Le nouveau cadre de synthèse vidéo de Meta nous a apporté quelques surprises
En termes de niveau de développement de l'intelligence artificielle d'aujourd'hui, les images basées sur du texte, les vidéos basées sur des images et le transfert de style image/vidéo ne sont rien de difficile. L'IA générative est dotée de la capacité de créer ou de modifier du contenu sans effort. L’édition d’images, en particulier, a connu une croissance significative, portée par des modèles de diffusion texte-image pré-entraînés sur des ensembles de données à l’échelle d’un milliard. Cette vague a donné naissance à une pléthore d’applications d’édition d’images et de création de contenu. Sur la base des réalisations des modèles génératifs basés sur l'image, le prochain défi doit être d'y ajouter une « dimension temporelle », afin de réaliser un montage vidéo facile et créatif. Une stratégie simple consiste à utiliser un modèle d'image pour traiter la vidéo image par image. Cependant, l'édition d'image générative est intrinsèquement très variable : il existe d'innombrables façons d'éditer une image donnée, même à partir de la même invite de texte. Si chaque image est éditée indépendamment, il sera difficile de maintenir une cohérence temporelle. Dans un article récent, des chercheurs de l'équipe Meta GenAI ont proposé Fairy - une "simple adaptation" du modèle de diffusion de l'édition d'images, qui améliore considérablement les performances de l'IA dans le montage vidéo. Ce qui suit est l'affichage des effets vidéo d'édition de Fairy : 
Fairy génère 120 images de vidéo 512 × 384 (4 secondes, 30 FPS) en seulement 14 secondes, ce qui est au moins 44 fois plus rapide que les méthodes précédentes. Une étude utilisateur complète portant sur 1 000 échantillons générés a confirmé que la méthode proposée génère une qualité élevée et surpasse considérablement les méthodes existantes. Selon l'article, Fairy est basé sur le concept d'attention inter-images basée sur des points d'ancrage. Ce mécanisme peut implicitement propager des caractéristiques de diffusion à travers les images, garantissant des effets de synthèse cohérents dans le temps et haute fidélité. Fairy résout non seulement les limitations des modèles précédents en termes de mémoire et de vitesse de traitement, mais améliore également la cohérence temporelle grâce à une stratégie unique d'augmentation des données qui rend le modèle équivalent à une transformation affine des images source et cible.
- Adresse de papier: https://arxiv.org/pdf/2312.13834.pdf
- project Homepage: https://fairy-video2video.github.io/
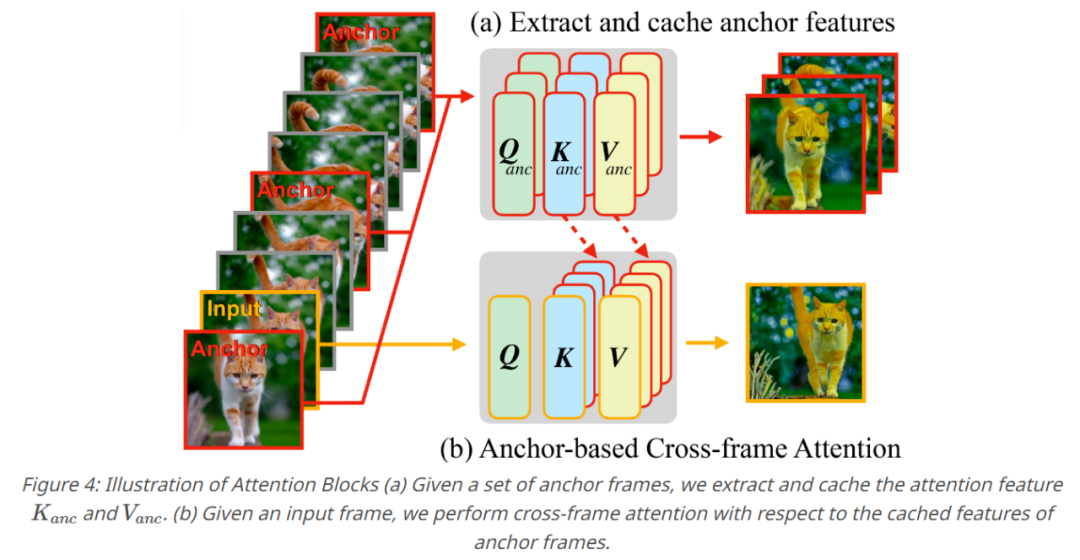
Fairy revisite le précédent paradigme de suivi et de propagation dans le contexte des caractéristiques du modèle de diffusion. En particulier, cette étude utilise l'estimation de correspondance pour combler l'attention inter-images, permettant au modèle de suivre et de propager les caractéristiques intermédiaires au sein du modèle de diffusion. La carte d'attention entre les images peut être interprétée comme une mesure de similarité pour évaluer la correspondance entre les jetons dans chaque image, où les caractéristiques d'une zone sémantique accorderont une plus grande attention aux autres images. Zones sémantiques similaires, comme le montre la figure 3 ci-dessous. . Par conséquent, la représentation actuelle des caractéristiques est affinée et propagée en se concentrant sur la somme pondérée des régions similaires entre les images, minimisant ainsi efficacement les différences de caractéristiques entre les images.
Une série d'opérations produit un modèle basé sur une ancre, qui est le composant central de Fairy. Pour garantir la cohérence temporelle des vidéos générées, cette étude a échantillonné K images d'ancrage pour extraire les caractéristiques de diffusion, et les caractéristiques extraites ont été définies comme un ensemble de caractéristiques globales à propager aux images consécutives. Cette étude remplace la couche d'auto-attention par une attention inter-images pour les fonctionnalités mises en cache de l'image d'ancrage lorsque chaque nouvelle image est générée. Grâce à l'attention inter-trames, les jetons de chaque trame adoptent des caractéristiques qui présentent un contenu sémantique similaire dans la trame d'ancrage, améliorant ainsi la cohérence.
Dans la partie expérimentale, les chercheurs ont principalement implémenté Fairy sur la base du modèle pédagogique d'édition d'images et ont utilisé l'attention multi-images pour remplacer l'auto-attention du modèle. Ils ont fixé le nombre de cadres d'ancrage à 3. Le modèle peut accepter des entrées de différents rapports d'aspect et redimensionner la résolution d'entrée de taille plus longue à 512, en gardant le rapport d'aspect inchangé. Les chercheurs éditent toutes les images de la vidéo d’entrée sans sous-échantillonnage. Tous les calculs sont répartis sur 8 GPU A100. Le chercheur a d'abord montré les résultats qualitatifs de Fairy, comme le montre la figure 5 ci-dessous, Fairy peut éditer différents sujets.
Dans la figure 6 ci-dessous, le chercheur montre que Fairy peut effectuer différents types d'édition en fonction des instructions du texte, notamment la stylisation, les changements de rôle, l'édition locale, l'édition d'attributs, etc.
La figure 9 ci-dessous montre que Fairy peut convertir le personnage source en différents personnages cibles selon les instructions.
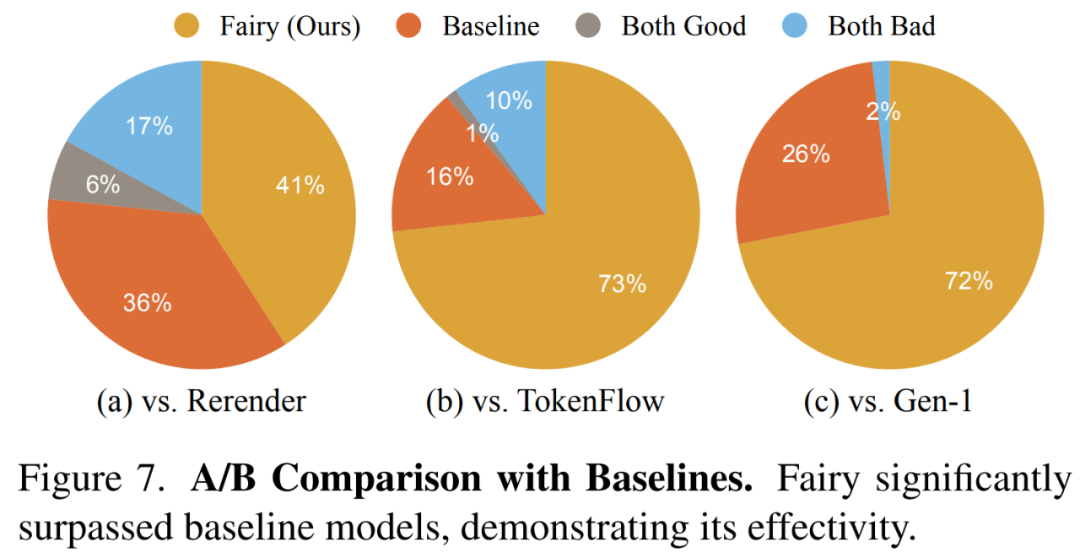
Les chercheurs montrent les résultats globaux de la comparaison de la qualité dans la figure 7 ci-dessous, dans laquelle les vidéos générées par Fairy sont les plus populaires.
La figure 10 ci-dessous montre les résultats de la comparaison visuelle avec le modèle de base.
Pour plus de détails techniques et de résultats expérimentaux, veuillez vous référer à l'article original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!