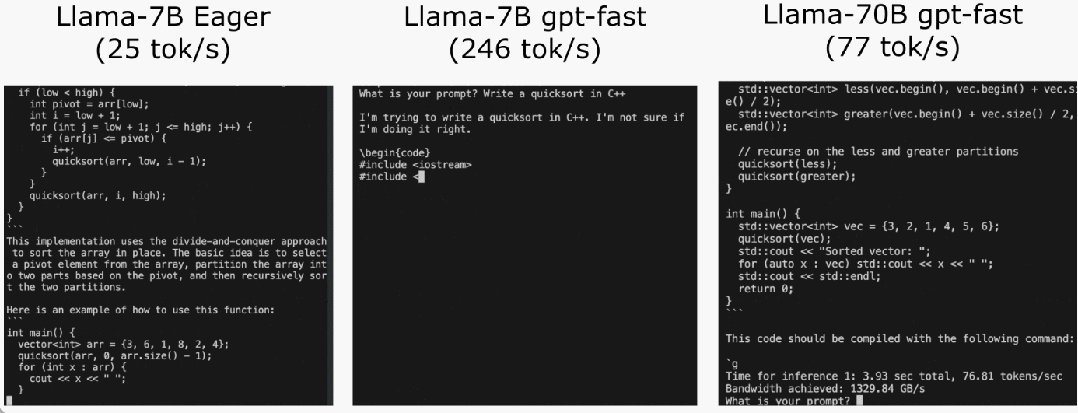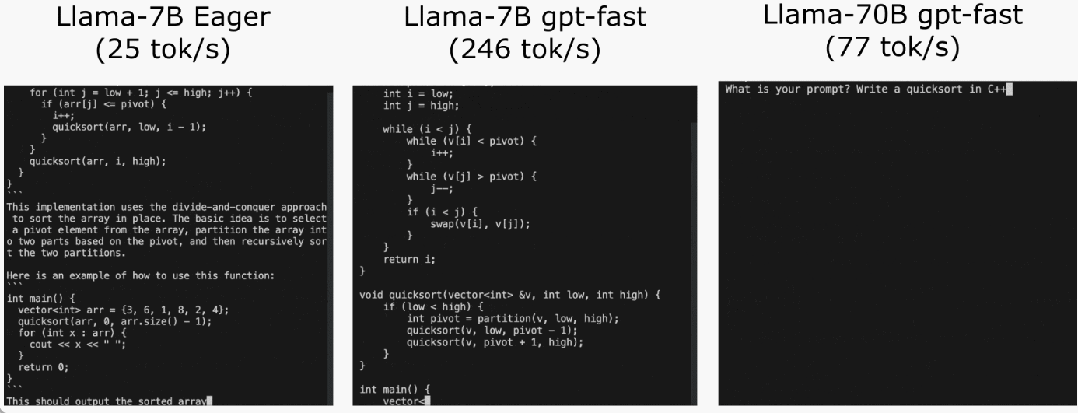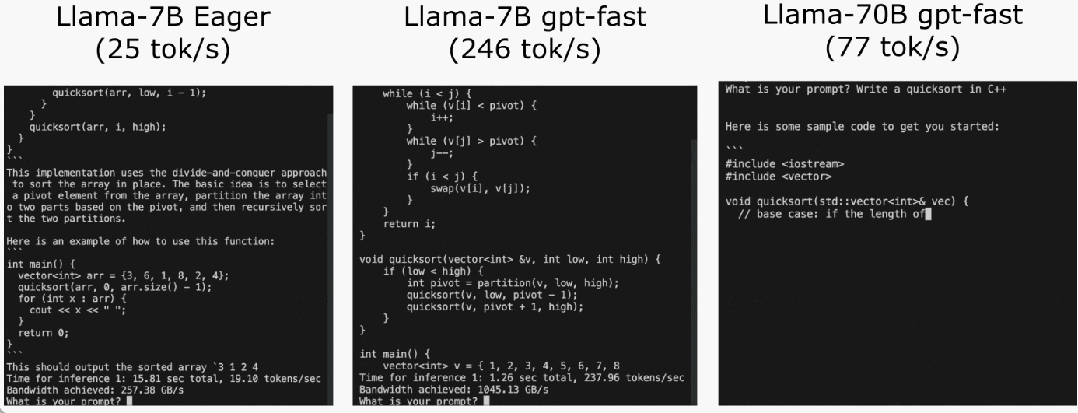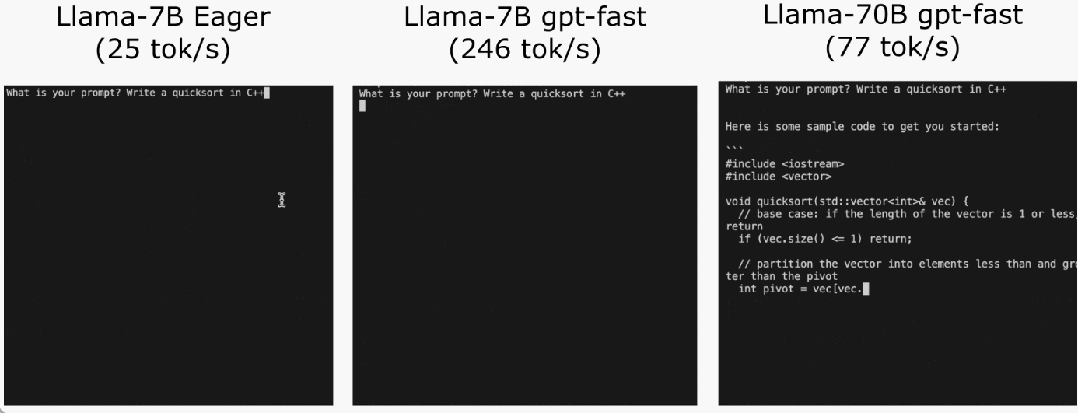
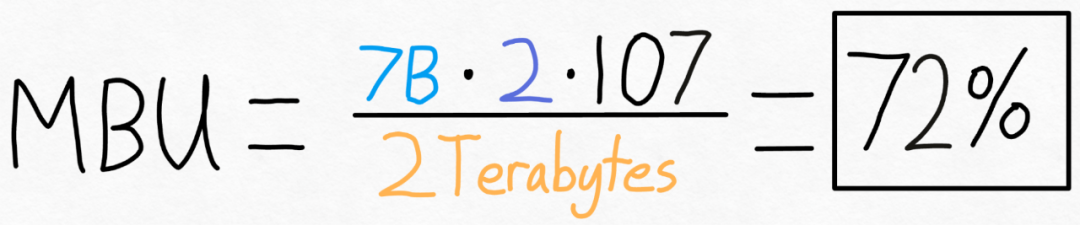L'équipe PyTorch vous apprend personnellement comment accélérer l'inférence de grands modèles.
Au cours de la dernière année, l'IA générative s'est développée rapidement. Parmi eux, la génération de texte a toujours été un domaine particulièrement populaire tels que lama.cpp, vLLM, MLC-LLM, etc. afin d'obtenir de meilleurs résultats, une optimisation continue est effectuée. En tant que l'un des frameworks les plus populaires dans la communauté du machine learning, PyTorch a naturellement saisi cette nouvelle opportunité et l'a continuellement optimisée. Pour aider chacun à mieux comprendre ces innovations, l'équipe PyTorch a spécialement mis en place une série de blogs pour se concentrer sur la façon d'utiliser PyTorch natif pur pour accélérer les modèles d'IA génératifs. 
Adresse du code : https://github.com/pytorch-labs/gpt-fast Jetons d'abord un coup d'œil aux résultats. L'équipe a réécrit LLM et la vitesse d'inférence était 10 fois plus rapide que la ligne de base sans perte de précision, en utilisant moins de 1000 lignes de code PyTorch natif pur !
Tous les benchmarks fonctionnent sur A100-80GB, puissance limitée à 330W. Ces optimisations incluent :
- Torch.compile : compilateur de modèles PyTorch, PyTorch 2.0 ajoute une nouvelle fonction appelée torch.compile (), qui peut compiler des modèles existants avec une seule ligne de code. Accélérer le modèle ;
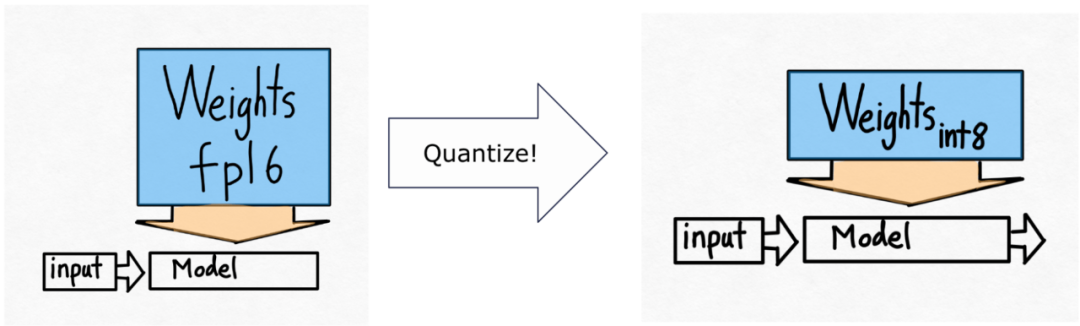
- Quantification GPU : accélère le modèle en réduisant la précision de calcul ;
- Décodage spéculatif : une méthode d'accélération d'inférence de grand modèle qui utilise un petit "projet" de modèle pour prédire de grandes "cibles" ;
- Tensor Parallel : accélérez l'inférence de modèle en exécutant le modèle sur plusieurs appareils.
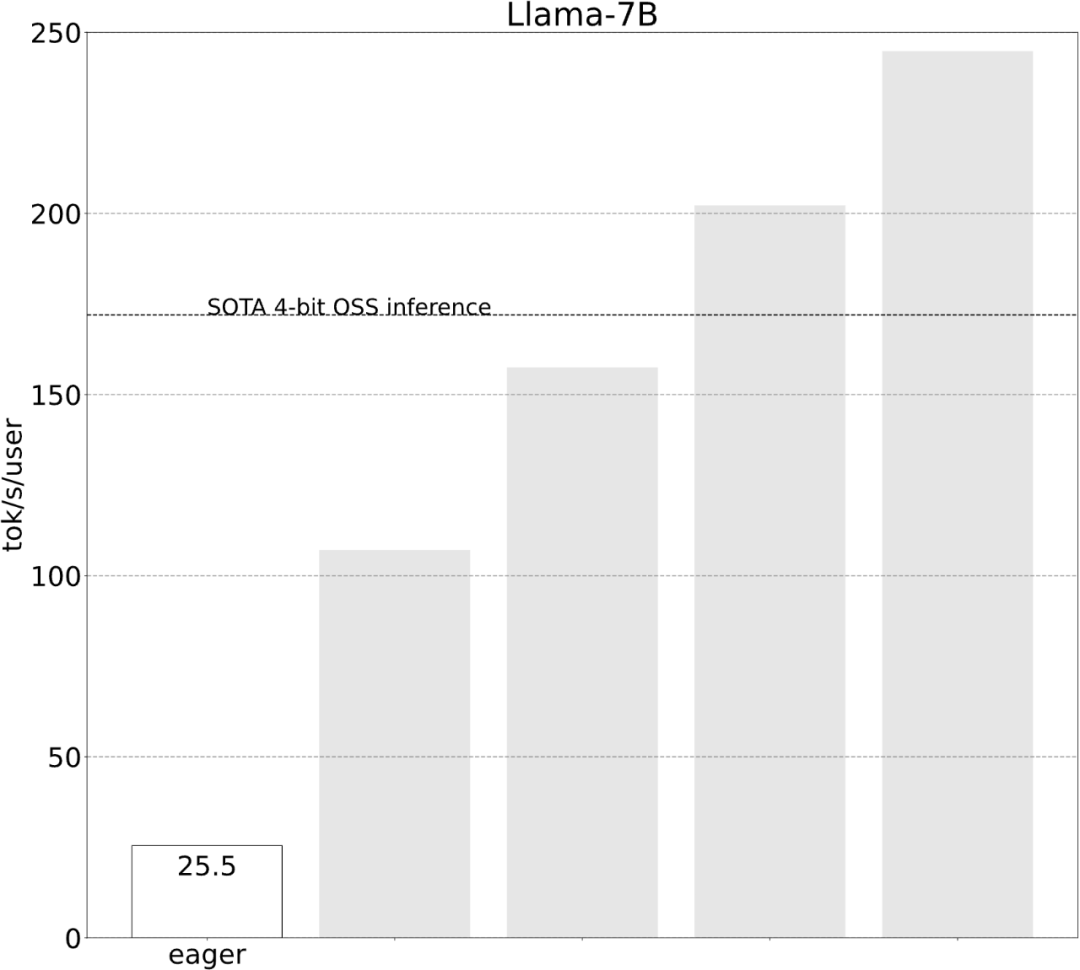
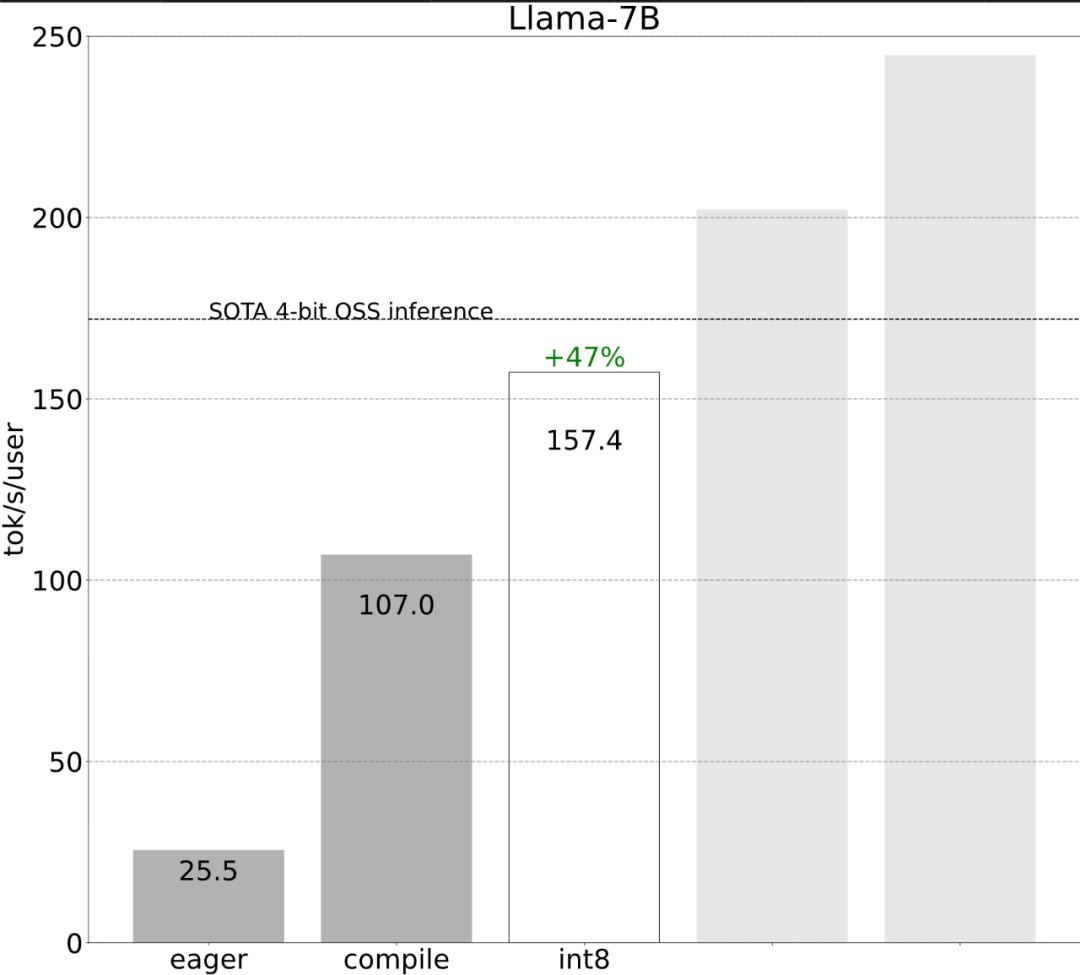
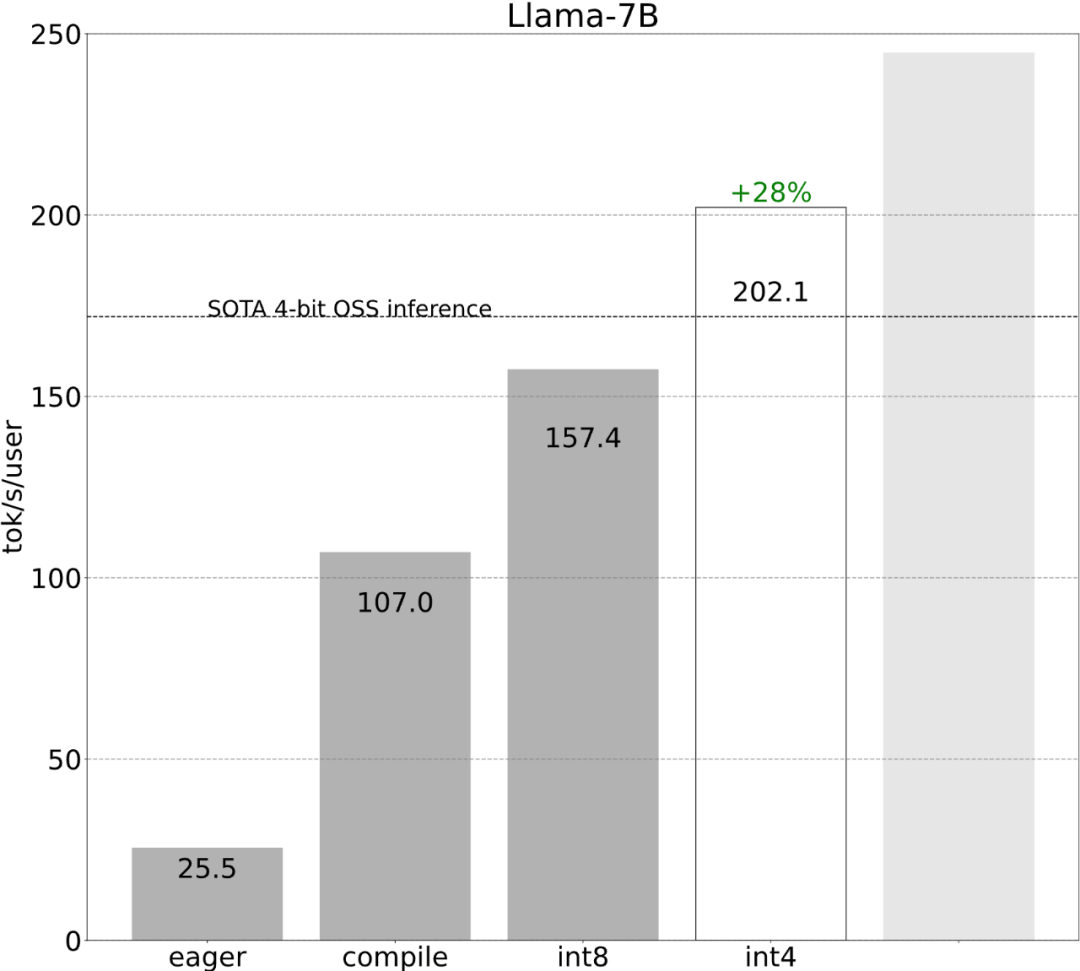
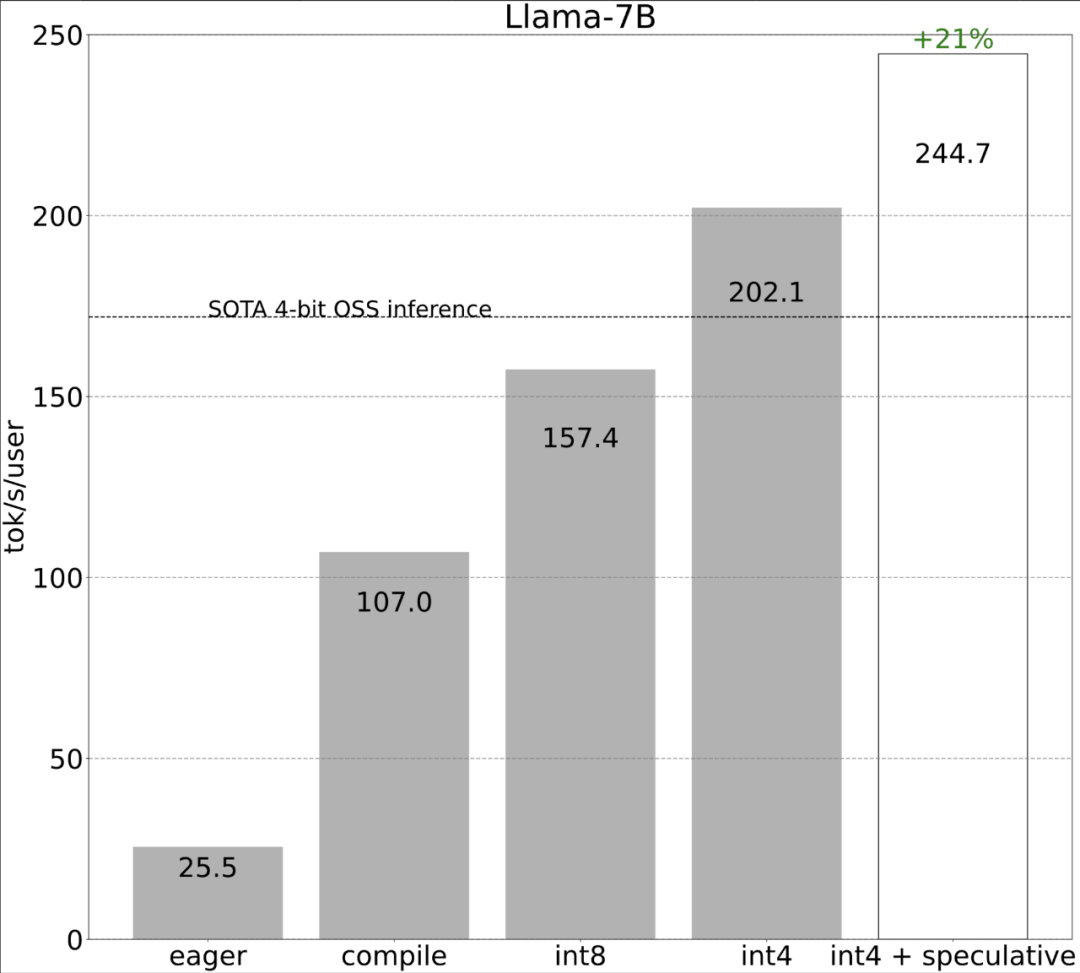
Voyons ensuite comment chaque étape est mise en œuvre. 6 étapes pour accélérer l'inférence du grand modèleL'étude montre qu'avant optimisation, la performance d'inférence du grand modèle est de 25,5 tok/s, ce qui n'est pas très bon :
Après quelques explorations, j'ai finalement trouvé la raison : une surcharge CPU excessive. Ensuite, il y a le processus d’optimisation en 6 étapes suivant.
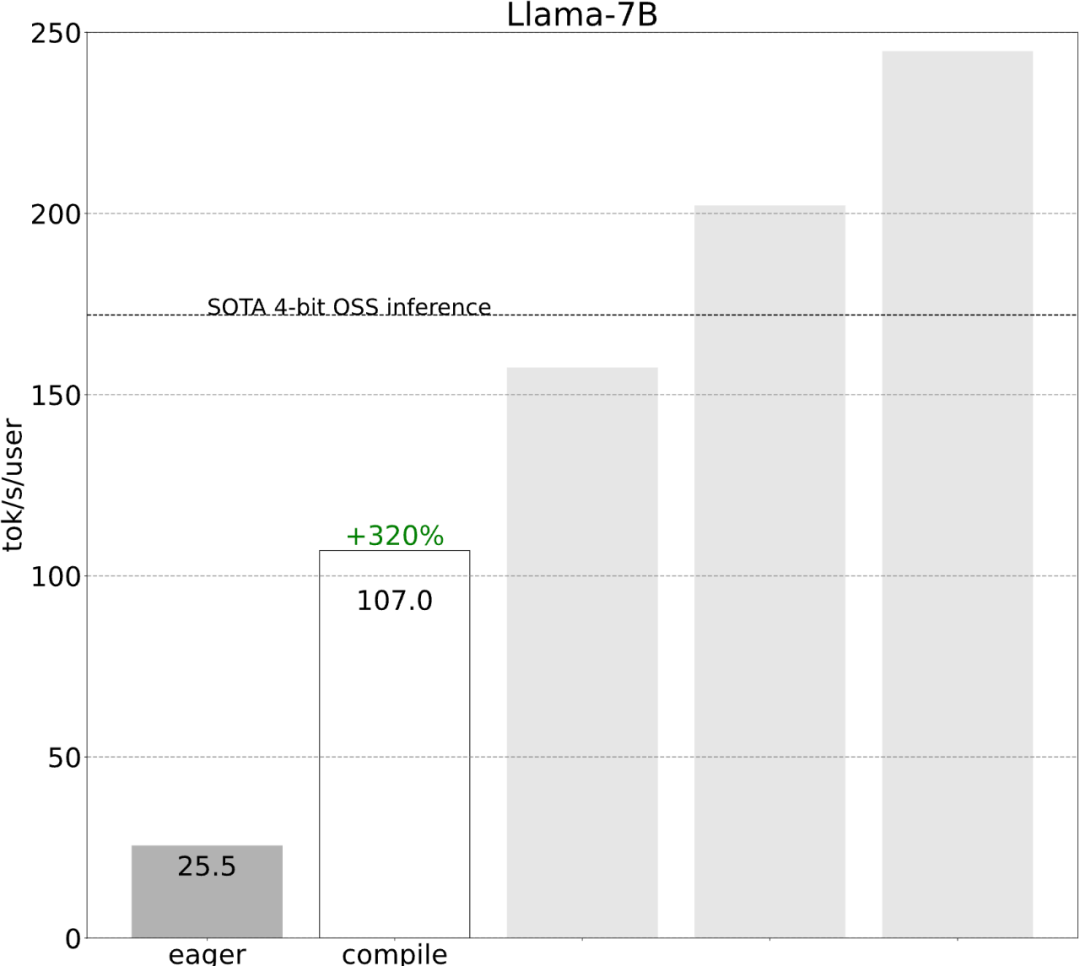
Étape 1 : Réduisez la surcharge du processeur avec Torch.compile et le cache KV statique pour atteindre 107,0 TOK/Storch.compile permet aux utilisateurs de capturer des régions plus grandes dans une seule région de compilation, en particulier en mode ="reduce-overhead" (reportez-vous au code ci-dessous), cette fonction est très efficace pour réduire la surcharge du processeur. De plus, cet article spécifie également fullgraph=True pour vérifier qu'il n'y a pas d'"interruption du graphique" dans le modèle (c'est-à-dire). , la partie que torch.compile ne peut pas compiler).
Cependant, même avec la bénédiction de torch.compile, il reste encore quelques obstacles. Le premier obstacle est le cache kv. Autrement dit, lorsque l'utilisateur génère plus de jetons, la « longueur logique » du cache kv augmente. Ce problème se produit pour deux raisons : premièrement, il est très coûteux de réaffecter (et de copier) le cache kv à chaque fois que le cache augmente ; deuxièmement, cette allocation dynamique rend plus difficile la réduction de la surcharge ; Afin de résoudre ce problème, cet article utilise un cache KV statique, alloue statiquement la taille du cache KV, puis masque les valeurs inutilisées dans le mécanisme d'attention.
Le deuxième obstacle est l'étape de pré-remplissage. La génération de texte avec Transformer peut être considérée comme un processus en deux étapes : 1. Étape de pré-remplissage pour traiter l'intégralité de l'invite 2. Décoder le jeton.Bien que le cache kv soit défini pour être statique, en raison de la longueur variable de l'invite, les étapes de pré-remplissage ont encore besoin de plus de dynamique. Par conséquent, des stratégies de compilation distinctes doivent être utilisées pour compiler ces deux étapes.
Bien que ces détails soient un peu délicats, ils ne sont pas difficiles à mettre en œuvre et les améliorations de performances sont énormes. Après cette opération, les performances ont été multipliées par plus de 4, passant de 25 tok/s à 107 tok/s.
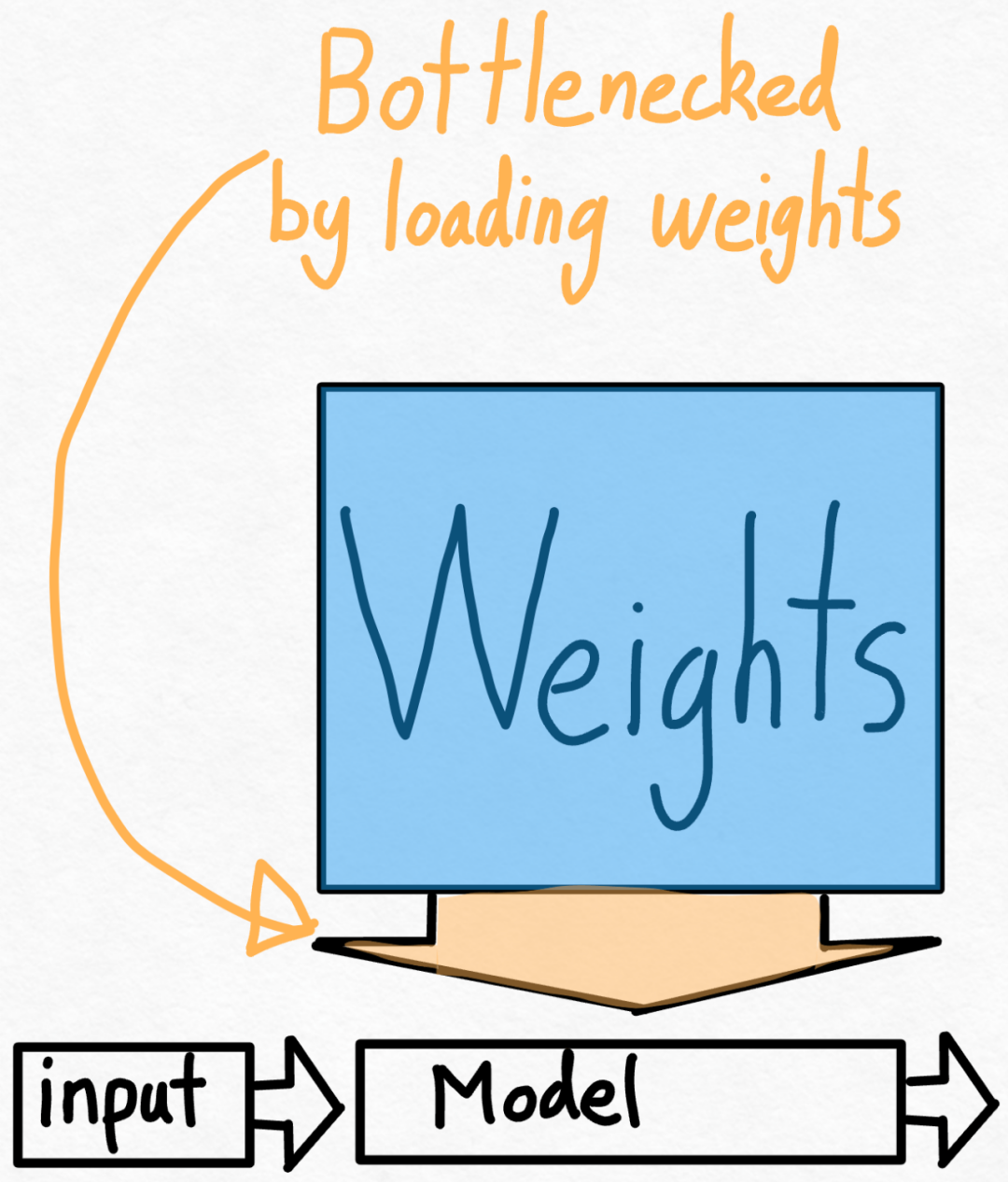
Étape 2 : Réduire le goulot d'étranglement de la bande passante mémoire grâce à la quantification du poids int8 et atteindre 157,4 tok/sGrâce à ce qui précède, nous avons vu l'impact apporté par l'application de torch.compile, le cache kv statique, etc. Énorme accélération, mais l'équipe PyTorch n'en était pas satisfaite et a trouvé d'autres angles d'optimisation. Ils pensent que le plus gros goulot d'étranglement dans l'accélération de la formation en IA générative est le coût de chargement des poids de la mémoire globale du GPU dans les registres. En d’autres termes, chaque passe avant doit « toucher » chaque paramètre du GPU. Alors, à quelle vitesse pouvons-nous théoriquement « accéder » à chaque paramètre du modèle ?
Pour mesurer cela, cet article utilise l'utilisation de la bande passante du modèle (MBU), son calcul est très simple comme suit :
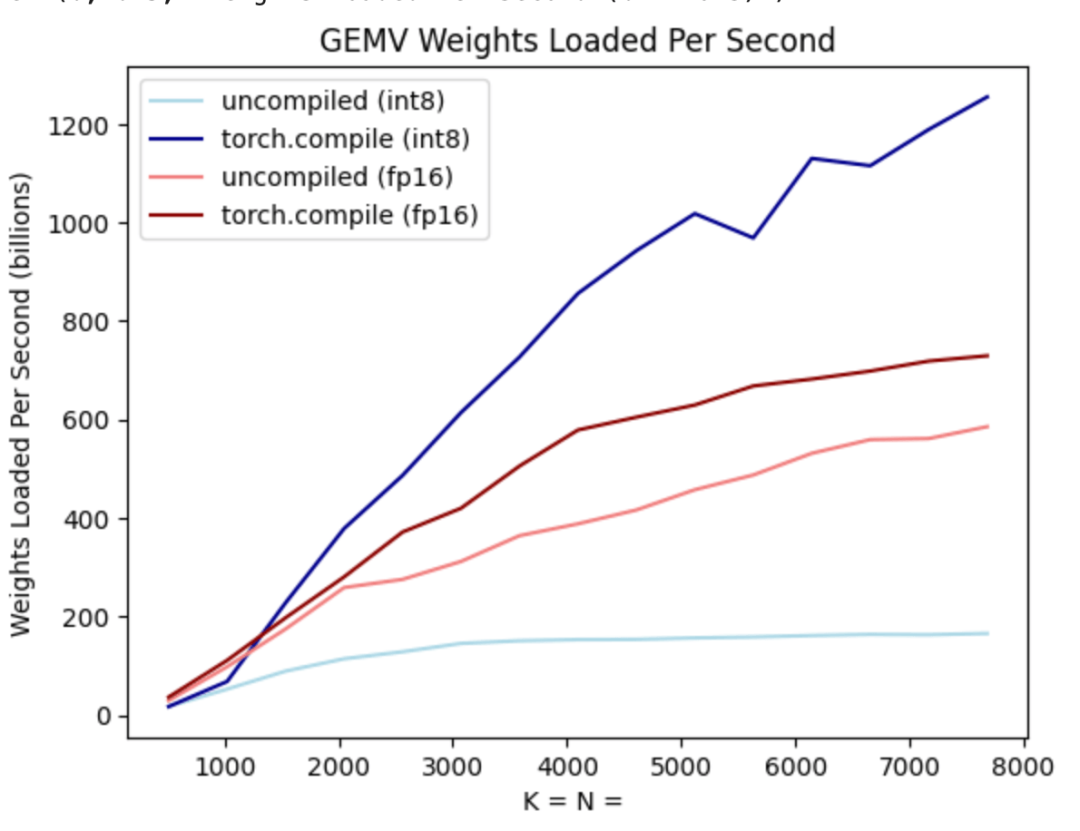
Par exemple, pour un modèle de paramètres 7B, chaque paramètre est stocké dans In fp16 (2 octets par paramètre), 107 jetons/s peuvent être atteints. L'A100-80GB dispose d'une bande passante mémoire théorique de 2 To/s. Comme le montre la figure ci-dessous, en mettant la formule ci-dessus dans des valeurs spécifiques, vous pouvez obtenir un MBU de 72 % ! Ce résultat est plutôt bon, car de nombreuses études ont du mal à dépasser les 85 %.
Mais l'équipe PyTorch souhaite également augmenter cette valeur. Ils ont constaté qu’ils ne pouvaient pas modifier le nombre de paramètres du modèle, ni la bande passante mémoire du GPU. Mais ils ont découvert qu’ils pouvaient modifier le nombre d’octets stockés pour chaque paramètre !
Donc, ils vont utiliser la quantification int8.
Veuillez noter qu'il ne s'agit que des poids quantifiés, le calcul lui-même est toujours effectué dans bf16. De plus, avec torch.compile, il est facile de générer du code efficace pour la quantification int8.
Comme le montre la figure ci-dessus, il peut être vu sur la ligne bleu foncé (torch.compile + int8) que lors de l'utilisation de torch.compile + int8 uniquement pour la quantification du poids, les performances sont considérablement améliorées. L'application de la quantification int8 au modèle Llama-7B améliore les performances d'environ 50 % à 157,4 jetons/s.
Étape 3 : Utiliser le décodage spéculatif
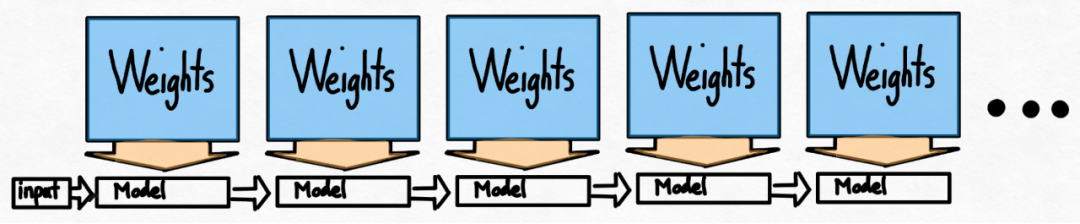
Même après avoir utilisé des techniques telles que la quantification int8, l'équipe était toujours confrontée à un autre problème, c'est-à-dire que pour générer 100 jetons, le poids 100 doit être chargé de second ordre.
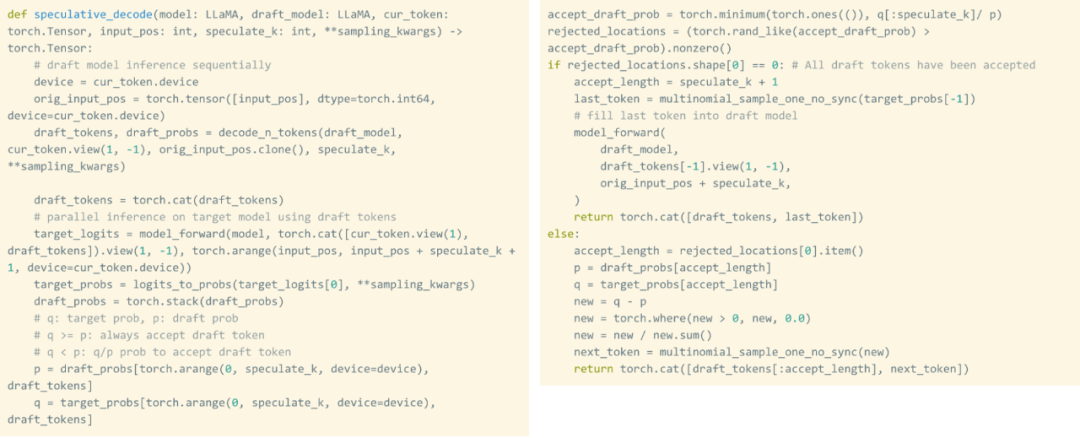
Même si les poids sont quantifiés, charger les poids encore et encore est inévitable. Comment résoudre ce problème ? Il s’avère que l’exploitation du décodage spéculatif peut briser cette stricte dépendance sérielle et accélérer le processus.
Cette étude utilise un projet de modèle pour générer 8 jetons, puis utilise un modèle de validation pour les traiter en parallèle, en éliminant les jetons sans correspondance. Ce processus rompt les dépendances série. L'ensemble de l'implémentation nécessite environ 50 lignes de code PyTorch natif.
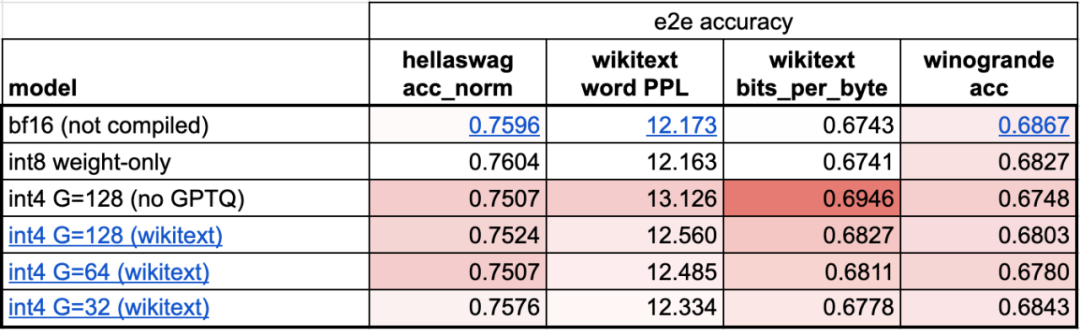
Étape 4 : Utilisez la quantification int4 et la méthode GPTQ pour réduire davantage le poids afin d'atteindre 202,1 tok/sCet article a révélé que lorsque le poids est de 4 bits, la précision du modèle commence diminuer.
Afin de résoudre ce problème, cet article utilise deux techniques pour le résoudre : la première consiste à avoir un facteur d'échelle plus fin ; l'autre consiste à utiliser une stratégie de quantification plus avancée. En combinant ces opérations ensemble, nous obtenons ce qui suit :
Étape 5 : En combinant le tout ensemble, nous obtenons 244,7 tok/sEnfin, combinez toutes les techniques ensemble pour vous améliorer La performance est de 244,7 tok /s.
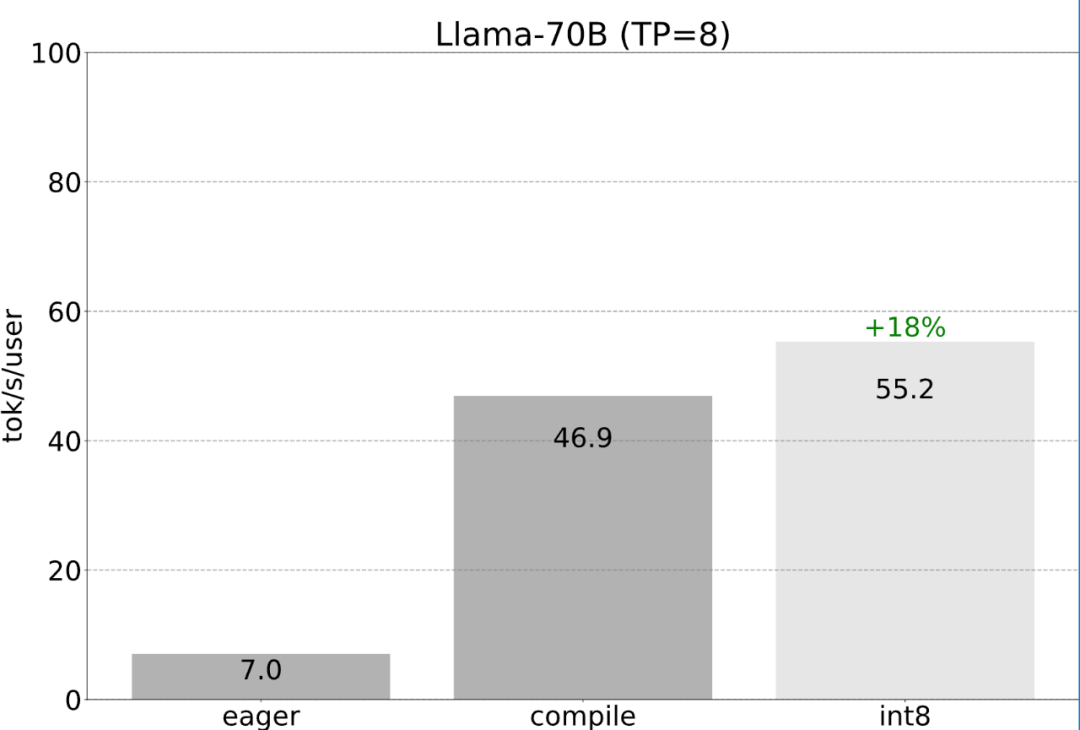
Étape six : Parallélisme tensoriel Jusqu'à présent, cet article a porté sur la minimisation de la latence sur un seul GPU. En fait, il est également possible d'utiliser plusieurs GPU, afin que la latence soit encore améliorée. Heureusement, l'équipe PyTorch fournit des outils de bas niveau pour le parallélisme tensoriel qui ne nécessitent que 150 lignes de code et ne nécessitent aucune modification de modèle.
Toutes les optimisations mentionnées précédemment peuvent continuer à être combinées avec le parallélisme tensoriel, qui fournissent ensemble une quantification int8 pour le modèle Llama-70B à 55 jetons/s.
Enfin, résumez brièvement le contenu principal de l'article. Sur Llama-7B, cet article utilise la combinaison « compilation + int4 quant + décodage spéculatif » pour atteindre plus de 240 tok/s. Sur Llama-70B, cet article introduit également le parallélisme tensoriel pour atteindre environ 80 tok/s, ce qui est proche ou supérieur aux performances SOTA. Lien original : https://pytorch.org/blog/accelerating-generative-ai-2/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!