Dans les scénarios de génération vidéo, l'utilisation de Transformer comme épine dorsale du débruitage du modèle de diffusion s'est avérée réalisable par des chercheurs tels que Li Feifei. Cela peut être considéré comme un succès majeur pour Transformer dans le domaine de la génération vidéo.
Récemment, une recherche sur la génération vidéo a reçu de nombreux éloges et a même été qualifiée de « la fin d'Hollywood » par un internaute X. Est-ce vraiment si bon ? Jetons d'abord un coup d'œil à l'effet : 
Évidemment, ces vidéos non seulement ne contiennent presque aucun artefact, mais sont également très cohérentes et pleines de détails. Il semble même que même si quelques images sont ajoutées à un film à succès, ce ne sera évidemment pas incohérent. L'auteur de ces vidéos est le Window Attention Latent Transformer proposé par des chercheurs de l'Université de Stanford, de Google et du Georgia Institute of Technology, c'est-à-dire le Window Attention Latent Transformer, appelé W.A.L.T. Cette méthode intègre avec succès l’architecture Transformer dans le modèle de diffusion vidéo latente. Le professeur Li Feifei de l'Université de Stanford est également l'un des auteurs de l'article.
- Site Web du projet : https://walt-video-diffusion.github.io/
-
Adresse papier : https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
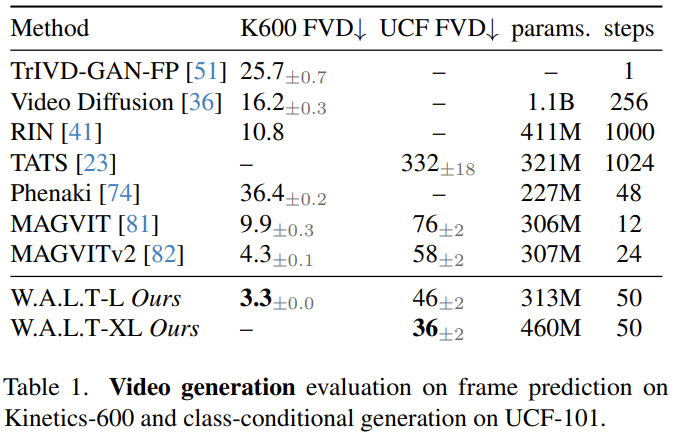
Avant cela, l'architecture Transformer a connu un grand succès dans de nombreux domaines différents, mais le domaine de la modélisation générative d'images et de vidéos est une exception. Le paradigme dominant dans ce domaine est le modèle de diffusion. Dans le domaine de la génération d'images et de vidéos, le modèle de diffusion est devenu le paradigme principal. Cependant, parmi toutes les méthodes de diffusion vidéo, le réseau fédérateur dominant est l’architecture U-Net composée d’une série de couches convolutives et d’auto-attention. U-Net est préféré car les besoins en mémoire du mécanisme d'attention totale de Transformer augmentent de façon quadratique avec la longueur de la séquence d'entrée. Lors du traitement de signaux de grande dimension tels que la vidéo, ce modèle de croissance rend le coût de calcul très élevé. Le modèle de diffusion latente (MLD) fonctionne dans un espace latent de dimension inférieure dérivé des auto-encodeurs, réduisant ainsi les exigences de calcul. Dans ce cas, un choix de conception clé est le type d’espace latent : compression spatiale versus compression espace-temps. Les gens préfèrent souvent la compression spatiale car elle permet l'utilisation d'encodeurs automatiques d'images et de LDM pré-entraînés, qui sont formés à l'aide de grands ensembles de données image-texte appariés. Cependant, le choix de la compression spatiale augmente la complexité du réseau et rend Transformer difficile à utiliser comme épine dorsale du réseau (en raison de contraintes de mémoire), en particulier lors de la génération de vidéos haute résolution. D’un autre côté, même si la compression spatio-temporelle peut atténuer ces problèmes, elle n’est pas adaptée au travail avec des ensembles de données image-texte appariés, qui ont tendance à être plus volumineux et plus diversifiés que les ensembles de données vidéo-texte. W.A.L.T est une méthode Transformer pour le modèle de diffusion vidéo latente (LVDM). Cette méthode se compose de deux étapes. Dans la première étape, un encodeur automatique est utilisé pour mapper la vidéo et l'image dans un espace latent unifié de basse dimension. Cela permet d'entraîner conjointement un modèle génératif unique sur des ensembles de données d'images et de vidéos et réduit considérablement le coût de calcul lié à la génération de vidéos haute résolution. Pour la deuxième phase, l'équipe a conçu un nouveau bloc Transformer pour les modèles de diffusion vidéo latente, composé de couches d'auto-attention qui fonctionnent dans un espace et un temps non chevauchants et restreints par fenêtre. Cette conception présente deux avantages principaux : premièrement, elle utilise l'attention de la fenêtre locale, ce qui peut réduire considérablement les besoins de calcul. Deuxièmement, cela facilite la formation conjointe, dans laquelle la couche spatiale peut traiter les images et les images vidéo de manière indépendante, tandis que la couche spatio-temporelle est utilisée pour modéliser les relations temporelles dans les vidéos. Bien que conceptuellement simple, cette étude est la première à démontrer expérimentalement la qualité de génération supérieure de Transformer et l'efficacité des paramètres dans la diffusion vidéo latente sur un benchmark public. Enfin, pour démontrer l'évolutivité et l'efficacité de la nouvelle méthode, l'équipe a également expérimenté la difficile tâche photoréaliste de génération d'image en vidéo. Ils ont formé trois modèles en cascade. Ceux-ci incluent un modèle de diffusion vidéo latente de base et deux modèles de diffusion vidéo à super-résolution. Le résultat est une vidéo avec une résolution de 512×896 à 8 images par seconde. Cette approche permet d'obtenir des scores FVD zéro tir de pointe sur la référence UCF-101.
De plus, ce modèle peut être utilisé pour générer des vidéos avec un mouvement de caméra 3D cohérent.
Apprentissage des jetons visuelsDans le domaine de la modélisation générative de la vidéo, une décision de conception clé est le choix de la représentation de l'espace latent. Idéalement, nous aimerions disposer d’une représentation visuelle compressée partagée et unifiée qui puisse être utilisée pour la modélisation générative d’images et de vidéos. Plus précisément, étant donné une séquence vidéo x, le but est d'apprendre une représentation z de basse dimension qui effectue une compression spatio-temporelle à une certaine échelle temporelle et spatiale. Afin d'obtenir une représentation unifiée de la vidéo et des images fixes, il est toujours nécessaire d'encoder la première image de la vidéo séparément des images restantes. Cela vous permet de traiter les images fixes comme s’il s’agissait d’une seule image vidéo. Basée sur cette idée, la conception actuelle de l'équipe utilise l'architecture causale d'encodeur-décodeur CNN 3D du tokenizer MAGVIT-v2. Après cette étape, l'entrée du modèle devient un lot de tenseurs latents, qui représentent une seule vidéo ou une pile d'images discrètes (Figure 2). Et la représentation implicite ici est à valeur réelle et non quantifiée. Apprenez à générer des images et des vidéos Patchify. Conformément à la conception originale de ViT, l'équipe a posé chaque cadre caché individuellement en le convertissant en une séquence de carreaux qui ne se chevauchent pas. Ils ont également utilisé des intégrations de positions apprenables, qui sont la somme des intégrations de positions spatiales et temporelles. L'intégration positionnelle est ajoutée à la projection linéaire de la tuile. Notez que pour les images, ajoutez simplement l'intégration de position temporelle correspondant à la première image cachée. Attention fenêtre. Les modèles de transformateurs entièrement constitués de modules globaux d’auto-attention sont coûteux en termes de calcul et de mémoire, en particulier pour les tâches vidéo. Pour l’efficacité et le traitement conjoint des images et des vidéos, l’équipe calcule l’auto-attention de manière fenêtrée sur la base de deux types de configurations qui ne se chevauchent pas : l’espace (S) et l’espace-temps (ST), voir Figure 2. L'attention de la fenêtre spatiale (SW) se concentre sur tous les jetons dans un cadre caché. SW modélise les relations spatiales dans les images et les vidéos. La portée de l'attention de la fenêtre spatio-temporelle (STW) est une fenêtre 3D qui modélise la relation temporelle entre les images cachées de la vidéo. Enfin, en plus de l’intégration de position absolue, ils ont également utilisé l’intégration de position relative. Selon les rapports, bien que cette conception soit simple, elle est très efficace sur le plan informatique et peut être formée conjointement sur des ensembles de données d'images et de vidéos. Contrairement aux méthodes basées sur des encodeurs automatiques au niveau de l'image, la nouvelle méthode ne produit pas d'artefacts de scintillement, un problème courant avec les méthodes qui encodent et décodent les images vidéo séparément. Génération conditionnelle
Afin de réaliser une génération vidéo contrôlable, en plus du pas de temps t comme condition, le modèle de diffusion utilise également souvent des informations conditionnelles supplémentaires c, telles que les étiquettes de catégorie, le langage naturel, les images passées. ou vidéo basse résolution. Dans le réseau fédérateur Transformer récemment proposé, l'équipe a intégré trois types de mécanismes conditionnels, comme décrit ci-dessous :
Attention croisée. En plus d'utiliser des couches d'auto-attention dans les blocs Transformer fenêtrés, ils ont également ajouté des couches d'attention croisée pour la génération conditionnelle de texte. Lors de la formation du modèle avec uniquement des vidéos, la couche d'attention croisée utilise la même attention restreinte à la fenêtre que la couche d'auto-attention, ce qui signifie que S/ST aura une couche d'attention croisée SW/STW (Figure 2). Cependant, pour la formation conjointe, seule la couche d’attention croisée SW est utilisée. Pour l’attention croisée, l’approche de l’équipe consiste à concaténer les signaux d’entrée (requêtes) et les signaux conditionnels (clé, valeur).
AdaLN-LoRA. Les couches de normalisation adaptative sont des composants importants dans de nombreux modèles de synthèse générative et visuelle. Pour incorporer des couches de normalisation adaptative, une approche simple consiste à inclure une couche MLP pour chaque couche i qui régresse sur le vecteur de paramètres conditionnels. Le nombre de paramètres pour ces couches MLP supplémentaires augmente linéairement avec le nombre de couches et quadratiquement avec la dimensionnalité du modèle. Inspirés par LoRA, les chercheurs ont proposé une solution simple pour réduire les paramètres du modèle : AdaLN-LoRA.
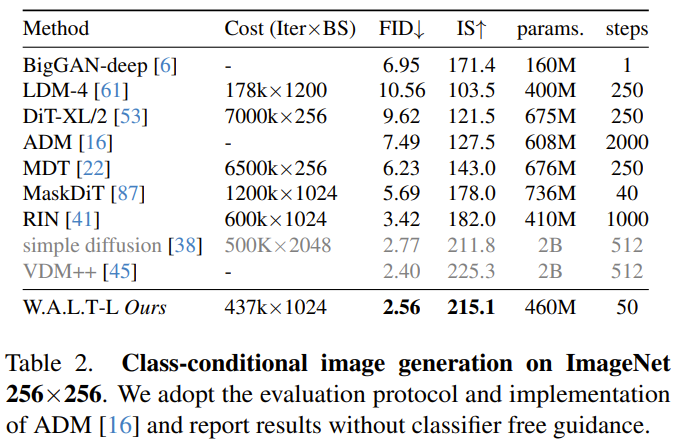
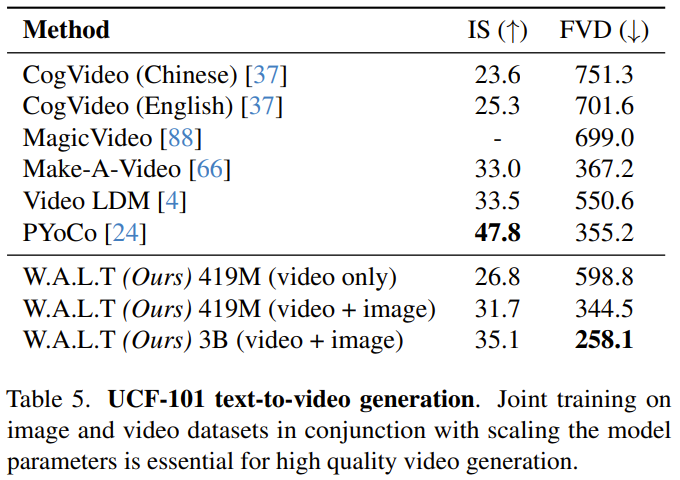
Auto-conditionnement. En plus d'être conditionnés sur des entrées externes, les algorithmes de génération itérative peuvent également être conditionnés sur les échantillons qu'ils génèrent lors de l'inférence. Plus précisément, Chen et al. cet échantillon initial, utilisez une autre passe avant pour affiner cette estimation. Il existe également une certaine probabilité que 1-p_sc n'effectue qu'une seule passe avant.L’équipe a concaténé cette estimation de modèle avec l’entrée le long de la dimension du canal et a constaté que cette technique simple fonctionnait bien en combinaison avec la prédiction v. Génération autorégressivePour générer de longues vidéos grâce à la prédiction autorégressive, l'équipe a également formé conjointement le modèle à la tâche de prédiction de trame. Ceci est réalisé en donnant au modèle une certaine probabilité p_fp conditionnée par les images passées pendant le processus de formation. La condition est soit 1 image cachée (génération d'image en vidéo), soit 2 images cachées (prédiction vidéo). Cette condition est intégrée dans le modèle par dimensions de canal le long de l'entrée implicite bruitée. L'amorçage standard sans classificateur est utilisé pendant l'inférence, avec c_fp comme signal conditionnel. Le coût de calcul lié à l'utilisation d'un seul modèle pour générer une vidéo haute résolution est très élevé et fondamentalement difficile à réaliser. Les chercheurs se réfèrent à l'article « Modèles de diffusion en cascade pour la génération d'images haute fidélité » et utilisent une méthode en cascade pour mettre en cascade les trois modèles, et ils fonctionnent à des résolutions de plus en plus élevées. Le modèle de base génère une vidéo à une résolution de 128 × 128, qui est ensuite suréchantillonnée deux fois à travers deux étapes de super-résolution. L'entrée basse résolution (vidéo ou image) est d'abord sur-échantillonnée spatialement à l'aide d'une opération de convolution profondeur-espace. Notez que contrairement à la formation (où une entrée de vérité terrain à basse résolution est fournie), l'inférence repose sur des représentations implicites générées lors des étapes précédentes. Pour réduire cette différence et gérer de manière plus robuste les artefacts produits au stade basse résolution au stade super-résolution, l'équipe a également utilisé l'amélioration conditionnelle du bruit. Réglage précis du rapport hauteur/largeur. Pour simplifier la formation et exploiter davantage de sources de données avec différents formats d'image, ils ont utilisé un format d'image carré dans l'étape de base. Ils ont ensuite affiné le modèle sur un sous-ensemble de données pour générer des vidéos au format 9:16 via une interpolation d'intégration positionnelle. Les chercheurs ont évalué la méthode nouvellement proposée sur diverses tâches : génération d'images et de vidéos conditionnées par catégories, prédiction d'images, génération de vidéos basées sur du texte. Ils ont également exploré les effets de différents choix de conception au moyen d’études sur l’ablation. Génération vidéo : sur les ensembles de données UCF-101 et Kinetics-600, W.A.L.T surpasse toutes les méthodes précédentes sur la métrique FVD, voir le tableau 1. Génération d'images : le tableau 2 compare les résultats de W.A.L.T avec d'autres meilleures méthodes actuelles pour générer des images de résolution 256 × 256. Le modèle nouvellement proposé surpasse les méthodes précédentes et ne nécessite pas de planification spécialisée, de biais d'induction convolutive, de perte de diffusion améliorée et de guidage sans classificateur. Bien que VDM++ ait un score FID légèrement plus élevé, il possède beaucoup plus de paramètres de modèle (2B). Pour comprendre la contribution des différentes décisions de conception, l'équipe a également mené une étude sur l'ablation. Le tableau 3 présente les résultats de l'étude d'ablation en termes de taille de patch, d'attention de fenêtre, d'autoconditionnement, d'AdaLN-LoRA et d'auto-encodeurs. Génération de texte en vidéo L'équipe a formé conjointement les capacités de génération de texte en vidéo de W.A.L.T sur des paires texte-image et texte-vidéo. Ils ont utilisé un ensemble de données provenant de l’Internet public et de sources internes contenant environ 970 millions de paires texte-image et environ 89 millions de paires texte-vidéo. La résolution du modèle de base (3B) est de 17×128×128, et les deux modèles super-résolution en cascade sont de 17×128×224 → 17×256×448 (L, 1,3B, p = 2 ) et 17× 256×448→ 17×512×896 (L, 419M, p = 2). Ils ont également affiné le rapport hauteur/largeur dans l’étage de base pour produire des vidéos à une résolution de 128×224. Tous les résultats de génération de texte en vidéo utilisent une approche d'amorçage sans classificateur. Vous trouverez ci-dessous quelques exemples de vidéos générées. Pour en savoir plus, veuillez visiter le site Web du projet : Texte : Un écureuil mangeant un hamburger.
Texte : Un chat chevauchant un cycliste fantôme à travers le désert .
Évaluer la génération de vidéos textuelles de manière scientifique reste un défi, en partie à cause du manque d'ensembles de données et de références de formation standardisés. Jusqu'à présent, les expériences et analyses des chercheurs se sont concentrées sur des références académiques standards, qui utilisent les mêmes données de formation pour garantir des comparaisons équitables. Néanmoins, à des fins de comparaison avec les études précédentes sur la génération de texte en vidéo, l'équipe rapporte les résultats sur l'ensemble de données UCF-101 dans un cadre d'évaluation zéro-shot. On voit que les avantages de W.A.L.T sont évidents. Veuillez vous référer au document original pour plus de détails. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!