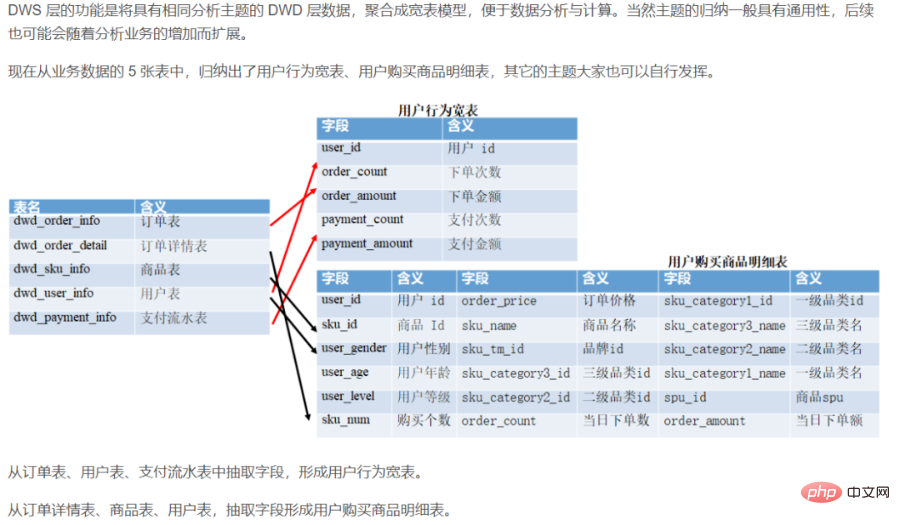
- 用户维度:用户主题
drop table if exists dws_sale_detail_daycount; create external table dws_sale_detail_daycount( user_id string comment '用户 id', --用户信息 user_gender string comment '用户性别', user_age string comment '用户年龄', user_level string comment '用户等级', buyer_nick string comment '买家昵称', mord_prov string comment '地址', --下单数、 商品数量, 金额汇总 login_count bigint comment '当日登录次数', cart_count bigint comment '加入购物车次数', order_count bigint comment '当日下单次数', order_amount decimal(16,2) comment '当日下单金额', payment_count bigint comment '当日支付次数', payment_amount decimal(16,2) comment '当日支付金额', confirm_paid_amt_sum_1d double comment '最近一天订单已经确认收货的金额总和' order_detail_stats array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计' ) comment '每日购买行为' partitioned by(`dt` string) stored as parquet location '/warehouse/gmall/dws/dws_sale_detail_daycount/' tblproperties("parquet.compression" = "lzo");- 商品维度:商品主题
CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d ( item_id BIGINT COMMENT '商品ID', --商品信息,产品信息 item_title STRING COMMENT '商品名称', cate_id BIGINT COMMENT '商品类目ID', cate_name STRING COMMENT '商品类目名称', --mord_prov STRING COMMENT '收货人省份', --商品售出金额汇总 confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和' ) COMMENT '商品粒度交易最近一天汇总事实表' PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD') LIFECYCLE 36000;
问:数据集市层是不是没地方放了,各个业务的数据集市表是应该在 dws 还是在 app?
答:这个问题不太好回答,我感觉主要就是明确一下数据集市层是干什么的,如果你的数据集市层放的就是一些可以供业务方使用的宽表,放在 app 层就行。如果你说的数据集市层是一个比较泛一点的概念,那么其实 dws、dwd、app 这些合起来都算是数据集市的内容。
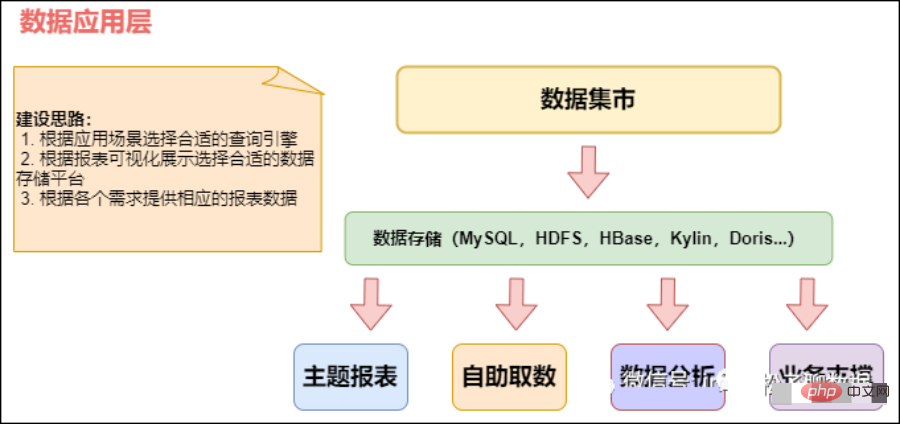
03 应用层(ADS)applicationData Service应用数据服务
数据应用层(ADS,Application Data Store):存放数据产品个性化的统计指标数据,报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。
在 DWS 之上,我们会面向应用场景去做一些更贴近应用的 APP 应用数据层,这些数据应该是高度汇总的,并且能够直接导入到我们的应用服务去使用。
应用层(ADS):应用层主要是各个业务方或者部门基于DWD和DWS建立的数据集市(Data Market, DM),一般来说应用层的数据来源于DW层,而且相对于DW层,应用层只包含部门或者业务方面自己关心的明细层和汇总层的数据。
该层主要是提供数据产品和数据分析使用的数据。一般就直接对接OLAP分析,或者业务层数据调用接口了
数据应用层APP:面向业务定制的应用数据主要提供给数据铲平和数据分析使用的数据,一般会放在ES,MYSQL,Oracle,Redis等系统供线上系统使用,也可以放在Hive 或者 Druid 中供数据分析和数据挖掘使用。
APP 层:为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。包括前端报表、分析图表、KPI、仪表盘、OLAP、专题等分析,面向最终结果用户;
概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。
数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
日志存储方式:使用impala内表,parquet文件格式。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名。库名:暂定ads,另外根据业务不同,不限定一定要一个库。
旧数据更新方式:直接覆盖。
ADS 层复购率统计
CREATE TABLE app_usr_interact( user_id string COMMENT '用户id', nickname string COMMENT '用户昵称', register_date string COMMENT '注册日期', register_from string COMMENT '注册来源', remark string COMMENT '细分渠道', province string COMMENT '注册省份', pl_cnt bigint COMMENT '评论次数', ds_cnt bigint COMMENT '打赏次数', sc_add bigint COMMENT '添加收藏', sc_cancel bigint COMMENT '取消收藏', gzg_add bigint COMMENT '关注商品', gzg_cancel bigint COMMENT '取消关注商品', gzp_add bigint COMMENT '关注人', gzp_cancel bigint COMMENT '取消关注人', buzhi_cnt bigint COMMENT '点不值次数', zhi_cnt bigint COMMENT '点值次数', zan_cnt bigint COMMENT '点赞次数', share_cnts bigint COMMENT '分享次数', bl_cnt bigint COMMENT '爆料数', fb_cnt bigint COMMENT '好价发布数', online_cnt bigint COMMENT '活跃次数', checkin_cnt bigint COMMENT '签到次数', fix_checkin bigint COMMENT '补签次数', house_point bigint COMMENT '幸运屋金币抽奖次数', house_gold bigint COMMENT '幸运屋积分抽奖次数', pack_cnt bigint COMMENT '礼品兑换次数', gold_add bigint COMMENT '获取金币', gold_cancel bigint COMMENT '支出金币', surplus_gold bigint COMMENT '剩余金币', event bigint COMMENT '电商点击次数', gmv_amount bigint COMMENT 'gmv', gmv_sales bigint COMMENT '订单数' ) PARTITIONED BY( dt string) --stat_dt date COMMENT '互动日期',
①如何分析用户活跃?
在启动日志中统计不同设备 id 出现次数。
②如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中 mid 为空的即为用户新增。
③如何分析用户 1 天留存?
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
④如何分析沉默用户?
(登录时间为 7 天前,且只出现过一次)
按照设备 id 对日活表分组,登录次数为 1,且是在一周前登录。
⑤如何分析本周回流用户?
本周活跃 left join 本周新增 left join 上周活跃,且本周新增 id 和上周活跃 id 都为 null。
⑥如何分析流失用户?
(登录时间为 7 天前)
按照设备 id 对日活表分组,且七天内没有登录过。
⑦如何分析最近连续 3 周活跃用户数?
按照设备 id 对周活进行分组,统计次数大于 3 次。
⑧Comment analyser le nombre d'utilisateurs actifs pendant trois jours consécutifs au cours des sept derniers jours ?
- Interrogez les utilisateurs actifs au cours des 7 derniers jours et classez la date d'activité de l'utilisateur
- Calculez la différence entre la date d'activité et le classement de l'utilisateur
- Calculez le même utilisateur et le même groupe les différences et comptez le nombre de différences
- Retirez les données avec le même nombre de différences supérieur ou égal à 3, puis supprimez les doublons, c'est-à-dire les utilisateurs qui ont été actifs pendant 3 jours consécutifs ou plus
7 Favoris, likes, achats, achats supplémentaires, paiements, navigation, clics sur les produits, retours en continu tous les jours
1 mois pendant 7 jours consécutifs
deux semaines consécutives
TMP : chaque niveau de calcul aura de nombreuses tables temporaires, et une couche DW TMP est spécialement conçue pour stocker les tables temporaires de notre entrepôt de données.
04 Spécification d'appel hiérarchique
- Les appels inversés sont interdits
- ODS ne peut être appelé que par DWD.
- DWD peut être appelé par DWS et ADS.
- DWS ne peut être appelé que par ADS.
- Les applications de données peuvent appeler DWD, DWS et ADS, mais il est recommandé de donner la priorité aux données avec un degré d'agrégation élevé.
- ODS->DWD->DWS>ADS
- ODS->DWD->ADS



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI