
Maison >Périphériques technologiques >IA >'Sujet Trois' qui attire l'attention du monde entier : Messi, Iron Man et les femmes bidimensionnelles peuvent le gérer facilement
'Sujet Trois' qui attire l'attention du monde entier : Messi, Iron Man et les femmes bidimensionnelles peuvent le gérer facilement

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-03 11:25:271115parcourir
Ces derniers temps, vous avez peut-être entendu plus ou moins parler du "Sujet 3", qui consiste à agiter les mains, à mi-entrejambe et à associer une musique rythmée. Ce mouvement de danse a été imité par tout Internet.
Que se passerait-il si des danses similaires étaient générées par l'IA ? Comme le montre l’image ci-dessous, les gens modernes et les gens du papier effectuent des mouvements uniformes. Ce que vous ne devinerez peut-être pas, c'est qu'il s'agit d'une vidéo de danse générée à partir d'une image.

Les mouvements des personnages deviennent plus difficiles, et la vidéo générée est également très fluide (extrême droite) :

Il est facile de faire bouger Messi et Iron Man :
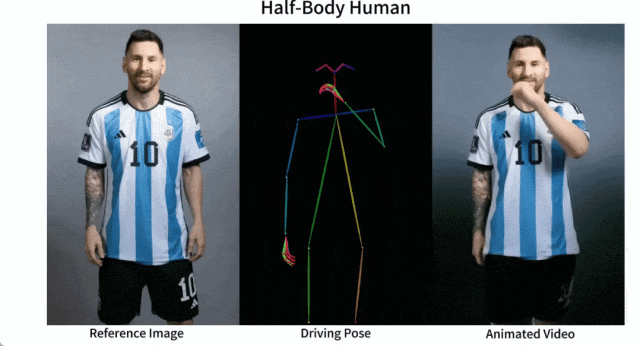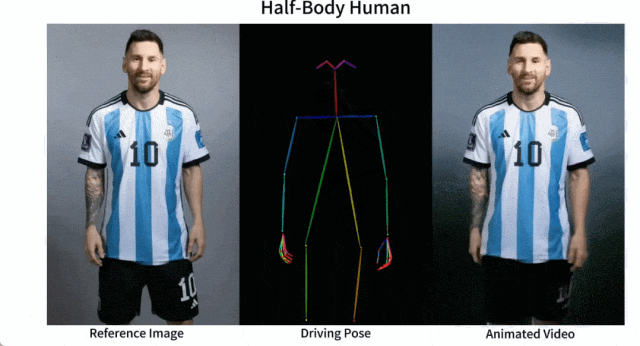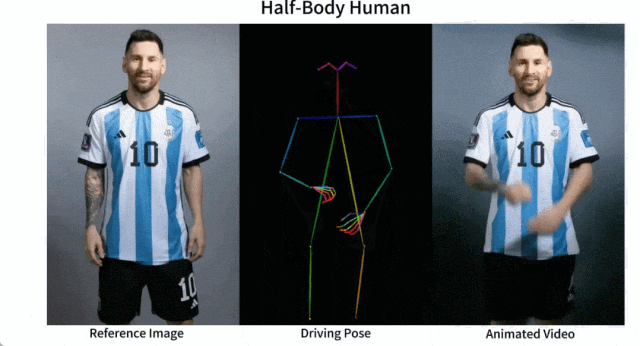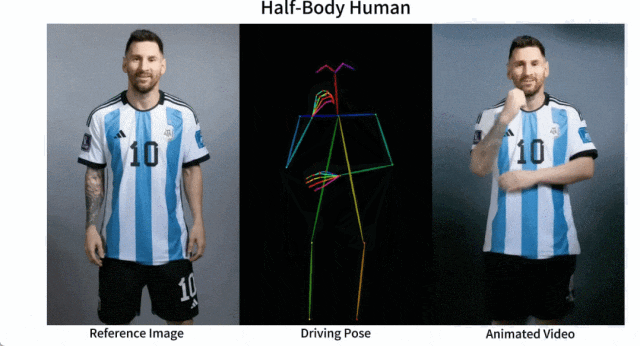
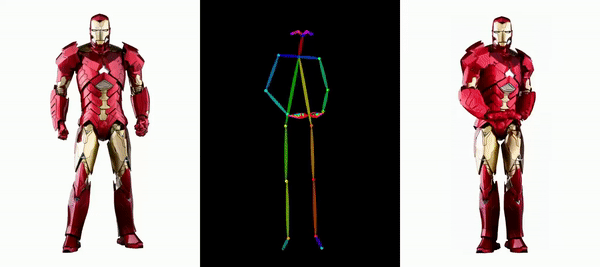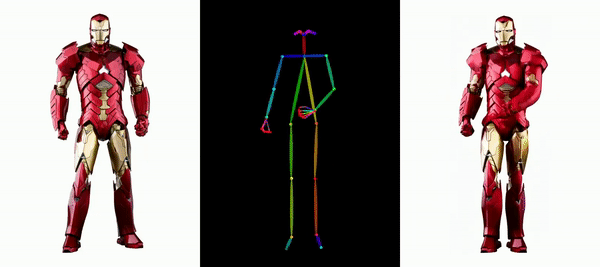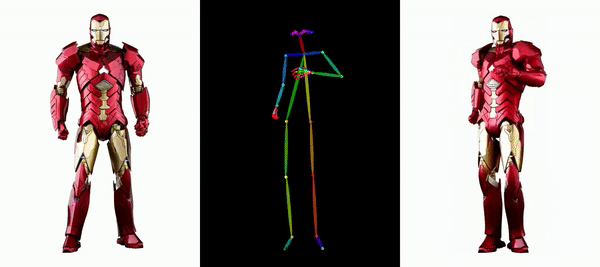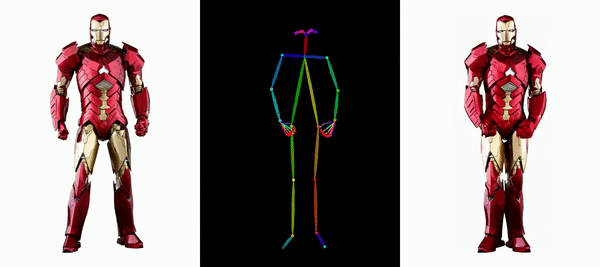
Il y a aussi diverses filles d'anime.

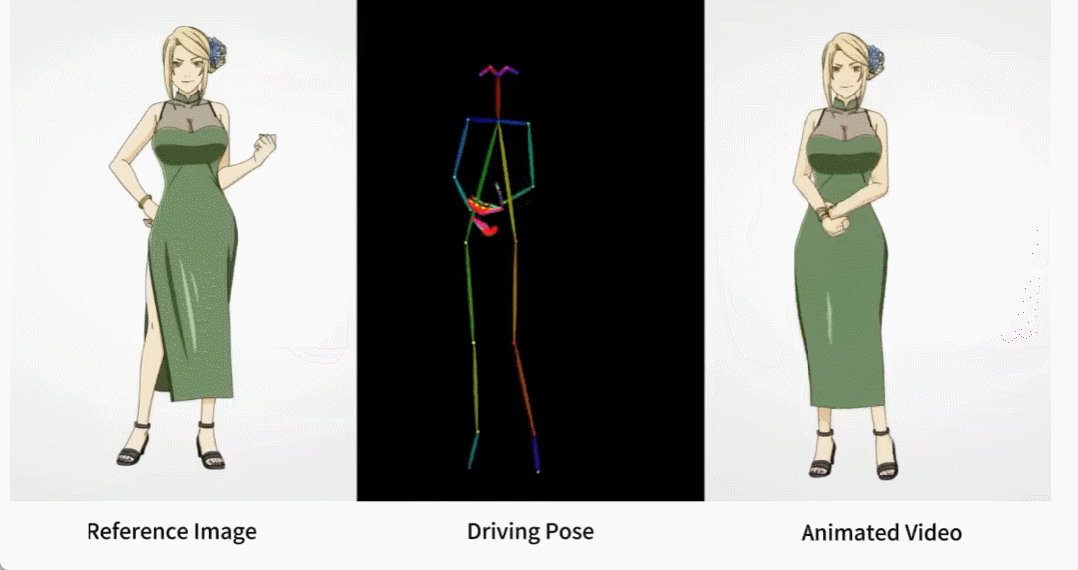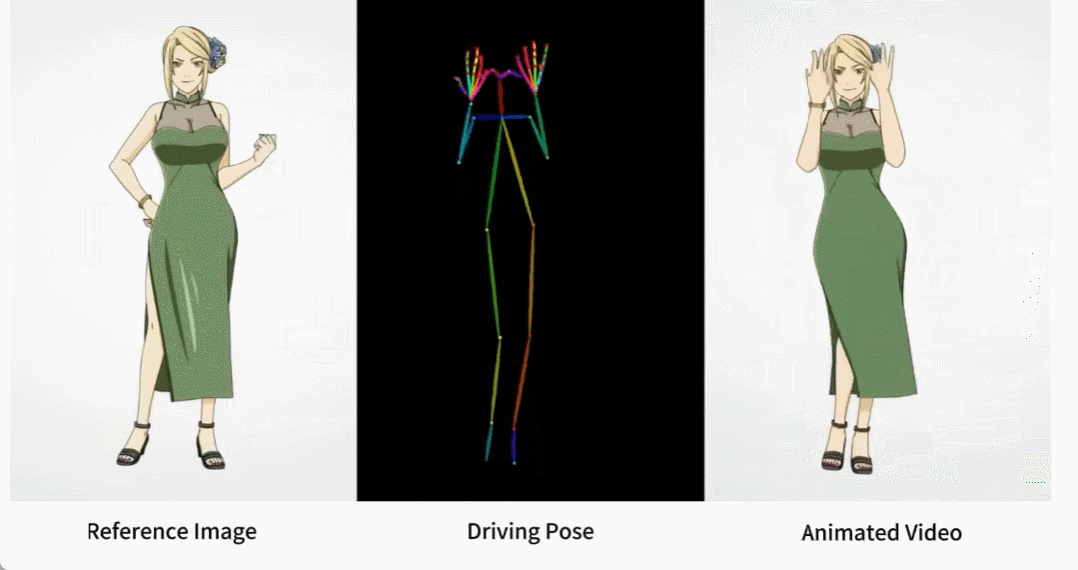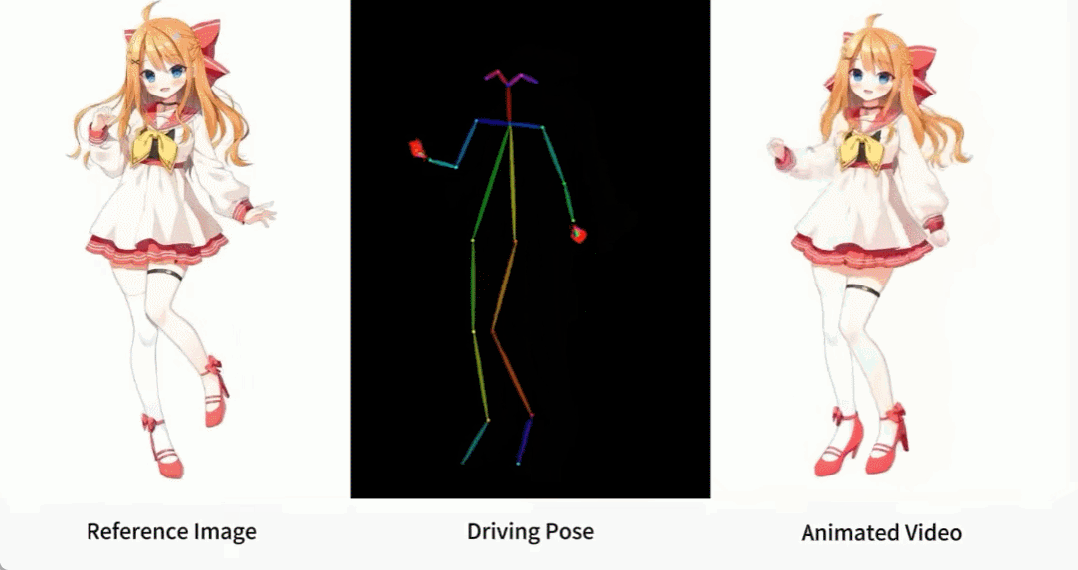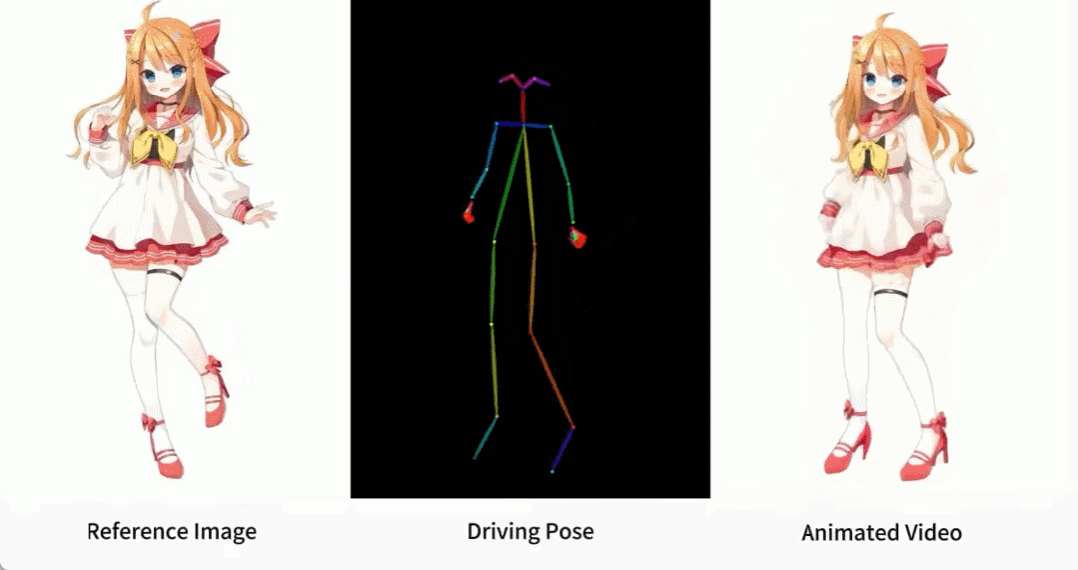
Comment ces effets sont-ils obtenus ? Continuons la lecture
L'animation de personnages est le processus de conversion des images originales de personnages en vidéos réalistes dans la séquence de poses souhaitée. Cette tâche a de nombreux domaines d'application potentiels, tels que la vente au détail en ligne, les vidéos de divertissement, la création artistique et les personnages virtuels, etc.
Depuis l'avènement de la technologie GAN, les chercheurs explorent continuellement en profondeur la conversion d'images en animations et en complétion. de la méthode de transfert de pose. Cependant, les images ou vidéos générées présentent encore certains problèmes, tels qu'une distorsion locale, des détails flous, une incohérence sémantique et une instabilité temporelle, qui entravent l'application de ces méthodes.
Les chercheurs d'Ali ont proposé une méthode appelée Animate Anybody qui convertit les images de personnages. en vidéos animées qui suivent la séquence de poses souhaitée. Cette étude a adopté la conception du réseau Stable Diffusion et les poids pré-entraînés, et a modifié le débruitage UNet pour s'adapter à l'entrée multi-trame

- Adresse papier : https://arxiv.org/pdf/2311.17117. pdf
- Adresse du projet : https://humanaigc.github.io/animate-anyone/
Afin de maintenir une apparence cohérente, l'étude a introduit ReferenceNet. Le réseau adopte une structure UNet symétrique et vise à capturer les détails spatiaux de l’image de référence. Dans chaque couche de bloc UNet correspondante, cette étude utilise un mécanisme d'attention spatiale pour intégrer les fonctionnalités de ReferenceNet dans l'UNet de débruitage. Cette architecture permet au modèle d'apprendre de manière exhaustive la relation avec l'image de référence dans un espace de fonctionnalités cohérent.
Pour garantir le contrôle de la pose, cette étude a conçu un guide de pose léger pour contrôler efficacement la pose. Le signal est intégré dans le processus de débruitage. Afin d'obtenir une stabilité temporelle, cet article introduit une couche temporelle pour modéliser la relation entre plusieurs images, conservant ainsi les détails haute résolution de la qualité visuelle tout en simulant un processus de mouvement temporel continu et fluide.
Animate Anybody a été formé sur un ensemble de données interne de clips vidéo de 5 000 personnages, comme le montre la figure 1, montrant les résultats d'animation de différents personnages. Par rapport aux méthodes précédentes, la méthode présentée dans cet article présente plusieurs avantages évidents :
- Tout d'abord, il maintient efficacement la cohérence spatiale et temporelle de l'apparence des personnages de la vidéo.
- Deuxièmement, les vidéos haute définition qu'il génère n'auront pas de problèmes tels que la gigue temporelle ou le scintillement.
- Troisièmement, il est capable d'animer n'importe quelle image de personnage dans une vidéo sans être limité par un champ spécifique.
Cet article est évalué sur deux références spécifiques de synthèse vidéo humaine (UBC Fashion Video Dataset et TikTok Dataset). Les résultats montrent qu'Animate Anybody atteint les résultats SOTA. De plus, l'étude a comparé la méthode Animate Anybody avec des méthodes générales de conversion d'image en vidéo formées sur des données à grande échelle, montrant qu'Animate Anybody démontre des capacités supérieures en matière d'animation de personnages.

Animate Anybody Comparaison avec d'autres méthodes :

Introduction à la méthode
La méthode de traitement de cet article est présentée dans la figure 2. L'entrée originale du réseau est composé de bruit multi-trame. Afin d'obtenir l'effet de débruitage, les chercheurs ont adopté une configuration basée sur la conception SD, utilisant le même cadre et les mêmes unités de blocs, et héritant des poids d'entraînement de SD. Plus précisément, cette méthode comprend trois parties clés, à savoir :
- ReferenceNet, qui encode les caractéristiques d'apparence du personnage dans l'image de référence ;
- Pose Guider (guide de posture), qui encode les signaux de contrôle d'action pour obtenir une contrôlabilité ; Mouvement du personnage ;
- Couche temporelle (couche temporelle), codant les relations temporelles pour assurer la continuité des actions des personnages.
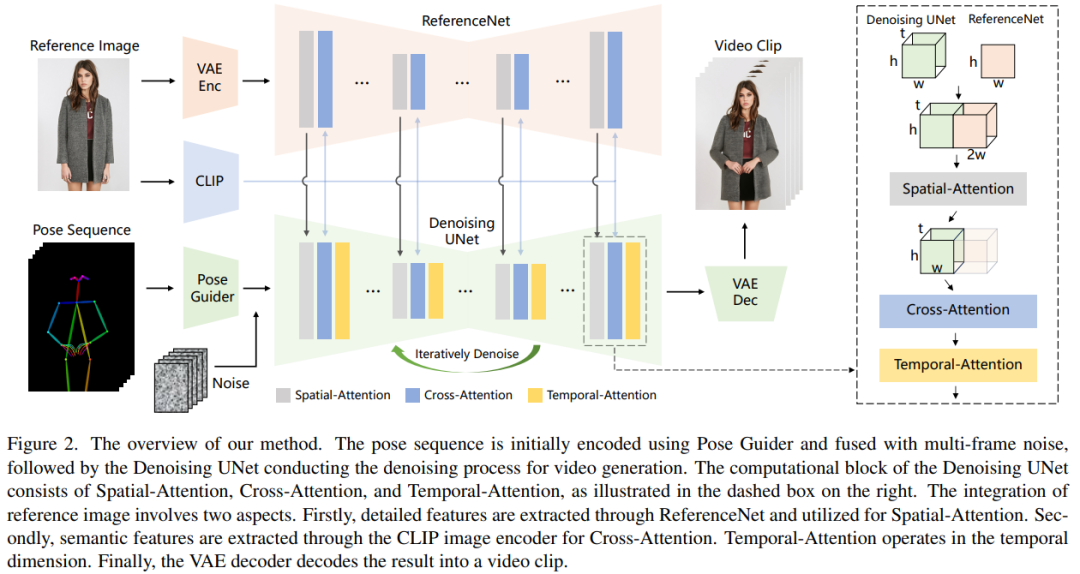
ReferenceNet
ReferenceNet est un réseau d'extraction de caractéristiques d'image de référence, son cadre est à peu près le même que le débruitage UNet, seule la couche temporelle est différente. Par conséquent, ReferenceNet hérite des poids SD d'origine similaires à UNet de débruitage, et chaque mise à jour de poids est effectuée indépendamment. Les chercheurs expliquent comment intégrer les fonctionnalités de ReferenceNet dans le débruitage UNet.
ReferenceNet est conçu avec deux avantages. Premièrement, ReferenceNet peut exploiter les capacités de modélisation de caractéristiques d'image pré-entraînées du SD brut pour produire des caractéristiques bien initialisées. Deuxièmement, étant donné que ReferenceNet et le débruitage UNet ont essentiellement la même structure de réseau et les mêmes poids d'initialisation partagés, le débruitage UNet peut apprendre sélectivement les fonctionnalités associées dans le même espace de fonctionnalités à partir de ReferenceNet.
Posture Guider
Le contenu réécrit est le suivant : Ce guide de posture léger utilise quatre couches convolutives (noyau 4 × 4, foulée 2 × 2), et le nombre de canaux est respectivement de 16, 32, 64. , 128, similaire à l'encodeur conditionnel de [56], utilisé pour aligner les images de pose avec la même résolution que le bruit sous-jacent. L'image de pose traitée est ajoutée au bruit latent, puis entrée dans l'UNet de débruitage pour traitement. Le guide de pose est initialisé avec des poids gaussiens et utilise des convolutions nulles dans la couche de cartographie finale
Couche temporelle
La conception de la couche temporelle est inspirée d'AnimateDiff. Pour une carte de caractéristiques x∈R^b×t×h×w×c, le chercheur la déforme d'abord en x∈R^(b×h×w)×t×c, puis effectue une attention temporelle, c'est-à-dire le long de L'attention personnelle dans la dimension t. Les caractéristiques de la couche temporelle sont fusionnées avec les caractéristiques d'origine via des connexions résiduelles. Cette conception est cohérente avec la méthode de formation en deux étapes ci-dessous. Les couches temporelles sont utilisées exclusivement dans le bloc Res-Trans du débruitage UNet.
Stratégie de formation
Le processus de formation est divisé en deux étapes.
Contenu réécrit : Dans la première étape de la formation, une seule image vidéo est utilisée pour la formation. Dans le modèle UNet de débruitage, les chercheurs ont temporairement exclu la couche temporelle et ont pris le bruit d'une seule image comme entrée. Parallèlement, le réseau de référence et le guide d'attitude sont également formés. Les images de référence sont sélectionnées au hasard dans l’ensemble du clip vidéo. Ils ont utilisé des poids pré-entraînés pour initialiser les modèles de débruitage UNet et ReferenceNet. Le guide de pose est initialisé avec des poids gaussiens, à l'exception de la couche de projection finale, qui utilise zéro convolution. Les poids de l'encodeur et du décodeur VAE et de l'encodeur d'image CLIP restent inchangés. L'objectif d'optimisation de cette étape est de générer des images animées de haute qualité compte tenu de l'image de référence et de la pose cible.
Dans la deuxième étape, les chercheurs ont introduit la couche temporelle dans le modèle précédemment formé et ont utilisé AnimateDiff pour pré-initialiser le modèle formé. poids. L'entrée du modèle consiste en un clip vidéo de 24 images. A ce stade, seule la couche temporelle est entraînée, tandis que les poids des autres parties du réseau sont fixes.
Expériences et résultats
Résultats qualitatifs : comme le montre la figure 3, cette méthode peut produire des animations de n'importe quel personnage, y compris des portraits complets, des portraits en demi-longueur, des personnages de dessins animés et des personnages humanoïdes. Cette méthode est capable de produire des détails humains réalistes et en haute définition. Il maintient une cohérence temporelle avec l'image de référence et présente une continuité temporelle d'une image à l'autre, même en présence de mouvements importants.

Synthèse vidéo de mode. L'objectif de la synthèse vidéo de mode est de transformer des photos de mode en vidéos animées réalistes à l'aide de séquences de poses pilotées. Les expériences sont menées sur l'ensemble de données vidéo de mode de l'UBC, qui comprend 500 vidéos de formation et 100 vidéos de test, chacune contenant environ 350 images. Les comparaisons quantitatives sont présentées dans le tableau 1. Les résultats montrent que la méthode présentée dans cet article est meilleure que les autres méthodes, notamment dans les indicateurs de mesure vidéo, montrant une nette avance.
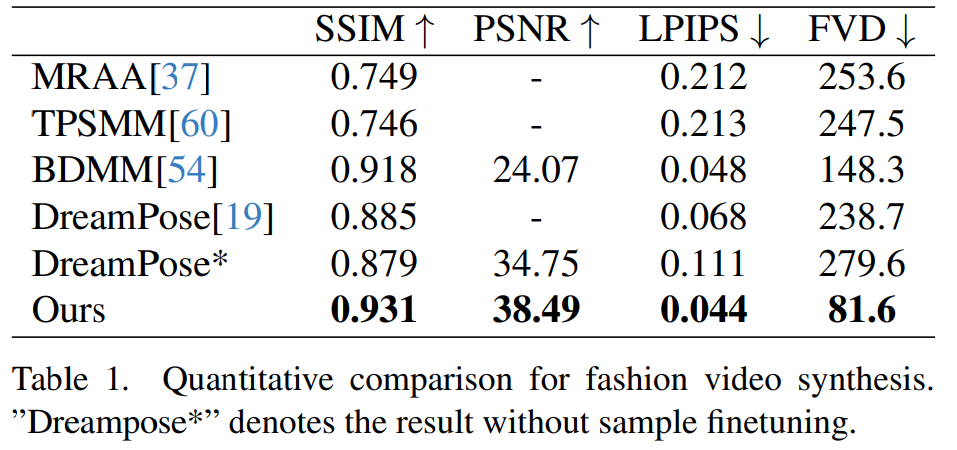
La comparaison qualitative est présentée dans la figure 4. Pour une comparaison équitable, les chercheurs ont utilisé le code open source de DreamPose pour obtenir des résultats sans peaufiner les échantillons. Dans le domaine des vidéos de mode, les exigences en matière de détails vestimentaires sont très strictes. Cependant, les vidéos générées par DreamPose et BDMM ne parviennent pas à maintenir la cohérence des détails des vêtements et présentent des erreurs significatives dans la couleur et les éléments structurels fins. En revanche, les résultats générés par cette méthode permettent de maintenir plus efficacement la cohérence des détails des vêtements.

Human dance Generation est une étude dont le but est de générer de la danse humaine en animant des images de scènes de danse réalistes. Les chercheurs ont utilisé l’ensemble de données TikTok, qui comprend 340 vidéos de formation et 100 vidéos de test. Ils ont effectué une comparaison quantitative en utilisant le même ensemble de tests, qui comprenait 10 vidéos de style TikTok, en suivant la méthode de partitionnement des ensembles de données de DisCo. Comme le montre le tableau 2, la méthode décrite dans cet article donne les meilleurs résultats. Afin d'améliorer la capacité de généralisation du modèle, DisCo combine le pré-entraînement des attributs humains et utilise un grand nombre de paires d'images pour pré-entraîner le modèle. En revanche, d'autres chercheurs se sont formés uniquement sur l'ensemble de données TikTok, mais les résultats étaient toujours meilleurs que ceux de DisCo
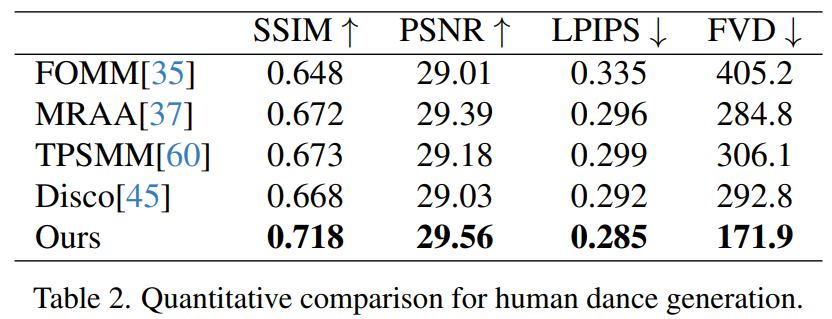
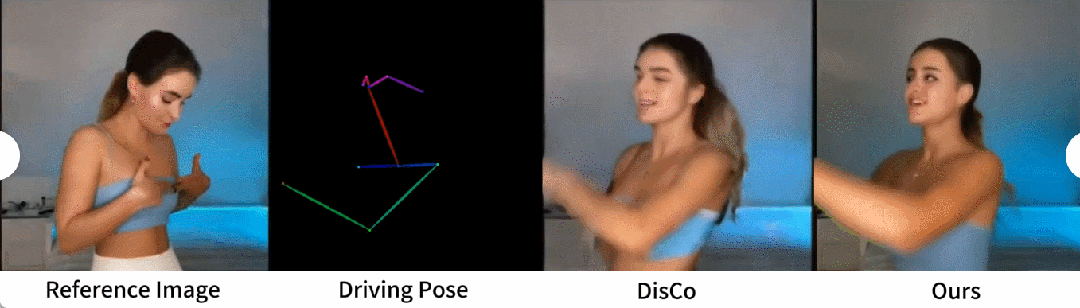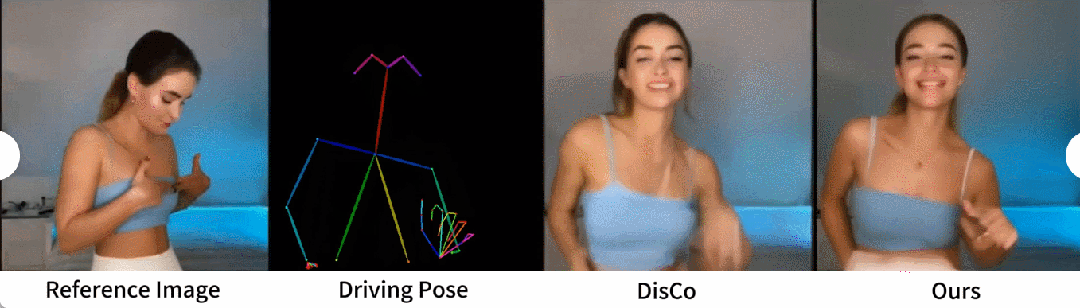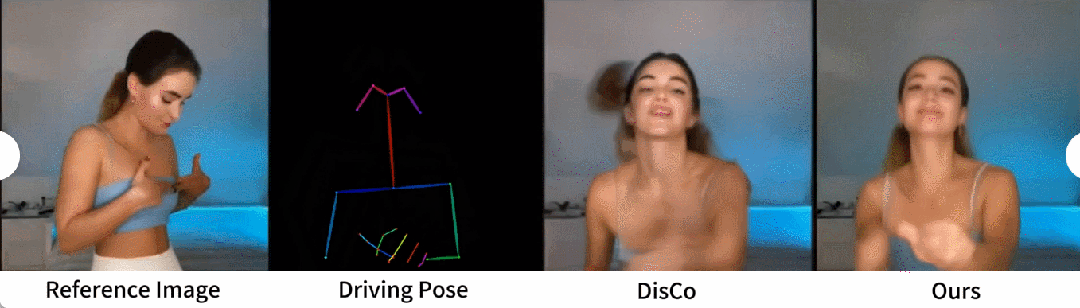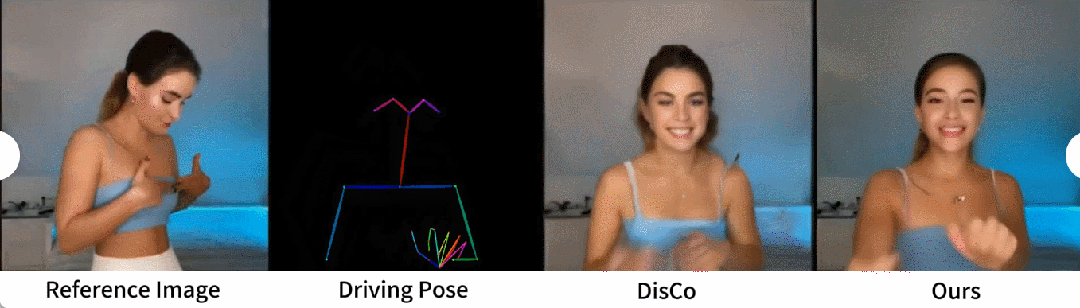
Une comparaison qualitative avec DisCo est présentée dans la figure 5. Compte tenu de la complexité de la scène, l'approche de DisCo nécessite l'utilisation supplémentaire de SAM pour générer des masques humains au premier plan. En revanche, notre méthode montre que même sans apprentissage explicite du masque humain, le modèle peut saisir la relation premier-plan-arrière-plan à partir du mouvement du sujet sans segmentation humaine préalable. De plus, dans les séquences de danse complexes, le modèle excelle à maintenir une continuité visuelle tout au long de l'action et fait preuve d'une plus grande robustesse dans la gestion des différentes apparences des personnages.

Image - Approche universelle de la vidéo. Actuellement, de nombreuses études ont proposé des modèles de diffusion vidéo dotés de fortes capacités de génération basés sur des données de formation à grande échelle. Les chercheurs ont choisi à des fins de comparaison deux des méthodes image-vidéo les plus connues et les plus efficaces : AnimateDiff et Gen2. Puisque ces deux méthodes n’effectuent pas de contrôle de pose, les chercheurs ont uniquement comparé leur capacité à maintenir la fidélité d’apparence de l’image de référence. Comme le montre la figure 6, les approches image-vidéo actuelles sont confrontées à des difficultés pour générer un grand nombre d'actions de personnages et peinent à maintenir une cohérence d'apparence à long terme dans les vidéos, entravant ainsi la prise en charge efficace d'une animation cohérente des personnages.

Veuillez vérifier le papier original pour plus d'informations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel est le mot de passe initial du routeur ikuai ?
- Quels sont les trois modèles de données de la base de données ?
- Quelles sont les fonctions du ps ai ae pr ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?
- Comment copier un modèle dans un autre fichier dans 3dmax