
Maison >Périphériques technologiques >IA >Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.
Cet article résume les méthodes classiques et la comparaison des effets de l'amélioration et de la personnalisation des fonctionnalités dans l'estimation du CTR.

- PHPzavant
- 2023-12-15 09:23:02979parcourir
Dans l'estimation du CTR, la méthode traditionnelle utilise l'intégration de fonctionnalités + MLP, dans lesquels les fonctionnalités sont très critiques. Cependant, pour les mêmes caractéristiques, la représentation est la même dans différents échantillons. Cette façon de saisir le modèle en aval limitera la capacité d'expression du modèle.
Afin de résoudre ce problème, une série de travaux connexes ont été proposés dans le domaine de l'estimation du CTR, appelés module d'amélioration des fonctionnalités. Le module d'amélioration des fonctionnalités corrige les résultats de sortie de la couche d'intégration en fonction de différents échantillons pour s'adapter à la représentation des caractéristiques de différents échantillons et améliorer la capacité d'expression du modèle.
Récemment, l'Université de Fudan et Microsoft Research Asia ont publié conjointement une revue des travaux d'amélioration des fonctionnalités, comparant les méthodes de mise en œuvre et les effets des différents modules d'amélioration des fonctionnalités. Présentons maintenant les méthodes de mise en œuvre de plusieurs modules d'amélioration des fonctionnalités, ainsi que les expériences comparatives associées menées dans cet article
 Titre de l'article : Résumé et évaluation complets des modules de raffinement des fonctionnalités pour la prédiction du CTR
Titre de l'article : Résumé et évaluation complets des modules de raffinement des fonctionnalités pour la prédiction du CTR
Adresse de téléchargement : https :// arxiv.org/pdf/2311.04625v1.pdf
1. Idée de modélisation d'amélioration des fonctionnalités
Le module d'amélioration des fonctionnalités est conçu pour améliorer la capacité d'expression de la couche d'intégration dans le modèle de prédiction CTR et réaliser une différenciation des représentations du mêmes caractéristiques sous différents échantillons. Le module d'amélioration des fonctionnalités peut être exprimé par la formule unifiée suivante, saisir l'intégration d'origine et, après avoir transmis une fonction, générer l'intégration personnalisée de cet exemple.
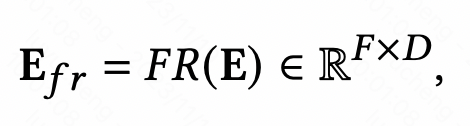 Images
Images
L'idée générale de cette méthode est qu'après avoir obtenu l'intégration initiale de chaque fonctionnalité, utilisez la représentation de l'échantillon lui-même pour transformer l'intégration de fonctionnalités afin d'obtenir l'intégration personnalisée de l'échantillon actuel. Nous présentons ici quelques méthodes classiques de modélisation de modules d’amélioration des fonctionnalités.
2. Méthode classique d'amélioration des fonctionnalités
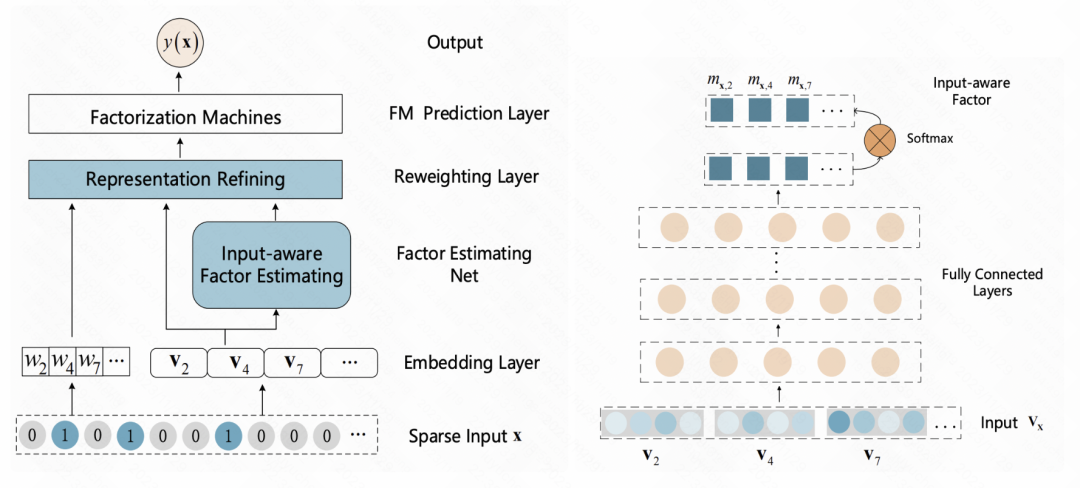
Une machine de factorisation sensible aux entrées pour la prédiction clairsemée (IJCAI 2019) Cet article ajoute une couche de repondération après la couche d'intégration et saisit l'intégration initiale de l'échantillon dans un MLP pour obtenir une représentation. de l'échantillon, normalisés à l'aide de softmax. Chaque élément après Softmax correspond à une fonctionnalité, représentant l'importance de cette fonctionnalité. Ce résultat softmax est multiplié par l'intégration initiale de chaque fonctionnalité correspondante pour obtenir une pondération d'intégration des fonctionnalités à la granularité de l'échantillon.
 Pictures
Pictures
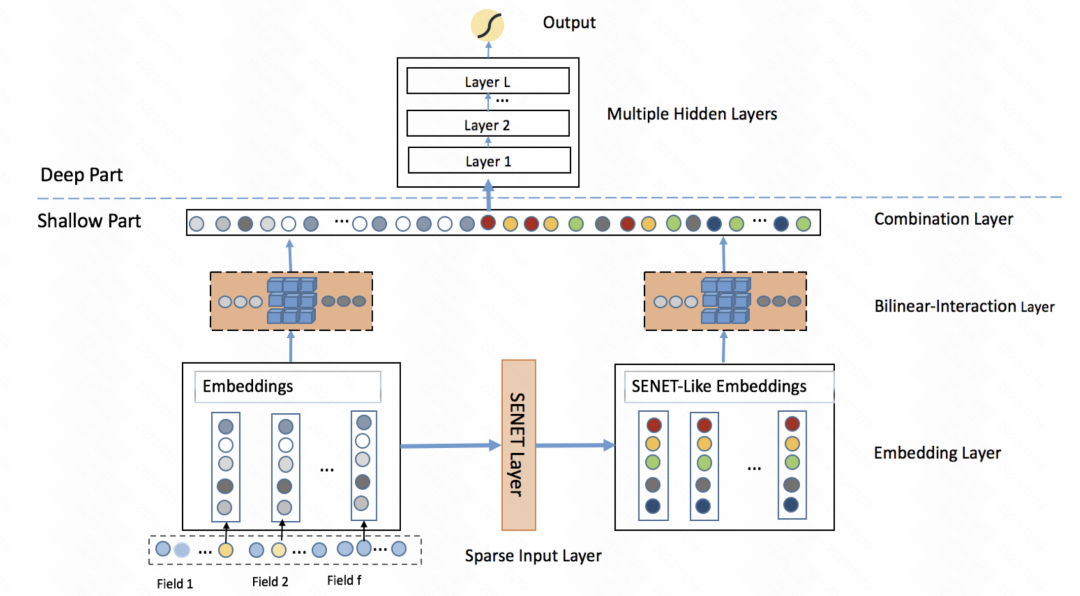
FiBiNET : un modèle de prédiction du taux de clics combinant l'importance des fonctionnalités et l'interaction des fonctionnalités de second ordre (RecSys 2019) adopte également une idée similaire. Le modèle apprend un poids personnalisé d'une caractéristique pour chaque échantillon. L'ensemble du processus est divisé en trois étapes : pressage, extraction et repondération. Lors de l'étape de compression, le vecteur d'intégration de chaque caractéristique est obtenu sous forme de scalaire statistique grâce à la méthode de pooling. Lors de l'étape d'extraction, ces scalaires sont entrés dans un perceptron multicouche (MLP) pour obtenir le poids de chaque caractéristique. Enfin, ces poids sont multipliés par le vecteur d'intégration de chaque caractéristique pour obtenir le résultat d'intégration pondéré, ce qui équivaut au filtrage de l'importance des caractéristiques au niveau de l'échantillon
 Image
Image
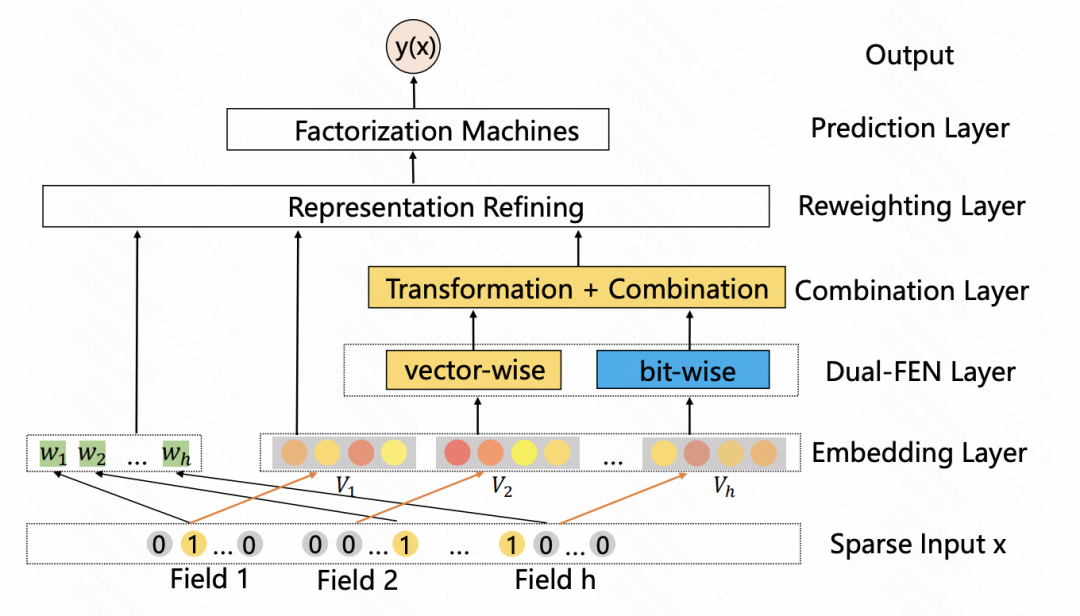
Une machine de factorisation à double entrée pour la prédiction du CTR ( IJCAI 2020) est similaire à l'article précédent, utilisant également l'auto-attention pour améliorer les fonctionnalités. Le tout est divisé en deux modules : vectoriel et bit-wise. Vector-wise traite l'intégration de chaque fonctionnalité comme un élément dans la séquence et l'entre dans le transformateur pour obtenir la représentation des fonctionnalités fusionnées ; la partie par bit utilise MLP multicouche pour mapper les fonctionnalités d'origine. Une fois les résultats d'entrée des deux parties ajoutés, le poids de chaque élément de fonctionnalité est obtenu et multiplié par chaque bit de la fonctionnalité d'origine correspondante pour obtenir la fonctionnalité améliorée.
 Image
Image
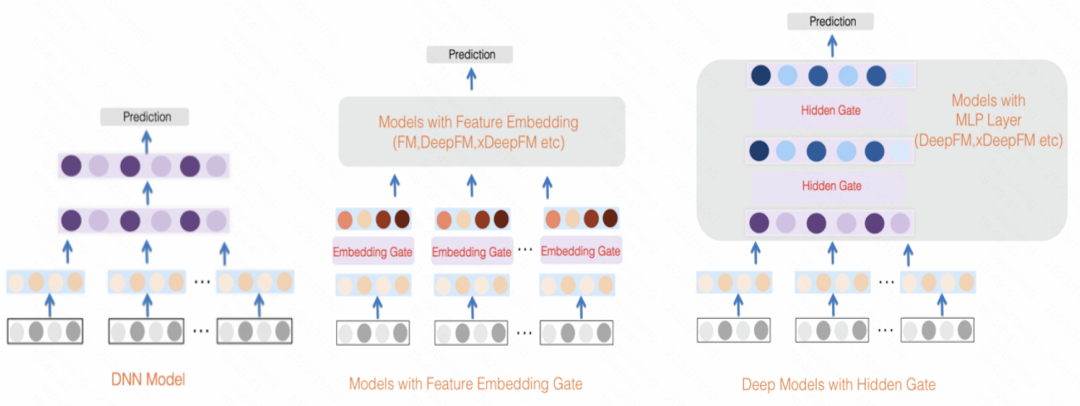
GateNet : Enhanced Gated Deep Network for Click-through Rate Prediction (2020) Utilise le vecteur d'intégration initial de chaque fonctionnalité pour générer son score de pondération de fonctionnalité indépendant via une fonction MLP et sigmoïde, tout en utilisant MLP pour combiner toutes les fonctionnalités sont mappées à des scores de pondération au niveau du bit, et les deux sont combinés pour pondérer les fonctionnalités d'entrée. En plus de la couche de fonctionnalités, dans la couche cachée de MLP, une méthode similaire est également utilisée pour pondérer l'entrée de chaque couche cachée
 image
image
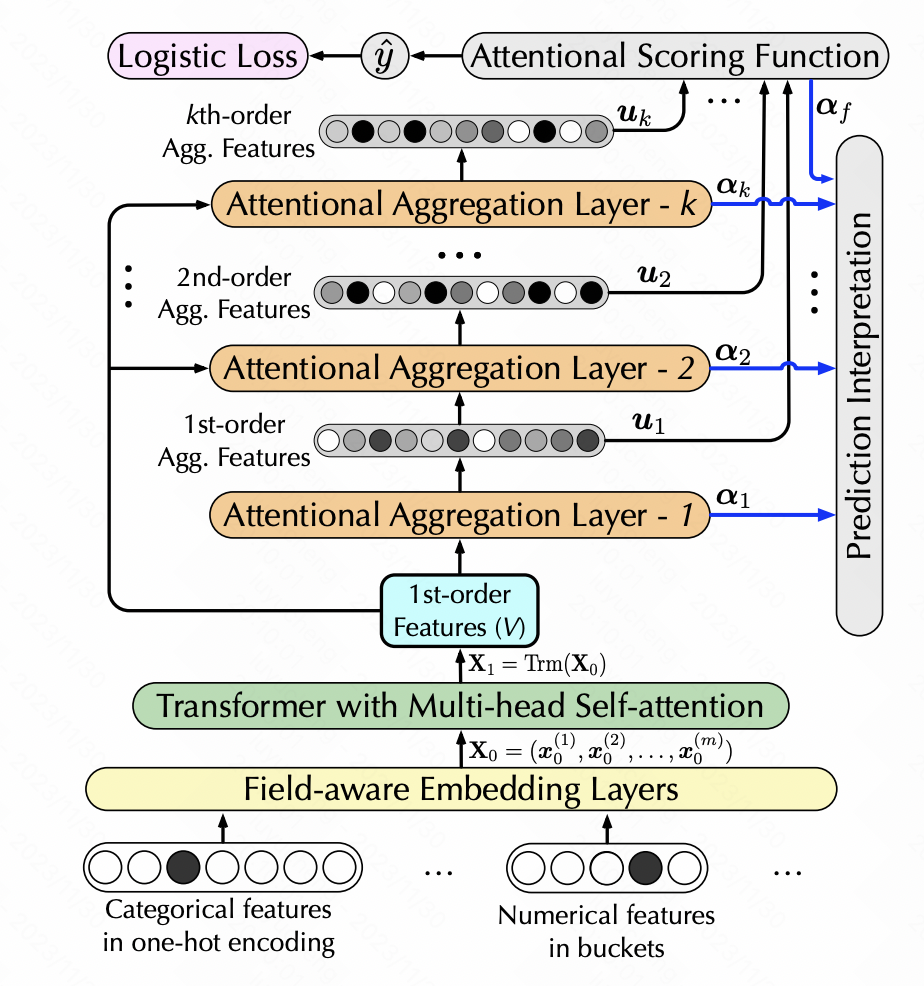
La prédiction interprétable du taux de clics via l'attention hiérarchique (WSDM 2020) utilise également l'auto-attention pour réaliser la conversion des fonctionnalités, mais ajoute la génération de fonctionnalités d'ordre élevé. L'auto-attention hiérarchique est utilisée ici.Chaque couche d'auto-attention prend comme entrée la sortie de la couche d'auto-attention précédente.Chaque couche ajoute une combinaison de caractéristiques de premier ordre pour obtenir une extraction hiérarchique de caractéristiques multi-ordres. Plus précisément, une fois que chaque couche a effectué une auto-attention, la nouvelle matrice de fonctionnalités générée est transmise via softmax pour obtenir le poids de chaque fonctionnalité. Les nouvelles fonctionnalités sont pondérées en fonction des poids des fonctionnalités d'origine, puis un produit scalaire est effectué. avec les caractéristiques originales pour obtenir une augmentation d'une caractéristique d'intersection des niveaux.
 Pictures
Pictures
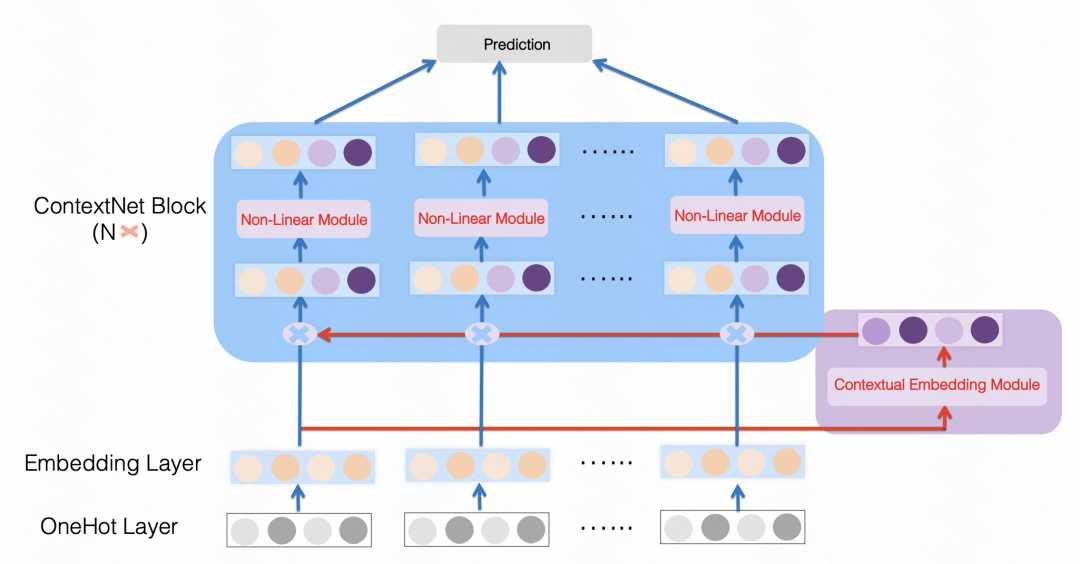
ContextNet : un cadre de prévision du taux de clics utilisant des informations contextuelles pour affiner l'intégration des fonctionnalités (2021) est également une approche similaire, utilisant un MLP pour mapper toutes les fonctionnalités dans une dimension de chaque taille d'intégration de fonctionnalités, par exemple Les fonctionnalités d'origine sont mises à l'échelle et des paramètres MLP personnalisés sont utilisés pour chaque fonctionnalité. De cette manière, chaque fonctionnalité est améliorée en utilisant d'autres fonctionnalités de l'échantillon comme bits supérieurs et inférieurs.
 Images
Images
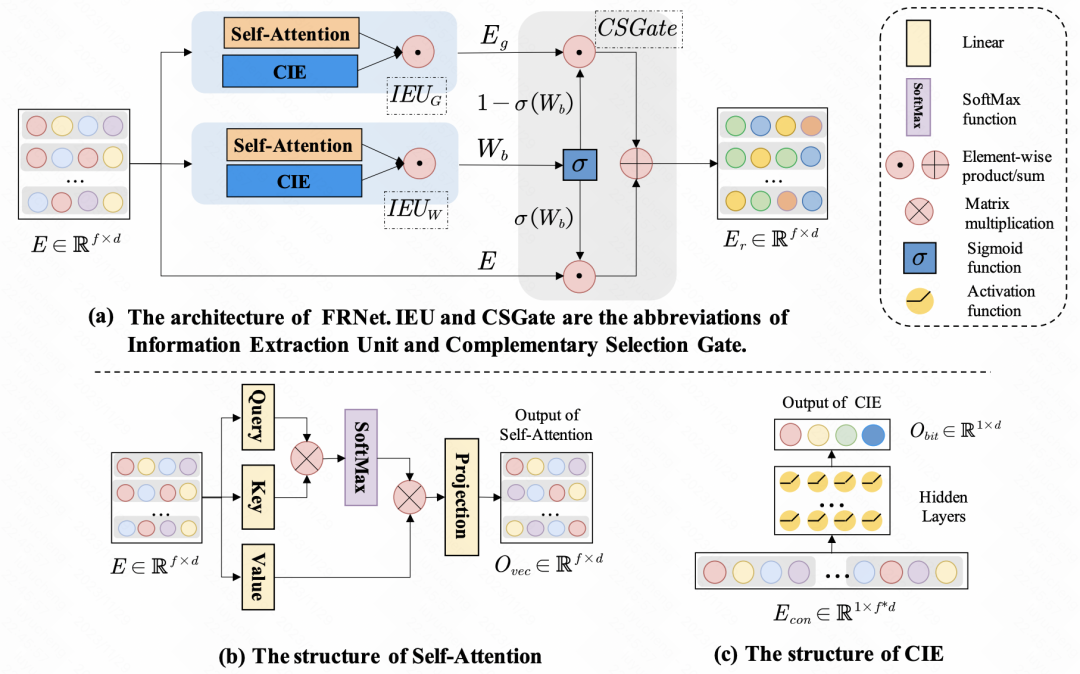
Amélioration de la prédiction du CTR avec l'apprentissage de la représentation des fonctionnalités contextuelle (SIGIR 2022) utilise l'auto-attention pour l'amélioration des fonctionnalités. Pour un ensemble de fonctionnalités d'entrée, le degré d'influence de chaque fonctionnalité sur d'autres fonctionnalités est différent. Grâce à l'auto-attention, l'auto-attention est effectuée sur l'intégration de chaque fonctionnalité pour obtenir une interaction d'informations entre les fonctionnalités au sein de l'échantillon. En plus de l'interaction entre les fonctionnalités, l'article utilise également MLP pour l'interaction des informations au niveau bit. La nouvelle intégration générée ci-dessus sera fusionnée avec l'intégration d'origine via un réseau de portes pour obtenir la représentation finale raffinée des fonctionnalités.
 Photos
Photos
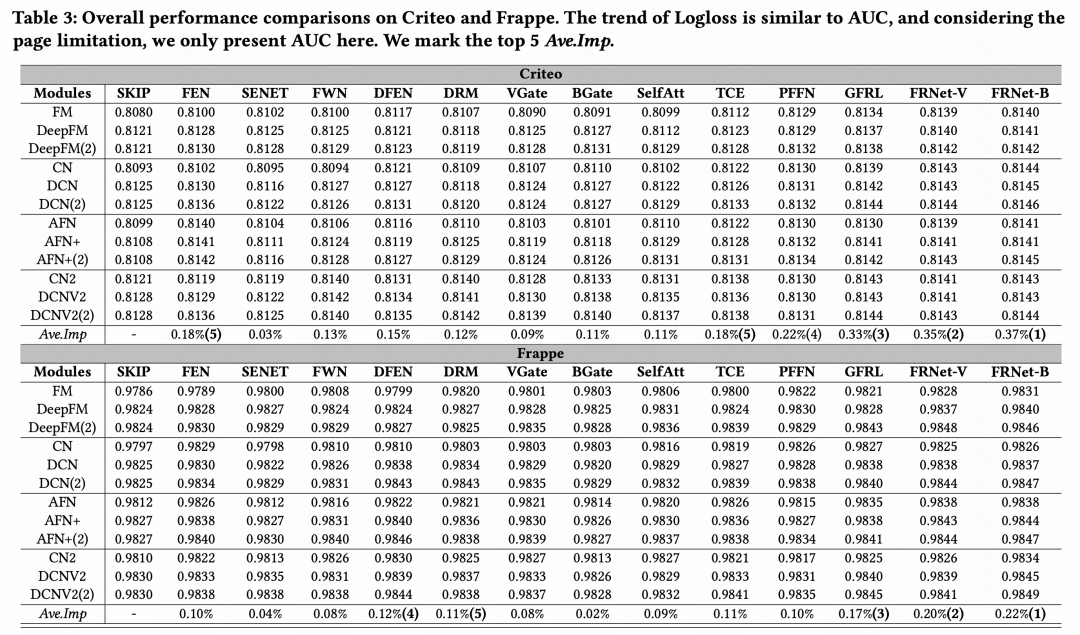
3. Résultats expérimentaux
Après avoir comparé les effets de diverses méthodes d'amélioration des fonctionnalités, nous sommes arrivés à la conclusion générale : parmi de nombreux modules d'amélioration des fonctionnalités, GFRL, FRNet-V et FRNetB sont les plus performants, et The l'effet est meilleur que les autres méthodes d'amélioration des fonctionnalités
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!